A series of discussions last week got me around to talking about the right way to test a system against a realistic set of data. The problem is simply this: without data in the test environment which is representative of what you’ll end up with in the production environment, it’s very difficult to properly simulate the way the app will behave after it rolls out.
There are a whole bunch of counter-techniques for the empty database problem ranging from the tedious to the impractical to the downright ridiculous. And then there’s Red Gate’s SQL Data Generator, which is none of these. In fact it’s almost magical when you see it in action over your own data schema. Let’s take a closer look.
The patterns of insufficient test data
So what’s the problem? Well, there’s a couple of discrete challenges when suitable test data is not available, one of them being performance. Software has a funny habit of behaving differently once it starts dealing with decent volumes of data. It’s a common scene for a developer to begin scratching his head when faced with the lethargic performance of an application which has spent some time accruing transactional data. “It never did that under development or test.” A handful of records in your test environment versus a few million in production will do that.
Another issue is usability. One of the primary ideas of a test cycle is that it allows the app owner to experience what the software will be like once it rolls out. Many of the functions they need to perform in order to fully experience the product are dependent on the presence of data. A customer management app, for example, is going to be very hard to test without a good set of customer records.
Data generation anti-patterns
The issues above are not new, in fact they’re very well trodden paths. Thing is though, the way some folks deal with them is rather problematic. Here are some popular approaches which are ultimately all pretty flawed:
Manual creation: Using the app to organically create test data is just plain tedious. You’re inevitably going to either blow huge amounts of time or end up with an insufficient set of data to test against. Or both. This is simply not the smart approach.
Hand-crafted scripts: So why not just write some scripts to insert the required number of records? You’ve got two problems with this: Firstly, anything more than a very basic script becomes tedious. Have a half dozen tables with multiple columns and relational integrity considerations and there goes a significant amount of time. Secondly, it’s not reflective of real data. If you’re looping through and inserting a million “John Smith” records it’s not going to look right during testing and chances are the black magic within SQL Server’s indexing and query optimisation is not going to behave the way it would with real data.
Pulling a copy of production data: Don’t ever, ever, ever do this! Just don’t! Not only is there a huge confidentiality risk, there’s also something seriously wrong with the underlying app lifecycle if you’re able to readily pull production data backups into a test environment. It could also well mean that your test or development environments are beginning to create dependencies on a production state (i.e. key values). Just don’t do this, ok?
The SQL Data Generator solution
There’s a pattern with the Red Gate tools and I’m not just saying this because of the Friends of Red Gate thing:
- They’re extremely intuitive and easy to get up and running with fast.
- They take traditionally laborious tasks and automate them into near instantaneous processes.
- They’re entirely unobtrusive in the development process; they work with you rather than asking you to change the things you’re already comfortable with.
Moving on, we’re going to use SQL Data Generator (normally a $295 spend), to push a whole heap of data into your classic Northwind database. In particular, I want to focus on these four tables:

Why these four? Because they’re very atypical of many apps, they span a good range of both SQL data types and logical data values and there’s a bunch of relational integrity going on to make things interesting.
Out of the box, Northwind gives you 91 customers with 830 orders containing 2,155 order details across 77 products managed by 9 employees. Lightweights! Let’s turn this up by, oh, a factor of one thousand. Yep, 91,000 customers with 830,000 orders containing 2,155,000 order details across 77,000 products managed by 9,000 employees. That oughta do it.
In we go:

Project setup is a piece of cake; just point it at a server and choose a database:
We than land up on a screen consisting of three panels allowing us to configure the data generation. We could just generate everything right now but that would make for a very short blog post and not fully demonstrate the full power of the tool. Instead, let’s begin by deselecting the tables we don’t want to generate data for in the “Tables to populate” panel:

We’re getting little warning symbols against Customers and Employees as there are foreign key dependencies on these by tables not in the above batch. Consequently, deleting data from them might cause some dramas due to the referential integrity. Let’s take a closer look at the table generation settings and see how we can fix that up:
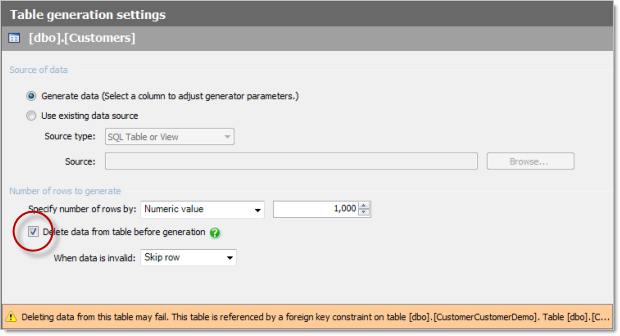
With those two tables not set to delete data before generation we won’t have any failed constraints to deal with. Our little yellow warning signs from earlier on now make a hasty retreat. The other thing we can do in the panel above is set the number of records we want generated so I’ll update these to the values I outlined earlier on.
Now let’s look at where the magic in SQL Data Generator lies – the process of actually creating data. For each different data type in the DB, the tool needs to generate a random set of data that is a realistic match for the context it’s going into. For example, here’s what we can expect in a column of type smallint:
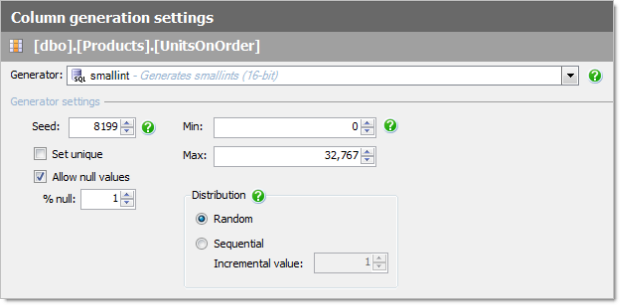
Vey self-explanatory and as you can see, we can do things like set ranges, allow nulls, force unique values or manipulate the randomness via seed or sequence. But it’s the string fields which get a bit more interesting. Let’s take a look at an address:
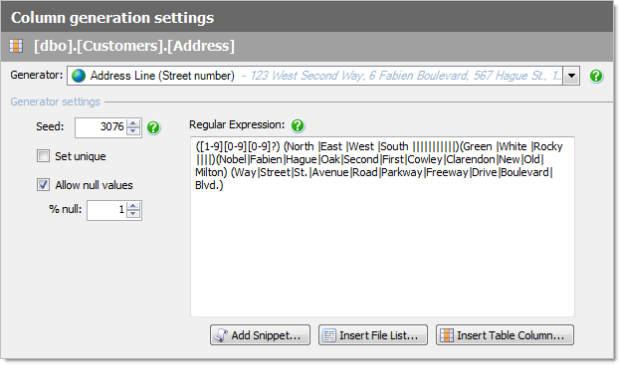
Ah, welcome to the joyless world of regular expressions! But it’s actually rather clever and just in case it looks like Latin to you, here’s the sort of data values this will create:
- 17 Rocky Oak Parkway
- 55 West Rocky Nobel Avenue
- 78 First Street
Here’s the cool bit about this: SQL Data Compare is looking at the name of the field and determining the correct type of natural data to insert. It’s not saying “Hey, this is a string type, let’s just throw characters at it”, it’s actually saying “Hey, this is an address, I know what an address looks like”.
Very smart, and of course you can always edit the expression yourself to do things like put unit numbers in front of some street addresses or add to the road types. But regexes aren’t the only way of getting data into a text field:
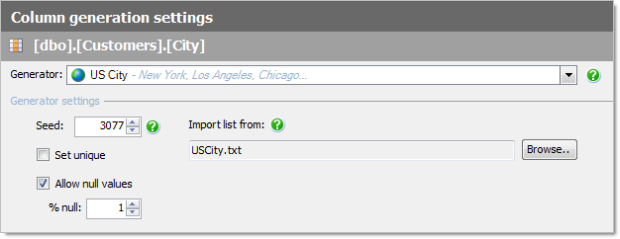
The neat thing about the city approach above is that we can always just feed in our own list of values. For example, I can go off to the Australia Post website and grab a list of all our local towns and suburbs and use that instead. The same approach can be taken with things like people names – either you take a default set of values or feed in a list of your own.
The other thing you can always do is override the default field selection and choose another natural value type from the generator list:
Let’s look at one more very cool feature before generating our data; photos. The employees table has a field named “Photo” of type “image” which is enough for SQL Data Generator to actually pull out a whole heap of image data:
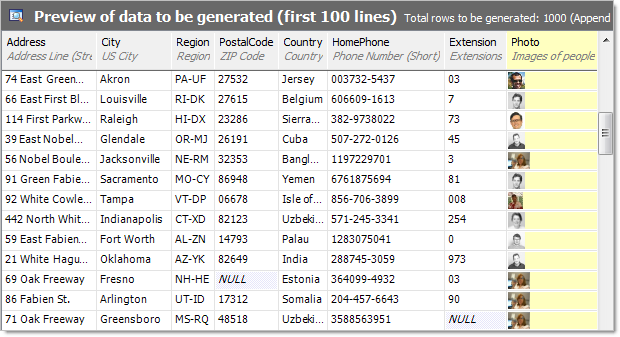
Now that’s cool – try manually scripting that yourself! Real photos of people in nice little binary blobs ready to drop right into the record. What we’re looking at above is the data preview panel which is the best way to see what these guys are going to look like. Enough of this though, let’s build some data.
Hit “Generate…” and here’s what’s going to happen:
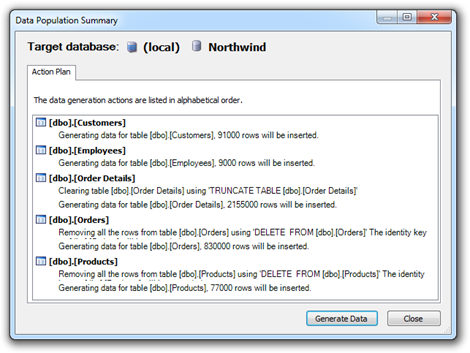
Looks good to me, fire away:
Five and a bit minutes later:
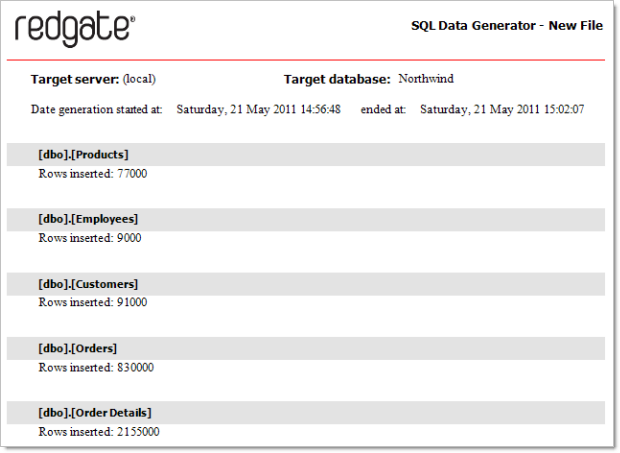
Wow – that’s impressive – just over 3 million records of realistic test data (including 9,000 images) inserted with a grand manual labour total of about 2 minutes and then another 5 of automation while I went for a coffee. Let’s grab some employee records and check it really happened:
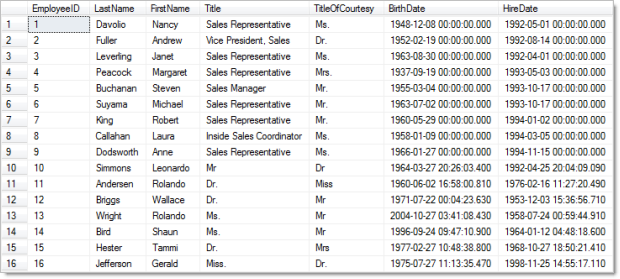
Excellent, we can see the first nine records that Northwind already had then a whole bunch of new ones after that. The interesting thing is that you can see a change in pattern from record ten onwards where Northwind’s definition of a title is obviously a little different to Red Gate’s. Of course if this was important we could always just create a text file of job titles and feed it into the title field.
The other thing that appears a little odd is the records where the hire date is earlier than the birth date. Whilst we might have a logical association between the fields and know that this can’t be physically possible, there’s no way of the tool knowing this automatically nor is there a way to define cross-column rules. The best we could do is define an acceptable range for both dates so that they wouldn’t overlap. But seriously though, that’s not going to add a lot of value to the objective of generating test data.
But wait, there’s more!
I’ve actually written about SQL Data Generator in the past (albeit very briefly) back in Automated database releases with TeamCity and Red Gate. What I did in that post was automate the entire release process of both schema and data then at the very end of it I added a twist by inserting a whole bunch of generated data.
You see after going through the configuration process you’ve just read about, SQL Data Generator lets you save a project file which allows all your configuration to be persisted. This is just a little XML file with a .sqlgen extension that you can drop into your favourite version control system. Couple that with the ability to run SQL Data Generator unattended from the command line and you’ve now got yourself a nice little automation process from your build server.
Summary
Obviously I’m pretty ecstatic about this tool because like most other Red Gate products its taken something that can be tedious, error prone, insecure and downright painful and solved it in a few click. I’m a big fan of throwing money at a problem if it makes a good business case and when it comes to either investing huge amounts of time performing a tedious task, not testing against realistic data at all or spending $295, it’s an easy case to make.