I often write up analyses of the passwords disclosed in website breaches. For example, there was A brief Sony password analysis back in mid-2011 and then our local Aussie ABC earlier this year where I talked about Lousy ABC cryptography cracked in seconds as Aussie passwords are exposed. I wrote a number of other pieces looking specifically at the nature of the data exposed in individual sites, but what I really found interesting was when I started comparing breaches.
In the middle of last year I wrote What do Sony and Yahoo! have in common? Passwords! and found that 59% of people with accounts in both sources used the same password. Then just last month when I wrote about “the mother of all breaches” in Adobe credentials and the serious insecurity of password hints, I found that many of the accounts from the Sony breach were also in Adobe’s. In that case I explained how this put personal information at serious risk as the unencrypted password hints in Adobe’s breach often had the answers in the unencrypted Sony passwords!
As I analysed various breaches I kept finding user accounts that were also disclosed in other attacks – people were having their accounts pwned over and over again. So I built this:

The site is now up and public at haveibeenpwned.com so let me share what it’s all about.
About HIBP
Just after the Adobe breach, a number of sites started popping up that let you search through the breach to see if your email address (and consequently your password), was leaked. For example there was this one by Ilias Ismanalijev, here’s another by Lucb1e and even LastPass got on the bandwagon with this one. When I used the tool to check my accounts, I found both my personal and work accounts contained in the breach. I had absolutely no idea why!
The most likely answer is that I did indeed create accounts on Adobe, perhaps as far back as in the days when I was using Dreamweaver to build classic ASP whilst it was still owned by Macromedia. The point is that these accounts had been floating around for so long that by the time a breach actually occurred I had no idea that my account had been compromised because the site was simply no longer on my radar.
But of course Adobe is not the only searchable breach online, there’s also one for Gawker, another for LinkedIn passwords (emails and usernames weren't disclosed) and so on and so forth. Problem is, there’s not a tool to search across multiple breaches, at least not that I’ve found which is why I’ve built haveibeenpwned.com:
Enter your email address and go – any of the sites the address appears breached on will return a result with an overview of what happened to them. Here’s an example:
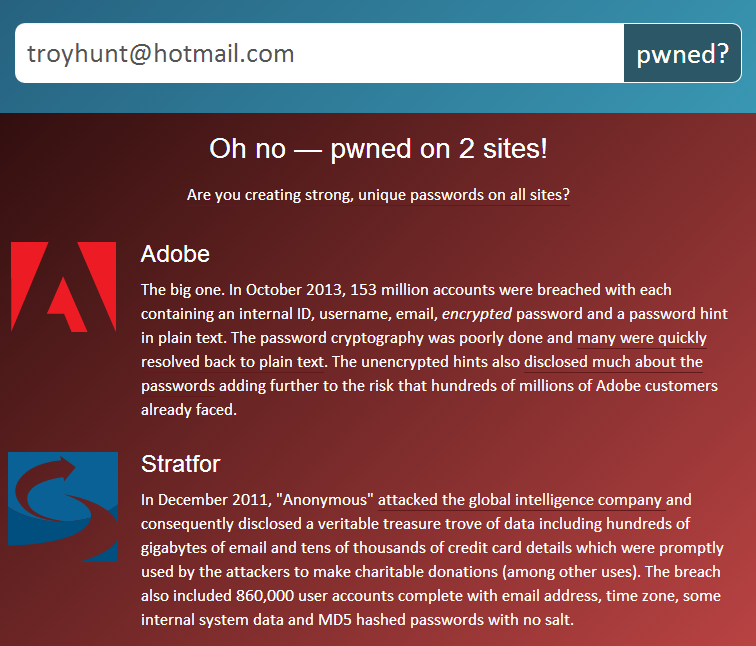
As I mentioned earlier, my email address was in the Adobe breach. Fortunately it wasn’t in any of the others so I’ve just added in Stratfor for illustrative purposes.
As you’ll see in the footer of the site, there’s rather a broad collection of accounts – over 154 million as of today – and they break down like this:
- 152,445,165 Adobe accounts
- 859,777 Stratfor accounts
- 532,659 Gawker accounts
- 453,427 Yahoo! accounts
- 37,103 Sony accounts
Despite the lowball reports of “only” 38 million, the Adobe dump did indeed have more than 152 million unique email addresses in it which is obviously a staggeringly high figure (there’s some contention as to whether an “account” is only one being actively used which may account for the discrepancy). As significant as the likes of the Stratfor breach appeared at the time (and certainly it had a serious impact on them), it was a “mere” 860 thousand odd accounts and the others less again. Even so, there’s a lot of commonality across the victims of the breaches.
The prevalence of multiple breaches by user
Importing the data – particularly the 153 million Adobe records – wasn’t a small task, at least not to get it into the structure I wanted. I’ll write more about that in the next day or two in terms of the underlying architecture, but the way I approached it was that I imported the Adobe data first and then for each subsequent breach either added new addresses or updated the existing address information about the subsequent breaches on the same account.
When I added the Stratfor breach to the existing Adobe records, 16% of the email addresses were already in the system. I moved onto Sony and 17% of them were already there. Yahoo! was 22%. Whilst not the chronological order in which the breaches occurred, what this demonstrated is that subsequent data sets showed a high correlation between new breach data and existing records in the system and that’s the very reason why I created this site.
Entering the era of breach data reuse
One of the things I noticed with the Adobe breach that I haven’t seen in previous cases was other companies notifying their users that their Adobe account had been breached. Not just one or two companies, but many of them. For example, Facebook did this and actually matched breached credentials with the ones they had on file:
Facebook users who used the same email and password combinations at both Facebook and Adobe’s site are being asked to change their password and to answer some additional security questions.
I wasn’t notified by Facebook (it’s no surprise that I don’t reuse credentials!), but I did receive a notification from Evernote purely because my email address was the same on both systems. After I wrote about the Adobe analysis, I was also contacted with requests for help in generating similar notifications for other purposes.
The point is that analysing breach data appears to be becoming mainstream. Arguably the sheer volume of the Adobe breach was the catalyst, but I do find it interesting how illegally obtained data now well and truly in the public domain is being used for constructive purposes. My hope is that HIBP can continue with that trend.
Future breaches and roadmaps
Clearly we haven’t seen the last of the data breaches, of that there can be no doubt. Now that I have a platform on which to build I’ll be able to rapidly integrate future breaches and make them quickly searchable by people who may have been impacted. It’s a bit of an unfair game at the moment – attackers and others wishing to use data breaches for malicious purposes can very quickly obtain and analyse the data but your average consumer has no feasible way of pulling gigabytes of gzipped accounts from a torrent and discovering whether they’ve been compromised or not.
Of course the other thing is that I’ve only got five data breaches here and there are many more out there which I’m yet to integrate. Some of them aren’t suitable (LinkedIn only contained passwords and not email addresses), but if there are others you’re aware of that are now public, please let me know. No, don’t go and breach a system in order to contribute to this project!
The ability to rapidly integrate future breaches into a common location opens up a range of other opportunities to help consumers deal with account compromises in the future. I won’t go into detail now, but depending on how subsequent breaches pan out there are a number of ways HIBP can help people deal with compromised accounts early rather than waiting until they’re potentially taken advantage of.
Other miscellaneous facts:
Passwords: I’m not storing them. Nada. Zip. I just don’t need them and frankly, I don’t want the responsibility either. This is all about raising awareness of the breadth of breaches.
Windows Azure: This wasn’t entirely an exercise to build a service, it was a great opportunity to test out some Windows Azure features I really wanted to give a good workout. I’m enormously happy with the result and I’m drafting up a blog with the technical details that I’ll push out shortly.
Internet Explorer 8: Yeah, sorry guys. This browser accounts for 4% of traffic to troyhunt.com, has absolutely no HTML 5 support and is well and truly into its impending crisis and ultimate obliteration. I simply didn’t have the time to make things play nice in IE8 and I also didn’t want to add any bloat to the site to cater for such a small, declining audience. Having said that, it will work – you can discover if an account was in a breach, it just won’t be a first class experience. Or second class. Ok so it’s a visual nightmare but it can still perform the key function.
No bloat: The upside to no IE8 support is that this site is very, very light! There’s only just over 100kb of content downloaded over 3 requests required to make it run (another 50 odd kb and 6 requests for font-awesome and the SVG logos at the bottom of the page). I could take this down further by ditching jQuery and the full Bootstrap JS but we’re talking small kb numbers that are already bundled, minified and gzipped.
Massively fast: I’ll talk about this in the follow-up post about the technology, but querying those 154 million records is taking about 4ms. In fact the querying and HTTP request was going too fast and I had to slow things down in order to properly show the animation when you get search results.
Email validation: You can search for a@a and HIBP will give it a go. As I wrote a couple of weeks ago when I started this project, email validation is a nightmare. There’ll be a small number of junk addresses in the system and indeed you can search for seemingly invalid addresses but better to be too liberal than too strict. The validation goes like this: got an @ symbol and stuff either side of it? Right, let me check the DB for you!