It’s never real nice waking up to something like this:
This was Have I been pwned? (HIBP) first thing my Saturday morning. The outage was accompanied by a great many automated email notifications and manual reminders from concerned citizens that my site was indeed, down. Having my Azure showcase site down at the very same moment as my Pluralsight course on Azure was launched – Modernizing Your Websites with Azure Platform as a Service – only served to rub salt into the wound.
But as I’ve written before, the cloud does actually go down. If anyone tells you it doesn’t, they fundamentally misunderstand the mechanics which underlie what is ultimately still just a bunch of computers running [something] as a service. Whilst you can certainly get much higher degrees of resiliency against outages, you don’t get 100% uptime and indeed that’s why the SLAs in the aforementioned blog post exist.
In this case, the cloud well and truly did go down and it only took a quick glance at the Azure status page to see where the problem was:

Now when I say “The cloud can go down”, let’s just qualify that position a little more accurately by looking at exactly what was down where:
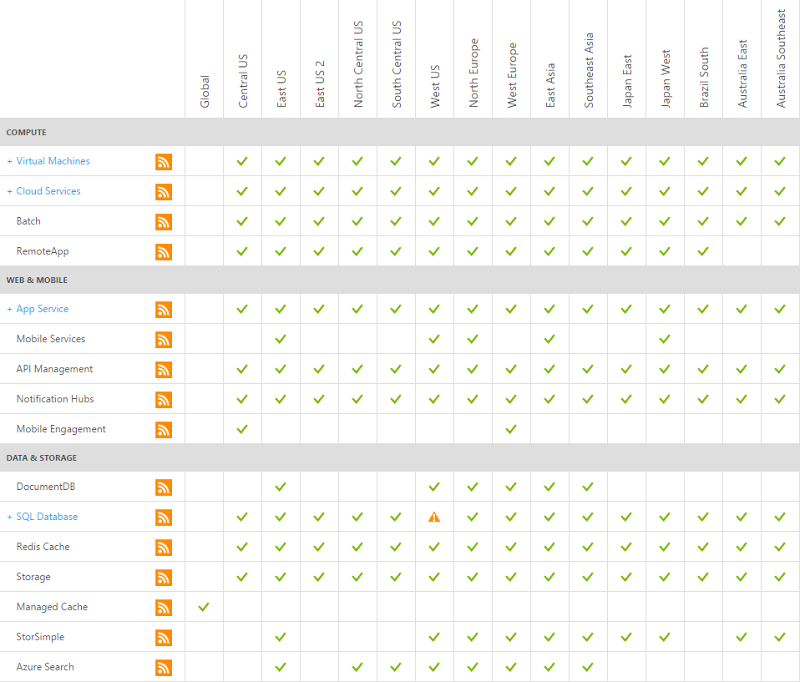
One thing down in one place and I’ve truncated this list too so you’re not seeing dozens of other services (i.e. media services, Active Directory, Backup). Actually, it was even better (worse?) than that because per the earlier explanation from the portal, only a subset of customers in the West US data centre were impacted. I actually found that my sample vulnerable website Hack Yourself First was running beautifully and that’s in the same location. As clearly unhappy as I was about the situation, the “cloud is down” would be massively overstating what ultimately amounted to a very small proportion of the ecosystem misbehaving. Regardless, this meant that HIBP was cactus.
Failing slow
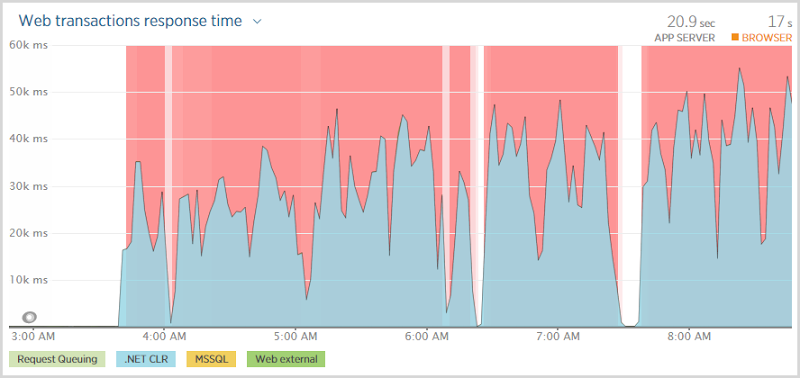
What the outage meant was that anyone going to the site was faced with this:
And they waited. And waited. And waited. In fact if you look at that first graph above, they were waiting somewhere between 30 and 50 seconds before being told that hey, you’re not going to get anything. Now this isn’t a particularly positive user experience and it’s also not great news for the site to have all these threads sitting there taking ages to establish that something which normally should happen in milliseconds is not happening at all. (Not the site was going to be doing much else without a database anyway…)
This is the problem with timeouts; you want them configured at a comfortable threshold to allow things that might genuinely take a bit of time to process successfully but then when fast things go wrong, you’re waiting ages to find out about it. The question, of course, was which timeout was eventually being hit – the DB command? The connection? The web request? You need visibility to the internal exception for that.
Understanding SQL Azure execution strategies
As I’ve written before, I use Raygun extensively for logging those pesky unhandled exceptions and it was very clearly telling me where the problem was:

I did indeed have an execution strategy with 5 retries, it looks just like this:
SetExecutionStrategy("System.Data.SqlClient", () => new SqlAzureExecutionStrategy(5, TimeSpan.FromSeconds(3)));
Now SqlAzureExecutionStrategy can be both a blessing and a curse. It can be great for resiliency insofar as it can retry database transactions without you needing to code it yourself but it can also be downright stubborn and keep trying things it probably shouldn’t thus leading to the problem we see here now. So I disabled it entirely, just an immediate term approach, and saw this:
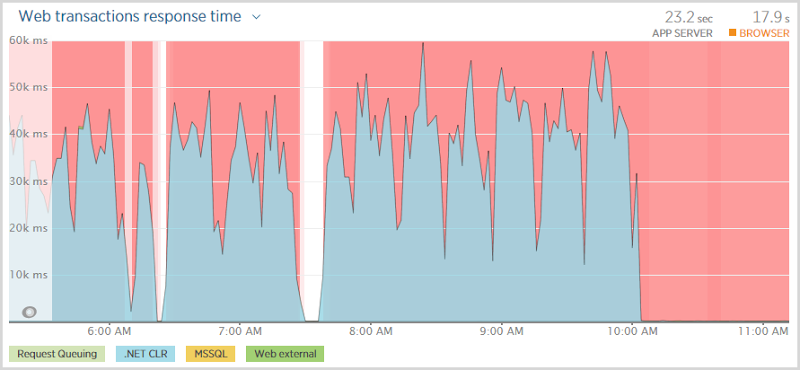
Of course none of this means that the site isn’t totally stuffed, but what it does mean is that rather than having people sitting around thinking “I wonder if this thing is stuffed?”, they immediately get this:

Which all begs the question – what was going wrong with the execution strategy? I mean if having no execution caused the system to immediately recognise that it couldn’t connect to the database and return an appropriate response, shouldn’t the execution strategy merely cause 5 immediate consecutive failures resulting in a response almost as quickly?
Confused, I reached out to good friend and Entity Framework extraordinaire Julie Lerman. In that earlier code snippet, there was a max retry count of 5 (which was exceeded) and a max delay of 3 seconds between those retries. Julie explained that the actual delay is calculated based on a variety of factors including what other processes experiencing the same problem are doing and a formula which also takes into account the retries. There’s a clip in her Pluralsight course Entity Framework 6: Ninja Edition - What's New in EF6 called “Digging into the connection resiliency feature” which explains all this very elegantly and shows the internal implementation within EF. She also shows how to fake a transient failure which then causes the execution strategy to retry so I dropped that into the site, just to confirm suspicions…
And I confirmed very little. With my execution strategy, I consistently saw a 10 second response time which was enough to retry 5 times but well under the 30 seconds plus I was seeing on the transactions. I reverted the execution strategy to the default and now I was constantly seeing 27 seconds, all locally of course so no network latency or other requests being queued. Under these circumstances I could envisage 30 seconds plus, particularly as requests got backed up whilst sitting there waiting to execute. So my only conclusion at this point is that I screwed up the execution strategy somewhere along the line and it was the default one being implemented. Next step would probably be to hook into the ReaderExecuting event within IDbCommandInterceptor (another takeaway from Julie’s course) and figure out exactly when those connections are being made and if indeed there is something else causing delays before, after or within each execution.
It’s not easy testing unpredictable failures like this because, well, they’re kinda unpredictable. However I love Julie’s approach of causing a transient failure to see how the app behaves when things go wrong. One conclusion I did reach with her is that in a scenario like this, you ideally want multiple data contexts as the execution strategy applies to the whole thing. The front page of HIBP only needs to make a tiny DB hit which pulls back a few dozen records (and even that is cached for 5 mins), so it’s highly unlikely to fail due to any sort of organic timeout or race condition or other sort of DB scenario you might legitimately hit under normal usage. The execution strategy should be different and it should fail early so that’s now well and truly on the “to do” list because sooner or later, it’ll happen again. I mentioned the cloud can go down, right?
The cloud can go down – plan for it
Lastly, on that outage – it was a big one. There’s no way to sugar coat the fact that it took HIBP down for 11 hours so for this incident alone, my availability is going to be at about 98.5% for the month which is way down on the Azure SQL Database SLA of 99.99% for a standard DB. I know I said it before, but the cloud goes down and not just within the outage the SLA implies. The SLA isn’t a guarantee of availability, but rather a promise that you’ll get some cash back if it’s not met. Regardless of the cloud provider, you need to expect downtime and all of them have had periods of many hours where one or more things just simply don’t work. Expect that. Plan for that and if it’s going to cause significant business impact then prepare in advance and build out more resiliency. A geo-redundant replication of my database and website, for example, would have avoided extended downtime. It’s not worth it for a free service like HIBP, but you’d seriously consider it if it was a revenue generating site where downtime translated directly into dollars.
Learn more about Azure on Pluralsight

As I mentioned earlier, I’ve just launched a new Pluralsight course and it’s actually the first one I’ve done that isn’t about security! Modernizing Your Websites with Azure Platform as a Service contains a heap of practical lessons on using Azure Websites and Azure SQL Databases (both are Microsoft’s PaaS offerings) and a significant amount of the content in that course has come from real world experiences like this ones learned while building and managing HIBP. It’s very practical, very hands on and a great resource if you want to learn more about the mechanics of how to use Azure websites and databases in the real world.