
A few weeks ago now I launched the notification service for Have I been pwned? (HIBP). The premise of the service is that whilst it’s great to be able to go to the HIBP website at any time and ask it if your account had been pwned, what’d be really great is if it could just tell you automagically if your email address appears in a data breach loaded into the system in the future. Neat, right?
When I first launched HIBP, I wrote about Working with 154 million records on Azure Table Storage which outlined how the service worked and how I’d used features of Azure such as Table Storage and virtual machines to make it both super-fast and super-cheap. A lot of people asked me if I’d write up how I did the notification service and indeed they had some very good questions:
Do you still store everything in Table Storage?
How will you send millions of emails if there’s a big breach?
Won’t this cost a lot?
I don’t, I won’t need to and it won’t. Let me explain as it’s actually all very simple.
“Plan A”
I’ll let you in on a bit of internal thinking, “internal” being pretty much what happens in my head and how I think I’ll approach things before I actually start. These are the notes I jotted down in Evernote while thinking about the whole thing:
Allow people to sign up so they can be notified if their email appears in a new breach.
New nav item called "Notify Me" and prompt on each search.
Signing up
- Enter email only into a text field
- Need a CAPTCHA to avoid brute-force
- Generate a crypto random token
- Put in a table called EmailVerification with common partition key and token as row key
- Send a confirmation email with token link
- Include IP the request originated from
- Email must be responded to within one hour
- Responding moves the email into an EmailNotification table with same key structure as breach table
- Also deletes the record from the EmailVerification table
- Need a column called BreachesNotified to ensure no double-sending
- Also need an UnsubscribeToken column to be included when sending notifications
- Not responding purges the queue item
Edge cases
- Already signed up: email and tell them no need for verification. Include a link to unsubscribe
Queuing notifications
- The check for if someone needs to be notified should be added to the import console
- For each record in a dump, check if the email is in the EmailNotification table
- If exists:
- Insert email and breach name into a PendingNotification queue
- Save the breach record
Sending notifications
- Background worker?
- For each queue item:
- Send the email with a link back to the site for more info on the breach (do this first as it's most likely to fail)
- Update the record in the EmailNotification table to flag the breach as processed
- Delete the item from the queue
- Include a link to stop receiving notificatons (can this just include token or need email for key? Maybe have another table of tokens?) - this should also confirm that email and all history has been removed fr the system
- On send, add a token record which is the key and have and email field on the table so it knows which row to
Things to check
- Email service - SendGrid?
- Steps to take for junk mail resiliency
- How do I log the count?
tl;dr: whack everything in Table Storage, use the existing breach import process that runs in the virtual machine to also check for notifications that need to be sent, chuck the notifications into a message queue then have a background worker go through and process the queue. Sound feasible?
Entirely, but it was way too complex and it all begins with the Table Storage piece.
Not all roads lead to Table Storage
In the earlier post about working with all those records in Azure, I made the following comments:
“We need a database therefore we need SQL Server.” How many times have you heard this? This is so often the default position for people wanting to persist data on the server and as the old adage goes, this is the hammer to every database requirement which then becomes the nail. SQL Server has simply become “the standard” for many people.
You know what’s just as bad as defaulting to SQL Server “just because”? Defaulting to Table Storage “just because”!
Table Storage worked really well for storing the breached accounts for a few reasons:
- It’s enormously fast across gigantic data sets
- It’s dead easy to query when you’re searching by a single key (such as an email address)
- It’s very cheap compared to SQL Azure (about 5% of the price by volume)
The first sign that this wasn’t necessarily the best path was when I was designing the verification token process. I needed to be able to resolve account by either email address (when I’m looking for an account in a breach) or by token (when I’m verifying an account). Suddenly the value of super-fast key-lookups wasn’t looking so great (note: I haven’t tested the difference in perf, but it wasn’t the only reason).
The other thing was that I really needed relational data; I wanted to have breaches (Adobe, Stratfor, etc) and I wanted to have notification users and I then I wanted to be able to map between those in order to track which users had been sent a notification for which breach. This is important as it gives me idempotence – I can run the same script over and over again on the same records without them sending notifications twice because I know who’s already received one.
You know what does relational data well? SQL Azure! Seriously though, there are cases where relating entities to each other and achieving referential integrity and being able to easily query the data make a lot of sense. This was one of those cases.
But what about the cost? How will I handle a 20-fold increase? The answer lies in what you’re actually increasing 20-fold and compared to the breach data of 154M records, this was going to be tiny. At the time of writing, here’s how much data 15,000 subscribers were using:

Let’s run the numbers on that based on the SQL Azure costs:
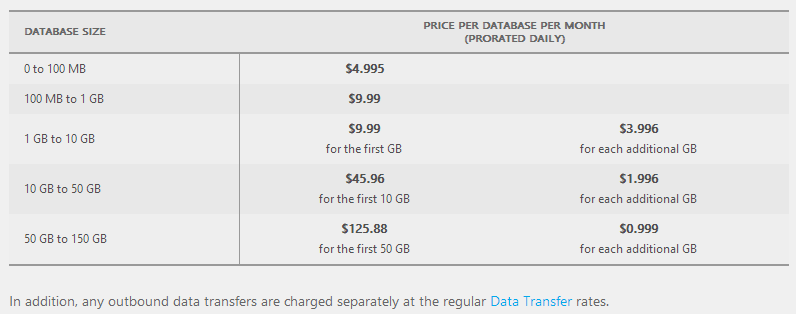
That’s about 1.3 cappuccinos per month on my coffee scale or in other words, a price I don’t need to think about. Even at a gig, it’s still not enough to barely even make a dent in the coffee budget so I’m just fine with that.
The other thing is that by having a SQL back end handy I can now do things like store exceptions with ELMAH and log ad hoc data with Log4Net. Sure, there are other ways of storing both these but a relational database you can actually query is a very valuable thing.
The other thing is that once you’re in SQL Azure you’ve also got Entity Framework which means inserting, updating and querying data – particularly in such a simple model – is dead easy. It just makes sense.
But, but… now you have two persistence tools and they’re unrelated! Nothing explicitly ties the string values of the breach name in Table Storage to the relational data structure in SQL Azure. Who cares? Seriously, what’s the downside? The point I want to make here is that there’s absolutely nothing wrong with being a data layer polyglot when multiple technologies excel in different areas and can be used harmoniously. This concept, for some, is mind-blowing but it shouldn’t be. Use what makes sense and don’t be afraid to mix it up a bit.
CAPTCHA (sorry!) and email verification
No really, I’m genuinely sorry to have to hit you with this and believe me, people tell me when they don’t like it:
Don’t you just hate it when people put barriers in front of you using a free service?! :)
Let me explain the rationale because nobody puts a CAPTCHA in for fun. There are two primary reasons I need protection against automation:
- To prevent junk signups. If I have a DB full of crap it’s going to make enumerating each record when a new breach is uploaded significantly harder. It could also have a cost impact if enough junk goes in there and blows out the DB size. Yes, I could implement various brute-force protections but it only takes one galah with a rented botnet and I’ve got a serious problem.
- To limit the emails that are sent. I’ll write more about email delivery in the next section, the important thing for now is that each email costs money (remember, I’ve a coffee budget to preserve here!) and perhaps even more importantly, each email sent has an impact on the “reputation” of the email account which then impact spam filters.
Moving on, once the CAPTCHA is answered (again, sorry, I really mean it), I’m sending a verification email which requires a link to be followed in order to confirm that the owner of the email address does indeed want to be a part of this service. The reason I’m doing this in addition to the CAPTCHA is that whilst anti-automation proves that it’s (usually) not an automated process submitting the form, it doesn’t prove that the owner of the email address actually wants to receive notifications. That’s an important distinction because I want to end up with a collection of records for people who I know genuinely want to receive email from the site. I’m happy to pay for these guys to get notified and I’m happy for each of them to contribute to the resources required and the duration taken to process the notifications.
The flip side, of course, is that both CAPTCHA and email verification are barriers to entry. But how much of a barrier? That brings me neatly to the next point.
Instrument and measure all the things
A project like this (and most software projects, for that matter), are never really “done”, they’re just at various stages of “in progress”. Rest on your laurels and let technology and the world in general speed on by and you’re missing too many opportunities. No, in my mind at least, software projects are an ongoing process of continuous improvement but before we can improve, we must be able to measure.
A case in point: CAPTCHAs are nasty (have I apologised for these yet?) and we know the damn things get in the way, but how much of a barrier are they really? I mean are they enough to completely turn someone away after being stuck with a few dodgy ones? You can’t answer this unless you measure what you care about.
I’ve used Log4Net extensively throughout the project to record pieces of information that are important to improving the service. For example, I record when someone gets a CAPTCHA wrong and when they get it right as I can use this information to make some logical decisions about its usefulness. What I found in the week leading up to now is this:
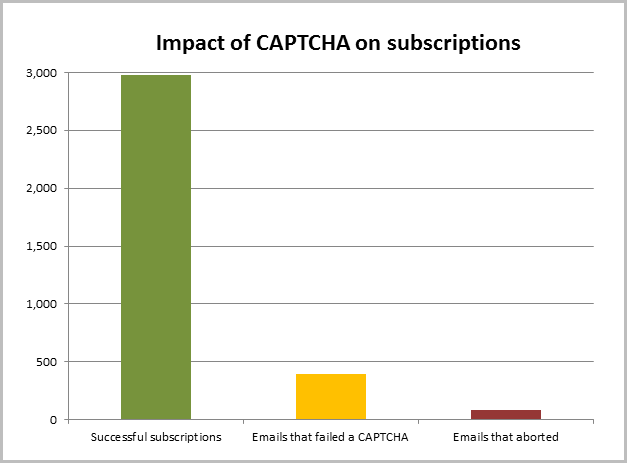
There 2,978 email addresses successfully subscribed to notifications. During this period, there were 393 email addresses that failed one or more CAPTCHAs and 79 of those never managed to solve one. Put another way, for every one attempt that tried then walked away after getting a CAPTCHA wrong, there were another 39 that went through just fine. I’m losing about two and a half per cent of potential subscribers. Now granted, this doesn’t account for the proportion of people who say “Argh! CAPTCHA! I’m not even gonna try!”, but it does give a good indication of the proportion of people who genuinely want to subscribe yet find CAPTCHA to be an unsurmountable hurdle.
I’m sharing this firstly because it demonstrates what a small percentage of people are shut out by CAPTCHA (at least compared to the ramification of just one bad egg going nuts with the subscription service) and secondly because it demonstrates the value of instrumentation and measurement. Time may not prove my decision with CAPTCHAs to be the best path forward, but I’m proceeding with a complete and clear understanding of the impact on the user base. Measurement is invaluable.
Delivering emails en masse
Now, back to emails. They’re hard. I know what you’re thinking – they’re not hard and you can just pump them out over SMTP willy nilly but that’s not quite true. Have a read of Jeff Atwood’s “So You'd Like to Send Some Email (Through Code)” and you start to realise the complexities involved, particularly with regards to beating your way through spam filters.
Spam is one of the biggest hurdles to reliably getting email out because it’s just such a black art. Yes, I know there are DKIMs and SPFs and reverse PTRs and probably other acronyms I’ve never heard of, but you’ve really gotta know your way around these and just pumping emails out through your hosting provider’s SMTP gateway is asking for trouble. Certainly I’ve been involved in projects before where the question ultimately comes up – “How come all the emails are going to customers’ junk mail folders?”
HIBP needs to send out emails one by one when someone signs up in order to verify that the recipient genuinely wants to receive notifications, then of course when there are future breaches and subscribers appear in there then it needs to be able to send them out in bulk. The latter in particular is not a pattern that pleases spam filters very much so it’s critical that a proper email delivery service is used.
In the past, I’ve used Mailgun for ASafaWeb as it’s easily accessible via AppHarbor, but in the Azure world we have SendGrid baked in as an add-on. Now what’s really cool with this is that you can get into SendGrid for free, in fact you can get 25,000 emails per month without spending a dollar. However, there’s other stuff you don’t get:

I’ve upped the email ante and gone bronze for a few key reasons. Firstly, it gives you all those neat deliverability features that are described above. If I’m going to go to the effort of writing software that sends email, I want to maximise the chances of it actually getting to where it’s meant to go. That’s essential.
Next, there’s the volume and 25,000 per month is cutting it just a bit too fine:
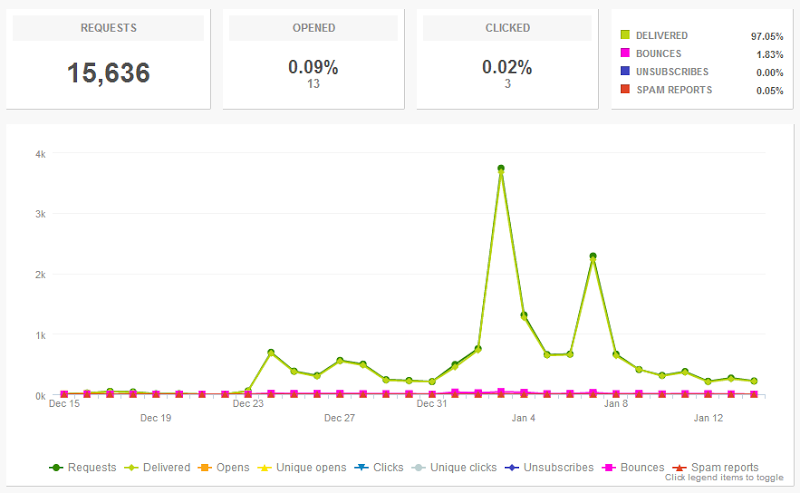
This is the stats since the service launched on Xmas eve and over this (arguably extra quiet) period, the site is running pro rata on about 22,000 emails a month and this is without loading any breaches in that would result in additional email notifications. Ignoring the deliverability advantages of the Bronze plan for a moment, coming within 12% of the service simply not working is just too tight for comfort, particularly when this site has a habit of turning around and suddenly being expectedly wildly popular. Strike another few coffees out of the monthly caffeine budget.
Incidentally, the costs and thresholds here should give you some idea of why I want to restrict volume with a CAPTCHA. The next tier up runs at an eight-fold price increase which I really don’t want to incur. In all honesty, I’d probably load-balance the mail between SendGrid and Mailgun if I got near that point, but that’s another layer of complexity I don’t really want to have to deal with just yet.
Oh – one more thing: notice how the report shows only 13 opened and 3 clicked emails? I consciously disabled these features very early on and as of now, I don’t see it providing any value but I do see it being not viewed favourably by recipients. Yes, I know, I just said “instrument and measure all the things” but I also want to ensure I continue to provide a service that people don’t feel is invasive. Don’t take that as an “I will never measure opens”, but certainly I’m not going to do it unless it’s genuinely useful.
Now, what will those 15,000 current subscribers do to my mail stats when I load in a new breach? That all depends on how many of them are in that breach. If it’s another Strafor with 860,000 users then there may only be hundreds of subscribers that are actually found. If it’s another Adobe with 4.6 million well, yeah, that’s going to get interesting! Under “normal” breach size circumstances I won’t have any problems and I’ve got avenues to pursue in the event of another biggie to ensure the mail gets to subscribers successfully.
Seriously messing up the site performance
I pride myself in the speed of this site – it’s blistering! I’ve talked about querying 154 million records in as little as 4ms and micro-optimised the bejesus out of it all in the pursuit of more speed. Imagine then, my horror at seeing this:
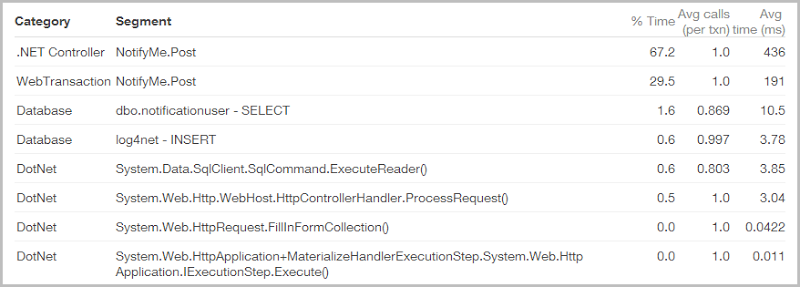
My stats! My beautiful stats! Even under full load, the process to query those hundreds of millions of records completes in its entirety in an average of only 56 milliseconds. Now here we have this monster taking nearly 12 times that – 649 milliseconds on average for crying out loud!
What you’re looking at here is an app performance report from NewRelic (you know you get this for free in Azure, right?), and what’s killing it is the SMTP server. Sending mail is woefully slow, especially compared to, say, querying table storage and it only gets worse when you’re using a provider who may not be located on the same LAN (I’m assuming SendGrid doesn’t have a point of presence in Microsoft’s West US Azure data centre). The usual suspects in the poor performance department (such as the database) are actually doing pretty well (although 10.5ms to pull an email seems high, might be missing an index there), it’s that mail delivery that’s killing it.
On the flip side, at least it’s consistent:
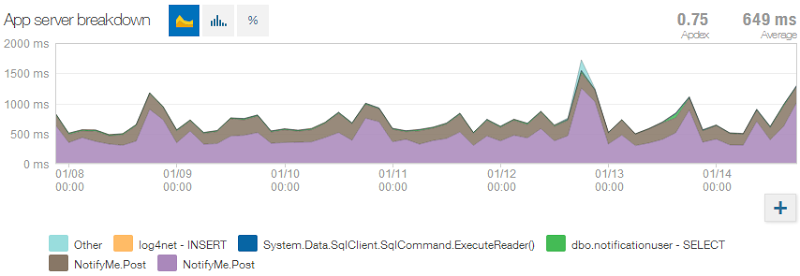
This is more NewRelic goodness and it goes to my earlier point about measuring all the things and that’s really the point I want to make about the email performance. Whilst I know it’s not great (although arguably waiting just over half a second for such a process is extremely tolerable), I know why it’s not great and I know what the impact on the end user is. I also have a baseline – if I can improve this in the future (I’ve a suspicion their API might help me do this instead of hitting SMTP), I’ll know exactly how far I’ve improved it and how much time that’s shaved off the site sitting there processing. Remember, that’s in extremely important metric when it impacts the auto-scaling of a popular site and it directly impacts your hip pocket!
Sending notifications to breached emails
Almost always (at least in my experience), the simplest possible implementation is the best. Faster to write, easier to maintain, less moving parts to go wrong. That’s why I don’t need message queues or background workers to send these notifications out.
Per my “Plan A” notes above, the original rationale was that during the import of the data I’d be checking each breached accounts against a list of subscribers then if there’s a hit, pumping it into a message queue after which a background process would come along and actually send the emails out. My rationale for doing this was that the queue provides an abstraction between the import process and the sending of notifications such that when I’m sucking new data in it doesn’t get bogged down in the latency that is SMTP mail delivery (remember how this is woefully slow?)
But it ultimately didn’t make sense for a number of reasons:
- Sending notifications isn’t time critical, at least not insofar as it has to happen immediately after the row is inserted into the table of breached accounts.
- Even pushing to a message queue would have a significant impact on the speed with which I can get that initial data set into the system. Per my previous post on the mechanics of this service, I’m getting a throughput of about 58 rows per second on import which even multiplied across nine instances is only about 1.8 million records in an hour. Another big dump and I’m already going to be struggling to get it processed in a reasonable time.
- There is absolutely no reason why inserting each breached record into the system has to happen sequentially with the notification to the user (if they’re a subscriber). There are really entirely independent processes with the only real interdependency being that I don’t list the breach on the site until all the data is in and I don’t really want to send out notification emails before the listing appears.
- I don’t want the ongoing responsibility of maintaining the background worker if I don’t need to. The queue I don’t really care about because it just sits there as a storage container, but I don’t need some process cycling around continually monitoring it.
So I built another console app just for the notifications. It’s 60 lines long including all the namespaces, curly braces and Console.Writes (there’s a little more in data access and logic projects but it’s all just basic plumbing), and here’s what it does:
- Loads ever single subscriber from the SQL Azure database into memory. Many tens of thousands of subscribers shouldn’t bother this. Hundreds of thousands shouldn’t either.
- Goes through the breach dump file of email addresses (the same one the original important tool uses), and checks each one against the in-memory collection of subscribers.
- When there’s a hit it sends the email out via SMTP using the SendGrid service and updates the SQL Azure database to map the subscriber to the breach (remember the idempotence objective).
That’s it – simple! It’s all single threaded and there’s no async but it just doesn’t matter. The only real delay is in sending the mail via SMTP but at an absolute worst case that happens in less than a second. Say I have 10,000 notifications to send – that’s a very highball number but even that would all be done in less than 3 hours. That might sound like a while, but the process can just sit there in the VM up in the cloud nice and close to the database and do its thing. If it crashes then I just start it again and it picks up from where it was before because it’s logged who’s been notified already.
The key message I wanted to impart here is to simplify, simplify, simplify then when you’re done with that, make it easier! Many an architect in many a shiny ivory tower will cry into their PowerPoint decks in reading this, but as awesome as those original designs may have seemed, they were entirely unnecessary and amounted to nothing more than bloat.
Why aren’t I charging for this service?
Because it’s too hard. Well actually that’s only part of it and what I mean is that if I have to stop and build all the paraphernalia around charging people and managing accounts then that’s a whole lot of time I can’t spend doing what I actually want to do and that’s building new features and expanding the data set.
The other thing is that it adds a heap of complexity to the system. One of the things I love about the model at the moment is that the absolute most sensitive, most explosively damaging data I have is… email addresses. No passwords. No names. No addresses and certainly no financial information. The system is beautifully streamlined the way it is.
Then there’s the cost to provide the current service – there isn’t any. Ok, so there’s some very minor hosting costs and there’s the ten bucks I give SendGrid every month now but as I’ve said time and again, if it’s not putting a dent in my coffee budget then there’s really not a cost to recoup.
Now, whether or not this service presents a viable business model that can actually make money is a whole other question again. I’m vaguely aware of other services that charge for this sort of info (honestly – I’ve barely looked at the others and just focused on building what I think is valuable), and I’m conscious that some of the things you’re going to see in the very near future command considerable money in some corners of the web. I’m all for someone coming and making me an offer I can’t refuse to take on the service at some point in the future but for as far as I can see, I honestly have no plans to charge for it. I just don’t need to.
Why am I writing these posts?
Firstly, I think many people are genuinely interested in the mechanics behind this site and I’m only too willing to share my experiences (both good and bad) for the benefit of others. Particularly when it comes to using the shiny bits in Azure, we have a whole heap of ways of building software that are both very cool and very foreign to many people. I hope this gives practical context to how the technology can be used.
Secondly, I get really, really good feedback from people when they respond to these posts. Not the “hey, great job” sort of feedback (as nice as that is), but the “hey, have you thought of doing it this way” or “here’s what I’d really like to see you do” sort of feedback. Given I sit here in isolation and have personally written every single last line of C#, HTML, CSS and JS, it’s very easy to miss the woods for the trees and your feedback, dear reader, is absolutely invaluable.
Finally – and this is true of many of my blog posts – writing the story helps me enormously in the design process. I write many of these posts during the design and development as when you’re forced to articulate your position in a clear and concise fashion, all sorts of things dawn on you. My writing improves my code enormously and I can’t speak highly enough of this process for anyone building software.
Coming soon…
There’s a heap of stuff still in the pipeline ranging from all new features to enhancements of the existing ones to fleshing it out with more breached data sets. Some of this you’ll see imminently and I’m really looking forward to the ways people find to make use of the data. I’m already seeing some great uses of the API (one of the things on the “to do” list is to detail these on the site) and I’m sure there are innovative uses of the data I haven’t even though of yet.
As always, keep the good ideas coming. I’ll build as many of them as are feasible and I really depend on that input in order to help the site grow in the right direction.