
I’m one of these people that must learn by doing. Yes, I’m sure all those demos look very flashy and the code appears awesome, but unless I can do it myself then I have trouble really buying into it. And I really want to buy into Azure because frankly, it’s freakin’ awesome.
This is not a “yeah but you’re an MVP so you’ve gotta say that / you’re predispositioned to say that / you’re getting kickbacks from Ballmer”. I don’t, I’m not and I wish!
As many of you will know by now, yesterday I launched Have I been pwned? (HIBP) which as I briefly mentioned in that blog post, runs on Windows Azure. Now I’ve run stuff on Azure before, but it’s usually been the classic website and database model translated to the Azure paradigm rather than using the innovative cloud services that Azure does well.
When I came to build HIBP, I had a challenge: How do I make querying 154 million email addresses as fast as possible? Doing just about anything with the data in SQL Server was painfully slow to the extent that I ended up creating a 56GB of RAM Windows Azure SQL Server VM just to analyse it in order to prepare the info for the post I wrote on the insecurity of password hints. Plus, of course, the data will grow – more pwning of sites will happen and sooner or later there’ll be another “Adobe” and we’ll be looking at 300M records that need to be queried.
The answer was Azure Table Storage and as it turns out, it totally rocks.
Azure table storage – the good, the bad and the awesome
“We need a database therefore we need SQL Server.” How many times have you heard this? This is so often the default position for people wanting to persist data on the server and as the old adage goes, this is the hammer to every database requirement which then becomes the nail. SQL Server has simply become “the standard” for many people.
SQL Server is a beast. It does a lot. If in doubt, take a look at the feature comparison and ask yourself how much of this you actually understand. I’ve been building software on it for 15 years and there’s a heap of stuff there I don’t use / understand / can even begin to comprehend. It’s awesome at what it does, but it always does more than I actually need.
Azure Table Storage is simple, at least relatively speaking. You have a table, it’s partitioned, it has rows. You put stuff into that table then you query is back out, usually by referencing the partition and row keys. That’s obviously a simplistic view, things are better explained by Julie Lerman (a proper database person!) in her post on Windows Azure Table Storage – Not Your Father’s Database.
One of the things that attracted me to Table Storage is that it’s not constrained to a server or a VM or any logical construct that’s governed by finite resources (at least not “finite” within a reasonable definition), rather it’s a service. You don’t pay for CPU and RAM or put it on a particular server, you pay for the number of transactions and the amount of storage you need:

In other words, if I want 100GB of storage and I want to hit it 10 million times, it’ll cost me $8 a month. Eight. Two cappuccinos at my local cafe. Compare this to SQL Azure which whilst very good for all the same cloudy reasons (fully managed service, available and scalable on demand, etc.), it costs a hell of a lot more:
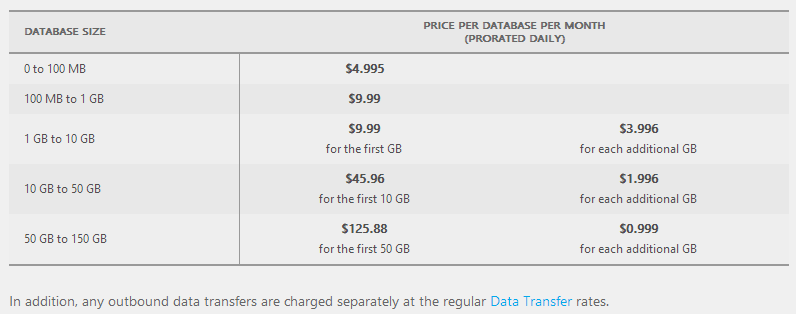
That’s $176 a month for the same volume of data and whilst arguably that’s actually a very good deal for a fully managed service for the behemoth that is SQL Server (or at least Azure’s flavour of it), it’s also 22 times more expensive. Of course it’s not an apples and apples comparison; do take a look at Windows Azure Table Storage and Windows Azure SQL Database - Compared and Contrasted for some more perspective, but in my case I only need Table Storage anyway.
So what’s the “bad” bit? It’s something new to learn, a “foreign entity” to most people, if you like. It has it’s own idiosyncrasies, quite different ways of working with data and interacting with the system and you can’t SELECT * FROM Foo. But it’s easy and it is massively impressive and that’s what I want to walk you through here now.
Provisioning the storage and querying the data
Let’s jump right in and I’ll assume you already have an Azure account and know how to find the portal at https://manage.windowsazure.com
We’ll create a new service and it’s simply going to be a storage account. Unsurprisingly, mine is called “haveibeenpwned” and it’s sitting over on the West Coast of the US (I figured that’s a reasonably central location for the audience):
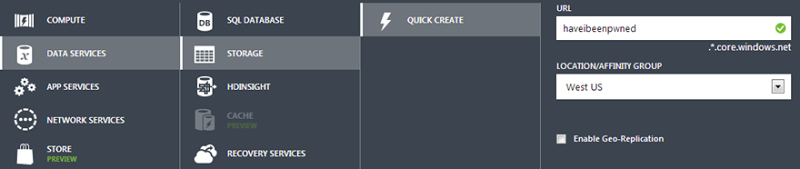
It should go without saying, but you want the storage account located in the same location as where you’ll be putting the things that use it which is predominantly the website in front of it and as you’ll see soon, a VM as well. Once that’s provisioned you’ll find it listed under “Storage” in the portal:
Now, before we can do anything with it we need to connect to it and for that we’ll need an access key. Think of it like the credentials for the account so let’s hit the “MANAGE ACCESS KEYS” icon:
Clearly I’ve obfuscated the keys, but you get the idea. Right, so this is everything we need to connect to Azure Table Storage, now we can just jump into SQL Server Management Studio and… oh yeah, no SQL!
We’ll be accessing data programmatically later on, but for now I just want to browse through it and for that I’ll grab a third party tool. By far the most popular is the Azure Storage Explorer which you can grab for free over on CodePlex. Fire that guy up and you have this:
Let’s now add the account from above and use a secure connection:
And we see… not very much:
We’ll come back to the explorer later on, first we need to understand what those “Storage Type” buttons means and for that we need to talk about what you get in a storage account.
Blobs, queues and tables
In days gone by, binary data loaded into a website (such as images in a content management system) would be stored either on the file system in IIS or within SQL Server. Both options cause problems of different natures and varying degrees. In Azure, you’d load it into blob storage and that’s one of the storage types available. There are other uses for blob storage as well but there’s no need to go into that here.
Another storage type is “queues” which are essentially just message queues. They’re very awesome and serve a very valuable role in providing asynchronicity between system components. Again, won’t go into it here but read up on How to use the Queue Storage Service if it sounds interesting.
And finally there’s Table Storage which is obviously the focus of this post. The main point I wanted to make was that these three paradigms all exist within each and every storage account whether you elect to use them or not.
Moving forward with tables, you can read the long version at How to use the Table Storage Service (and I strongly suggest you do if you’re actually going to use the service), but for now here’s the succinct version:
One storage account can have many tables.
Each table has many partitions.
Each partition has many rows.
Each row has a partition key, a row key and a timestamp.
You store an entity in the row that inherits from Microsoft.WindowsAzure.Storage.Table.TableEntity.
You create a partition and a row by inserting an entity with a partition key and a row key.
You retrieve a row by searching with the partition and row key and casting the result back to the entity type.
That it in a nutshell and it’s not even the simplistic version – that’s just how it works. There are features and nuances and other things you can do with it but that’s the bulk of it and it’s all I really needed in order to build HIBP. I’m going to step into code shortly but firstly we need to talk about partition design for my particular use case.
Designing the table partitions for HIBP
Conceptually, partitions are not that different to the alphabetised sections of a phonebook (remember those paper ones they used to dump on your doorstep?) Rather than just chucking all the numbers randomly into the book, they’re nicely distributed into 26 different “partitions” (A-Z) then of course each person is neatly ordered alphabetically within there. It does wonderful things in terms of the time is takes to actually find what you need.
In Azure Table Storage, partitions can have a big impact on performance as Julie explains in the earlier mentioned post:
Windows Azure Tables use keys that enable efficient querying, and you can employ one—the PartitionKey—for load balancing when the table service decides it’s time to spread your table over multiple servers.
How you structure your partitions is very dependent on how you want to query your data so let’s touch on that for a moment. Here’s how HIBP is queried by users:
As it turns out, an email address has an organic structure that lends itself very well to being segmented into partitions and rows. Take foo@bar.com – the domain is the partition key and the alias is the row key. By creating a partition for “bar.com” we can make the search for “foo” massively fast as there are only a small portion of the total records in the data set, at least compared to the number of overall records.
Obviously some partitions are going to be very large. In the Adobe breach, there were more than 32 million “hotmail.com” accounts so that’s going to be a big one. A small company with their own domain and only a few people caught up in a breach might just have a few addresses and a very small partition. That doesn’t mean the Hotmail partition will be slow, far from it and I’ll come back to that later on. For now though, let’s move onto the code.
Inserting breach data into Table Storage
Let’s do the “Hello World” of Table Storage using the HIBP data structure. Firstly, we need one little NuGet package and that’s the Windows Azure Storage libraries. Be careful though – don’t take the current version which is 3.0.0. I’ll explain why later when I talk about the emulator (and do check the currency of this statement if you’re reading this in the future), instead run this from the Library Package Manager command line:
Install-Package WindowsAzure.Storage -Version 2.1.0.4
Now we’ll use that access key from earlier on and whack it into a connection string and it looks just like this:
<connectionStrings> <add name="StorageConnectionString"
connectionString="DefaultEndpointsProtocol=https;AccountName=haveibeenpwned;AccountKey=mykey" /> </connectionStrings>
Just like a SQL connection string (kinda). Note the endpoint protocol – you can go HTTP or HTTPS. Clearly the secure option is preferable.
Into the code itself, we begin by getting a reference to the storage instance:
var connString = ConfigurationManager.ConnectionStrings["StorageConnectionString"].ConnectionString; var storageAccount = CloudStorageAccount.Parse(connString);
Now we’ll get a reference to the table within that storage instance and if it doesn’t already exist, we’ll just create it (obviously just a first-run thing):
var tableClient = storageAccount.CreateCloudTableClient(); var table = tableClient.GetTableReference("BreachedAccount"); table.CreateIfNotExists();
Before we can start chucking stuff in there, we need that entity I mentioned earlier so let’s create a BreachedAccount that inherits from TableEntity.
public class BreachedAccount : TableEntity { public BreachedAccount() { } public string Websites { get; set; } }
Notice how we haven’t created partition or row keys? They’re inherited from the TableEntity and what it means is that we can now do this:
var breachedAccount = new BreachedAccount { PartitionKey = "bar.com", RowKey = "foo", Websites = "Adobe;Stratfor" };
Obviously the websites are just semicolon delimited – nothing fancy (in my case I then split this back into a string array later on). Anyway, now we can just save it:
var insertOperation = TableOperation.Insert(breachedAccount); table.Execute(insertOperation);
And that’s it, we’re done! Now we can flick back into the Azure Storage Explorer, hit the “Tables” button in the top right, select the “BreachedAccount” table from the left and then “Query” it:
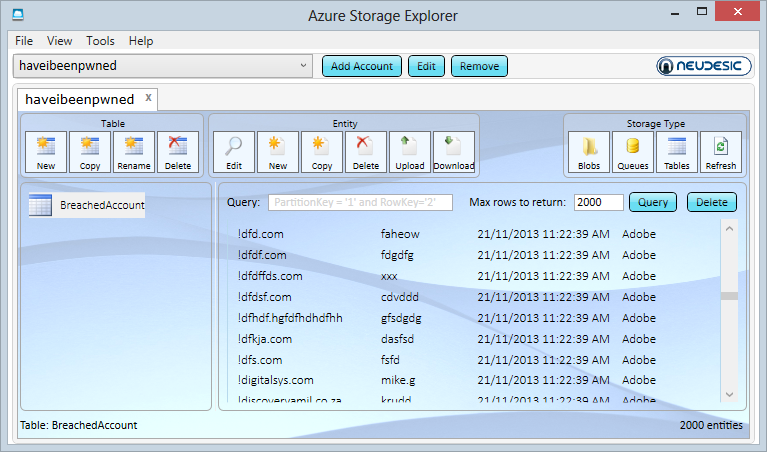
We have data! This is a current live view of what’s in HIBP and I’ve scrolled down to the section with a bunch of what are probably junk accounts (don’t get me started on email address validation again). You can now see the partition key, row key, timestamp and “Websites”. If we were to add another attribute to the BreachedAccount entity then we’ll see that too even though we already have data there conforming to a different schema. That’s the neat thing about many NoSQL database implementations in that you’re not constrained to a single schema within the one container.
It’d be remiss of me not to mention that you can also view this data directly from within Visual Studio in the Server Explorer. The updates to this pushed out in version 2.2 of the Windows Azure SDK six weeks ago make it an absolute cinch in either VS2012 or 2013:
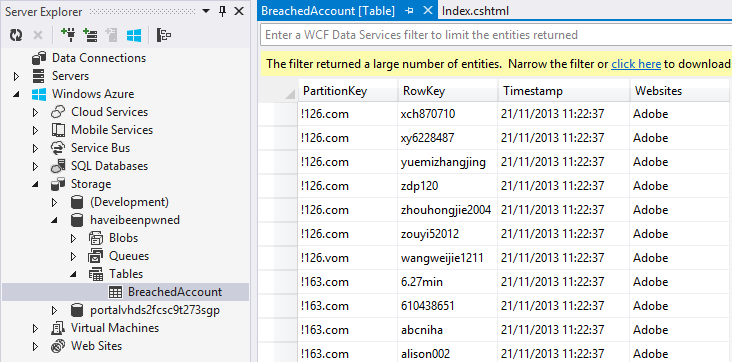
So we’re done, right? Kinda – I don’t really want to do 154 million individual inserts as each connection does have some overhead. What I want to do is batch it and that looks more like this:
var batch = new TableBatchOperation(); batch.Insert(breachedAccount1); batch.Insert(breachedAccount2); batch.Insert(breachedAccount3); table.ExecuteBatch(batch);
Batching is about more than just committing a bunch of rows at one time, it also has an impact on cost. Remember how Azure Table Storage charges you $0.0000001 per “transaction”? I’m not made of money so I want to bring that cost down a little and I can do this by batching because a batch is one transaction. However, there are some caveats.
Firstly, you can only batch records into the same partition. I can’t insert foo@bar.com and foo@fizz.com within the same batch. However, I can insert foo@bar.com and buzz@bar.com at the same time as I’m using the domain as the partition key. What this meant is that when I wrote the code to process the records I had to sort the data by domain so that I could keep all the records for the partition together and batch them. This makes sense in the context of Julie’s earlier comment about the partition being tied to a machine somewhere.
Secondly, you can only batch up to 100 rows at a time. Those 32 million Hotmail addresses? That’s 320,000 batches thank you very much. This meant my importer needed to not only enumerate through accounts ordered by domain, but each time it had a collection of 100 it needed it commit them before moving on. Per the previous point, it obviously also had to commit the batch as soon as it got to the next domain as it couldn’t commit to multiple partitions in the one batch.
With all that clear, all I had to do was create a text file with all the 153 million Adobe addresses broken down into alias and domain ordered by the latter then create a little console app to enumerate each row and batch as much as possible. Easy, right? Yes, but we’d be looking at millions of consecutive transactions sent across a high-latency connection – you know how far it is from Sydney to the West Coast of the US? Not only that, but even with low-latency this thing wouldn’t take minutes or hours or possibly even days – I needed more speed.
Turning the import script up to 11
There were two goals for getting this into Table Storage quickly:
- Decrease the latency
- Increase the asynchronicity
The first one is easy and it’s along the lines of what I touched on earlier in relation to when I used the chunky SQL Server VM – just provision a VM in Azure at the same location as the Table Storage and your latency comes down to next to nothing. Obviously I needed to copy the source data up and we’re looking at gigabytes of even compressed records here, but once that was done it was just a matter of running the console app in the VM and that’s the latency issue solved.
Asynchronicity was a bit tricker and I took two approaches. Firstly, we’re living in an era of Async Await so that was the first task (little async joke there!) and I tackled it by sending collections of 20,000 rows at a time to a process that then broke them into the appropriate batches (remember the batch constraints above), fires this off to a task and waited for them all to complete before grabbing the next 20,000. Yes, it meant at best there were 200 async tasks running (assuming optimal batches of 100 rows each), but it actually proved to be highly efficient. Maybe more or less would have been better, I don’t know, it just seemed like a reasonable number.
The other approach to asynchronicity was multi-threading and of course this is a different beast to the parallelism provided by Async Await. Now I could have been clever and done the threading within the console app, but I decided instead to take the poor man’s approach to multithreading and just spin up multiple instances of the console.
To do this I allowed it to be invoked with parameters stating the range of rows it should process – which row should it start at then which row should it finish on. The bottom line was that I could now run multiple instances of the importer with each asyncing batch commits across partitions. So how did it go? Rather well…
Importing 22,500 rows per second into Azure Table Storage
Up in the Azure VM now and I’m now importing the 153 million Adobe accounts with nine simultaneous instances of the importer (I chose nine because it looked nice on the screen!) each processing 17 million addresses and sending clusters of up to 20,000 domains at once to async tasks that then broke them into batches of 100 records each. It looked like this:
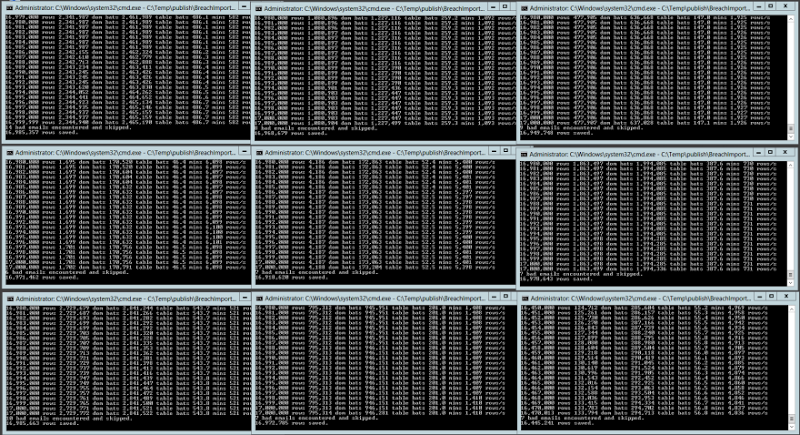
The max throughput I achieved with this in a single console instance was when all 17 million rows were processed in only 47 minutes – that’s a sustained average of over 6,000 rows per second for three quarters of an hour. Then again, the slowest was “only” 521 records per second which meant a 9 hour run time. Why the 12-fold difference in speed? If one chunk of 17 million rows had a heap of email on the same domain (gmail.com, hotmail.com, etc.) then you’d get a lot of very efficient batches. When you have lots of dispersed domains you end up with sub-optimal batches, in other words lots of batches with less than 100 rows. In fact that slowest instance committed nearly 3 million batches so had around 6 rows per batch whilst the fastest only committed just over 170,000 batches so it was almost perfectly optimised.
The bottom line is that if you combine the average speed of each of those nine instances, you end up with a sustained average of about 22,500 inserts per second. Of course this peak is only achieved when all instances are simultaneously running but IMHO, that’s a very impressive number when you consider that the process is reading the data out of a text file, doing some basic validation then inserting it into Table Storage. I honestly don’t know if you’d get that level of success with your average SQL Server instance. I’d be surprised.
Unsurprisingly, the VM did have to work rather hard when running the nine simultaneous importers:
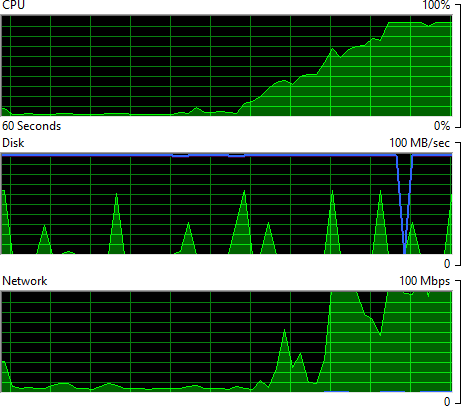
Oh – and this is an 8 core machine too! Mind you, it may be saying something about the efficiency of my code but somehow I don’t think it’s just that. What I find interesting with this is that the CPU is maxed and NIC is pumping out over 100Mbps so the machine is well and truly getting worked; what would the throughput do if I was running two VMs? Or five? Would we be looking at 100,000 rows per second? My inclination is to say “yes” given the way the Table Storage service is provisioned by spreading those partitions out across the Azure infrastructure. Assuming batches were being simultaneously committed across different partitions, we shouldn’t be IO bound on the storage side.
One issue I found was that I’d get to the end of an instance processing its 17 million records and the stats at the end would suggest it had only processed 99.7%+ of addresses. What the?! After a bunch of debugging I found that the async task I was firing off didn’t always start. Now keep in mind that I’m firing off a heap of these at once – at least 200 at once depending on the spread of domains and consequently partition keys – but I also found the same result when re-running and firing off only 5 tasks simultaneously (incidentally, this only increased the duration by about 25% – you can’t just infinitely fire off more async tasks and achieve a linear speed gain). But the results were also inconsistent insofar as there might be a 99.7% success rate on one run then a 99.8% on the next. I’m no expert on async, but my understanding is that there’s no guarantee all tasks will complete even when awaiting “WhenAll”. But in this case, it actually doesn’t matter too much if a small number of records don’t make it if the task doesn’t run, just to be sure though, I ran the whole process again. And again. And Again. Which brings me to the next point – idempotency:
Idempotence is the property of certain operations in mathematics and computer science, that can be applied multiple times without changing the result beyond the initial application.
I used very simple examples in the Table Storage code earlier on – just simple “Insert” statements. When I created the importer though, I ended up using InsertOrReplace which meant that I could run the same process over and over again. If it failed or I wasn’t confident all the tasks completed, I’d just give it another cycle and it wouldn’t break when the data already existed.
Now of course all of this so far has just been about inserting the Adobe data and whilst it’s the big one, it’s also the easiest one insofar as all I had to do was insert new records with a “Websites” value of “Adobe”. Adding the subsequent breaches was a whole new ball game.
Adding additional data breaches
Inserting a clean set of data is easy – just fire and shoot and whack as many rows as you can into each batch. Adding additional rows from subsequent breaches is hard (comparatively) because you can’t be quite so indiscriminate. After the 153 million Adobe records, I moved onto Stratfor which has a “measly” 860,000 email addresses. Now, for each of those Stratfor records (and all the others from subsequent breaches I later imported), I needed to see if the record actually existed already then either add Stratfor to the Adobe entry if it was there already, or just insert a brand new record. This meant that I couldn’t just simply throw batches at the things, I’d need to go through record by record, 860,000 times.
I decided to bring it all back down to basics with this process; no async and I’d run it locally from my machine. I felt I could get away with this simply because the data set was so small in comparison to Adobe and it wouldn’t matter if it took, say, overnight. However, I wasn’t aware of just how slow it would end up being…
I ran up 9 separate instances of the import process as I’d done earlier with Adobe in the VM and also as per earlier, each one took one ninth of the records in the DB and managed a grand total of… 2 rows per second in each instance. Ouch! Not quite the 6,000 per second I got by sending batches async within the same data centre. Regardless, it took about 14 hours so as a one off for the second largest data set I had, that’s not too bad. Here’s how things looked at the end of the import in one of the nine consoles:
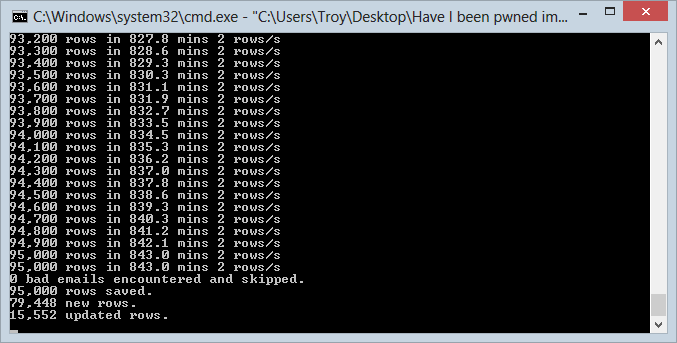
One of the interesting things you’ll see is that more than 15,000 of the rows were updated rather than inserted – these guys were already in the Adobe breach. This was the first real validation that there’d be overlap on the data sets which, of course, is a key part of the rationale for building HIBP in the first place. In fact after the whole Stratfor import completed, the stats showed that 16% of the addresses were common over the breaches.
Later on I did Sony and 17% of the addresses were already in there.
Then Yahoo! and it was 22%.
Before moving on past Stratfor though, I realised I needed to address the speed issue of subsequent breaches. The Strafor example was really just too long to be practical if another large data set came along. Imagine another Adobe in the future – I’d be looking at almost 2 and a half years for the import! Not gonna happen so it’s back to the cloud! Actually, I did fire off the Sony import locally because that was only 37,000 records but Yahoo! was looking at 453,000 and Gawker 533,000. To the cloud!
I pushed the data dump and the console app back to the VM instance I’d done the original Adobe import with and as you’d expect, the throughput shot right up. Now instead of 2 records a second it was running at around 58. Obviously that was much better and the Yahoo! dump went through in only 15 minutes. It’s nowhere near the figure I got with Adobe but without the ability to batch and considering the overhead involved in checking if the record already exists then either updating or inserting, you can understand the perf hit. However at that speed, another Adobe at 153 million records would still take a month. It’s easy to forget just how significant the scale of that dump is, it’s truly unprecedented and it may be a long time before we see something like this again, although we will see it.
Last thing on the VM – it’s still up there (in “The Cloud”, I mean) and it has the console app sitting there waiting to do its duty when next called. All I’ve done is shut the machine down but in doing that I’ve eradicated 100% of the compute cost. When it’s not running you don’t pay for it, the only cost is the storage of the VM image and storage so cheap for tens of GB that we can just as well call it “free”.
Monitoring
One of the the really neat things about Azure in general is the amount of monitoring you have access to and Table Storage is no exception. I didn’t get all of the import process above right the first go, in fact it took multiple attempts over many days to find the “sweet spot”. Here’s a sample of the sort of data I retrieved from the portal at the time:
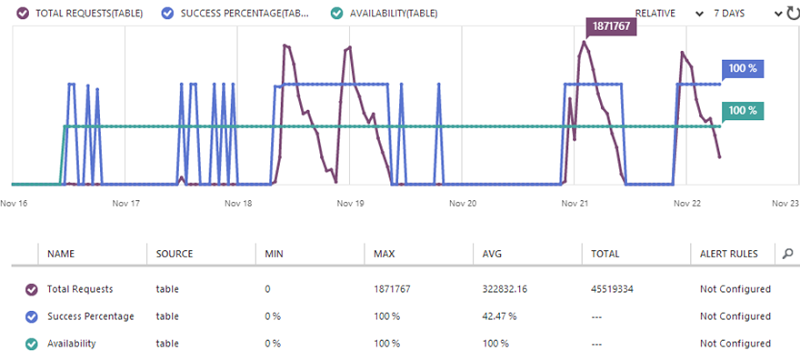
Of course the really interesting bit is the total requests – on November 21st I saw up to nearly 1.9 million requests in a single hour. Inevitably this was just after kicking everything off then you can see the number start to drop off as individual instances of the console finished their processing. The other two things we see are firstly, the availability remaining at a flat 100% and the success percentage mostly remaining at 100% (I’ll talk more about this later).
Getting the data back out
Ok, so we’ve got data in the system, but that’s just the start. Of course it’s also the hardest bit so that’s good, let’s now pull records back out. Obviously I’ve designed the whole thing to be ultra fast in terms of reading data based on the email address. Remember that this is what I’ve compromised the partition and row keys out of.
It’s pretty much the same deal as earlier in terms of needing a storage account object and then a table client after which you can just invoke the “Retrieve” method and pass it the partition key (the domain) and the row key (the alias):
var retrieveOperation = TableOperation.Retrieve<BreachedAccount>("bar.com", "foo"); var retrievedResult = table.Execute(retrieveOperation); var breachedAccount = (BreachedAccount)retrievedResult.Result;
Now sometimes this will actually be null – the email won’t have been found in any breaches – and that actually has an interesting impact on the monitoring which I’ll come back to. All things going to plan though and a valid BreachedAccount with websites comes back out. I’ve done the usual thing of abstracting this away into another project of the app and in fact the web project knows nothing of Azure Table Storage, it simply gets a string array of impacted websites back from the method that accepts the email address it search for. It’s dead simple. It’s also fast – too fast!
A serious problem – it’s too damn fast
I did a little private beta test last week as a final sanity check and I kept getting the same feedback – it’s too fast. The response from each search was coming back so quickly that the user wasn’t sure if it was legitimately checking subsequent addresses they entered or if there was a glitch. Terrible problem, right?!
So how fast is too fast? I wrapped a stopwatch around the record retrieval from Table Storage and stood up a live test page, try this: http://haveibeenpwned.com/HowFastIsAzureTableStorage/?email=foo@foo.com
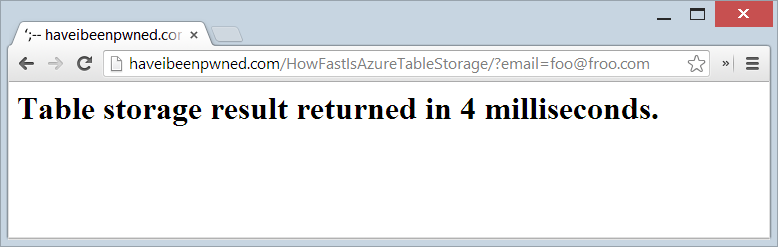
Ah, but you’ve read everything above carefully and realise that the “foo” partition is probably quite small therefore quite fast. Ok, so let’s try it with the largest partition which will be the Hotmail accounts, in fact you can even try this with my personal email address: http://haveibeenpwned.com/HowFastIsAzureTableStorage/?email=troyhunt@hotmail.com
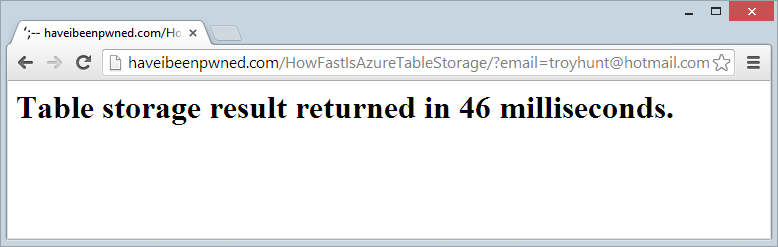
Well that performance is clearly just woeful, let’s refresh:
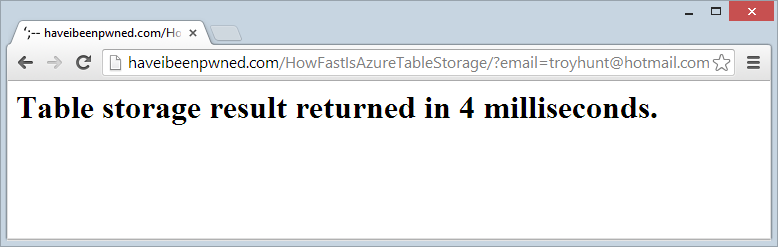
Better :) I don’t know the mechanics of the Azure Table Storage internals, but if I had to speculate it does appear as though some caching is happening or perhaps optimisation of subsequent queries. Regardless, the speed is blistering.
Let us not lose the gravitas of this – that’s 154M records being searched and the connection overhead plus some validation of the email address and then splitting it into partition and row keys and it’s all wrapped up in 4ms. I’m massively impressed with this, it’s hard not to be.
Getting back to it being too fast and the impact on usability, I recall listening to Billy Hollis talking about the value of delays in UX some time back. Essentially he was saying responses that are too fast lose some of the implicit communication that tells the user something is actually happening in the background. I ended up putting a 400ms delay in the JavaScript which invokes the API just to give the UX transitions time to do their thing and communicate that there’s actually some stuff happening. Isn’t that a nice problem to have – slowing the UI down 100-fold because the back end is too fast!
Certainly the feedback on the performance has been fantastic and I’ve seen a lot of stuff like this:
I have a question...how big is the backend to this site? Its average response is about 100ms, which, to me, seems impressively fast considering the number of bulk records and the amount of concurrent traffic that such a site is getting.
All of that’s great, but what happens at scale? Going fast in isolation is easy, doing it under load is another story. This morning, something happened. I’m not exactly sure what, obviously it got some airtime somewhere, but the end result was a few people swung by at the same time:
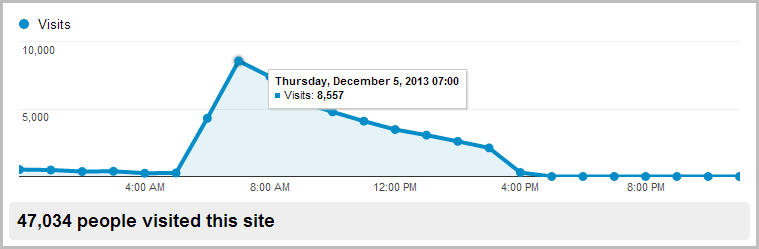
That Google Analytics report is showing eight and a half thousand visitors between 7 and 8am. Obviously they weren’t all hitting it at the same time, but inevitably it had plenty of simultaneous load. So what does that do to the availability of Table Storage? Nothing:
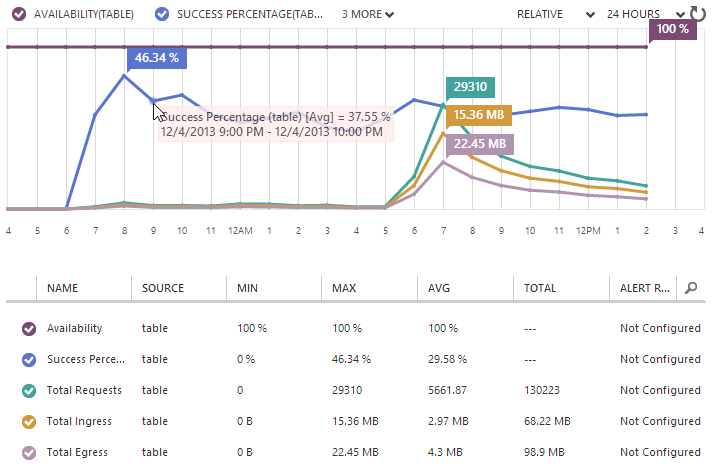
Availability flat-lined at 100% and indeed when I jumped on and tested the speed using the process above that showed 4ms, I saw… 4ms. Refresh 4ms. Refresh 5ms. Damn – a 25% jump! But seriously, the point is that it didn’t even flinch. Granted, this is still a low volume in the grand scheme of large websites, but I wouldn’t expect it to slow down, not when it isn’t constrained to the resources of logical machines provisioned for the single purpose of supporting this site. Instead, it’s scaling out over the vast resources that are within Azure and being simultaneously distributed across thousands and thousands of partitions.
But hang on, what’s all this about the “Success Percentage” tracking at just under 30%?! Why are more than two thirds of the queries “failing”?! As it turns out, they’re not actually failing, they’re simply not returning a row. You see what’s actually happening is that 70% of searches for a pwned email address are not returning a result. This is actually an added benefit for this particular project that I didn’t anticipate – free reporting!
Cost transparency
The other thing worth touching on is the ability to track spend. I hear quite a bit from people saying “Oh but if you go to the cloud with commoditised resources that scale infinitely and you become wildly successful your costs can unexpectedly jump”. Firstly, “wildly successful” is a problem most people are happy to have! Secondly, here’s the sort of granularity you have to watch cost:
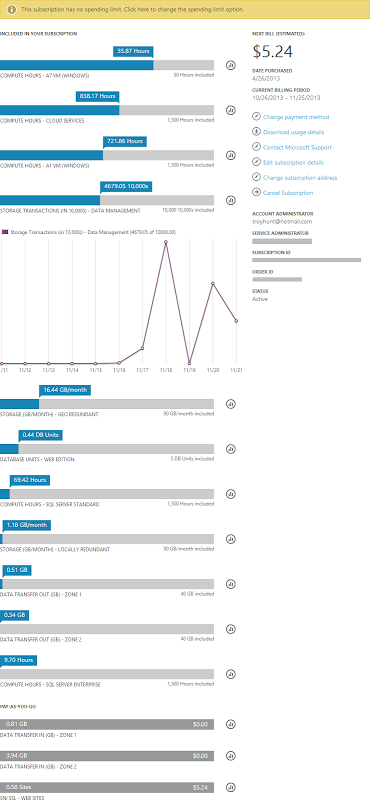
I have an MSDN Ultimate subscription which gives me (and anyone else with an MSDN subscription) a bunch of free Azure time which is why you see all the “included” components. What I really wanted to get across here though is the granularity available to track the spend. I make it about 14 different aspects of the services I’ve used that are individually monitored, measured and billed.
Within each of these 14 services you then have the ability to drill down and monitor the utilisation over time. Take a look at the storage transactions – I know exactly what I’m using when and assuming I know what’s going on in my software, I also know exactly why I’m using the resource.
To my mind, this is the sort of thing that makes Azure such a great product – it’s not just about the services or the technology or the price, it’s that everything is so transparent and well integrated. I’ve barely scratched the surface of the data that’s available to you about what’s going on in your apps, but hopefully this gives you a sense of what’s available.
Developing locally with the emulator
This post wouldn’t be complete without touching on developing against Azure storage locally. I built a lot of this site while sitting on long international flights last week and that simply couldn’t happen if I was dependent on hitting the Azure service in “The Cloud”. This is precisely why we have the Windows Azure Storage Emulator in the Azure SDK (the same one you get the neat Visual Studio integration with I mentioned earlier). Install this guy and run him up in this rich graphical user… uh, I mean command line:
And that’s just fine because once it’s running it just sits there in the background anyway, just like Azure storage proper would. Connecting to it in code is dead easy, just change the connection string as follows:
<add name="StorageConnectionString" connectionString="UseDevelopmentStorage=true;" />
This is actually the only connection string I have recorded in the web app. I configured the real connection string (the one we saw earlier) directly within the Azure portal in the website configuration so that’s automatically applied on deploy. This means no creds in the app or in source control (I have a private GitHub repository) which is just the way you want it.
Connecting to the emulator to visually browse through the data is easy, in fact you’ll see a checkbox in the earlier Azure Storage Explorer image when I added the Azure account plus you’ll see it automatically pop up in the Server Explorer in Visual Studio.
The emulator is almost the same as what you’d find in cloudy Azure bar a few minor differences. Oh – and one major difference. Back earlier when I wrote about the Windows Azure Storage libraries on NuGet I said “don’t take the current version”. I started out with version 2,x and built all of HIBP on that using the emulator and everything was roses. Then just as I was getting ready to launch I thought “I know, I’ll make sure all my NuGet packages are current first” which I promptly did and got a nice new shiny version of the storage libraries which then broke everything that hit the emulator.
It turns out that the SDK is on a different release cycle to the libraries and it just so happens that the SDK is now behind the libraries since version 3 launched. tl;dr: until the SDK catches up you need to stick with the old libraries otherwise there’s no local emulator for you.
And that’s it – how’s that compare to trying to SQL Server up and running on your machine?!
In closing…
Obviously I’m excited about Azure. If you’re reading this you probably know what’s it like to pick up something new in the technology world and just really sink your teeth into learning what makes it tick and how to get it to do your bidding. It’s exciting, frustrating and wonderful all at the same time but once you get to grips with it you realise just how much potential it has to change the way we build software and the services we can offer to our customers. The latter point in particular is pertinent when you consider the cost and the ability to rapidly scale and adapt to a changing environment.
Building HIBP was an excellent learning experience and I hope this gives people an opportunity to understand more about Table Storage and the potentially massive scale it can reach at negligible cost. Those headline figures – 22,500 records inserted per second then 154 million records queried to return a result in only 4 milliseconds – are the ones I’ll be touting for a long time to come.