For some years now, one of the first things I’ve dropped into any new project has been ELMAH. Grab it from NuGet, provision yourself a SQL database table and watch magic happen as every unhandled error gets dumped into the DB and is reviewable via a handler which exposes the original stack trace amongst other info such as server variables and POST data. In theory, you also secure this. In practice, many people don’t.
To get a sense of what ELMAH does, check it out on my sample insecure website “Supercar Showdown”. It’s neat stuff, but it’s also an absolute firehose of exceptions. The same stuff is there over and over again; there’s no triaging or flagging of exceptions rather it’s just page after page of the same issues. At certain times in the lifecycle of certain projects, I’ve used the automated email notification to be told when an exception is raised then been flooded with noise. Oh – and the logging to the DB won’t work if the exception it’s trying to capture is that the DB can’t be reached!
But this isn’t intended to be an ELMAH-bashing session as indeed its served me very well for many years, rather it’s to look at the next evolution of error logging and that’s what brings us to Raygun:

With branding like this it must be awesome, right?! Actually yes, it is. Let me explain how this is working for me and the problems it’s solved.
Errors happen. Deal with it!
First of all, let’s be clear that unhandled exceptions are always going to happen. Yes, you test like crazy and yes, you exception handle everything you can get your hands on but funny things will inevitably happen on the web. Here’s an example: On Have I been pwned? (the site I’ll be implementing Raygun on for this post, often referred to as HIBP), I have a facility to search for all breached accounts across a domain. It looks like this:
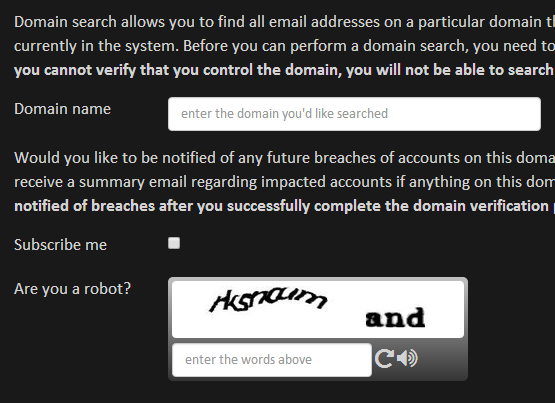
Now what do you think a valid value is for the “Subscribe me” field? If it’s checked it must be “true”, right? Then why on earth did I just get dozens of requests with a value of “on” which subsequently caused a 500 exception because the string couldn’t be cast as a boolean? This made my ELMAH log a mess and filled it up with the same junk over and over again:
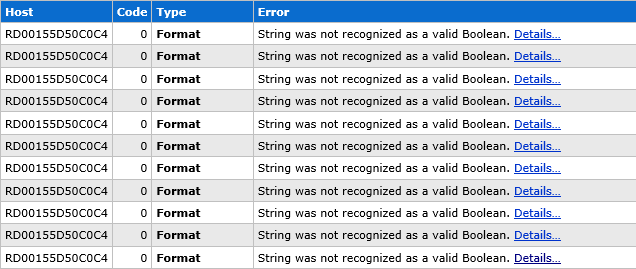
And when we look inside at the form data posted with the request, here’s what we see:

Yeah, I don’t think “Joey” is a valid domain name! This is just some form of spam bot sending random junk. (Interestingly, it’s actually retrieved what looks to be a valid request verification token from the form so it’s probably requested the page first.) Clearly it wouldn’t have passed the CAPTCHA anyway (see why I have these now?), but the point is that odd things will happen to your app in ways that you never planned either due to users being random creatures or automation against your site.
Oh, and just in case you’re wondering why there are two values for the “SubscribeToNotifications” checkbox, the ASP.NET MVC checkbox helper does this of its own accord. And yes, the controller action does check that the model is valid but the (attempted) conversion to boolean happens upstream of there when the form data is cast to the model type for the action.
Attempting to sort the wheat from the chaff (AKA “Shaving the Yak”)
In times gone by, what I’d do is add URL rewrite rules to catch odd requests and send them off in different directions so that they didn’t raise exceptions. For example, I kept getting requests for a “smart quote” at the root of the domain which would cause a 404 so I’d do a permanent redirect back to the root. This is your proverbial yak shaving and in effect, does nothing of any real value (assuming of course they’re not legitimate requests by users). In reality, it’s probably better to have these requests raise exceptions but not let them flood my error log with noise.
When we think about it, exceptions break down into two major categories:
- Stuff that’s gone wrong and I really should fix. This may be genuine errors from legitimate use of the site and I’d be doing users a favour by resolving them or they may be unexpected usage in a way that shouldn’t really work anyway but it would be nice not to have exceptions occur as a result.
- Stuff that’s gone wrong and I just don’t care about. This is very much the scenarios painted above where they’re way outside the bounds of proper usage but I don’t necessarily want to implement workaround just to quieten down the error noise. I’d like it recorded, I just don’t want it getting in the way of me focussing on the genuinely important errors.
Of course there’s no way of accurately automating the classification of these exceptions, rather we need a means of triaging them. We also want to be able to take a case like the invalid boolean value earlier on and say “This is an exception and I’m happy to record it, but for all intents and purposes it should be ignored”.
So that’s the background, let’s jump into making Raygun work on HIBP.
Installation
One important note here before the detail: Raygun is not just a web server exception logging service, it also does awesome things on client apps like iOS and Android. You’ve got all sorts of different challenges in these environments due to the often disconnected nature of the app so to have a tool like this available as a drop in service and be able to run it across multiple server and client stacks is rather awesome. Have a listen to John-Daniel Trask (Co-founder & CEO) on Hanselminutes for a really good rundown of this.
Moving on, HIBP is all ASP.NET MVC on Azure and it’s dead easy to just get the Raygun bits from NuGet. Drop in the package, set your API key from the one you’ll find under your account on the website and that’s it, job done. It seems almost too easy but that was all it took. I then added a controller action to the site that deliberately caused an exception (trying to create a GUID of an empty string will do that!) just to check things worked. And it did. First go.
How do I know it worked? That brings us to the dashboard.
The Raygun dashboard
Let’s just jump right into it:
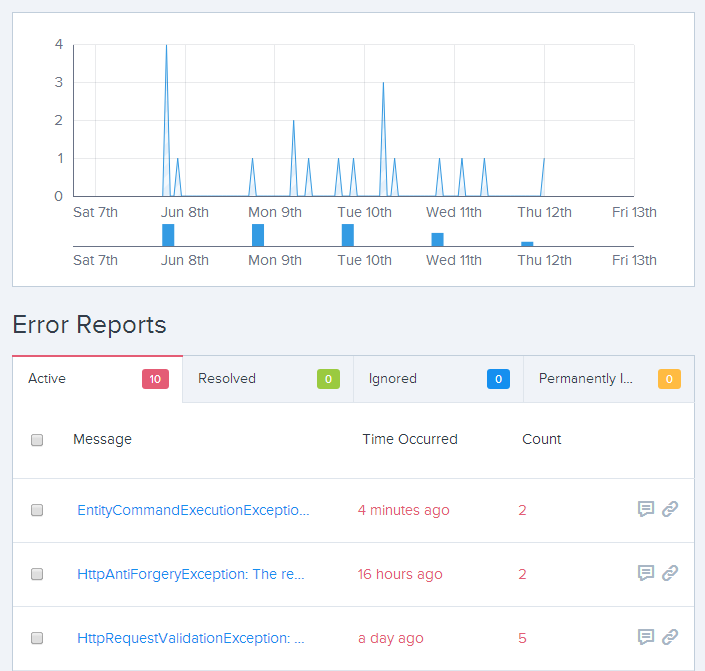
This is less than a week’s worth of data on a site which has been very carefully monitored and refined so I wouldn’t expect to see many exceptions in there (at least not genuine ones raised by legitimate use of the site) but there are a few we can look at here. Exceptions are grouped which is neat because if something goes wrong and you suddenly ends up with thousands of the same things you’ll see it, but it won’t drown out all the other exceptions like it would have in the ELMAH model.
The second axis allows you to pick a time segment to zoom in on which then focuses the graph on a specific area of interest:
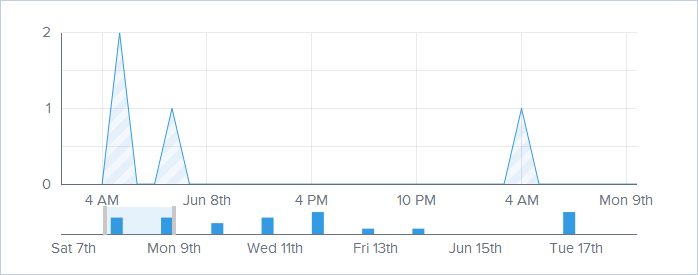
Each point on the graph is also “active” so you can get info at a glance:

That’s your basic functions, let’s drill down into detail and find out what’s going on with these exceptions.
Assessing an exception
Let’s look at one of these a bit more closely and I’m going to pick on that last one in the list above which is the request validation exception. Remember this is ASP.NET’s built in XSS defence and an HttpRequestValidationException will be raised if a request contains a potential cross site scripting payload which predominantly means it has angle brackets that look like a possible HTML tag. Let’s drill down into that:
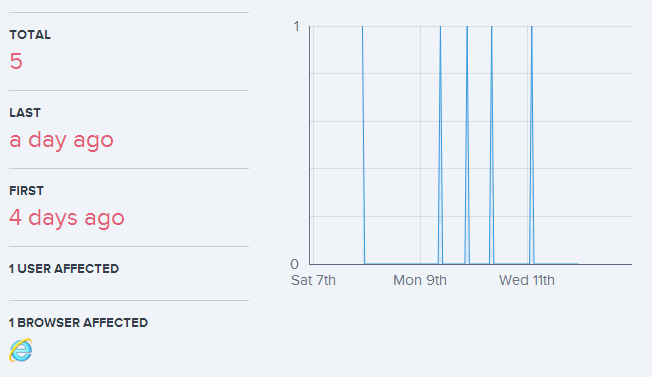
Seeing data represented in this fashion gives us a real good bird’s eye view of what’s going on. The exceptions are distributed across a period of days rather than being clumped together so it’s clearly not a transient issue. On the other hand, it only appears to be affecting one user and they’re using IE so it may be constrained to just them or just Microsoft’s browser. We’re going to need some more info to get to the bottom of this so let’s scroll down a little and look at the exception:
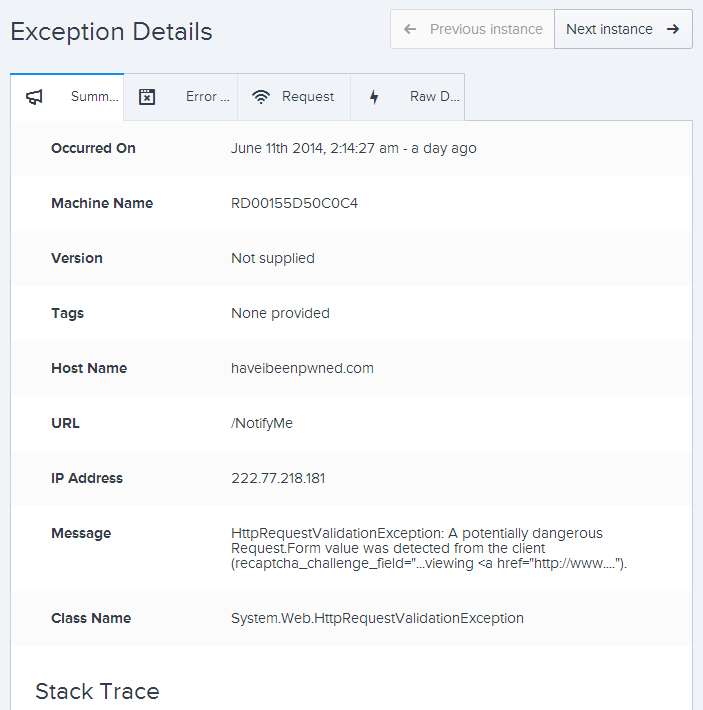
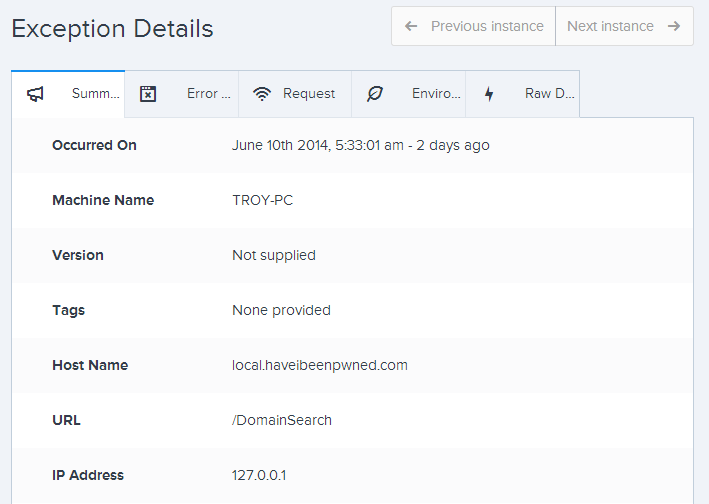
This is fairly self-explanatory, although one thing that would be neat is to see that IP address translated to a physical location and network name as that can be pretty useful at times (incidentally, this one is from China). The stack trace shows, well, exactly what you’d expect it to so I won’t reproduce it in full here. If I hit “Next instance” then we can see that the previous exception (they’re in chronologically descending order) was from a different IP address (another location in China) albeit with the same message:
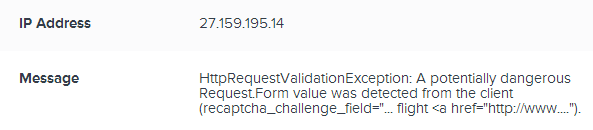
Wait – why is there only one user impacted when we’re seeing exceptions from different IP addresses? Because they’re both the same authenticated identity which in this case, is anonymous – there’s no login feature on the site. If users could actually authenticate then there’d be the ability to accurately report on the number of unique identities impacted by the exception which is pretty useful for assessing scope. More info on this in the docos.
Moving on, the valuable data in terms of getting to the bottom of this is on the “Request” tab and that has pretty much everything conceivable in terms of both the client state (request header and body including cookies and form data) and server state (namely the server variables). It’s too much to reproduce in its entirety here, but I will share the form data as that’s where the really useful info is:
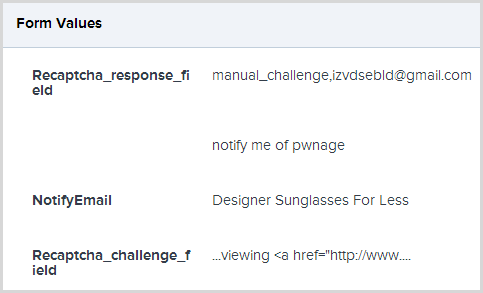
Ah, right, so we’re looking at a spam bot that’s plugging designer sunnies and clearly has no idea of how to get around the CAPTCHA (told you serve a purpose)! The request validation exception is being raised because it’s trying to post a hyperlink in the CAPTCHA field and the angle brackets are upsetting things.
On the one hand, this is spam so it’s clearly not adversely impacting any users and it really shouldn’t bother me. On the other, I don’t like unhandled exceptions of any kind plus it also raises an interesting question – what if the CAPTCHA ever legitimately has an angle bracket in it? Whilst I can’t say I’ve ever seen one, it seems a feasible possibility. This field is never redisplayed anywhere so there’s no XSS risk (and it would be automatically encoded by an HTML helper in MVC even if it was), so is request validation really necessary here? Probably not, let’s turn it off on the model attributes:
[AllowHtml] public string recaptcha_challenge_field { get; set; }[
AllowHtml]
[Required(ErrorMessage = "The puzzle must be solved")]
public string recaptcha_response_field { get; set; }
Now, why have I decorated two fields with AllowHtml? The challenge – the one causing the exception – is generated by the CAPTCHA and is the token which identifies it. Under normal operation it’s passed in a hidden field and is never actually visible to the user. In all its wisdom, this is what the spam bot is manipulating (take note folks – hidden fields often contain things you never expect them to!) and the response field is the one the user would normally type into. I’d almost consider just disabling request validation on the site altogether given the nature of it (and other reasons I’ll write about another time), but for now, this stops it from firing on just those two fields.
Now that I’ve implemented this change, tested it and “fixed” this unhandled exception, I’m going to “resolve” it:
This now jumps off my list of active exceptions and moves over to the “Resolved” tab:
I like this approach for a couple of different reasons: Firstly, I don’t lose information on exceptions I’ve dealt with in the past. I like having the data handy and for some exceptions, being able to revisit it later on can be very useful. Secondly, triaging exceptions in this way enables me to use that “Active” tab as a to-do list; everything that’s on there is something that should be dealt with in one way or another so that it eventually comes down to zero.
Ignoring
Every now and then you’re bound to get errors which don’t actually require any action, even though strictly speaking, they’re still unhandled exceptions. A good example is a missing anti-forgery cookie for CSRF protection. Most anti-forgery implementations depend on both a hidden field and a cookie which are paired together to prevent attackers from tricking the browser into making a request. If there’s no cookie, we’re going to see an exception somewhat like this:
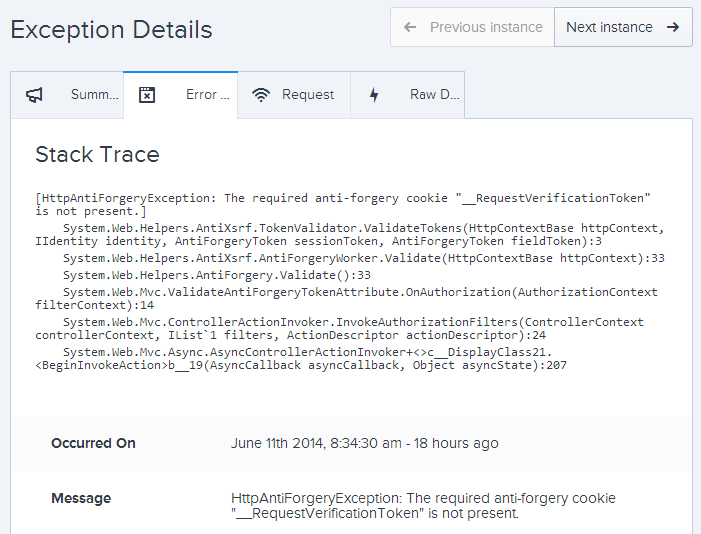
We can easily work out what’s going on here by checking out the details of the request and taking a look at the cookies the browser sent when the exception was raised:
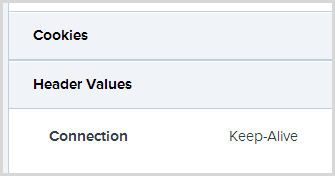
Ah, ok, so no cookies. No Google Analytics cookies, no Azure affinity cookies and certainly no anti-forgery token cookie. This client almost certainly has cookies disabled which means they’re not going to be submitting any forms with anti-forgery tokens on them. Now there are ways to hack around the cookie dependency and indeed you could probably question whether it’s even necessary on an unauthenticated resource such as the domain search feature where this is occurring, but for the sake of this exercise I really just want to ignore these errors. In fact I want to permanently ignore them:
This will keep them off the active exceptions list and not send me any notifications and it’s more all-encompassing than just “ignoring” a single exception (more on the semantics here). Did I say notifications? Let’s cover that now.
Email notifications
Right at the opening of this post I mentioned how I’d been flooded with ELMAH email notifications in the past. These are great for being told immediately something goes wrong, but you need to be smart about it. I don’t want 50 emails about the same thing, I want one when it first breaks then I’ll go and sort it out. If, after that, it happens again then yes, I want to be told again. This requires some smarts but it’s exactly what Raygun does.
When an error that’s not meant to be happening occurs (i.e. you haven’t heard about it before and it’s not permanently ignored), you immediately get hit with an email like this:
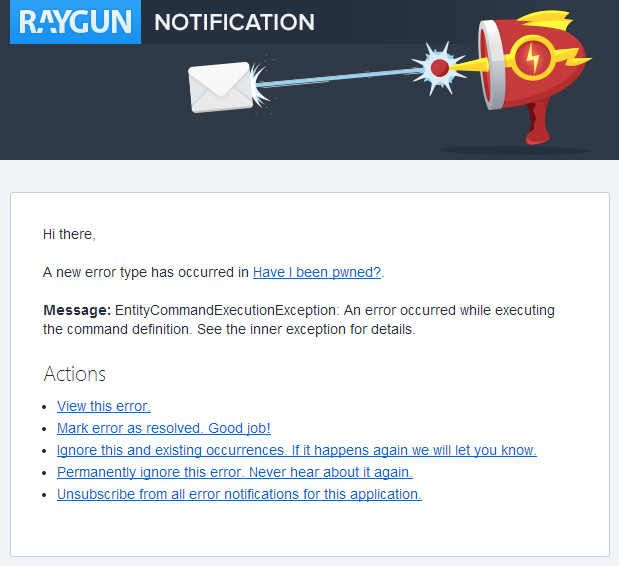
This is exactly the kind of exception I don’t want to see – Entity Framework is having trouble connecting to the database. I want to know about this sort of thing ASAP as it could be that the DB is offline or if it’s just after a publish, I may have broken something on the app side. You can jump straight into the exception and view the details with the stack trace which quickly discloses the root cause of the problem:

Ok, “transport-level error”, not a lot I can do about that. As you’ve seen already, I can also look at other exceptions of the same type and it turns out that this is a very uncommon one:
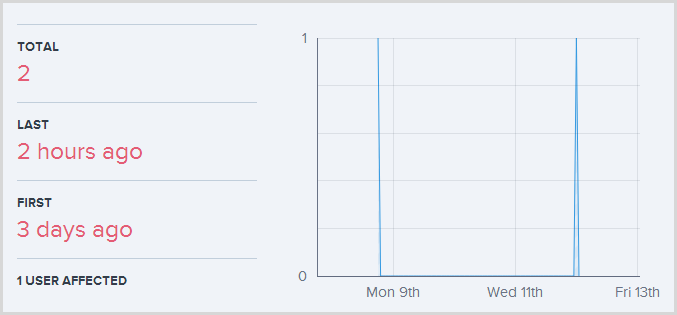
I might want to take a look at what it is that’s causing this more closely but it may well also be beyond my control (i.e. SQL Azure just being inaccessible on the very odd occasion). I’ll just ignore both of these errors for now which means I’ll still get a notification email if it happens again, but I’ve removed them from the active exceptions on my dashboard.
Manual exception logging
All the automated catching and logging of unhandled exceptions is awesome and it’s definitely the primary value proposition of the service in the same way that it was for ELMAH. But also as with ELMAH, there are times when you want to explicitly log your own exceptions and it turns out that’s fundamentally simple:
try {}
catch (Exception ex)
{
new RaygunClient().Send(ex);
}
Or of course you can just raise your own exception type. Regardless, the point is that you have programmatic control over the process which is really neat.
Incidentally, this works really well in HIBP when I’m connecting to a third party service where bunch of stuff can go wrong (connection dropped, API key invalid, they change their data model, etc.)
Keeping errors out of dev environments with config transforms
The ease of adding Raygun via the web.config is awesome, but you’ve also got this problem:
I don’t want to log exceptions from my development environment, there’s just no point. I expect stuff to break while I’m building it and I don’t want it muddying up the waters and obscuring the legitimate errors.
As the Raygun configuration is all in the web.config, it’s dead easy to just apply config transforms so that it’s only added when published using the “Release” build profile. Here’s what my config transform now looks like:
<configuration xmlns:xdt="http://schemas.microsoft.com/XML-Document-Transform"> <configSections> <section name="RaygunSettings" type="Mindscape.Raygun4Net.RaygunSettings, Mindscape.Raygun4Net" xdt:Transform="Insert" /> </configSections> <system.web> <httpModules> <add name="RaygunErrorModule" type="Mindscape.Raygun4Net.RaygunHttpModule" xdt:Transform="Insert" /> </httpModules> </system.web> <system.webServer> <modules> <add name="RaygunErrorModule" type="Mindscape.Raygun4Net.RaygunHttpModule" xdt:Transform="Insert" /> </modules> </system.webServer> <RaygunSettings apikey="[my API key]" xdt:Transform="Insert" /> </configuration>Clean web.config in dev, correct web.config in prod and no Raygun errors where I don’t want them.
Incidentally, if an exception like this does sneak into Railgun.io, you can blitz it altogether by hitting the gear icon:
This will permanently kill it from the system which is just what you want in a case like this.
When stuff isn’t found – AKA HTTP 404 – (and why you want to know about it)
One of the most painful bits of filtering through ELMAH logs was 404s. Yes, I want to know when some nasty bot keeps requesting admin.php but no, I don’t want to continue hearing about it! From a security perspective, a heap of attack vectors result in 404s and automated scraping for PHP pages is a perfect example. I want to know when something new like this happens and I want a history of repeat attempts just in case I need to go back and review things at some point.
It’s also important for usability; sooner or later you’re going to rename or move something that someone is dependent on and you’re only go to know about when an exception is captured – or when they complain about it! Or here’s another one – a media piece about HIBP linked to the FAQs page but for some reason they linked to /FAQ (singular) instead of /FAQs (plural). I only knew this because I trawled through the ELMAH logs and found the 404s. Once I picked it up it was an easy fix with a URL Rewrite rule (ok, they should have fixed it at their end but good luck making any progress of that kind with the press!) but the point is that I only picked it up because I’d trapped the exception. Of course with Raygun, I’m also proactively notified of this typed of exception via email so when something like this goes wrong (even when it’s not my fault), I can get on top of it quick smart.
Understandably, I was excited about this feature in Raygun but when I went to test it… nada. No 404 tracking. I raised this with the guys and got some very good support which basically boiled down to “ASP.NET MVC funky errors handling semantics” but it was something they were getting onto fixing promptly. That was only last week and today they pushed out version 2.2.1 with a promised fix. Update from NuGet, push to GitHub, let Azure do its magic and…
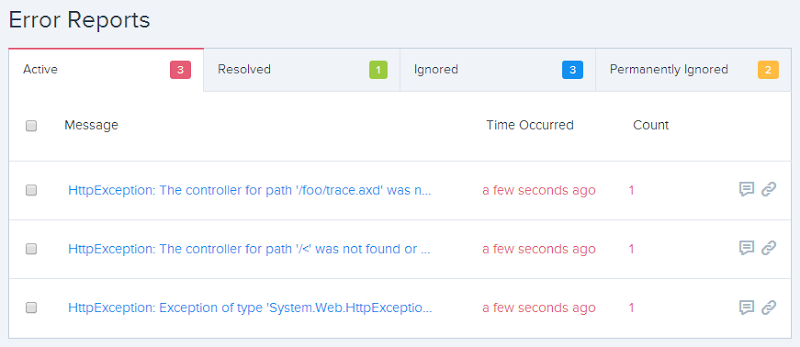
There we go, 404s now logged! In fact this is a perfect example of why it’s needed as I generated these from an ASafaWeb scan. For the uninitiated, this is my little freebie service for remotely assessing ASP.NET security misconfiguration in live websites and it always results in a bunch of 404s or other internal exceptions in the target site. In a case like this, being able to so easily pull request headers makes getting to the bottom of this sort of thing dead easy:
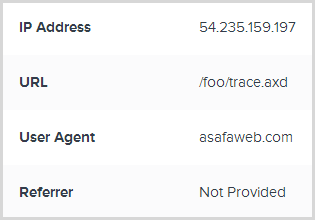
Of course in a case like this I just triaged the exceptions as “Ignore all” so they won’t stick out in future, but they’ll still be collected and I can still review them later. That, IMHO, is just a perfect balance.
Because your own database is not where you want to log errors
One of the most fundamental reasons why a service like Raygun makes sense for a website is simply this: When unhandled exceptions are raised, it’s usually because something has gone wrong. Expecting a failing app to reliably log these to its own repository in the way I’d done earlier with ELMAH is gonna cause issues sooner or later. I’ve seen it happen – “Hey, there’s no exceptions in the log!” – yeah, that’s because the DB reached capacity and they couldn’t be logged! That could well have been the case in that earlier transport layer exception I referred to.
To be fair, there are ELMAH services that are available in a similar model, for example TraceAgent and elmah.io. They all have slightly different pricing models that make some structures more attractive than others, but neither has Raygun’s broad platform support not just on the server, but for client apps too. Plus it’s from Down Under and even though they’re New Zealanders, when it comes to doing things that are awesome we generally like to consider them honorary Australians :)
Other stuff and wrap-up
All the bits above are the pieces that I think are fundamental to understand both about capturing exceptions in general and Raygun’s implementation in particular. But that’s not the whole story – there’s more!
For example, there’s a plugin ecosystem. Use FogBugz for issue tracking and want to create items for your exceptions there? There’s a plugin for that. Use GitHub’s issue tracker instead? Yeah, plugin for that too. In fact there are a heap of plugins for various purposes:

Then there’s the security aspect of things; as I mentioned in the opening paragraph, you’ve gotta be rather careful with your exception logging or bad things can happen. You’re trusting Raygun to get their app sec right and so far, it looks like they’ve done a pretty good job of it. They also give you configurability over the classes of data you capture and store with them. The last thing you want is to get all PCI DSS compliant then send an exception over to Raygun complete with the credit cards details sent in the failing request, that’s not going to be a good look. Fortunately, defining form variables you don’t want captured is a breeze and it goes straight into the web.config:
<RaygunSettings apikey="your_apikey" ignoreFormDataNames="password,creditcard,cv2" />
And finally, the obligatory disclosure bit – I’ve written about Raygun not because I was paid to (I wasn’t), but because frankly, the tool rocks. Writing posts like this forces me to understand what’s going on and ensures I can clearly articulate it to other people. This post also forms a part of the ongoing live documentation of HIBP so that you can all see what goes into standing up a service of this nature. Now the guys at Raygun did flick me over to a free account, I assume how long that lasts all depends on how good a job I’ve done of espousing the service’s benefits :)