I get a lot of people popping up with data breaches for Have I been pwned (HIBP). There’s an interesting story in that itself actually, one I must get around to writing in the future as folks come from all sorts of different backgrounds and offer up data they’ve come across in various locations. Recently someone sent me a list of various data breaches they’d obtained, including this one:
InstantCheckmate 2015 - 80M entries
On the surface of it, that’s a phenomenal incident and it would be the second largest data breach ever loaded into HIBP. But it turned out to be something quite different and that in itself makes for an interesting story. Let me walk you through what was provided to me, the research I did and how I eventually joined together an entirely different set of dots.
Understanding the data
The data consisted of 396 files that looked like this:
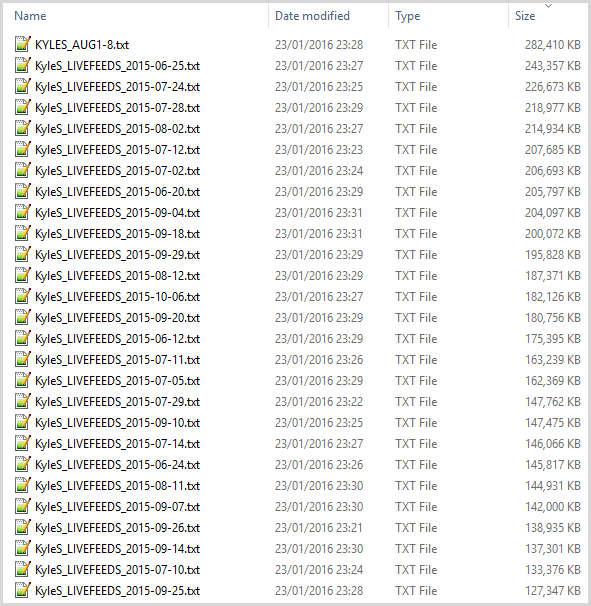
That’s just the first 27 of them in descending size. Just as an indication, here’s the first few rows of that largest file:
email,ip,url,joindate,fname,lname,address,address2,city,state,zip,phone,mobile,dob,gender [redacted]@gmail.com,162.158.22.[redacted],instantcheckmate.com,2015-08-06,[redacted],[redacted],,,San Francisco,CA,94107,,,, [redacted]@gmail.com,70.198.4.[redacted],creditcardguide.com,2015-08-06,,[redacted],,,Mitchell,SD,57301,,,, [redacted]@gmail.com,166.137.139.[redacted],creditcardguide.com,2015-08-06,[redacted],[redacted],,,,,,,,,
In all, there are 81,191,621 records of similar structure across the nearly 400 files. Across these, there were a total of 30,741,620 unique email addresses. Aspects of this are very data breach-like: personal details spread across a large collection of files adhering to a common structure. Yet this was one of those ones which didn’t quite “smell right” and as I dug into the data, I began to realise I was looking at something quite different. Let me explain.
Verifying the “breach”
Usually when I’m verifying a data breach, the first thing I’ll do is check out the site it allegedly came from. In this case, that’s instantcheckmate.com:
The whole point of the site appears to be to dig up information on people; prospective employees, a spouse and well, here’s some of the options they suggest based on their testimonials:
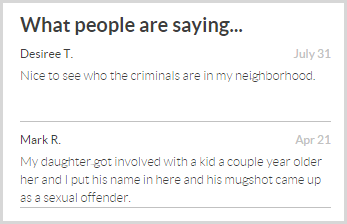
Spying on your neighbours or poking around your daughter’s private life are apparently also on the cards. Given that anybody can search for anybody else, I thought I’d see what I could find on my namesake in Texas:

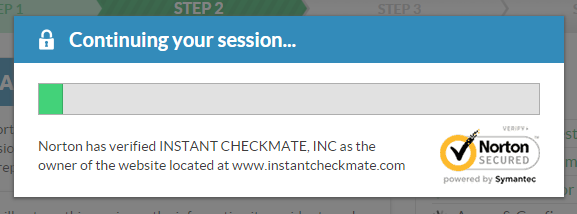
It goes through a bunch of “checks” and shows the progress along the way:
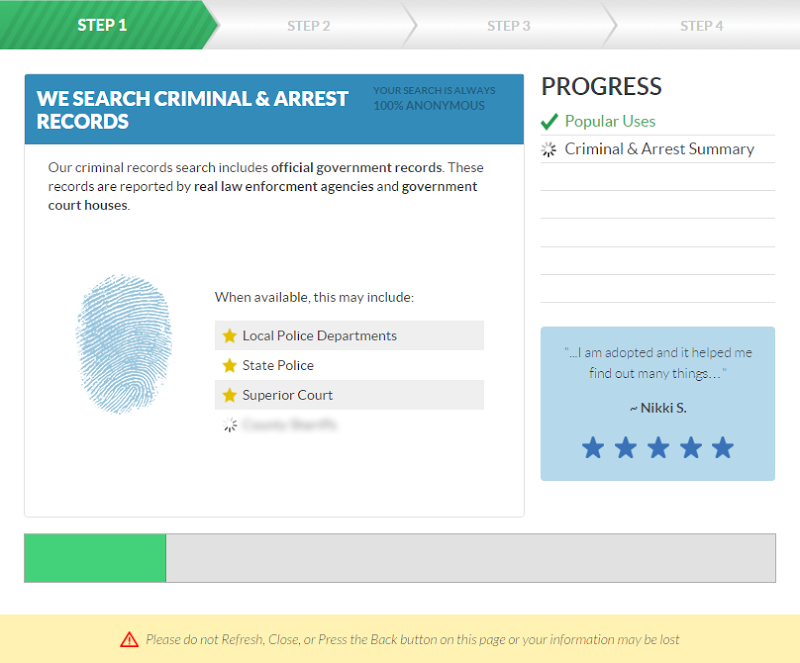
As the green status bar progresses, data in the locations showing the loading indictors above gradually complete as though it’s being populated as queries are run. Only thing is though, all the requests the browser sends during this process are for… images. No APIs returning results or anything remotely related to actually finding information on the individual, it’s all just showmanship. By now, I was starting to think the whole thing might be a bit dodgy, but fortunately the site was then confirmed as legit courtesy of a Norton seal (in case the irony is lost on you, read Here’s why you can’t trust SSL logos on HTTP pages (even from SSL vendors) and then Exploring the Ecosystem of Third-party Security Seals):
I go through a number of different steps and the only request that actually transfers any data backwards and forwards is this one:
GET https://www.instantcheckmate.com/api/check-customer/
{"success":true,"error":null,"loggedIn":false}
Not exactly the sort of response that would indicate any of these checks actually being run. But then I got through to the crux of why I’d come to the site in the first place – data collection. I filled in the following personal details:
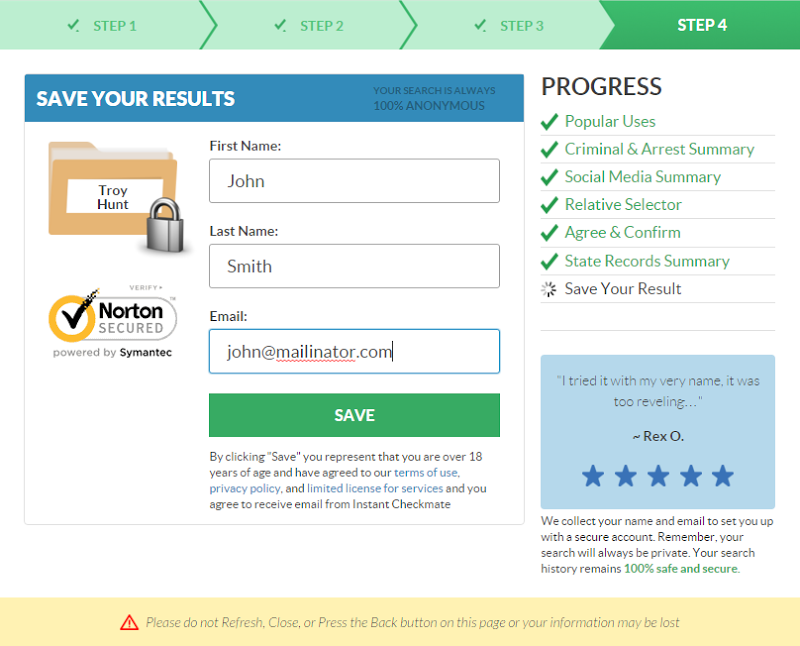
And this time, information was actually sent to the server. The API responded as follows:
{"success":false,"error":"Email already in use","lead":null,"emailInUse":true}
The significance here is that this is that by confirming that the email is already in use, the site exposes an enumeration risk or in other words, the server will happily tell you if an account exists on the site or not. This is the cornerstone of much of the verification process I go through every time I load a breach into HIBP. The “john” alias on Mailinator was simply made up and for those of you who aren’t familiar with it, Mailinator is a free service that allows you to email any alias you’d like and then check it without any authentication or identity verification. For example, here’s John’s and it’s a neat service for what’s probably best described as “throwaway” accounts.
Getting to the point of all this, with an enumeration vector now discovered I could take one of the email addresses from the data I was provided and see if it exists on the site. For example, there’s stella@mailinator.com but… Instant Checkmate didn’t have it on record. Same with other examples – they didn’t exist on the site. I ran some other quick checks as well and I kept coming to the same conclusion – I couldn’t verify that the data had come from the site.
As shady as the site is (and there’s probably another story in there on just how misleading some of their practices are), I couldn’t attribute the “breach” back to them so I needed to look further.
Digging into the data
I wanted to get further clarity on the accuracy of the data because one thing I see a lot of is fabricated breaches. Because the data has both IP address and physical address, there was an avenue here I could pursue. For example, let’s take that first record above:
[redacted]@gmail.com,162.158.22.[redacted],instantcheckmate.com,2015-08-06,[redacted],[redacted],,,San Francisco,CA,94107,,,,
And now do a search on the IP address:
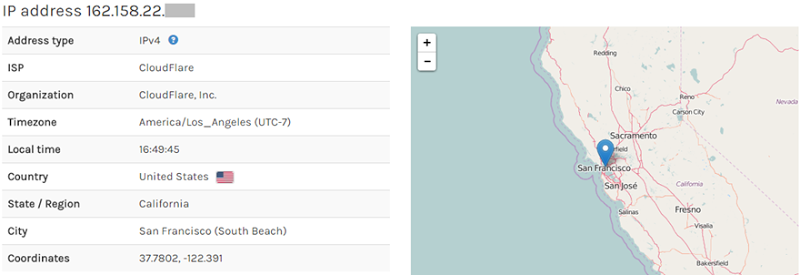
The IP address is located in San Francisco and so is the physical address on the record. I kept picking these at random and kept getting matches; the IP address was always a match to the location. My initial thought was that this likely indicated the person signing up to whatever service had leaked the data was entering their own physical address. In the case of Instant Checkmate, this might indicate that if the data had come from them, we’re looking at the info of the person doing the search, not the person they were searching for.
But the more I looked at the data the more…. good it looked. Too good – people don’t consistently enter the right city and postcode without typos or differences in case or other nuances that us fallible humans are so good at introducing. No, this was way more likely machine generated and given how well IPs were lining up with locations, it was very likely a case of someone on the other end taking the IP of the person who signed up and generating the physical location from it. Assuming that’s the case, it really told me very little about where the data had come from. I needed another angle and fortunately, I have a few hundred thousand of them on hand.
Verification with HIBP subscribers
As of the time of writing, I have 356k people subscribed to the free HIBP notification service and verified as wanting to be on there (they click a link in an email I send them). Every time there’s a paste or a breach loaded into the system, any single one of them who appears in it receives an email letting them know of their exposure. What this also means is that I’ve got a great list of people I can reach out to if I need help in verifying a data breach, something I’ve done on a number of occasions now when I’ve been unable to confirm the legitimacy of the incident.
I sent off a couple of dozen emails to the most recent subscribers asking for assistance and got a number of responses, including one from a girl in New Jersey. She offered assistance so I sent her over her record which was similar to the one above, but this time included the URL prepareyourcredit.com. She confirmed her name was correct but had this to say in terms of the location of the IP address:
A few blocks from a place I lived ~10 years ago.
And as for the URL:
Never heard of it, certainly didn't sign up for it in 2015. My credit is fine so I wouldn't even sign up for a similar service.
Which was interesting because it got me wondering how on earth she came to be associated with the site. She went on to say this:
I did sign up for my share of "earn money by taking online surveys" sites while in college, which is about the right timeframe for that data to have been sold/harvested.
As we went back and forwards discussing the data, the most likely explanation became that she had signed up to that site a decade ago and for some reason it had then been time-stamped last year and was now circulating around the web. Other responses from other people were consistent with the location being correct at some point in their lives, but them having no recollection of the site in the URL. This got me particularly interested in what was at the end of those URLs, so I did some digging…
Source URLs
I imported the entire data set into SQL Server to do some analysis. In there, I found over 900,000 unique values in the URL column. Some of them were due to data integrity issues in the source (i.e. inconsistent delimiters in some files), yet there were still 144 URLs with more than 50k records against them so obviously a large array of addresses.
Here’s the top 20 in terms of how many entries they had (note the double-up on the one that also represents the HTTP scheme):
| URL | Records |
| originalcruisegiveaway.com | 6,315,233 |
| www.directeducationcenter.com | 4,483,469 |
| creditcardguide.com | 3,021,831 |
| instantcheckmate.com | 2,742,961 |
| cash1234.biz | 2,026,161 |
| stimulationserotica.com | 1,948,071 |
| prepaidoptions.mobi | 1,864,010 |
| progressivebusinesssystems.com | 1,812,917 |
| thecouponcastle.com | 1,791,022 |
| employmentcalling.com | 1,663,183 |
| www.alwayscashloans.com | 1,503,810 |
| freerewardcenter.com | 1,476,341 |
| paydayloaneveryday.com | 1,250,648 |
| homepowerprofits.com | 1,209,936 |
| theonlinebusiness.com | 1,102,612 |
| http://www.homepowerprofits.com | 1,083,029 |
| pdlloans.com | 987,104 |
| employmentsearchusa.com | 968,445 |
| getamoneyadvance.com | 964,620 |
| luckylending.com | 952,957 |
Just reading through these, you’ll notice a very common theme. Here’s what the other four in the top five look like (you’ve already seen Instant Checkmate):


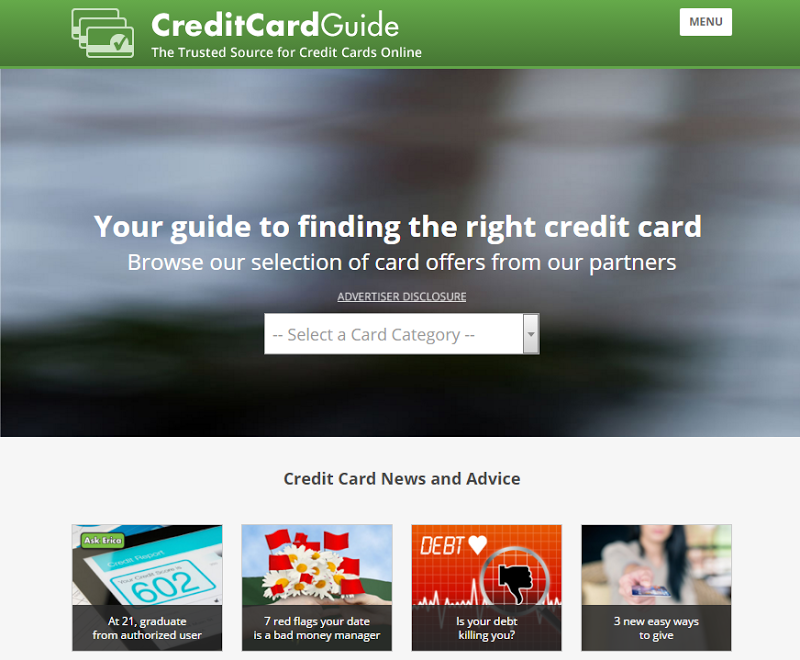
It’s that same sort of sleazy marketing feel – “give us your info and we’ll give you something… maybe” – and it’s the sort of site that most of us end up on accidentally and then get out of ASAP. But “feel” is not enough to start drawing any conclusions on where the data had actually come from, I needed evidence.
I started by looking at the HTML source of the top sites and found, well, some patterns:
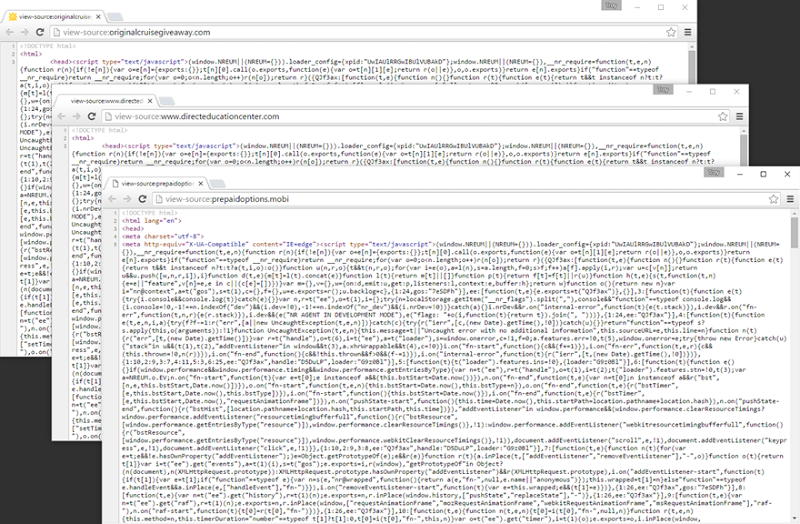
Expecting to find privacy-enabled WHOIS records, I ran a domain search and instead, found this on each of the ones above:
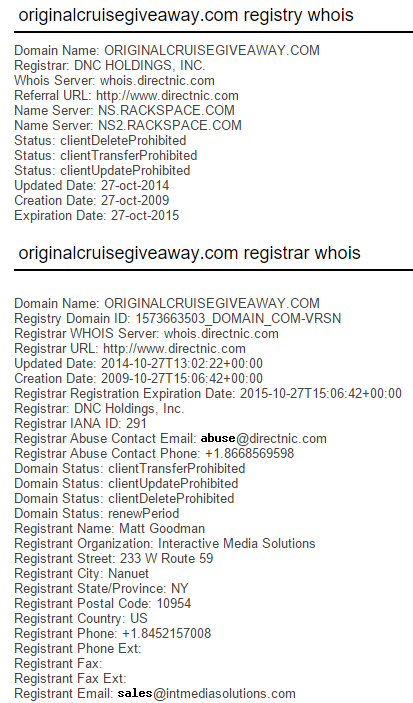
Now this is curious because we have identical ownership across sites designed to help you with your education, win a cruise and get yourself a credit card, not exactly complimentary business models.
I kept probing and found more matches:
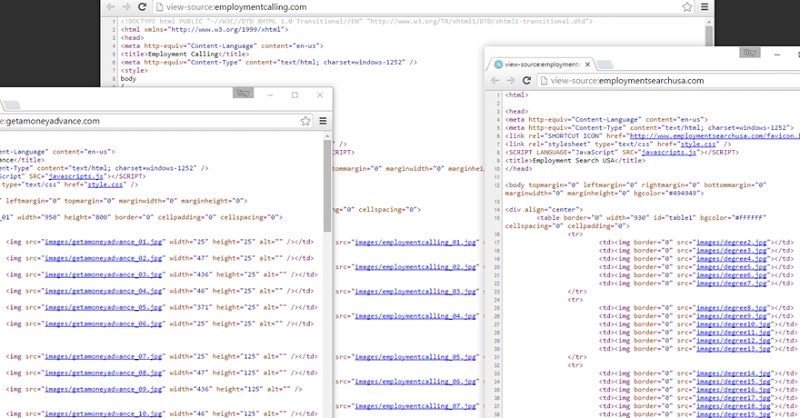
Ok, firstly, tables. But secondly, these ones all had privacy enabled and all used the same name servers:
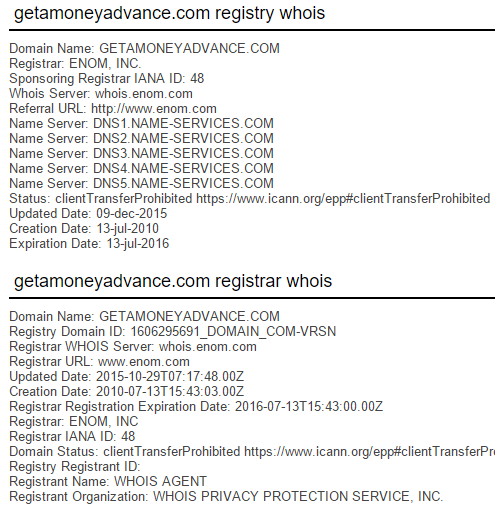
So here we have another set of sites almost certainly from the same organisation, albeit a different one from the first trilogy of sites I showed earlier. Now we’ve got a couple of employment sites and one about money advances which again, are not what you’d consider similar business models… unless the model is something altogether different…
Data harvesting services
Let’s go back to the largest of the sites in terms of the records provided in the dataset and that’s originalcruisegiveaway.com. Here’s how to “claim your spot” (but hurry!):
Once you enter your personal info (or fabricated info…) all you need to do is, wait…

Assumedly, at some point you will end up carrying your bride away on a tropical island (or possibly being carried away by your man, depending on your perspective).
However, there’s a popular saying that if you’re not paying for the product, then you are the product! It wouldn’t be a real solid business model to simply go giving away cruises to anyone who filled in the form, so there has to be another upside. Let’s try the privacy policy and in particular, this section (emphasis mine):
We may sell the personal information that you supply to us and we may work with other third party businesses to bring selected retail opportunities to our members via direct mail, email and telemarketing. These businesses may include providers of direct marketing services and applications, including lookup and reference, data enhancement, suppression and validation and email marketing. Regardless of any State or Federal Do Not Call Registrations, you the customer expressly consent to be contacted via telephone in reference to this offer.
But hang on – isn’t this your data they’re selling? Nope:
Once it is received in our database, any information, including your name, e-mail address, and home address becomes the property of Interactive Marketing Solutions.
This is outrageous! It’s America, so let’s just sue them. Oh wait, can’t do that either:
To the extent permitted by law, you agree that you will not bring, join or participate in any class action lawsuit as to any claim, dispute or controversy that you may have against the Company and/or its employees, officers, directors, members, representatives and/or assigns.
So in short, they own your data, they can resell it and there’s nothing you can do about it. But hey, at least you get a free cruise out of it, right?! Well, no. The web is littered with stories about free cruise scams and it’s entirely possible – no, likely – that this falls into the same category.
But that’s cruises, what about something like the education one? That data is also flying around the web, in fact it was being discussed in a forum on SEO tactics years ago:
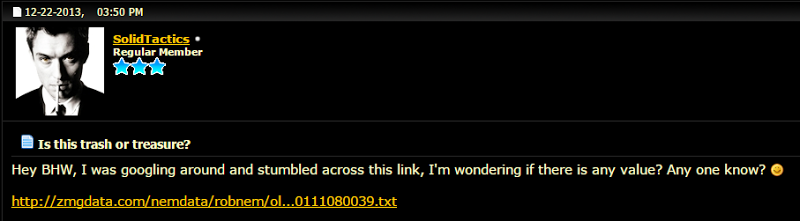
The original data is gone, but the site was archived:
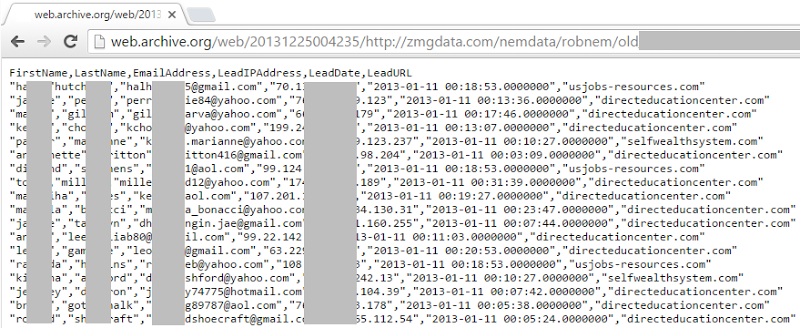
The more I dug into these, the more all these sites conformed to similar patterns – “Hey, give us your details and you’ll get free stuff” – and the clearer it became where the data in the records I was handed was actually sourced from.
Now you may be thinking that this is just data that’s sold or traded in underground circles, away from the public eye and only obtainable by those who mix with this class of, well, “adversary”. But it’s much more public than that, let me explain.
Your data for sale
This brings us to the Special K Data Feed:

Now normally I’d be a bit cautious about linking through to a resource like this but in this case, I feel that more exposure is better simply to illustrate the extent of the problem. There are screen caps of personal data – data I’ve elected to obfuscate here – but as you’ll also read, you need to take these with a grain of salt.
Apparently the data costs “1500$ compared to the 8,000$/month retail rate for it!” which is a little unclear in terms of what constitutes a month, although inevitably it’s a subset of the records handed to me. And why would someone want this data? For all sorts of good reasons:
![]()
This is data for sale – your data for sale – but of course you knew that because you agreed to your data being sold in the terms and conditions of the sites you gave it to, right?! The data here is a very close match to much of what I was given, in fact you can browse through the collection of files (although you can’t open them) and you’ll recognise many familiar filenames from my earlier screenshot.
As you browse back to the root of the site, you’ll find all sorts of data sets from different countries, including “foreign” countries like Australia:
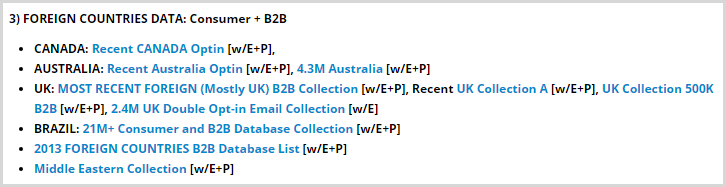
This data is sourced from all sorts of different locations:
5 Million records (w/phones, emails): Collected from several individuals/consumers in Australia, from verticals such as: Debt, Weight Loss, Cell Phone Sales/Accessories, and Sweepstakes/Giveaways!
Now I know what you’re thinking – you’d be blessed to have access to this sort of data and you’re absolutely right!
It's very RARE, but BLESSED when there's 5 Million records of this kind of data. Whether it's for PHONES or EMAIL, you really get a nice PIECE that represents a NEW frontier for NEW PROFITS! Australia, the Island Nation worth swimming on shore for its outrageous outback barbequeing, kangaroos in the wild, and in some areas: a 12-to-1 female to male pop. ratio!
If you like the idea of being the one bloke surrounded by a dozen women while you BBQ your kangaroo (or something like that), take a look at the data they have for you (click for the full-sized image):

This may look like personally identifiable info I’ve just shared but it’s not – it’s fake. The first sign of this is the very first name – “Sheila” – which just seemed way too convenient next to talk about kangaroos and BBQs. It’s frequently a tongue-in-cheek name for Aussie women and whilst indeed there are a number of legitimate Sheilas out there (named Sheila), this was just a bit too coincidental.
What’s not possible is to have all of these people in Western Australia yet have post codes which start with a 4:
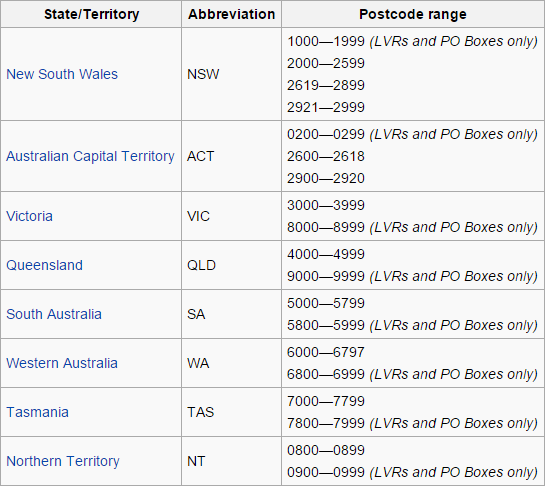
They’re all Queensland post codes in the sample data, yet they all sit next to phone numbers beginning with 03 which is only used in Victoria and Tasmania:

So that’s half the country’s states represented right there in the “sample” data. Let’s try Sheila’s IP address:
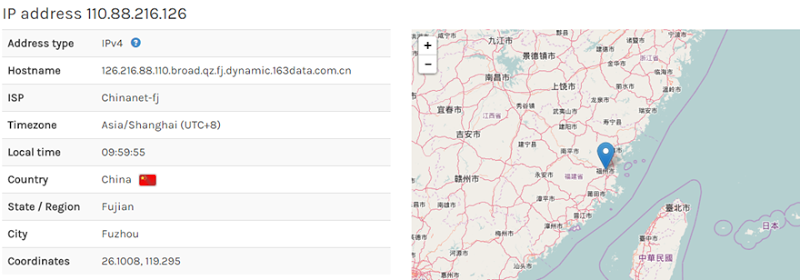
If you’re looking for kangaroos to BBQ there, you’re going to be greatly disappointed!
The bottom line is that there’s a bunch of fake data being sold. Initially I looked at this and was concerned to see names like Kogan there in the source of the data (they’re a legitimate company), but clearly it’s all fabricated anyway. I wondered if it was perhaps merely representative of the sort of data you could expect from the 5 million records, but there’s nothing on the site to explicitly suggest that.
The thing is though, other data isn’t fabricated because I’ve verified it with HIBP subscribers. Now that may well have come from a different source and the D4M site is merely reselling it as one of many online distribution channels, but the fact remains that in those 30M+ records there is legitimate personal data.
Conclusions
When I started looking at the data I was sent, I expected to end up with an additional 30 million records in HIBP. That’s not going to happen because this isn’t a data breach therefore I won’t be loading it, but what the exercise did do is open my eyes further in terms of understanding how personal data is collected and redistributed.
Aspects of this story remain unanswered for me; do the sites I discuss above have business models beyond just data harvesting? Instant Checkmate certainly wants to charge for reports, was it a conscious decision to sell the data in the collection sent to me and indeed did it even come from them in the first place? As for the other giveaway sites, are they simply on the shady side of the web running misleading campaigns or is it their express intention to collect and then resell the data? If anyone has any insights on this or would just like to speculate, please do leave a comment below.
Your data is actually quite valuable and I don’t just mean your sensitive personal info such as your birth date or your income level or the things we would normally associate with being worth something to nefarious parties. Your name and your location combined with your email address is valuable too, perhaps not in isolation but in large collections numbering in the millions, they’re actually worth a bit and they can be sold over and over again. The actual impact of this on you may be minimal (namely spam), but most people aren’t real keen on their data being traded in this way.
Your data is a commodity and as such, others will attempt to extract it from you and sell it. Remember this the next time a site like the ones above request it from you; how are they justifying their online presence? Are you the product? Probably.