Databases have long been the poor cousin of the application tier when it comes to many of the processes we take for granted in the .NET world. Source control management, for example, is near ubiquitous for application files and there are several excellent VCS products which make versioning a breeze. Continuous integration is another practice which although not as common, is still frequently present in a robust application lifecycle.
Of course the problem is that database objects don’t exist as simple files that can be versioned, nor can you just pick them up and place them in a target location when you want to deploy them. You’ve got to consider the very nature of databases being that you’ve got real live data to deal with and the ramifications of screwing up a deployment are pretty severe.
Some special tooling is in order and fortunately the planets are starting to align in such a fashion that some of my favourite products work very nicely together to serve just the purpose we’re after. Last year I wrote about Red Gate’s SQL Source Control as a very excellent way of versioning databases and followed up later in the year about automating deployments with TeamCity.
Let’s take these tools – plus a few more from the Red Gate product suite – and finally make one-click database deployment a true first class citizen with its application peer.
Get your database under source control
First and foremost, none of this is going to make any sense whatsoever unless you get your database under source control. As I wrote a couple of days back in The unnecessary evil of shared database development, “Database source control is no longer negotiable”.
Databases are an essential component of many of the applications we build and to deny them the value of VCS is just crazy talk. Without the DB in source control we end up with a fragmented, partially complete picture of what an application is. We lose the ability to say “Here – this is the state of code over time”, as only part of the picture exists.
Of course we also lose all the productivity advantages of not only being able to rollback when required, but being able to integrate with the work of our peers. Sometimes we’ll address the latter by using a shared development databases but, well, go back and read the article above for everything that’s wrong with that.
But most importantly in the context of this post, VCS is the “source of truth” for automated deployments from a continuous integration environment. It’s where application life begins and it’s where TeamCity is going to turn to when it publishes both the web application and the database.
Schema
Working on the understanding that anything we want to release with this process should come from source control, the obvious database elements which need to go into VCS are pretty much everything in the schema. This includes any database objects such as stored procedures, views, triggers and of course, tables. Because SQL Source Control neatly files each object type away into its own folder, all we need to do is take a quick look in the Subversion repository for the project and we’ll see just what sort of stuff is going to go in there:
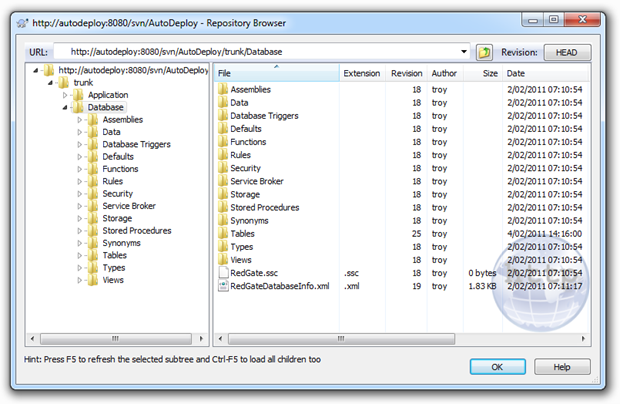
When it comes to publishing the above, we need a mechanism which can pull them from source control then script and execute the required changes against the target environment. Depending on the changes, we could be dropping objects, altering permissions, changing data lengths or potentially any other conceivable database change. The main thing is that VCS is our source of truth and we need to ensure the target environment is changed to match this exactly.
This is where SQL Compare comes into play. I’ve long been a user of this on the desktop as a means of automating releases and ensuring environments were absolutely identical. But there are two features the current version has which make it perfect for our purposes here; unattended command line execution and syncing from a VCS source, the latter of which necessitates the Professional version.
For the purpose of this post, I’m going to run the process against a data model which looks like this:
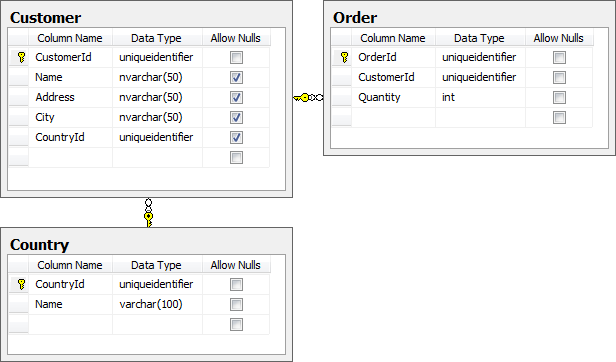
In theory, the “Customer” and “Order” tables would accumulate transactional data and the “Country” table would contain a static set of reference data. The importance of this distinction is about to become clear but for now, let’s just work on the assumption that everything you see in the image above is happily tucked away in VCS via SQL Source Control.
Data ain’t data
Here’s a contentious issue for you; versioning of data. But there’s data, and then there’s data. What should never go into source control is transactional data accrued during the normal function of the application. It shouldn’t go in as SQL scripts, it shouldn’t go in outputted to CSV and it definitely shouldn’t go in as a database backup.
But there is a class of data that should go into source control and that’s any data required for the application to actually function, such as reference data. For example, if a registration form contains a mandatory drop down list of countries driven from a “Country” table, we have to get that data in there in order for things to work.
In principal, we want VCS to contain enough information about the application to allow us to deploy directly from there to a target environment and everything just works. To do this, we need a means of generating the data in a scriptable format, storing it in source control then pulling it back out and synchronising it with the target environment.
But before we do that we need to populate my local development database (because a shared one would be evil), with a list of countries (thank you Text Fixer). Once this is done we can move on to actually versioning the data.
This is where this post goes off into a slightly different – albeit it much improved – direction to what I'd originally planned. You see, I was going to write (in fact I did – then ended up deleting) about how SQL Data Compare could be used to version the reference data. It involved checking out the database schema to a folder path and generating the reference data into that. I began lamenting the cumbersome nature of doing this; maintaining another working copy of the DB outside of the one SQL Source Control manages, having different processes (and subsequently different revisions) to get everything into VCS and perhaps most frustratingly, requiring another product just to keep data versioned. Then the SQL Source Control 2 early access preview came along.
You see, the next version recognises this problem and in the usual Red Gate way, makes it extremely simple to version the data. You just right-click on the table and “hey presto” instant data versioning:
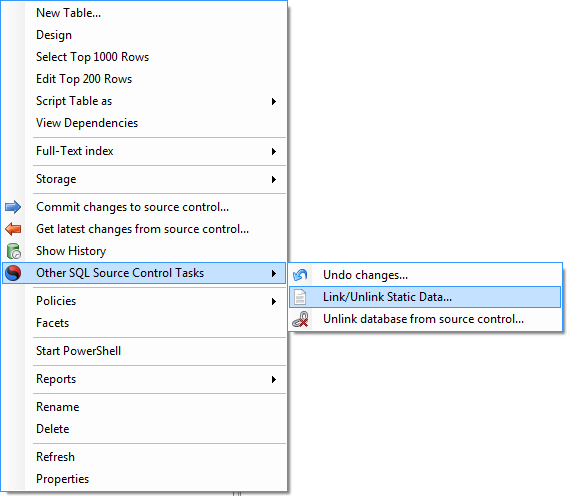
With this option we can now explicitly identify that the “Country” table contains our reference – or “static” in SQL Compare nomenclature – data:
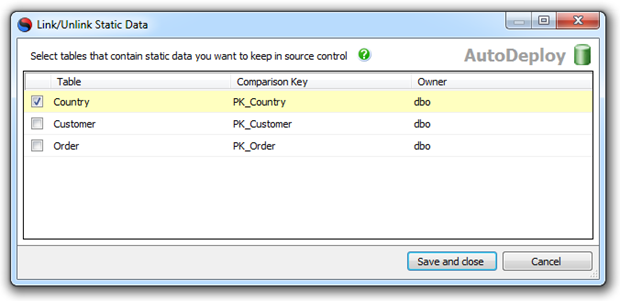
This will ensure that once we go back to the familiar old “Commit Changes” tab, we’ve got a rich set of static data ready for versioning. Let’s take a look at what we’re committing:
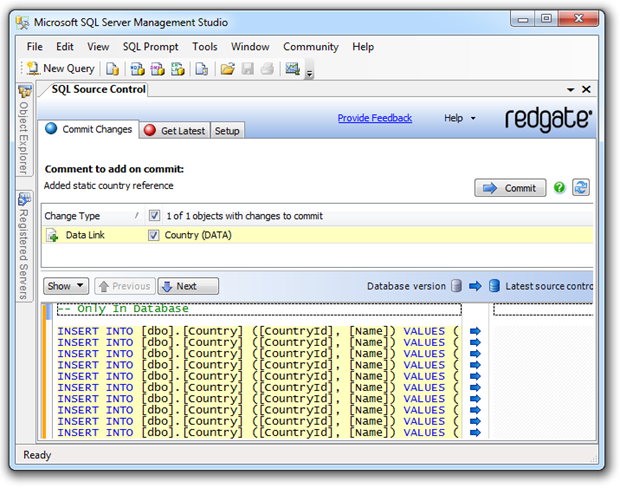
We can now go ahead and just commit that directly into source control. The beauty of versioning data this way is that the one transaction can also contain changes to the schema. To give you an idea of just how much easier this makes it than the original SQL Data Compare approach I took, the few paragraphs above replaced over 1,100 words and half a dozen illustrations. Very nice!
As with the schema, we ultimately need a means of automating the deployment of this data to a target environment. It’s going to mean not only inserting a bunch of records but later on, potentially updating or deleting them as well. We need a synchronisation mechanism and this is where we come back to SQL Data Compare Professional, but it will do all its work from the build server.
The build
Let’s get started with the nuts and bolts of how all this will work deployment wise. Firstly, I’m going to be using the TeamCity project which served me so well during the whole You’re deploying it wrong series. However, I’ve upgraded from TeamCity 5 to version 6 so although things look pretty familiar, we’ll have some new functionality available that will come in very useful a little later on.
I’m also going to use a combination of SQL Compare and SQL Data Compare – the Professional versions of each so they can run against scripts from VCS – so both of these must be installed on the build server. Fortunately we won’t require them anywhere else such as on developers’ PCs.
Let’s start with the general settings of the build:
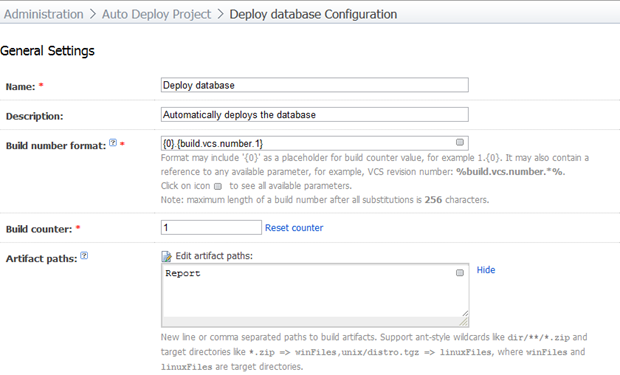
As I’ve said in previous posts, I always like to keep the VCS revision in the build number as it can make life a whole lot easier later on. The “Report” path in our artifacts will hold the output of the deployment so we can inspect it after the build.
Moving on to the VCS configuration, I’ve left all the main settings in their default positions and only customised a VCS checkout rule:
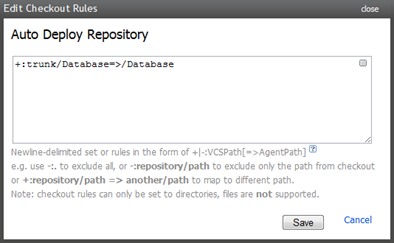
One thing I’ve changed about the original solution is the structure in VCS. Rather than sitting the ASP.NET app directly in the trunk, I’ve moved it into a folder called “Application” and placed a “Database” folder right next to it (you can see this in the screen-grab in the “Schema and objects” section above). This meant I needed to go back and change the VCS checkout rule in the existing builds to pull from one level deeper than the trunk.
Moving on to the build steps, we’re going to need to tackle this in two parts; objects then data. This is the reason why TeamCity 6 makes things a bit easier because it now provides for multiple steps in a single build. Yes, we could wrap it all up in an MSBuild script with some exec tasks and just call that but it’s always nice to avoid additional layers of complexity where possible.
The first step will be to sync the schema and we’ll run this direct from the SQL Compare executable. We need to run this first simply because the data synchronisation may have a dependency on this (i.e. new reference table crated and values to be inserted). Let’s get started:
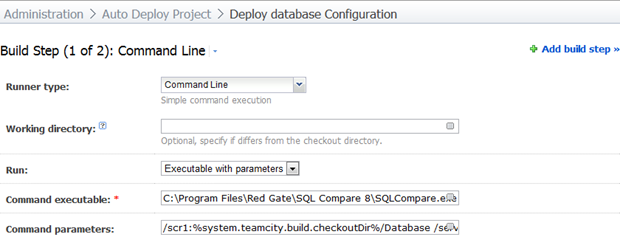
The magic is in the parameters:
/scr1:%system.teamcity.build.checkoutDir%/Database /server2:(local) /db2:AutoDeploy /Sync /Include:identical /Report:Report/SchemaDiffReport.html /ReportType:Interactive /ScriptFile:Report/SchemaSyncScript.sql /Force /Verbose
As succinctly as I can explain it, here’s what’s going on; the source of our scripts is in the “Database” folder of the checkout directory (we specified this in the checkout rule). We’re going to sync this schema against the SQL Server known as “(local)” (obviously it would be a remote server under normal circumstances) and the database called “AutoDeploy”. The account running the build agent has the rights to create objects in the target database otherwise we’d need to look at passing these via username and password parameters.
Moving on to the sync configuration, the “Sync” parameter ensures the changes are actually replicated to the target rather than just giving us a report on the differences (more on this later).
The “Include:identical” parameter means the output of the command will explicitly tell us which objects were identical and it will ensure SQL Compare doesn’t exit with an error code when everything is identical. If we don’t do this, subsequent runs of the build will fail and return a message like so:
The selected objects are identical or no objects have been selected in the comparison.
I like the extra verbosity and explicit feedback of this option and besides, I don’t want my build failing just because no changes were found. Furthermore, if we don’t take this option then the schema sync script (more on this shortly), won’t be generated and the build will pick up the last one unless we clean the sources first.
Moving on to the reporting, we’re automatically changing database objects here which can be a little frightening in a live environment so I want lots of output. The “Report” parameter is going to give us a nice web UI report which is “Interactive” in that it will let us drill down on the changes (more on that soon). We’ll also save the actual script file which was executed against the target and call it “SchemaSyncScript.sql”.
The “Force” parameter will ensure that when SQL Compare attempts to write the report and one already exists from a previous build, it will get overwritten. If we don’t do this the build will spit out a nice error message for you (the missing space in this quote is from Red Gate – not me!):
Unable to write report to file 'Report/SchemaDiffReport.html' because thefile already exists.
And finally, let’s get as much verbosity as possible in the response from the command. All this will go into the build log so the more information, the better.
Before we go on to the data synchronisation, because SQL Compare is happy to generate us a nice HTML report, let’s ensure we can display that in a friendly way on the build page. It’s over to the TeamCity Administration –> Server Configuration –> Report Tab and add a new entry like so:
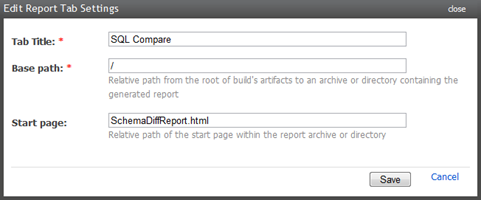
Onto the next step; syncing the data:
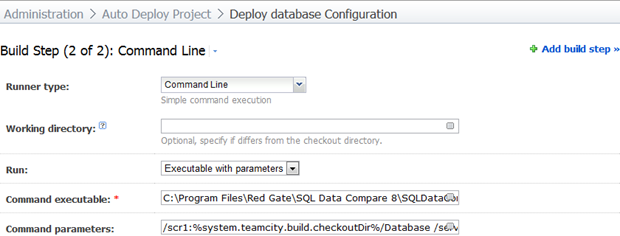
It’s a very similar situation to SQL Compare, just a different executable and path and some slightly different parameters:
/scr1:%system.teamcity.build.checkoutDir%/Database /server2:(local) /db2:AutoDeploy /Sync /Include:table:Country /Include:identical /ScriptFile:Report/DataSyncScript.sql /Force /Verbose
Actually, there is an important difference. I’ve had to explicitly include the table I want synced. You see, by default, Data Compare wants to sync every table and without explicitly telling it which ones to compare, every table gets compared to either a script in source control or to nothing and when you sync against nothing, well, you end up with nothing.
The problem with this approach is that as new reference tables are added to the database, the build parameters have to be updated with additional “/Include” parameters for each table otherwise they won’t sync. So what we end up with is a white-list of tables in the build configuration matching exactly the same tables which have already been versioned.
I originally did this the other way around – a black-list excluding the tables I didn’t want synced – but a question sitting over on the Red Gate forums has led to a more favourable, although not ideal, result. I’d still prefer to have it sync directly to VCS and simply ignore any tables which weren’t versioned.
There’s only really one other difference in the parameters and that’s the name of the script file so it doesn’t conflict with the schema change script. The other differences are actually omissions; there’s no mention of a report. It seems a little bit odd, if I’m honest, that SQL Compare is quite happy to produce a very nice human readable report of the differences but Data Compare doesn’t appear to have the facility.
Making the magic happen (aka running the build)
Now that we have all the schema under source control, all the reference data we’ll want to refer to and a build with deployment steps for both, let’s run it all against a brand new database with nothing in it. This an entirely clean install – just a brand new, empty DB:
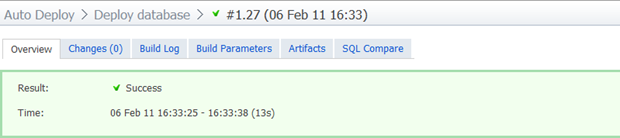
Green is good, but let’s look at what has actually happened here. Firstly, it only took 13 seconds. Yes, the changes are very small but they’re also running inside a VM on my PC including the whole gamut of TeamCity, IIS, SVN, SQL Server and of course, the Red Gate tools.
Let’s take a look inside the build log. There’s a lot of info in there (remember, I deliberately asked for verbosity), but here’s the essential bit in the first build step to sync the schema:
Object type Name DB1 DB2 --------------------------------------------------------------------- Table [dbo].[Country] >> Table [dbo].[Customer] >> Table [dbo].[Order] >>
Here we see the tables listed and the double right-angle brackets pointing from DB1 (which is our VCS) to DB2 (which is the target database). The angle brackets mean the structure on the left will be replicated to the structure on the right.
The log then contains all the create scripts and various other information until we get down to the second step in the build where the data is synced. Here’s what’s important:
Object type Name Records DB1 DB2 --------------------------------------------------------------------- Table [dbo].[Country] 244 >>
Pretty self-explanatory, 244 records are going to be inserted into our brand new “Country” table. Let’s move along and look at the artifacts which were created:
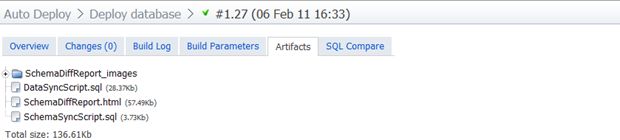
The two mains ones to look at here are the SchemaSyncScript.sql and DataSyncScript.sql. They’re both actually rather unremarkable with the former containing a series of CREATE statements and the latter having all the INSERT statements we saw when SQL Data Compare first generated them.
It’s the SQL Compare tab where things get a bit more interesting:
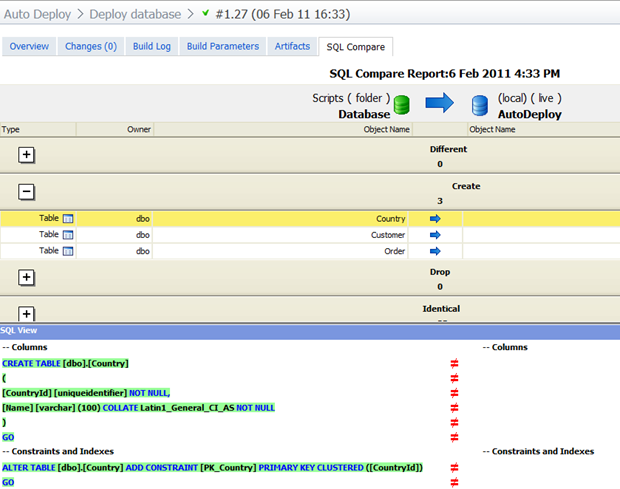
Here we have a nice visual representation of the three tables and then the required change to the selected one – the “Country” table – which of course just results in a comparison with a non-existent entity. Now why can’t we get that for SQL Data Compare as well?!
So that’s it – fully automated deployment of schema and objects with just the click of a button. But of course a pure CREATE and INSERT process is only ever done the first time. Let’s make it a bit more challenging.
How the build handles changes
We want to push the envelope a little bit further here so let’s move away from the comfort zone of simply replicating the source environment to another nice clean target. Here are the changes I’m going to make:
- Add a “PostCode” field to the “Customer” table
- Change the “Name” column in the “Country” table from a varchar(100) to an nvarchar(150)
- Delete the “New Zealand” record from the “Country” table (obviously they’ll simply become another state in Australia)
- Remove the word “Democratic” from “Korea, Democratic People's Republic of” (c’mon, they’re not fooling anyone)
The great thing about SQL Compare 2 is that all the above can go in as one VCS transaction. This is perfect for keeping the database atomically correct – now if only the application layer could go in at the same time!
Let’s run it all up again and take a look at the build log. Firstly, what it finds with the schema:
Object type Name DB1 DB2 --------------------------------------------------------------------- Table [dbo].[Country] <> <> Table [dbo].[Customer] <> <>
The two opposing angle brackets indicate the objects aren’t the same in source and target which is true for both tables. Browsing over to the artifacts we can see an ALTER COLUMN statement on the “Country” table followed by an ADD statement on the “Customer” table. Cool.
Now let’s look at the data:
Object type Name Records DB1 DB2 --------------------------------------------------------------------- Table [dbo].[Country] 242 == == Table [dbo].[Country] 1 <> <> Table [dbo].[Country] 1 <<
So 242 records sync up perfectly, one is different in both sources and one only exists in the target. Correct, correct and correct. Back over to the artifacts and the data sync script shows a DELETE statement for New Zealand (sorry guys), and an UPDATE statement for North Korea. Perfect!
It’s the change process which really illustrates the power of this mechanism and in particular, the Red Gate tools. You can let environments go through all sorts of schema and data changes then just simply let the build sync it all up. Red Gate takes care of the usual issues such as referential integrity and data retention throughout the change so for the people responsible for the environment, it really is as simple as clicking the run button and waiting about a dozen seconds.
This is a fantastic example of continuous integration and the ability for new work to head off in a different direction without fear of being able to integrate it all back together again. The great things about this is that it also makes reverting changes a breeze; it’s easy to run a build against an earlier revision because you know Red Gate can simply pick up the differences and script them appropriately.
Breaking the build
So far all this has been smooth sailing but what happens when things go wrong? What would happen, for example, if I deleted a country from the static reference data which was being used by a customer in the target environment? Let’s find out:
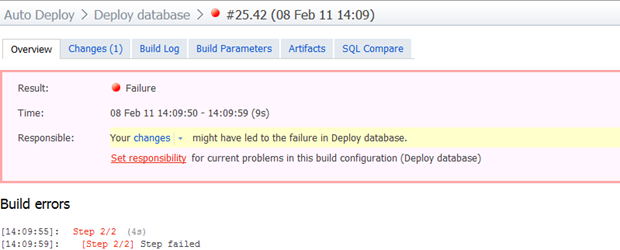
And if we now drill down into the build log:
Error: Synchronization of 'Scripts.Database' and '(local).AutoDeploy' failed:The DELETE statement conflicted with the REFERENCE constraint
"FK_Customer_Country". The conflict occurred in database "Autodeploy", table
"dbo.Customer", column 'CountryId'.
This is precisely what we’d expect to see happen and it raises an interesting point; there are going to be times where 100% automation may not be achievable. If, for example, New Zealand really did become an Australian state (quit mocking the suggestion – I didn’t come up with it), and we wanted to change all our customer records accordingly before deleting the country, there’s going to potentially be a several stage process involved.
Sure, we could start scripting the whole thing out and execute just that process in a build via sqlcmd, and there may be no other way in some environments, but it’s starting to become a bit of an agility anti-pattern. It would arguably become a simpler exercise to skip the build process in favour of working with whoever is playing the DBA role. After all, the whole point of this process is to make publishing easier, not to constrain people by rigid processes.
I’m nervous; can I see the change before it runs?
Yes, and it’s supremely simple to do; just drop the /Sync parameter. You see, doing this will give us every piece of information we previously got in the artifacts – namely proposed change scripts and the report for SQL Compare – but it won’t actually run them.
The real easy thing about this approach is that TeamCity gives you a “copy” feature to simply replicate an existing build configuration so we can take the one we set up earlier then just remove the parameters from each build step. Once this is done, you can run the new build then just sit back and soak in the results without committing to anything. Easy!
The tricky trigger problem – solved!
In the You’re deploying it wrong series, I had the build sequence triggered by a VCS change. As I said at the time, you might not always want to do this but it was a pretty neat party trick and it works well in certain circumstances (i.e. small team, deployment to an integration environment).
It was about here I’d previously lamented the fact that it took two commits to get both the schema and data into VCS and caution needed to be exercised to do this in the right order lest you try and insert data into a table which hadn’t yet been created. But SQL Source Control 2 solves this problem as everything goes in as a single transaction. So trigger away!
Single mother-of-all-builds versus linked builds
Earlier on we constructed a build configuration with two steps so that both the schema and data could be deployed. But of course it makes sense to tie this into the application layer as well which would mean associating it with the web deploy build. It’s just a question of how explicit this is.
In the one corner we could keep entirely autonomous build configurations and simply trigger one off the other with a snapshot dependency to ensure they pull from the same revision. On the other hand, the multiple build steps support of TeamCity 6 (or the classic MSBuild with multiple tasks pattern), could roll this all into the one build.
Personally, the linked builds model sits a bit better with me. To begin with, you’re pulling from different VCS roots so if it all goes into the one build you have to pull from a level higher then ensure all your references link to the appropriate “Application” or “Database” path.
Then you’ve got the fidelity of build failures; just seeing red in the mother-of-all-builds doesn’t tell you a lot about what went wrong without delving into it. And after that, what if you just want to run the DB deployment again and not necessarily the app build?
Of course your build log also becomes a bit of an epic and more thought needs to go into the artifact management. Furthermore, you can’t distribute web app builds and DB builds to different agents which could be useful in the future.
The only gotcha with linked builds is that if they’re triggered by a VCS commit and there’s a revision snapshot dependency you’re going to have trouble when you need to make both web app and DB commits. Actually, you'll end up running both builds twice as the second one requires the first to build against the same revision. In this situation I’d probably just decouple them and let changes to the web app root trigger web deploy and changes to the database root trigger the Red Gate tools.
Working with test data versus a clean slate
The model described above is great for syncing the schema and the data in the reference table. But what about the other tables? What do we want to do with our customers and orders?
There are a few different use cases to consider depending on the target environment and how it’s being used. Production, for example, is easy – this mechanism works perfectly as it retains all the transactional data the system has accrued.
A test environment midway through user acceptance testing is another place this rule applies. If you absolutely have to push out a change in the middle of a test cycle the last thing you want happening is for the data state of the transactional tables to suddenly and unexpectedly change.
Likewise in the development environment if you’re working in a team and collectively evolving the schema and reference data. You don’t want to be happily working away on your own tasks then take a change from a peer and suddenly you’ve lost a bunch of dummy customer data.
But there are times where the clean state approach is desirable. Between test cycles, for example, being able to clear the transactional data is desirable in terms of beginning testing from a known data state. And if you’re running integration tests anywhere with a data dependency, it’s absolutely essential to run them against a predictable set of data.
But this also doesn’t mean you want the transactional tables to be 100% clean – you may need some initialised data such as user accounts in order to even be able to logon. What you really want is the ability to create an initialisation script to prepare the database to your own personal tastes.
SQL Server actually makes this very easy by providing the sqlcmd utility which comes with the management studio. This allows us to remotely execute a script that can easily be pulled direct from VCS. As an example, I’ve put the following script into an “InitialiseData” folder at the trunk of the repository:
DELETE FROM dbo.[Order]
GO
DELETE FROM dbo.[Customer]
GO
INSERT INTO dbo.Customer (CustomerId, [Name], Address, City, CountryId)
SELECT NEWID(), 'Troy Hunt', '1 Smith St', 'Sydney',
'AA1DFC30-DD53-4BE5-A606-B595912C5C2B'
GO
I then created a new build configuration in TeamCity calling the command “C:\Program Files\Microsoft SQL Server\100\Tools\Binn\SQLCMD.exe” and passing the following parameters:
-i %system.teamcity.build.checkoutDir%/InitialiseData/Clean.sql
-S (local)
-d AutoDeploy
As with the previous builds, the build agent in this case has the necessary rights over the SQL Server so everything just works. It obviously also requires the sqlcmd utility to be installed. Check out the command syntax in the earlier link if you actually need to pass credentials over.
Obviously this is very much an “only on demand” build but it now means we can automate a totally clean state of the database each time I want to reset the target environment. Or alternatively, I could trigger it off a successful deployment to an integration environment before running automated tests. Very cool.
Testing against large data volumes
A couple of weeks back I was involved in a project where a release was made to the production environment which resulted in a sudden and unexpected spate of SQL timeouts. After looking at the offending stored procedure, it didn’t take long to realise it was never going to play nice with large volumes of data. But how could this be? It worked fine on the developer’s machine and there were no findings during user acceptance testing, what was going on?
The simple difference between these environments was the volume of data. Even though the test environment had previously been seeded with a large number of records, the production environment exceeded this by an order of magnitude. And just before we go any further, it’s never ok to pull production data down into any other environment for the purpose of testing performance. There has to be a better way…
And here it is; Red Gate’s SQL Data Generator. This puppy can turn around and seed your enterprise grade database with 10 million realistic records in the blink of an eye. It’s absolutely perfect for initialising a DB with enough data to demonstrate performance well into the future growth cycle of the application.
How does it do this? There are some great demos on the Red Gate site which go into detail but just briefly, it looks at the column names and data types and then uses a combination of regexes and static data for things like cities and uses these to create a realistic set of data. You can also provide your own of each of these if you want to get a bit more specific (cities in China only, perhaps), and the whole thing is conscious of referential integrity constraints so that “CountryId” foreign key will always get a valid value based on the “Country” table records.
As with SQL Compare and Data Compare, we’re going to be executing this on the build server. However, we can’t just feed in a command line with some parameters; this one takes some configuring directly within the Data Generator app. It makes sense though; you could simply never pass the sort of configuration the tool needs to run successfully via the command line.
So it’s into the TeamCity server and we’ll fire up Data Compare. The project configuration is very simple and we’ll steer away from the other tabs for the moment:
Here’s where the magic happens; configuring the data generator:
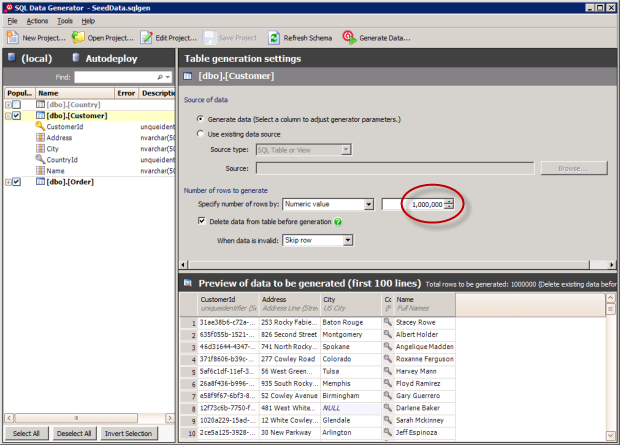
As you can see from the “Preview of data to be generated”, this is pretty realistic looking data. You’ll also see I’m going to generate one million records – I’m not one to do things by halves and to that effect I’m also going to generate two and a half million orders. Very cool.
Once this has been configured I’m going to save the solution file into a new “TestData” folder in the trunk of the repository and call it “Generate.sqlgen”. I’ll just check that folder out to a location on the build server and save the configuration there so it’s easy to come back to and reconfigure later on. The most important thing is that we need to get it committed back to VCS as this has now become an essential component of the project.
This activity doesn't have to be done on the build server; the project could just as easily be created on a PC. But of course this necessitates an additional license so assuming you’re happy to provide remote access to the build server – and this often won’t be the case – this makes things a little more cost effective.
I won’t go into the detail of every screen in the build (you’ve seen enough of that earlier on), but essentially this works in a near identical fashion to the earlier ones. Call it “Generate test data”, instruct the VCS checkout rule to grab the file from the “TestData” folder in the trunk and save it in a local path of the same name, then configure the build to run the “C:\Program Files\Red Gate\SQL Data Generator 1\SQLDataGenerator.exe” command.
The parameters are pretty basic for this one:
/project:%system.teamcity.build.checkoutDir%/TestData/Generate.sqlgen
/verbose
There are no artifacts to be generated and nothing else worth configuring for this build. All that’s left to do is to run it. Everything goes green and we get the following in the build log:
Start time: Tuesday, 8 February 2011 06:50:33 AM
End time: Tuesday, 8 February 2011 06:53:16 AM
[dbo].[Customer]
Rows inserted: 1000000
[dbo].[Order]
Rows inserted: 2500000
Have a good look at this – we just generated three and a half million records of test data in two and a half minutes. In a virtual machine running on a PC. Whoa. Is this for real?
SELECT COUNT() FROM dbo.[Customer]
SELECT COUNT() FROM dbo.[Order]
And we see:
- 1000000
- 2500000
That should last us for a while. So this is real-ish test data, generated on demand against a clean deployment by a single click of the “Run” button from a remote machine. Test data doesn’t get any easier than that.
Summary
Achieving a reliable, repeatable continuous integration build for the database was never going to be straight forward without investing in some tools. The fact that purely on its own merits, SQL Source Control stood out as the best way of getting the DB schema into Subversion – even before they added the static data capabilities – made the selection of the other Red Gate tools a very easy decision.
It’s a similar story with SQL Compare and Data Compare; I’ve used these for years (since 2004, by my records), and they’re quite simply the best damn thing you can do with your money if you’re regularly involved in deployments. The ability for these tools to integrate with SQL Source Control and run autonomously on the build server makes them an easy choice.
Purchased separately, the build server dependencies – SQL Compare, Data Compare and Data Generator – cost $1.5k. Spend that instead on the SQL Developer Bundle and you get a spare license of SQL Source Control (normally $300) and a few other bits as well (SQL Prompt is especially nice – decent intellisense for SSMS), that you can give to your favourite developer rather than buying a standalone license.
To be honest, the price is a bit inconsequential in the context of any rational look at what the tools are doing. Manual database migrations can be quite laborious, very error prone and extremely bad news when they go wrong. The ability to do all this automatically in a fraction of the time and in unison with web app deployment just by a single button click is absolute gold and in my humble opinion, worth every cent of the asking price.
Resources
- Evolutionary Database Design
- Continuous integration for databases using Red Gate SQL tools
- Continuous Integration (Martin Fowler)