The unfortunate reality of the web today is that you’re going to get hacked. Statistically speaking at least, the odds of you having a website without a serious security risk are very low – 14% according to WhiteHat’s State of Web Security report from a couple of weeks ago. Have enough websites for long enough (as many organisations do), and the chances of you getting out unscathed aren’t real good.
There’s this great TEDx talk by Jeremiah Grossman titled Hack Yourself First where he talks about the importance of actively seeking out vulnerabilities in your own software before the evildoers do it for you. In Jeremiah’s post about the talk, he makes a very salient point:
Hack Yourself First advocates building up our cyber-offense skills, and focusing these skills inward at ourselves, to find and fix security issues before the bad guys find and exploit them.
I love this angle – the angle that empowers the individual to go out and seek out risks in their own assets – as it’s a far more proactive, constructive approach than the one we so often see today which is the “after it breaks, I’ll fix it” approach. Perhaps that’s not always a conscious decision but it all too often turns out to be the case. It also advocates for the folks writing our apps to develop the skills required to break them which is a big part of what I’ve been advocating for some time now and features heavily in many posts on this blog as well as throughout the Pluralsight training I recently released. If developers do not understand the risk – I mean really understand it to the point where they know how to exploit it – then you’re fighting an uphill battle in terms of getting them to understand the value of secure coding.
It’s not just the dedicated security folks talking about hacking yourself first. The other day I was listening to Scott Hanselman talking about WordPress security on his podcast and he made the following point:
I know when I’m writing code I’m not thinking about evil, I’m just trying to think about functionality.
Which of course is perfectly naturally for most developers – we build stuff. Other people break stuff! But he goes on to say:
When was the last time I sat down and spent a day or a week trying to break my site?
And we’re back to hacking yourself first or in other words, making a concerted attempt to find vulnerabilities in your own code before someone else does. As Jeremiah referred to it, building up cyber-offense skills for developers. Developing the ability to detect these risks is easy once you know what to look for, in fact many of them are staring you right in the face when you browse a website and that’s what I want to talk about here today.
Let me share my top picks of website security fundamentals that you can check on any site right now without doing anything that a reasonable person would consider “hacking”. I make this point for two reasons: firstly, you really don’t want to go messing up things in your own live site and testing for risks such as SQL injection has every chance of doing just that if a risk is present. The other reason is that by picking non-invasive risks you can assess them on other peoples’ sites. I’ll come back to why I’m saying this and the context it can be used in at the end of this post, the point is that these are by no means malicious tests, think of them as the gateway drug to identifying more serious risks.
This is going to be a lengthy one so let me give you a little index to get you started:
- Lack of transport layer protection for sensitive data
- Loading login forms over an insecure channel
- Secure cookies
- Mixed mode HTTP and HTTPS
- Cross Site Scripting (XSS)
- Password reminders via email
- Insecure password storage
- Poor password entropy rules
- Denial of service via password reset
- HTTP only cookies
- Internal server error messages
- Path disclosure via robots.txt
- Sensitive data leakage via HTML source
- Parameter tampering
- Clickjacking and the X-Frame-Options header
- Cross Site Request Forgery (CSRF)
Remember, every one of these is remotely detectable and you can find them in any website with nothing more than a browser. They’re also web platform agnostic so everything you read here is equally relevant to ASP.NET as it is PHP as it is Java – there are no favourites here! I’m going to draw on lots of examples from previous posts and live websites to bring this back down to earth and avoid focussing on theory alone. Let’s get into it.
1. Lack of transport layer protection for sensitive data
We’ll start off one that’s easy to observe and manifests itself in several different ways. When we talk about HTTPS, we’re talking about a secure transport channel and as I’ve written before, it’s about more than just encryption. In fact HTTPS gives us assurance of identity (we know who we’re connecting to), it ensures data integrity (we know the content hasn’t been modified) and finally, it gives us privacy (the data is encrypted and can’t be read by others).
Observing HTTPS is simple as it’s right up there in the address bar:
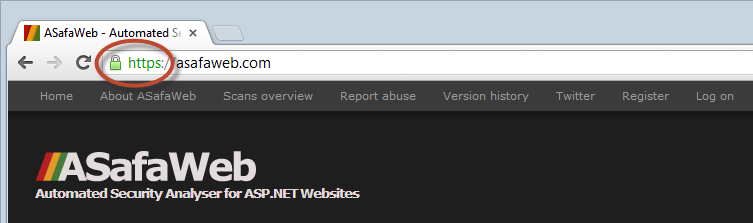
Any time any of those three HTTPS objectives are required – assurance, integrity, privacy – HTTPS needs to be there. There are several common HTTPS-misuse scenarios but clearly the most obvious one is when it simply doesn’t exist at all. We saw this recently with Top CashBack where they allowed for registration – including password transmission – without any transport layer protection whatsoever:
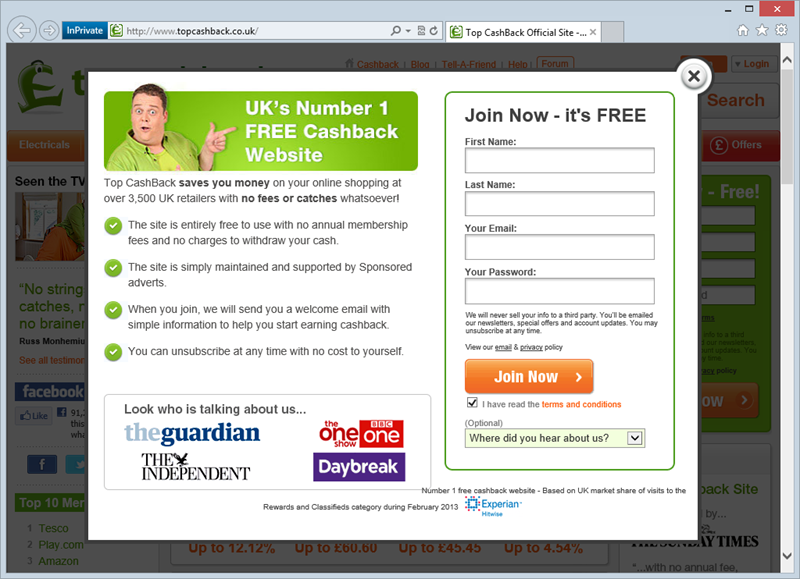
Confidential information such as bank account info, passwords and other data which should not be publicly accessible must be sent over HTTPS. Failure to do this opens up the requests to interception and eavesdropping by a third party at many, many points in the communication chain. Have a read of my post on The beginners guide to breaking website security with nothing more than a Pineapple if you’re not quite sure how that might be possible.
2. Loading login forms over an insecure channel
As OWASP talks about in part 9 of the 10, HTTPS is about more than just “do you or don’t you have it”, it’s about doing it properly. Indeed this is why they refer to it as “insufficient transport layer protection”. If a page isn’t loaded over HTTPS then you have no confidence in the integrity of it. In the aforementioned link, I pointed out how the Tunisian government had harvested Facebook credentials because the logon form could be loaded over HTTP. This meant that the state run ISPs could inject their own script into the page to siphon off credentials on submit. Nasty.
Detecting insufficient use of HTTPS is easy – you won’t see the HTTPS scheme in the address bar! If you see a logon form and the address starts with http:// then that’s wrong. Here’s an example courtesy of Singapore Airlines:
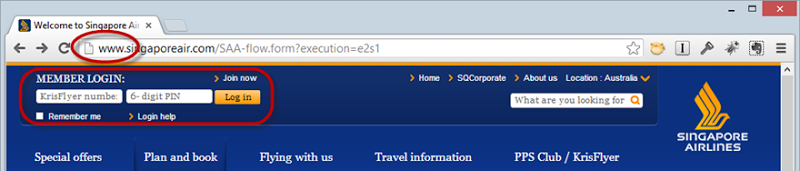
This may look the same as the previous section but here’s the difference:
<form id="headerLoginForm" action="https://www.singaporeair.com/kfHeaderLogin.form" method="post" autocomplete="off">It posts to an HTTPS path. Strictly speaking, the credentials are encrypted when they’re posted but by then it’s too late – the login form has already been loaded over an insecure channel and an attacker has already (potentially) injected their own keylogger into the page.
On occasion, you’ll also see a form loaded into an iframe within an HTTP page. The problem, of course, is we come back to integrity again: there is no guarantee that the HTTP page that embeds the iframe hasn’t been manipulated. Sure, when everything goes just right then the login form is loaded from a secure server, but when it doesn’t then you end up with an attacker loading their own login form that looks just like the real one and the victim is none the wiser.
3. Secure cookies
The thing about HTTP is that it’s stateless which means that each request is a new connection totally independent of previous requests. To maintain state (i.e. some knowledge about the user and their previous activities on the site), we most commonly use cookies and one of the most common uses of cookies is that after logging on, we set what’s referred to as an “auth cookie”. The auth cookie is verification that the user has indeed successfully logged on.
Now, if an attacker can obtain that auth cookie then they can impersonate the victim simply be sending it in a request to the target site. I showed how this works in part 9 of the OWASP Top 10 for .NET developers where I very easily sniffed out an auth cookie from a public network and hijacked the session. Consequently, all authenticated requests must be made over an HTTPS connection. If you can load a page that displays personal information while authenticated and the address starts with http:// then that’s almost certainly wrong.
For example, take a look at Qantas:
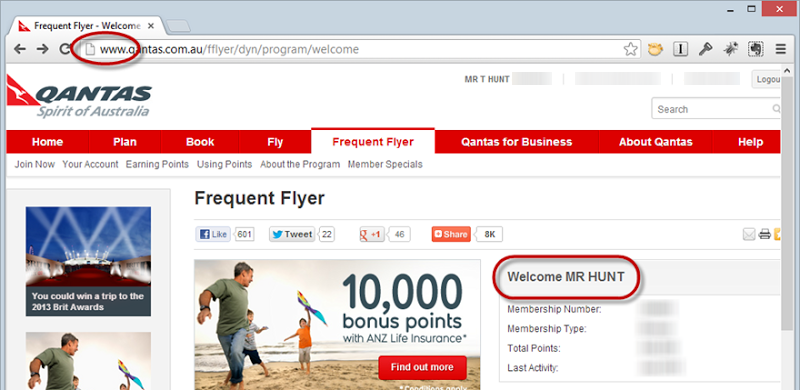
Get your hands on that auth cookie and suddenly you’re viewing my travel history, booking flights on my behalf, buying stuff with my frequent flyer points and so on and so forth.
The fix is easy and twofold: Firstly, you obviously don’t want to be loading pages over HTTP which need to show personal info once you’ve logged in, that’s quite clear. The other thing is that those auth cookies need to be flagged as “secure”. I wrote about this in detail recently in the post titled C is for cookie, H is for hacker – understanding HTTP only and Secure cookies but in short, cookies have an attribute called “secure” which when set disallows the browser from sending them over an insecure connection. Here’s what Qantas’ cookies look like in Chrome’s developer tools after I've logged in:
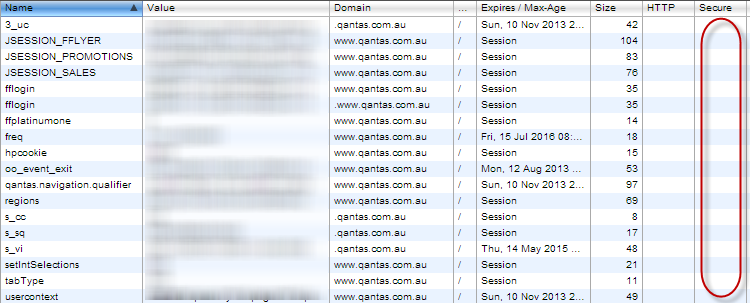
No secure cookies! Some of them shouldn’t be because they relate to browsing habits outside of my authenticated session, but some of them definitely should be and that includes the multiple auth cookies that are passing my frequent flyer account number around.
4. Mixed mode HTTP and HTTPS
Continuing with the HTTPS theme, another improper implementation is when a page loaded securely over HTTPS then embeds content insecurely over HTTP. This was one of the many (many, many) things that Tesco got wrong as it means you present your users with a rather disconcerting message like this:

That’s pretty clear – “Don’t load”! Not particularly reassuring, but assuming you do load the page, here’s what you’ll see:
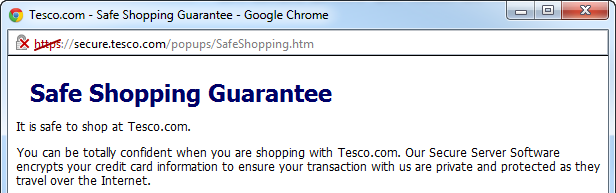
The usual assurance provided by the HTTPS scheme and the padlock has a great red cross through it. Nasty (particularly on a page designed to convince you of their security!)
What’s so bad about this? I mean the three HTTPS objectives I outlined earlier – assurance, integrity, privacy – still apply to the page, right? To the page itself as loaded over the wire, yes, but unfortunately things go downhill from there.
Here’s a scenario: a page is loaded over HTTPS which therefore means an eavesdropper cannot modify the contents. However, that page then embeds JavaScript which is loaded insecurely over HTTP which means that it can be intercepted and modified. So that’s just what an attacker does and the modification includes embedding JavaScript to siphon off credentials just like the Tunisian government did earlier. It’s that simple.
The easiest way to identify mixed mode is just to look for the browser warnings you see above. Different browsers will present the warning in different ways, for example in Internet Explorer:

You can also often see more information by clicking on the padlock icon, here’s Chrome (sorry Qantas, I’m calling you on bad security again!):
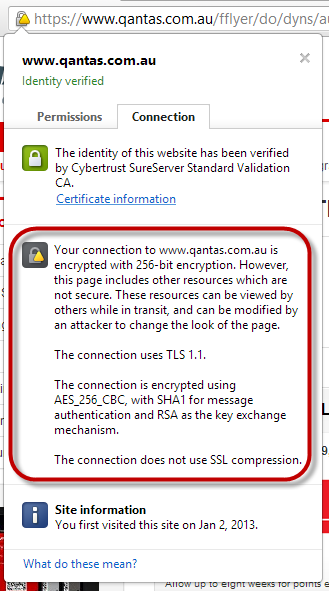
But that doesn’t tell you what was loaded insecurely. To do this, all we need to do is look at the requests made by the browser and the Developer Tools in Internet Explorer (just hit F12) are a great way of doing this. Here I’ve simply looked at the network requests made to load the Qantas website and identified the request that was sent over the HTTP scheme:
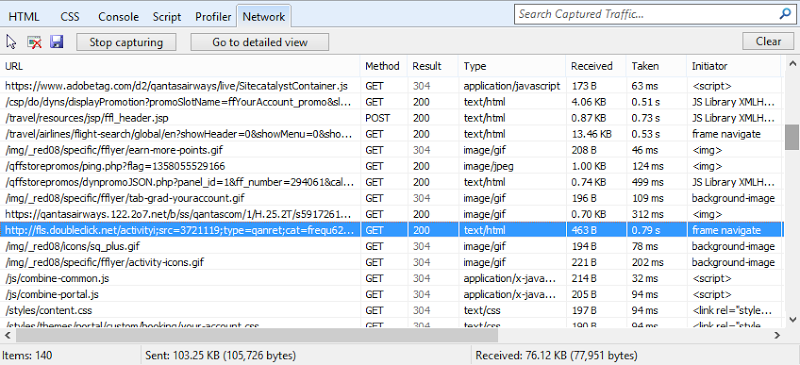
And there we have it; a single request designed to set a tracking cookie and now you’re being told the whole page can’t be trusted!
5. Cross Site Scripting (XSS)
This is the one area where some folks might argue a little exploring is no longer playing nice. However, assuming we’re talking about reflective XSS (the kind you only see when they payload is passed in via the request) and not persistent XSS (the kind you put in the database and gets served to everyone), I reckon, in my humble opinion, there’s no harm done assuming you don’t then go out and leverage it in an attack.
Moving on, you can observe reflective XSS when content such as HTML tags and JavaScript is able to be passed to a page (usually via query string or form post data) and rendered into the markup thus changing the way the page behaves. Take a page such as Billabong’s registration page:
Now let’s manipulate a few query string parameters and the page can be modified to include Bugs Bunny and Miranda Kerr:
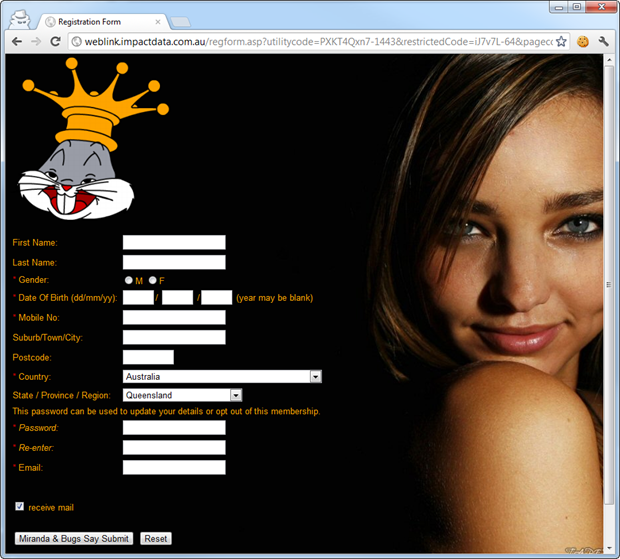
Clearly this is pretty innocuous but it demonstrates that an attacker can modify the page behaviour if they can engineer a victim to click on a carefully crafted link to the site. That link may rewrite the page contents to something quite different, serve the victim malware or even steal their cookies and hijack their session. There are many, many ways that XSS can be used to do nasty things and the detection of the risk is very simple.
Usually it takes nothing more than wrapping untrusted data (remember, this is the stuff your users provide to the system), in an italics tag to confirm the presence of XSS. For example, if I search for “Earth-shattering <i>kaboom!</a>” on a website and it then says “You searched for Earth-shattering kaboom!”, we have a problem. Instead of correctly output encoding the angle brackets into < and > it has rendered them exactly as provided to the source code and thus changed the actual markup rather than the content.
It’s a similar (although arguably more prevalent) problem with untrusted data rendered to JavaScript. What you need to remember is that encoding differs from context to context; you can’t encode angle brackets like you would for HTML, instead they become %3Ci and %3E. Developers often make the mistake of doing this very manually (“if char is < then replace with %3Ci”) which inevitably leads to gaps in the encoding logic so testing a range of different characters often yields results where the obvious ones won’t.
6. Password reminders via email
Nothing of a sensitive nature goes into email, it’s that simple. You should never, ever receive an email like this:
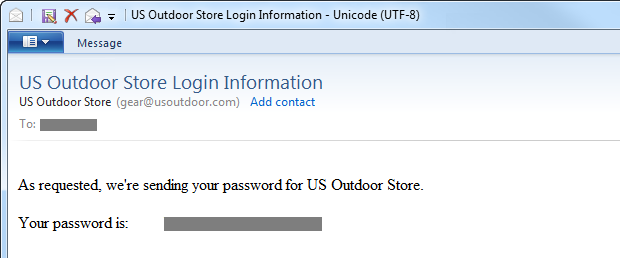
There are a couple of reasons why and the first one is that email is simply not a secure transport mechanism. Whilst it’s possible to secure the connection to an outbound SMTP server using SSL (SMTPS), there’s a lot that happens downstream from there with no guarantee that transport layer encryption is present on each downstream node. Of course there are options like PGP Email but I’ve never seen this used in a password reminder from a website. Ever.
The other issue is that your mailbox is simply not a secure storage facility. Of course there are many different mail providers with many different implementations but the only safe assumption is not to store sensitive data in there. Websites that email credentials put users at risk not just on their own site, but also on other sites due to the (unfortunate but real) propensity for people to reuse passwords. We’ve seen password reuse exploited before through cases like the Gawker Acai berry tweets. It’s a real risk.
The only suitable way for a website to assist a user who has lost heir password is to provide a secure password reset feature. This means emailing a time-limited, single use token that allows a new password to be set on the account and a confirmation email sent to the user afterwards. That’s a pretty simple mechanism but there are still numerous sites doing the wrong thing and sending the original password in email.
7. Insecure password storage
The previous point around emailing passwords is only possible because passwords are not stored correctly to begin with. Let that just sink in a bit and allow me to repeat: if a website is even able to email you your password then they’re not satisfactorily protecting it. You’ve got three common ways of storing passwords:
- In plain text
- Encrypted
- Hashed
The first point is pretty clear – there is no cryptography involved in the storage of the password. One little SQL injection risk let alone disclosure of the database and you’re toast – every password is immediately readable.
Encryption is at least some attempt at secure storage but as I’ve often said before, the problem with encryption is decryption. Once you’re talking encryption you’re talking key management and that’s not something we do well enough, often enough, particularly when it comes to websites (keys in config files, anyone?). What it usually means is multiple points of potential failure when a system is breached.
The most appropriate means of storing passwords is with a strong hashing algorithm. That doesn’t mean a single hit of MD5 or SHA1 (or any other SHA variant for that matter) and it also doesn’t mean just salting it before it’s hashed. I go into a lot more detail about this in Our password hashing has no clothes but in short, we’re often doing hashing wrong and what you really want is a computationally expensive algorithm designed for password cryptography.
Here’s why this is important:

This is an AMD Radeon 7970 consumer-level graphics card. You can buy it for a few hundred bucks and it can crack up to 7.5B hashes per second. Yes, that’s with a “B” so in other words 7,500,000,000. Crikey! Without delving into the nuances of cryptographic hashes here (the “no clothes” post above covers that), the point is that you have to choose the right hashing algorithm. Cracking is still possible, but what if we could bring that rate down by, say 99.99% then it poses a very different value proposition to an attacker.
In the context of this post though, there’s a very easy way to tell when a password hasn’t been stored as a hash – you can see it. That’s usually via the previous risk where it’s emailed to you but sometimes it’s also represented in the UI (more on that a little later). Another common way that poor password practices are disclosed is when an operator knows it, for example when you call up for support. Now identity verification is just fine and there are multiple ways to do that, but using the same credentials for web login and customer service verification is fraught with problems, not least of which is the fact that your personal credentials are visible to other humans whether that be by them looking at them in the system or people verbally providing them to operators.
You start to understand more about why this is a problem when you see stats like these:
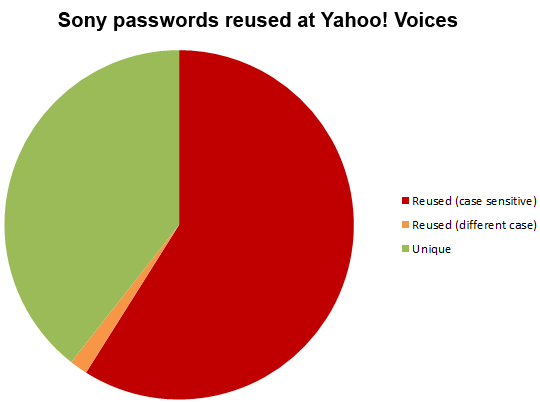
When 58% of people are reusing credentials (and many studies will show far higher levels than that), the risk of sloppy password management by a website starts to have much greater reach than just their own site, they’re jeopardising customers’ other sites because rightly or wrongly, there’s a pretty good chance those credentials have been reused elsewhere.
8. Poor password entropy rules
Here is a very simple password fact: the longer it is and the more characters of different types it contains in the most random fashion possible, the better it is.
Conversely, the more constrained a password is whether that be by length or particular characters or even entire character sets, the more likely it is to be cracked if push comes to shove.
Consequently, this is bad:
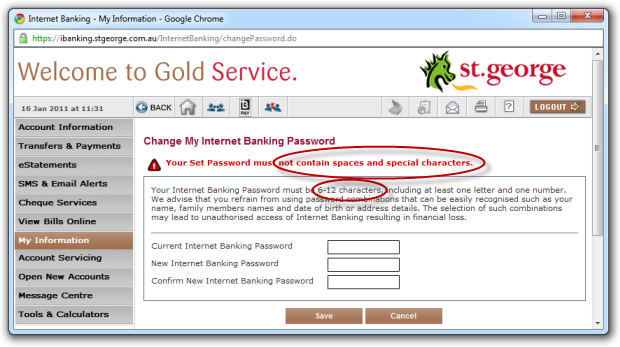
But this is even worse:
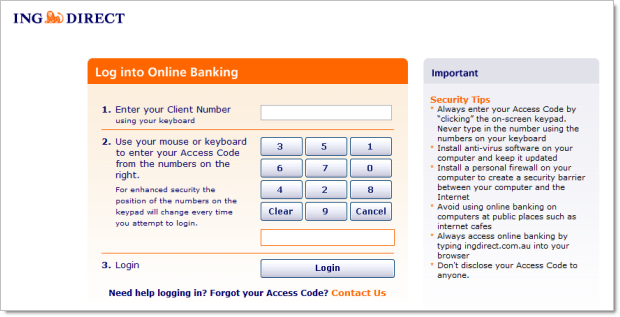
These are examples taken from my 2011 post on the Who’s who of bad password practices – banks, airlines and more where an alarming number of websites were placing arbitrary constraints on passwords. A follow-up post found 3 major reasons why these constraints exist and frankly, they’re all pretty weak excuses.
We need to come back to why this is so important: in the last risk above about password storage I mentioned cracking 7.5B passwords per second with a consumer level graphics card. Now, imagine you bank with ING Direct using a 4 digit password, their database gets breached and the hashed accounts are leaked – the hash is now the only thing between the password being protected and an attacker gaining access to it and using it anywhere it’s still valid, either on the original site or places it’s been reused. An attacker can compute the entire key space of hashes in 1/750,000th of a second. Clearly ING felt this might be a risk so since this post they strengthened their password policy… all the way up to 6 digits, or in other words, 1/7,500th of a second. Your password is toast. But strength increases exponentially so the longer a password becomes and the more characters it contains, the stronger it gets. It’s that simple.
Constraints of any kind on password fields (short of perhaps just one on a very long length) are just not on – there’s simply no good reason for it today. In fact I also made the point a little while back that you should expressly allow XSS in your passwords – no sanitisation at all! The thing is that per the previous risk on storage, passwords should never be redisplayed in any context anyway so let customers go nuts.
9. Denial of service via password reset
Here’s one that you often see gotten wrong: password reset processes that immediately disable the old password. It looks like this:
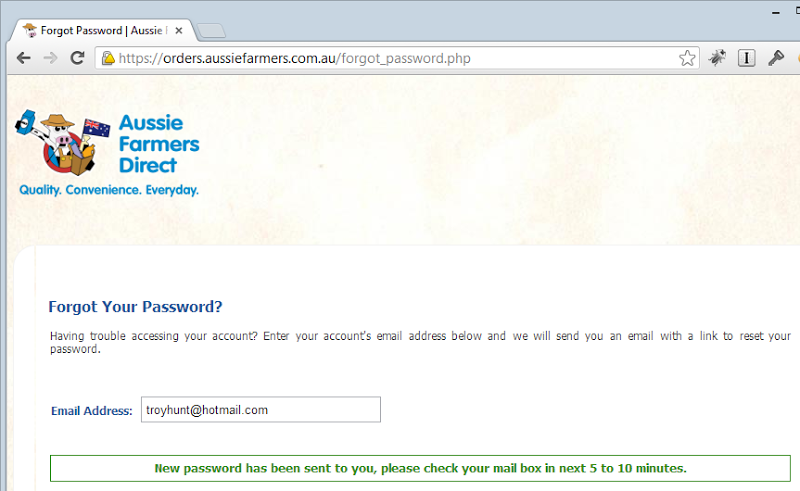
Now that might not seem too bad, but the problem is that it poses a denial of service risk (there’s also that mixed mode HTTP / HTTPS warning we looked at earlier). Here’s an example: you know someone who uses the Aussie Farmers Direct website and you want to make life a bit hard on them so you reset their password and bingo – they can no longer log in. Now of course they can go and grab the new password from their inbox (or junk mail) and log themselves in again, but they’ll probably want to then change it which adds another layer of inconvenience. This sort of practice can be used as an attack, for example it can take someone out of the running just before the end of an auction so the impact can extend beyond the realm of just mere inconvenience.
The correct way to issue a password reset is to send a time-limited, single use token to the recipient. This gives only the legitimate owner the ability to change their password and it does so without breaking the earlier rule of emailing a password that can then be used beyond the reset process. You can read more about this and other aspects of password resets in Everything you ever wanted to know about building a secure password reset feature.
10. HTTP only cookies
People often don’t think a lot about cookies but those little bytes of information in the header have hidden depths. They can also be pretty damn important to the security of the website and thus need to be appropriately protected. For example, it’s usually cookies that are used to persist a user’s authenticated state across requests. If an attacker can get hold of that cookie then they can hijack the session or in other words, immediately take on the identity of the victim.
I wrote about this recently in C is for cookie, H is for hacker – understanding HTTP only and Secure cookies, the latter part of which we looked at in the third risk in this post. For now though, the important thing to understand is that cookies may have an attribute set that is referred to as “HTTP only” which you can easily view from any tools which can inspect cookies such as Internet Explorer’s developer tools:

Here’s the party trick that HTTP only cookies have: they can’t be read by JavaScript on the client. Keeping in mind that there are cases where you want JavaScript to be able to access cookies, in many situations it’s only the server that needs to access those cookies. For example, when you logon to a website it’s usually an auth cookie that’s returned by the server and then automatically sent back again with each new request. This is what enables the website to see that you’re still authenticated.
This is what also enables session hijacking; if an attacker can get that cookie then it’s all over red rover – they can now become you. A popular means of session hijacking is to leverage an exploit such as XSS to send the cookies to an attacker. For example, an attacker may socialise a link which causes JavaScript to be embedded in the page which accesses document.cookie and makes a request to a resource which they own whilst passing the cookies along in the query string.
When we look at the response after logging into a site which doesn’t properly protect cookies with the HTTP only flag – such as Aussie Farmers Direct (again) – we see something like this:

What we can see here is that the PHPSESSID cookie is not flagged as HTTP only. All it would take is one little XSS risk to be combined with this and things would start to get very ugly.
11. Internal error messages
I’ve written a bunch about disclosure of internal error messages in the past. For example, there was Kogan with their massive leakage last year:

This included everything from framework versions to code locations to database credentials. This was running on Django but I’ve written about equally bad practices in ASP.NET, such as the masses of exposed ELMAH logs that are easily discoverable via Google. There were 11,000 easily discoverable ELMAH logs exposing authentication cookies when I wrote about this early last year:
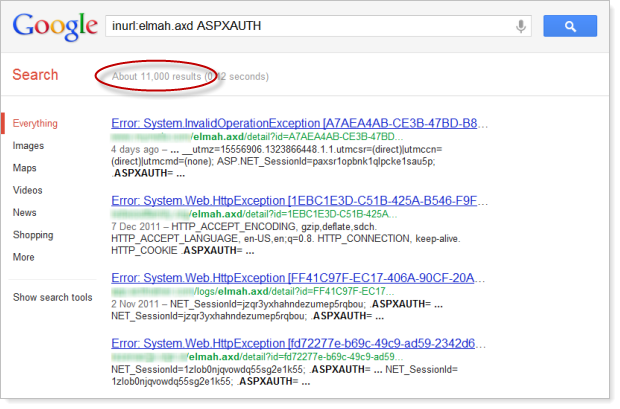
It’s, uh, kinda gotten a bit worse since then:
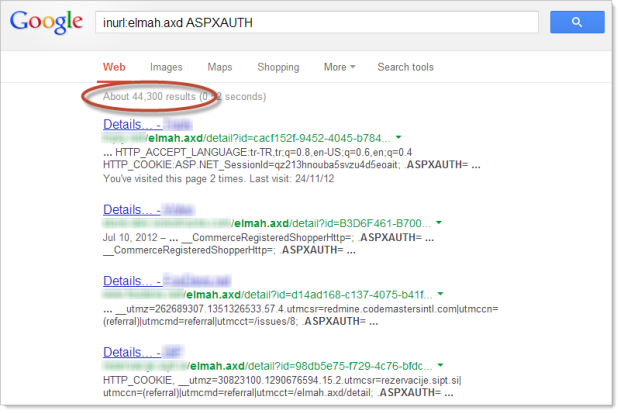
Of course the problem with internal error messages is that they can give an attacker a massive head start when it comes to compromising a vulnerable website. Naturally this will depend on the nature of the data exposed in the error, but in a case like those ELMAH auth cookies it makes session hijacking an absolute cinch. Other examples of exposed information can include anything up to and including connection strings to database servers that are publicly accessible. Ouch!
How you tackle this will differ by framework but the simple message that’s relevant across the stacks is this: keep internal errors internal! Configure your app to return generic error messages that don’t leak any info about how the app is put together. It’s not only more secure, it’s a whole lot more user friendly.
In terms of detection, there are enough times where an error message will just reveal itself during the organic use of the website. That was the case with Kogan above but you can often cause an internal error simply by a minor change to the request structure. For example, replacing “id=123” with “id=abc” and an exception is raised when the parameter is attempted to be converted to an integer without the appropriate error handling. Or simple appending an illegal character to a URL – an angle bracket will often cause an exception.
12. Path disclosure via robots.txt
Everybody know what robots.txt does? Here’s a quick recap: when search engines come knocking to discover what’s on a website so that it can be indexed and made easily searchable, in theory the search engine will look for a file named robots.txt in the root of the site. This file contains information which complies with the Robots Exclusion Standard and the idea is that it helps search engines with both what to index and what not to index.
The reason why the “what not to index” bit is important in the context of web security is that often developers will use the “Disallow” syntax to prohibit the search engine from making information on their site discoverable. For example, they may have some sensitive documents or administrative features they don’t want people stumbling across via carefully crafted Google searches (everyone is aware of Google Dorks, right?) so they politely ask the search engine not to crawl that particular piece of content.
The problem is that you end up with sites like GoGet and their robots.txt file which looks just like this:
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /components/ Disallow: /editor/ Disallow: /help/ Disallow: /images/ Disallow: /includes/ Disallow: /language/ Disallow: /mambots/ Disallow: /media/ Disallow: /modules/ Disallow: /templates/ Disallow: /installation/ Disallow: /bookings/secret/
See the last one – “/bookings/secret/”? The problem, of course, is that just naming a path “secret” does not make it so! Now GoGet isn’t immediately disclosing anything of risk (although they might want to review the earlier point on insufficient use of TLS), but there are many examples where that isn’t the case.
The thing about robots.txt is that it very often gives an attacker a starting point. It’s one of the first things to look for when trying to understand how a site is put together and where features that are intended to be private might exist. But most importantly, a disallow declaration in the robots.txt is never a substitute for robust access controls. Regardless of how much obfuscation you throw at a path, you absolutely, positively need to implement access controls and work on the assumption that all URLs are public URLs.
13. Sensitive data leakage via HTML source
Everyone knows how to view the HTML source of a page, right? It’s always a variation of the classic right-click –> view source or for the keyboard ninjas, CTRL-U in browsers such as Chrome and Firefox. But of course that’s not the only way to view source, you can always proxy the traffic through tools like Fiddler or Charles and inspect the page contents at that point. The point is that HTML source, for all intents and purposes, is readily viewable and not the place to store any sensitive data. Yet we have examples such as MyDish.co.uk doing this in the browser:
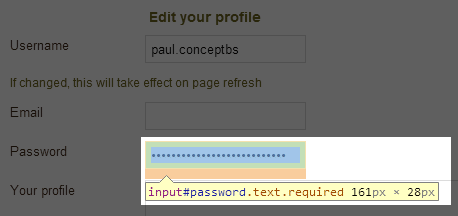
Which is driven by this in the source:
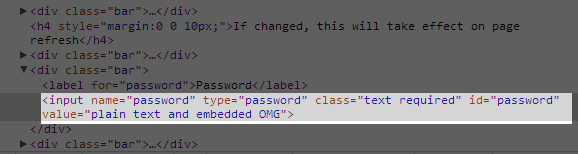
Now this is clearly just crazy stuff – there’s absolutely no reason to pre-populate this field and of course just the fact they can also means that they’re not storing the password correctly as a secure hash to begin with. Whilst this risk only discloses your own password, if an attacker could hijack the session then they could easily grab it from the HTML source (and then leverage everywhere it’s been reused on other sites).
This is a rather extreme example but I’ve seen many, many others which expose data they shouldn’t in the source. Just viewing the source code of various pages in a site can disclose a huge amount of information about how it’s put together and often disclose risks in the design. On many occasions now I’ve seen comments in the source which disclose varying levels of information about the internal implementation of the source. In fact commenting of code itself can be very revealing, particularly if it points to paths that may not be properly secured or contain their own vulnerabilities.
Another angle is the nature of the information disclosed through source in the legitimate function of the website. On occasion I’ve seen SQL statements in hidden fields which not only discloses the structure of the database but also opens the site up to parameter tampering and potentially SQL injection. Speaking of which…
14. Parameter tampering
Here’s an interesting one – when you search Action Recruitment for jobs you’ll notice a URL a little like this:
http://www.actionrecruitment.ie/search.html?module=next_results&basic_query=SELECT%20*%20,%20'1'%20AS%20Score%20FROM%20posting%20WHERE%20%20%20%20(%20CategoryID%20LIKE%20'%')%20%20%20ORDER%20BY%20Title%20&start=10
Can anyone see the problem with that? Let me break out the important bit and remove the URL encoding:
SELECT * , '1' AS Score FROM posting WHERE ( CategoryID LIKE '%') ORDER BY Title
That’s right, you’re looking at SQL statements embedded in the query string. For the sake of posterity should the site design change in the future, here’s what that page looks like right now:
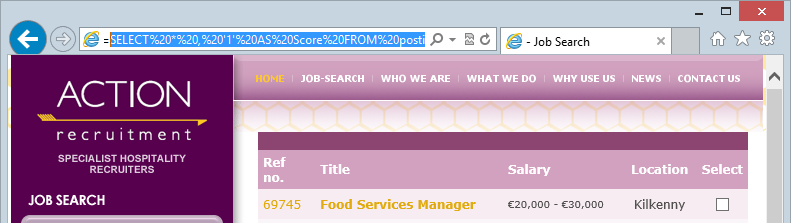
The problem here is that should this site indeed just take the query string parameter and execute it as an entire SQL statement, well, it actually poses two problems. The first is that tampering can produce results outside the intended function of the app. This could be minor – such as returning more records – or more significant such as returning someone else’s records. The second issue is that it could be at risk of SQL injection if manipulating the parameter changes the structure or behaviour of the database query itself. This is where things become a lot less grey and a lot more black…
The intention of this post is to draw attention to detecting risks which don’t step into the realm of what most reasonable people would deem “hacking”. Probing for SQL injection flaws very quickly descends into that realm and that’s not somewhere you want to go anywhere near on someone else’s site if you’re trying to play nice.
15. Clickjacking and the X-Frame-Options header
A few days ago I wrote about Clickjack attack – the hidden threat right in front of you and showed just how easily a clickjacking attack can be launched. In essence, this attack boils down to placing the target site in an iframe and whacking the opacity of it down to zero so that the site underneath that shows through. The underlying site is then structured to show tempting links which line up perfectly underneath the target site so whilst the victim thinks they’re clicking on a link on the hoax site, they’re actually clicking a hidden link on top of that which is served by the victim site above it.
Imagine this scenario:
This image shows the victim site sitting at 50% opacity (it would normally be at 0% therefore hidden), so you get a sense of how everything lines up. The impact of the clickjacking attack is commensurate with the action being performed by a simple click; it could range from a social media endorsement such as a “like” all the way through to performing a banking action.
The mitigation is simple to implement and also simple to observe, you just need to look for the response header. By example, here’s what you’ll see on ASafaWeb (my own site we’ll come back to shortly) using the Chrome developer tools:

As you’ll read in the post above, there are a few different possible values for this header, the main thing is that unless you’ve got a good reason to allow the site to be embedded in a frame absolutely anywhere, there should be an X-Frame-Options header returned along with each request. You can also check this with ASafaWeb, this test has been added to the software just this week.
16. Cross Site Request Forgery (CSRF)
In many ways HTTP is quite clever. For example, you can authenticate to a website and then in unison with the web browser it will happily send your auth cookie back to the website with each request automagically.
In other ways HTTP is rather foolish. For example, you can authenticate to a website and then in unison with the web browser it will happily send your auth cookie back to the website with each request automagically. Oh – even when you didn’t actually intend to make the request!
It’s that last bit that CSRF exploits. The risk here is that if an attacker can trick a victim’s browser into making a request to a website they’re already authenticated to and modify the parameters of the request to do the attacker’s bidding, we might have a bit of a problem. For example, if a banking website allows an authenticated user to make a request such as “/transfer/?amount=500&to_account=1234567890” and it actually impacts a change (such as transferring money), then we have a CSRF risk. That’s a very simplistic example and I do go into a lot more detail in part 5 of the OWASP Top 10.
Let me give you a real world example. When you’re logged in to Toys R Us, if you make a POST request like this:
http://www.toysrus.com.au/scripts/additemtoorder.asp
And you send the following form data:
productid: 1675220 quantity: 1 injectorder: true
You will add one of these to your cart:

Now of course there is nothing wrong with a Lego Star Wars X-wing model, assuming you actually wanted one! The problem is that all an attacker needs to do is trick your browser into reproducing the same request pattern – just the URL and form data – and you’ll have one of these in your cart. This execution of this can be extremely simple, for example, visit an attacker’s page where there are hidden form fields reconstructing those three pieces of data I showed earlier on and set the action to the URL which adds the item to the cart. Now give them a big “Win free stuff” button (which is how the attacker lured them in to begin with) and badaboom – they’ll submit the request along with their authentication cookie to the Toys R Us website and have a shiny new Leo model in their cart! The attacker might even target a hidden frame so that the victim can’t see the response from the Toys R US server.
That’s a very simplistic example in a low-risk scenario. There are more complex executions and obviously more risky scenarios and they’re possible because the CSRF attack is able to reproduce the appropriately structured HTTP request which, of course, also sends off the authenticated user’s cookies because that’s just how HTTP works.
The mitigation is detailed in the post I mentioned earlier and it’s all about using an anti-forgery token in the form with a corresponding cookie. If both of these values don’t reconcile when the request is made then it’s considered to be forged. This works because an attacker cannot simply recreate the correct form data without grabbing the token from the website which is unique to the user. The anti-forgery cookie will be sent automatically – that’s fine – but its mate from the form won’t be.
What’s important in the context of this post though is what a secure request should look like. Here’s what happens when I logon to ASafaWeb and there are two important bits of info I’ve highlighted:
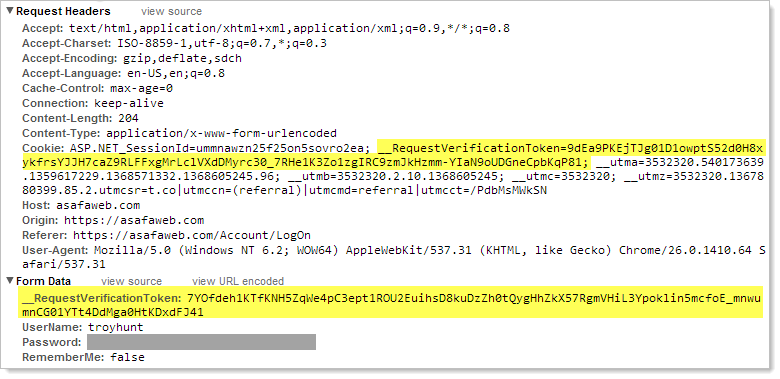
This is the anti-forgery token in both a cookie then further down in the hidden field. This is the way ASP.NET names them, other web platforms may show slightly different names but the point is that the token exists and without it, the request fails. This should be in every location where an inadvertent request could have an adverse impact for the user. If you don’t see it – like on Toys R Us – then a CSRF risk is almost certainly present.
Scorecarding websites with ASafaWeb
There’s a lot to remember when securing websites and indeed what’s listed above only even scrapes the surface. However it’s a good starting point and these are all risks that have many precedents of being exploited for an attacker’s gain. They’re also all risks that as I stated from the outset, can be remotely detected without stepping into the evil hacker realm. You can be responsible in detecting these risks.
I often see tweets like this:
Clearly this is somewhat of a rhetorical question as it’s very unlikely the culprit is aware of the risk. Moving on, rather than just having people point website owners to a lengthy post covering multiple issues as is the case above, I wanted to provide something more succinct that talks about specific risks then provide further reading from there. Given the sort of risks I’ve outlined throughout this post, I wanted to provide an easy mechanism for assessing, recording and sharing them so here it is – the ASafaWeb Scorecard:
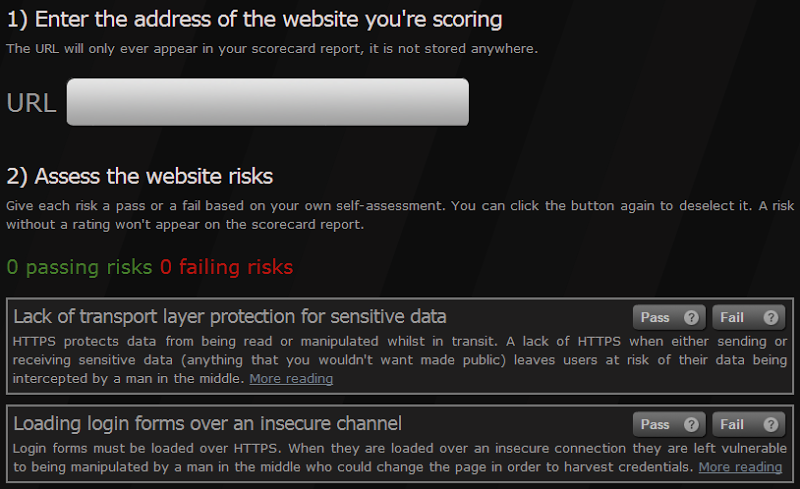
This is very simple mechanism and it works like this: first you enter the URL of the site you’re assessing. Next, for each of the 16 risks outlined above there’s an entry on the ASafaWeb Scorecard along with “Pass” and “Fail” buttons. You then go through and self-assess the site, clicking the appropriate button as you go (you can click the same button again to de-select the risk).
This is not a dynamic analysis tool like the ASafaWeb scanner is and that’s simply because for the most part you need to be a human to detect these issues. For example, you actually need to do a password reset and assess the resulting email in order to discover that it’s not being stored satisfactorily.
As you complete the assessment you’ll see the results appear in a hash in the URL. What this means is that a completed assessment has a URL something like this:
When the URL is received by someone and they open it up, the Scorecard appears with a little summary and the risks in read only mode so that they can’t be directly edited again:
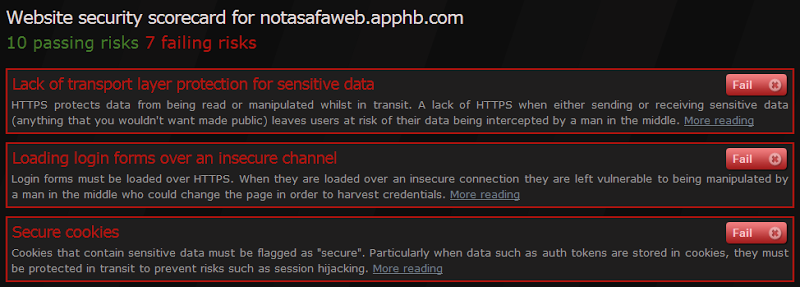
Mind you, it’s easy just to change the URL and as a result the Scorecard values, but this isn’t intended to be a tamperproof rather it’s a means of sharing information via URL alone. When the Scorecard is opened up it won’t show any risks that haven’t been given a pass or a fail grade so you can elect exactly what data you want to share. Only want to raise one risk – fine, just select that. Only want to alert someone to failing risks – likewise, just send those. You choose.
There are two reasons I’ve done this and by far the most important is that I don’t want to be building up a repository of vulnerable sites! By persisting the risk in the URL parameter the address contains all the information that’s required to understand what’s going on. Secondly, because that URL is so self-contained it’s easy to pick up and send to someone so it’s very transportable.
Ultimately that’s the goal – to create a mechanism to easily report on risks and share them around. I’d love to see this tool being used in place of trying to explain risks via Twitter and engaging in the banter that often ensues in an attempt to try and explain things in only 140 characters a shot. It would be great if this gains some traction and I’d love feedback on the effectiveness of it, including if there are further risks that should be included in an attempt to encourage people to seek them out.
And that brings us back to where this post started out – hacking yourself first. Using the Scorecard above, the chances of you finding at least one risk in your own site is very high and if you can do that and mitigate it before someone exploits it then that’s a very good thing indeed. And likewise, if you do find issues in someone else’s site, the risks above should keep you out of trouble if you detect and report on them responsibly. Hopefully the Scorecard feature helps this process and makes the web, well, ASafa place!
More hacking yourself
The risks outlined above are ones I tend to use as a starting point either to assess sites I’m involved in building or to get a sense of the relative security position of someone else’s site. They’re not exhaustive though and as I said at the outset, there are other risks such as SQL injection which are serious, prevalent and will very likely cause damage if probed a little further.
A good resource for further probing is the OWASP Testing Guide. This will take you through hundreds of pages of steps that go into a lot more detail than what this blog post alone covers. If you want to get really in depth then there’s my recent Pluralsight video training which gets right down into the guts of how these risks are exploited and mitigated across just over eight hours of material.