
The other day I wrote about how I’d implemented the notification service behind Have I been pwned? and I pointed out how I’d used SQL Azure to manage the data associated with this part of the service. Yes, the existing search feature was all driven by Azure Table Storage, but a relational database just made more sense for the notifications.
Anyway, I was doing a bit of local development and jumped over to SSMS to clean things up a bit:
DELETE FROM dbo.NotificationUser
Which resulted in this:

Ah, ok, so I need to… crikey – that’s the production system! It was that heart-in-mouth moment where you realise that firstly, you nearly blew away thousands of production records and secondly, that you have no backups. SQL Azure is highly available and redundant and resilient to individual nodes going out so that part of disaster recovery get ticked, but it’s not resilient to you simply screwing up.
Now I don’t know if I could have pulled things back from transaction logs or done other DBA-y sort of things that admittedly isn’t my forte, but I do know that there’s a glaring hole in my disaster recovery strategy. Mind you there are parts that are actually very good, but that’s not enough. So here’s what you get out of the box with Azure, the bit you’ve gotta fill and then in part 2, how to address what remains an unmet need in Azure when it comes to protecting against a disaster (or in my case, my own stupidity).
Azure’s baked in Godzilla resiliency
Unexpected Godzilla attack is just one of the risks Azure provides some awesome native defences against. Flood, cyclone, fire and the whole gamut of natural and man-made disasters that put data centres at risk are the other thing it’s pretty good at protecting your data from. Let me explain.
In “the old days” we put apps on physical disks in single servers and set them free on the world. If we got fancy enough we’d whack them into a RAID array which offered varying levels of redundancy or we’d have a farm which achieved the same thing across servers. Another route might be to use a SAN which is a big old array of disks in a rack connected by fast ethernet and effectively providing storage as a service. The commonality with all of these is that we ultimately managed a whole bunch of hardware which whilst often redundant insofar as not putting all your datas on a single disk, was laborious and expensive to manage and was only done at whatever scale your small / medium / large enterprise could afford.
The thing with Azure and cloud in general is that you’re buying services, not servers. That’s becoming an old and clichéd term but the important bit for us as Azure customers is that we’re buying a tiny, tiny slice of a very large collection of disks upon which our data is stored very, very redundantly. In the one data centre. What this means is that you get locally redundant storage:
Locally redundant storage provides highly durable and available storage within a single location. For locally redundant storage, account data is replicated three times within the same data center. All storage in Windows Azure is locally redundant.
The problem, of course, is your Godzilla risk. Yes, all that locally redundant stuff is great but have the data centre obliterated by some monstrous force and you’re going to have a problem.
As it turns out, there’s a really neat little trick you get when you jump on over to your storage settings. It looks like this:
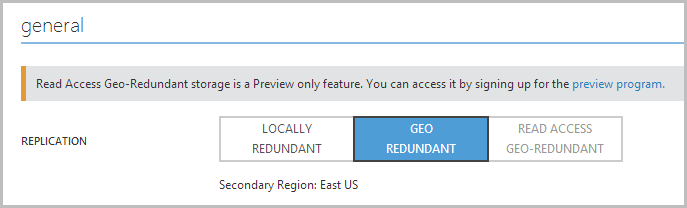
(If you’re wondering what “Read Access Geo-Redundant” storage is, check out Scott Gu’s blog post on the new feature)
Geo-redundant storage, you say? Here’s what you get in the box:
Geo-redundant storage provides the highest level of storage durability by seamlessly replicating your data to a secondary location within the same region. This enables failover in case of a major failure in the primary location. The secondary location is hundreds of miles from the primary location. GRS is implemented through a feature called geo-replication, which is turned on for a storage account by default, but can be turned off if you don't want to use it (for example, if company policies prevent its use).
Now you need two Godzilla attacks in totally separate corners of the world (albeit in the same “region”) to cause you any serious grief. Awesome, so we just geo-redundant all the bytes then, right? Other than the point above about company policy, what’s stopping you? One issue is that there’s a slight price increase:
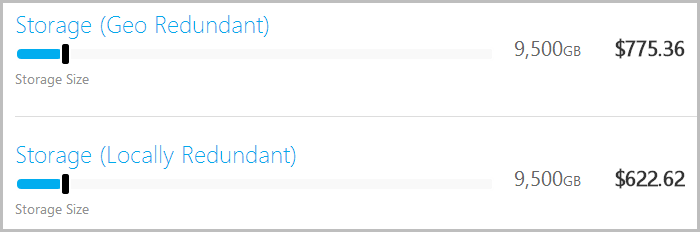
This is in the order of a 25% markup, but consider what’s actually happening here: they’re taking your data and seamlessly replicating gigabytes or terabytes or whateverbytes thousands of kilometres away all for less than 7c a gig. Put that back into the context of your classic data centre model and you start to realise that it’s an absolute bargain.
So we’re all good then – we’ve got data on each side of the continent so we’re covered, right? Ah, but this is only for “Windows Azure Storage”, this is not for “Windows Azure SQL Databases”. In other words your tables, blobs and queues are good but your relational database still needs a strategy. Let’s sort that out next.
Configuring automated exports for Azure SQL Databases
This one is also dead easy and it works like this: jump over to your database in the management portal, hit the “Configure” tab then make it look like this:
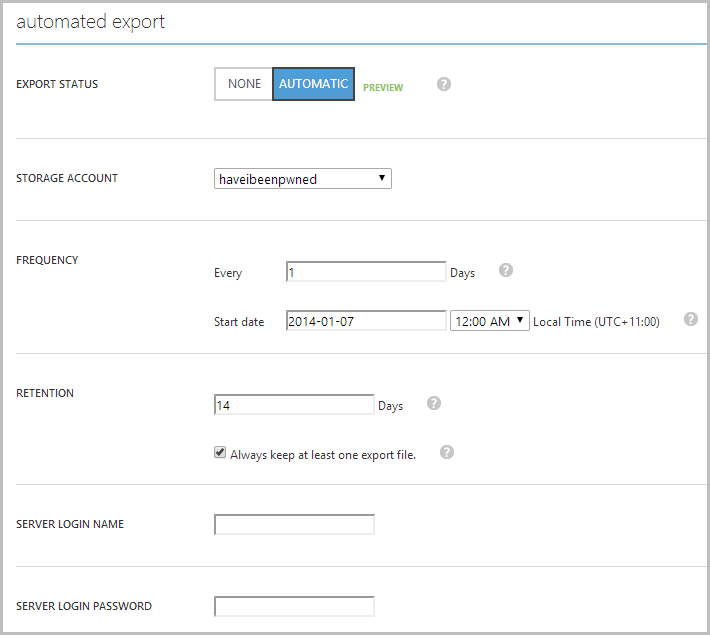
This should be pretty self-explanatory but let’s recap it anyway. What we’ve got here is an automatic export of the database to the “haveibeenpwned” storage account (this is the same one as above where the geo-redundant storage is configured). Every day at midnight local it’s going to take a backup of that database and drop it into the storage account. Not only that, but it’ll keep a rolling fourteen day’s worth of backups so if I run the delete query up there in the opening of this post and not realise until after the next backup, I can just go back an additional day and my window of loss is limited to 24 hours.
This is a critical point – storage redundancy doesn’t give you resiliency against screwing up your own data. What you don’t want is to do what I was about to do then have it happily replicated to the redundant nodes with no way of rolling it back. Of course it’s not just about running a dodgy query, you could have a bug in the app which corrupts data or some no good hacker who runs some sneaky SQL injection to insert persistent XSS that loads some nasty malware. There are many ways to lose your data.
This is also a really important point to delve into when you’re told that you have “backups”. Is this just locally redundant? Is geo-redundant (even tapes taken offsite offer geo-redundancy)? How many days of rolling backups do you have? Plus, of course, the all-important question – can you actually restore the data?
Moving on, once auto export is configured and runs at least once then the storage account will have a new container like this:
When we drill into that container, here’s what greets us:
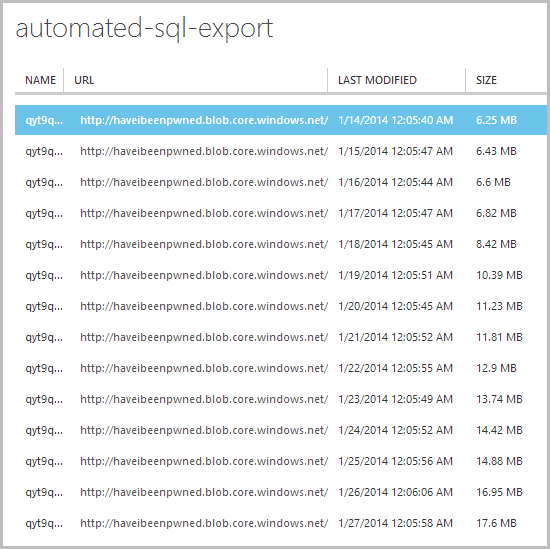
Here’s a nice rolling history of the database for the last couple of weeks and every backup is available as a downloadable .bacpac file:
A BACPAC is an artifact that encapsulates the database schema as well as the data stored in the database. The BACPAC is a Windows file with a .bacpac extension. Similar to the DACPAC, the BACPAC file format is open – the schema contents of the BACPAC are identical to that of the DACPAC. The data is stored in JSON format.
Now of course because those .bacpac files are sitting in my storage container, they’ll automatically get replicated to the other side of the US because I’ve already turned on geo-redundancy across that service. Remember, that’s in addition to the three locally redundant copies.
Backups, however, are nothing if you can’t restore. This may sound preachy, but there are a whole lot of people out there who go about their daily lives taking many backups of all their things then they come to restore it and… nada. It happens and it happens a lot so let’s make sure we can actually get this thing back into my local instance of SQL Server 2012.
Testing the restore process
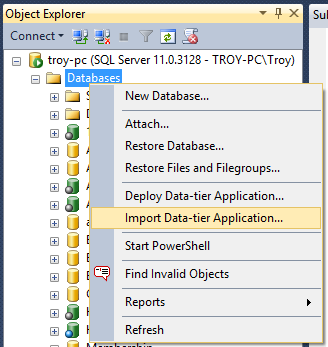
This is dead easy and it works like this: jump on over to SQL Management Studio, right click on “Databases” then grab “Import Data-tier Application…”:
Jump through the “Hey, I’m a wizard!” screen and now this:
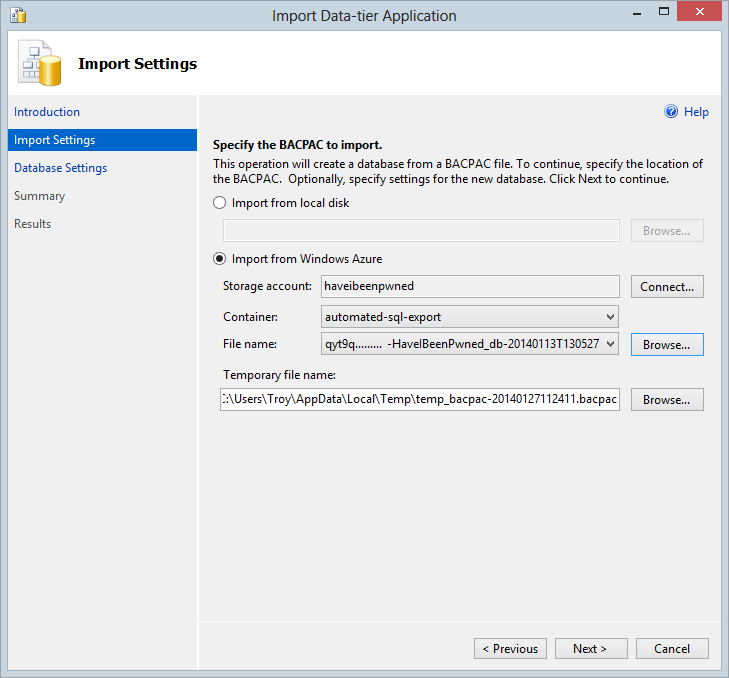
This is really neat – I can either manually download my .bacpac from the storage container where the 14 backups are present then select it from the local disk or I can just connect direct to the container and restore from there. That’s fancier – let’s do that!
Now we just give it a local DB name:
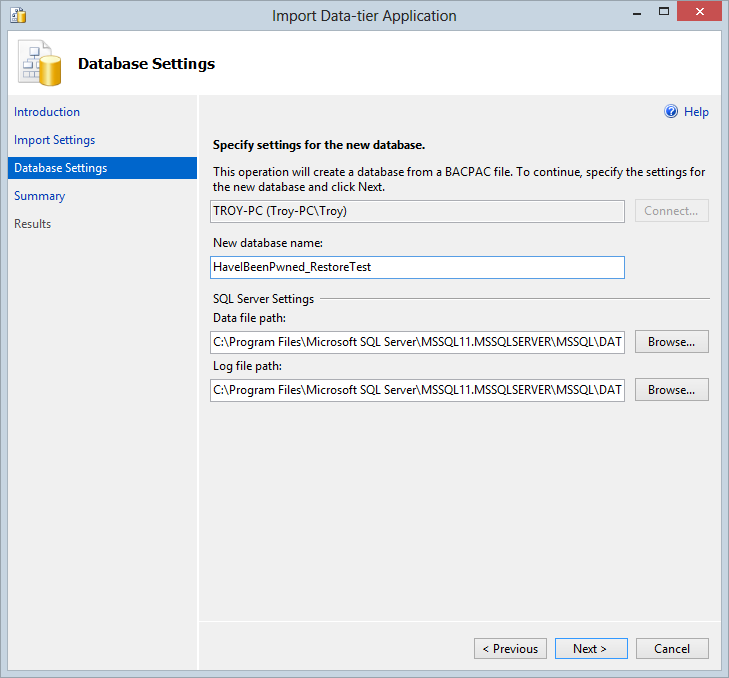
Accept the final confirmation screen then begin playing the waiting game and just a few minutes later – voila!
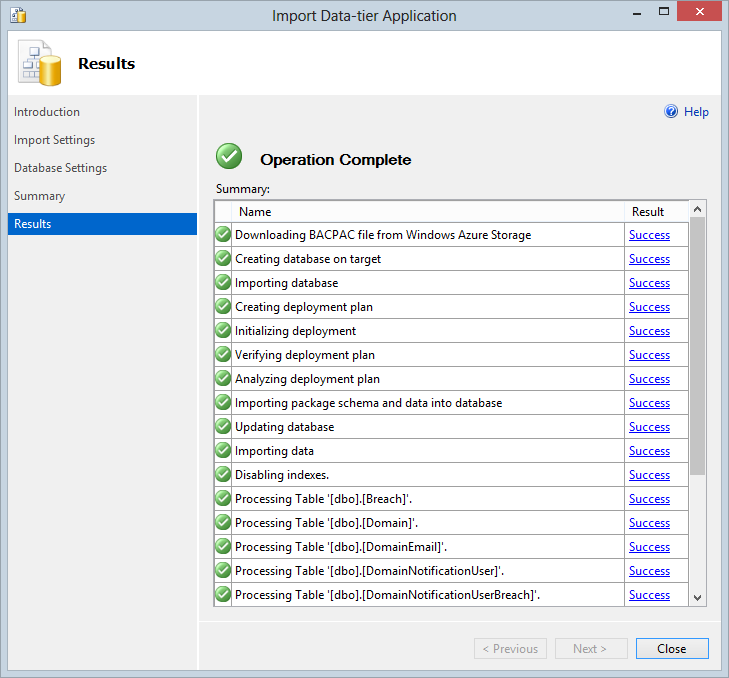
All my datas are now fully restored and a perfect replica of what I had in production at the time of the last backup (and yes, I did check!) This is actually a really neat way of running any sort of analytics you want to do on the data as well as it’s just so easy to bring it down and you don’t need to hit the production system. The most important thing, however, is obviously that I now have nightly backups that at replicated to geo-redundant locations and I’ve tested my ability to download and restore then at will.
Coming next…
Ok, so we’re done then? Not really – I’ve just espoused the virtues of rolling backups and we’ve done that with SQL, but what about the table storage? I’ve now got 160 million odd records in there that took a heap of work to get right and whilst I’ve got the Godzilla defence down, I’ve got zero defence against me accidentally deleting the storage table because I’ve had a few too many reds one night before churning out some code. Azure can’t help you on this one either so it’s time to turn to Red Gate. Stay tuned for part 2 tomorrow.