So the Sony saga continues. As if the whole thing about 77 million breached PlayStation Network accounts wasn’t bad enough, numerous other security breaches in other Sony services have followed in the ensuing weeks, most recently with SonyPictures.com.
As bad guys often like to do, the culprits quickly stood up and put their handiwork on show. This time around it was a group going by the name of LulzSec. Here’s the interesting bit:
Sony stored over 1,000,000 passwords of its customers in plaintext
Well actually, the really interesting bit is that they created a torrent of some of the breached accounts so that anyone could go and grab a copy. Ouch. Remember these are innocent customers’ usernames and passwords so we’re talking pretty serious data here. There’s no need to delve into everything Sony did wrong here, that’s both mostly obvious and not the objective of this post.
I thought it would be interesting to take a look at password practices from a real data source. I spend a bit of time writing about how people and software manage passwords and often talk about things like entropy and reuse, but are these really discussion worthy topics? I mean do people generally get passwords right anyway and regularly use long, random, unique strings? We’ve got the data – let’s find out.
What’s in the torrent
The Sony Pictures torrent contains a number of text files with breached information and a few instructions:

The interesting bits are in the “Sony Pictures” folder and in particular, three files with a whole bunch of accounts in them:

After a little bit of cleansing, de-duping and an import into SQL Server for analysis, we end up with a total of 37,608 accounts. The LulzSec post earlier on did mention this was only a subset of the million they managed to obtain but it should be sufficient for our purposes here today.
Analysis
Here’s what I’m really interested in:
- Length
- Variety of character types
- Randomness
- Uniqueness
These are pretty well accepted measures for password entropy and the more you have of each, the better. Preferably heaps of all of them.
Length
Firstly there’s length; the accepted principle is that as length increases, as does entropy. Longer password = stronger password (all things else being equal). How long is long enough? Well, part of the problem is that there’s no consensus and you end up with all sorts of opinions on the subject. Considering the usability versus security balance, around eight characters plus is a pretty generally accepted yardstick. Let’s see the Sony breakdown:
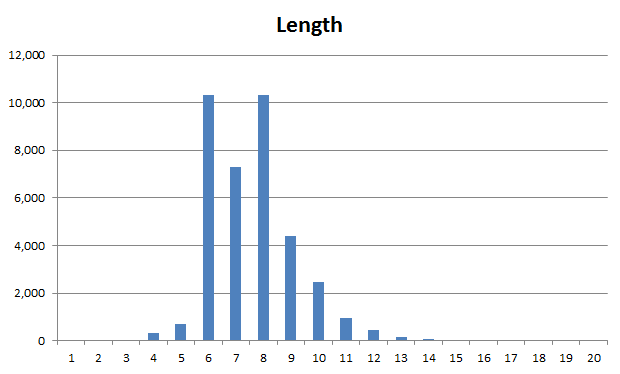
We end up with 93% of accounts being between 6 and 10 characters long which is pretty predictable. Bang on 50% of these are less than eight characters. It’s interesting that seven character long passwords are a bit of an outlier – odd number discrimination, perhaps?
I ended up grouping the instances of 20 or more characters together – there are literally only a small handful of them. In fact there’s really only a handful from the teens onwards so what we’d consider is a relatively secure length really just doesn’t feature.
Character types
Length only gives us so much, what’s really important is the diversity within that length. Let’s take a look at character types and we’ll categorise them as follows:
- Numbers
- Uppercase
- Lowercase
- Everything else
Again, we’ve got this issue of usability and security to consider but good practice would normally be considered as having three or more character types. Let’s see what we’ve got:
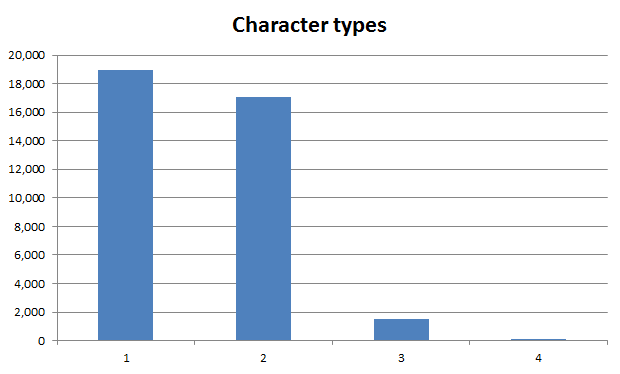
Or put another way, only 4% of passwords had three or more character types. But it’s the spread of character types which is also interesting, particularly when only a single type is used:

In short, half of the passwords had only one character type and nine out of ten of those where all lowercase. But the really startling bit is the use of non-alphanumeric or characters:

Yep, less than 1% of passwords contained a non-alphanumeric character. Interestingly, this also reconciles with the analysis done on the Gawker database a little while back.
Randomness
So how about randomness? Well, one way to look at this is how many of the passwords are identical. The top 25 were:
seinfeld, password, winner, 123456, purple, sweeps, contest, princess, maggie, 9452, peanut, shadow, ginger, michael, buster, sunshine, tigger, cookie, george, summer, taylor, bosco, abc123, ashley, bailey
Many of the usual culprits are in there; “password”, “123456” and “abc123”. We saw all these back in the top 25 from the Gawker breach. We also see lots of passwords related to the fact this database was apparently related to a competition: “winner”, “sweeps” and “contest”. A few of these look very specific (9452, for example), but there may have been context to this in the signup process which lead multiple people to choose the same password.
However in the grand scheme of things, there weren’t a whole lot of instances of multiple people choosing the same password, in fact the 25 above boiled down to only 2.5%. Furthermore, 80% of passwords actually only occurred once so whilst poor password entropy is looking rampant, most people are making these poor choices independently and achieving different results.
Another way of assessing the randomness is to compare the passwords to a password dictionary. Now this doesn’t necessarily mean an English dictionary in the way we know it, rather it’s a collection of words which may be used as passwords so you’ll get things like obfuscated characters and letter / number combinations. I’ll use this one which has about 1.7 million entries. Let’s see how many of the Sony passwords are in there:

So more than one third of passwords conform to a relatively predictable pattern. That’s not to say they’re not long enough or don’t contain sufficient character types, in fact the passwords “1qazZAQ!” and “dallascowboys” were both matched so you’ve got four character types (even with a special character) and then a 13 character long password respectively. The thing is that they’re simply not random – they’ve obviously made appearances in password databases before.
Uniqueness
This is the one that gets really interesting as it asks the question “are people creating unique passwords across multiple accounts?” The thing about this latest Sony exploit is that it included data from multiple apparently independent locations within the organisation and as we saw earlier on, the dump LulzSec provided consists of several different data sources.
Of particular interest in those data sources are the “Beauty” and “Delboca” files as they contain almost all the accounts with a pretty even split between them. They also contain well over 2,000 accounts with the same email address, i.e. someone has registered on both databases.
So how rampant is password reuse between these two systems? Let’s take a look:

92% of passwords were reused across both systems. That’s a pretty damning indictment of the whole “unique password” mantra. Is the situation really this bad? Or are the figures skewed by folks perhaps thinking “Sony is Sony” and being a little relaxed with their reuse?
Let’s make it really interesting and compare accounts against Gawker. The internet being what it is there will always be the full Gawker database floating around out there and a quick Google search easily discovers live torrents. Gnosis (the group behind the Gawker breach) was a bit more generous than LulzSec and provided over 188,000 accounts for us to take a look at.
Although there were only 88 email addresses found in common with Sony (I had thought it might be a bit higher but then again, they’re pretty independent fields), the results are still very interesting:

Two thirds of people with accounts at both Sony and Gawker reused their passwords. Now I’m not sure how much crossover there was timeframe wise in terms of when the Gawker accounts were created versus when the Sony ones were. It’s quite possible the Sony accounts came after the Gawker breach (remember this was six months ago now), and people got a little wise to the non-unique risk. But whichever way you look at it, there’s an awful lot of reuse going on here.
What really strikes me in this case is that between these two systems we have a couple of hundred thousand email addresses, usernames (the Gawker dump included these) and passwords. Based on the finding above, there’s a statistically good chance that the majority of them will work with other websites. How many Gmail or eBay or Facebook accounts are we holding the keys to here? And of course “we” is a bit misleading because anyone can grab these off the net right now. Scary stuff.
Putting it in a exploit context
When an entire database is compromised and all the passwords are just sitting there in plain text, the only thing saving customers of the service is their password uniqueness. Forget about rainbow tables and brute force – we’ll come back to that – the one thing which stops the problem becoming any worse for them is that it’s the only place those credentials appear. Of course we know that both from the findings above and many other online examples, password reuse is the norm rather than the exception.
But what if the passwords in the database were hashed? Not even salted, just hashed? How vulnerable would the passwords have been to a garden variety rainbow attack? It’s pretty easy to get your hands on a rainbow table of hashed passwords containing between one and nine lowercase and numeric characters (RainbowCrack is a good place to start), so how many of the Sony passwords would easily fall?

82% of passwords would easily fall to a basic rainbow table attack. Not good, but you can see why the rainbow table approach can be so effective, not so much because of its ability to make smart use of the time-memory trade-off scenario, but simply because it only needs to work against a narrow character set of very limited length to achieve a high success rate.
And if the passwords were salted before the hash is applied? Well, more than a third of the passwords were easily found in a common dictionary so it’s just a matter of having the compute power to brute force them and repeat the salt plus hash process. It may not be a trivial exercise, but there’s a very high probability of a significant portion of the passwords being exposed.
Summary
None of this is overly surprising, although it remains alarming. We know passwords are too short, too simple, too predictable and too much like the other ones the individual has created in other locations. The bit which did take me back a bit was the extent to which passwords conformed to very predictable patterns, namely only using alphanumeric character, being 10 characters or less and having a much better than average chance of being the same as other passwords the user has created on totally independent systems.
Sony has clearly screwed up big time here, no doubt. The usual process with these exploits is to berate the responsible organisation for only using MD5 or because they didn’t salt the password before hashing, but to not even attempt to obfuscate passwords and simply store them in the clear? Wow.
But the bigger story here, at least to my eye, is that users continue to apply lousy password practices. Sony’s breach is Sony’s fault, no doubt, but a whole bunch of people have made the situation far worse than it needs to be through reuse. Next week when another Sony database is exposed (it’s a pretty safe bet based on recent form), even if an attempt has been made to secure passwords, there’s a damn good chance a significant portion of them will be exposed anyway. And that is simply the fault of the end users.
Conclusion? Well, I’ll simply draw back to a previous post and say it again: The only secure password is the one you can’t remember.
Update, 7 June 2011:
I’ve cleaned up a couple of the graphs and would also like to clarify some of the points coming through in the comments:
- There does not appear to have been either length or character type restrictions on the databases. There are lengths ranging from 1 to 35 characters and (occasional) uses of non-alphanumerics.
- As far as I know, this database is not directly related to PSN. Sony is a huge media network and LulzSec claims this came from SonyPictures.com. There is no evidence to suggest that these passwords were created using a handheld game console controller.