I’ve been having a few sleepless nights lately worrying about the big one. The big “what”, you ask? I mean another massive data breach the scale of Adobe back in 2013, you know, the one where they had a 153 million user accounts wander out the door. If I had to load those into Have I been pwned? (HIBP), frankly I’m not sure how I’d do it. Or at least I wasn’t sure.
When I first wrote about how I built the system, I talked about a very rudimentary console app implementation that I used to bulk load data into Azure Table Storage. I started with the Adobe breach and then batched that data into storage at the maximum rate of 100 rows per transaction. The problem, however, is that I couldn’t batch subsequent breaches as for each row I needed to check if the account existed in the system already then either update the existing record or insert a new one. It’s explained more in that original post, but because I want the service to be super-fast when querying it, I want one row in one partition for each email address and that has a massive impact on the speed with which I can insert new data.
After toiling away with the easiest short-term solution I could find for loading new breaches, I came to the following conclusion about the efficiency of the process:
However at that speed, another Adobe at 153 million records would still take a month.
Ouch! And this is for pretty time-critical data too because much of the value proposition of HIBP is that people get to know about a breach fast, not a month later! I needed a better mousetrap, and here’s how I built it.

The breach loading overview
Let me break this down simply in terms of what’s logically required to load a new breach:
- Obtain the breach data
- Extract out a unique set of accounts
- Load them into the existing Table Storage
- Send email notifications for individual and domain subscribers
- Queue notifications for [super-secret new feature to be announced later]
The first and second points aren’t too bad for even a large breach. Adobe was a 3GB 7-Zip file which is quickly downloaded and there are plenty of ways to suck out those email addresses, although it can take a while if validating that they adhere to a valid email pattern. (By the way, email address validation is a quagmire all of its own.)
Number 3 is where it gets tricky and that’s what I’m primarily going to focus on in this blog post. It’s tricky not only because I need to get data into Table Storage, but also because I’m here in Sydney and that storage exists over on the West Coast of the US. I’ve got serious latency to deal with and as fast as it is to get 3GB of data down, getting it back up again is a whole other story. More on that later.
Points 4 and 5 are pretty much dealt with already and the model I use today is dependent on the Azure SQL Database service so this is essentially the PaaS offering. The reason I use this over Table Storage is that when it comes to saying “Hey, give me all the strings from this large collection that exist in that large collection”, an RDBMS with a query engine is rather handy. I’ve got well over 100,000 subscribers (and well over 10M in the super-secret point 5) and I need to find which of them are in a collection of emails from a breach which is regularly hundreds of thousands or even millions and per the objective of that post, it also needs to work when that number is more like 100 million.
Clearly, as numbers get larger things get trickier. I needed to make this whole thing work as fast possible with a seriously large data set. From the beginning, I had no idea where the bottleneck would be – would it be in getting the data to the West Coast of the US? Would it be getting the data into SQL? Or getting it out of SQL? Or, as I was most worried about, would it be getting it into Table Storage? Let’s find out.
The test data
Firstly, I wanted test data. Now I could have just worked with the Adobe breach, but these are real peoples’ email addresses and they deserve a little more respect than being crash test dummies for my experiments. I wanted a nice round number to work with so I settled on 100M. That may be less than Adobe’s 152M, but it’s more than 20 times the size of the next largest breach and so long as time scales in a linear way with breach size, I’m fine with that. (Incidentally, I did validate this at multiple points throughout the development process.)
So I generated 100M email addresses courtesy of Red Gate’s SQL Data Generator. These are totally random and don’t belong to anyone nor are they even valid domains. The upside is that if my processes actually causes any emails to be sent via the notification process, nobody should actually receive one.
The data was generated into SQL Server then I dumped it to a text file which gave me a 3.68GB file of 100M rows. Clearly it’s never going to be efficient trying to upload this over to the other side of the world, so I zipped it down to 1.75GB. And this is where the challenge began – how do you take a zip of this size, ship it to the US and get the contents extracted in a reasonable timeframe?
Uploading the breach
The composition of a process like this is really important and what I wanted to do was break things down into discrete tasks that could be processed in parallel. They also needed to be background tasks, that is they can’t be things where a UI is sitting there waiting as this is potentially going to be a very long process no matter how efficient I make it. I recently wrote about my love of WebJobs and how awesome they are at processing tasks in the background whilst being deployed as part of the website and not costing a cent. WebJobs were a great candidate for getting serious throughput in the system.
What I decided to do was start with one WebJob whose only responsibility is to prepare the breach data for processing. It’s triggered by the appearance of a zip file in blob storage which all sounds very simple (and it is), the real problem comes when you need to actually get the data into the blob. Why is this a problem? Let me demonstrate pictorially:

This is my home connection with TPG which is theoretically a 20Mb connection. The down speed might approach that, but the up speed is always woeful. What it meant was that when attempting to upload that 1.75GB zipped file via the Server Explorer in Visual Studio I couldn’t even hit 100KB/s:
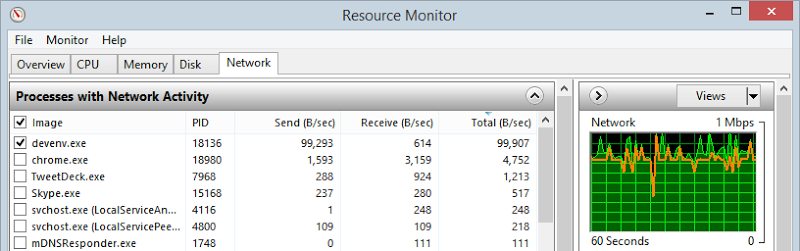
And then, after 5 hours, it simply dropped out. So I tried again. It dropped out again. I simply couldn’t get the up-speed. I wondered if it might be a limitation on the Azure end so I started Dropbox syncing a large file:
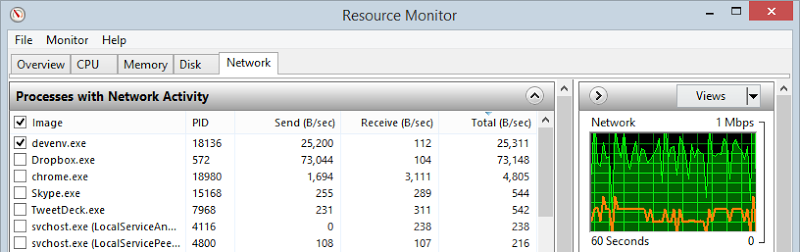
The total throughput remained very similar as Visual Studio lost bandwidth to Dropbox so clearly the bottleneck was at my end. Then I had an epiphany that lead to this:

So how do you get a 24-fold increase in your up speed? Get off ADSL 2 and onto 4G! This was via my Telstra connection with my iPhone tethered to the PC and suddenly that sub-100Kbps went to more like 1.6MB/s:
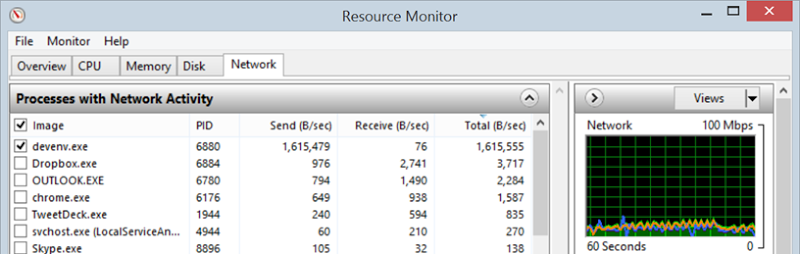
It’s ludicrous that it comes to this and frankly it’s a poor reflection of the state of internet connectivity down here (although I do console myself with beautiful weather and beaches). But on the other hand, most breaches don’t even reach 5% of this size and at a push, I can always either pay for the extra mobile data (that exercise wiped out more than half my monthly allowance), or visit a cafe somewhere with a decent up speed.
Of course the other entirely sensible approach is to never have the data in Aus. If I pull this directly into a VM in the West US from whatever location it’s originally processed, the latency issue goes away. Of course then I need to have the right tooling in the VM as well because the source breach file always requires a bit of pre-processing plus it means spinning the machine up, remoting in and, well, it’s just never going to be as frictionless as processing locally. But it remains an option.
Anyway, that data is now there so it’s time to start processing it.
WebJob 1: Extracting the breach file into the Azure SQL DB
This is where the real magic starts to happen courtesy of a WebJob that does this:
public static void ProcessBlob([BlobTrigger("breach/{name}.zip")] Stream input, string name, TextWriter log)
The container in my Blob Storage account is called “breach” and the job is triggered on the occurrence of a zip file which is then read as a stream. Using DotNetZip I can then read this as an uncompressed stream of data which works just fine, even when we’re talking about a 100M row file. I was worried about how reliable this would be but so far it has posed absolutely zero problems.
The next trick is how to get this into the Azure SQL Database service, you know, the PaaS offering which isn’t a full blown SQL Server (although the current v12 is very, very close). Under these circumstances, the most efficient process I arrived at is to use SQL Bulk Copy. Using this approach you can throw a data table (yep, remember those?) at a connection and map the columns to a target table name and columns. Which all sounded very easy except…
Know what happens when you try to put 100M rows in a data table? Yeah, not much! You end up getting memory-bound pretty quickly and through trial and error I found that 100k rows was pretty much the limit before things started breaking. So I ended up processing in batches of data tables which of course for 100M records means we’re ultimately talking about one thousand recursions of sending a data table to bulk copy. Except it’s also not that easy…
Tuning SQL Bulk Copy and Azure SQL Database scale
When I tried to throw 100k rows at SQL Bulk Copy, it timed out. Admittedly, this was running on the basic tier of the Azure service and frankly that was just never designed to handle this sort of load. I ratcheted it up a couple of notches to S1 on the standard tier and… timeout. Screw this, MAX POWER up to S3 (hey, it’s only for a few hours anyway and that’s charged at 20c an hour) and… timeout.
Now I could have gone all the way up to a premium level database with literally ten times the power and still only $5/h (I was expecting this whole process to complete in single digit hours anyway so the money wouldn’t be too bad), but frankly it was just starting to get a bit silly. Besides, there’s no point in processing the SQL side of things massively fast then later on when I get data into Table Storage it running much slower. More on that later.
What I decided to do was play with the batch size of SQL Bulk Copy. Rather than trying to send 100k rows at a time to SQL, how about only 10k? Success! 50k? Timeout. 20k – success! 25k – failure. So I left it at 20k. This doesn’t mean I’m only going to get 20% of the throughput compared to if it was 100k, it just means 5 consecutive connections instead of 1 and because it’s just an attribute of bulk copy, there’s no coding the enumeration of batches on my side, it all happens internally.
One thing I noticed while this was all running was that the DTUs on the Azure SQL Database service were well and truly maxed out:
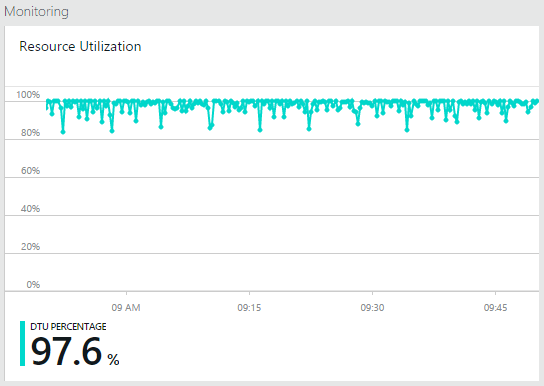
Questions of table and batch sizes aside, clearly I was well and truly exhausting all the available perf on the service. Again, I could always scale to the premium tier if I wanted to wear the dollars, but for now this seemed like a pretty optimal price versus performance level.
For interest sake, I played around a bit with the throughput of the various standard tiers and found the following on S0 (lowest tier at $15/m) and S3 (highest tier at $150/m):
S0 (10 DTUs) 1M rows in 396 seconds
S3 (100 DTUs) 1M rows in 159 seconds
Now this is inserting into an indexed column so inserts will be a little slower, but the main thing I took away was that under these circumstances, the perf increase was non-linear compared to the dollars. Frankly though, all this is a bit arbitrary because we’re talking about an ad hoc process where I scale when needed and only pay for the hour so when speed matters, throw cents at it!
The bottom line was around four and a half hours to insert those 100M rows maxing out the standard tier.
Just one more thing on this – a web job running for hours is going to be prone to failure. If it unloads from the machine (and there are various reasons why it might), the process is going to exit part way through. Azure is resilient enough to run it again for you automatically until it fails five times (although I did up this to 100), but of course the script needs to be resilient to this. In my case, this meant tracking which batches had been successfully bulk copied so that I could simply skip through the stream and resume if the thing died anywhere along the way.
WebJob 2: Process a slice of the breach
This is where it gets kinda interesting. Inserting records into table storage is slow, at least compared to inserting into SQL Server. The earlier bulk copy example was perfect where on that S3 instance I managed 1M rows in 159 seconds so call it about 6,300 rows a second. Back in that article on how I originally built the service, I lamented only being able to get about 58 records a second into Table Storage so yeah, less than 1% of the speed. But what Table Storage loses in insert speed it makes up for in read speed when you’re pulling a record out by a key and the big selling point, cost.
But there’s something else that Table Storage also does exceptionally well – it scales. Yes, I’m maxing out at under 60 records a second but that’s just in a single synchronous thread and really, who wants to only run single threaded these days anyway?! The great thing about Azure WebJobs is that they scale out awesomely. By default you can run 16 of them at the same time on a single web server when they’re triggered by a new item in Azure Queue Storage but you can always up that number and you can up the number of web servers running at the same time. The bottom line is that you can make them massively parallelised and per the title of this post, that’s exactly what I did.
The approach I settled on was to break the breach down into chunks of records and process each chunk by orchestrating a WebJob via a queue message. For example, there’s a queue message which says “Go and process records 1 through 10,000” then there’s another which says “Go and process 10,001 through 20,000” and so on and so forth. It’s a message containing serialised JSON that has a couple of other bits in there as well to help me track things but that’s the general gist of it.
10,000 is the size I settled on too. This is reasonable number to pull from an Azure SQL DB in one go and it’ll keep the WebJob busy for a few minutes at nearly 60 a second too so if it does fail, there’s not much loss to pick up. It’s all idempotent too so to the previous point about planning for WebJobs to fail, it’ll happily pick back up and continue processing when things go wrong, it might just need to re-process a few rows.
The execution of this was supremely simple, the bigger challenge was to work out how many simultaneous WebJobs to run on one machine and then of course, how many machines to run. Remember that whilst WebJobs may be free (they run within the existing cost you’re already paying for the website), the very fact that they’re running on the same infrastructure as your site means they’re sharing resources. This can mean an adverse impact on the app not just in terms of the website performance, but refer back to that earlier diagram with the database DTUs as well. This could hammer the DB resources.
The answer to the scale question is simple – massive amounts of trial and error! I loaded that 100M breach file over and over again in order to find the sweet spot. Fortunately you can just change its name in Blob Storage and it will cause the breach import job to be re-triggered (or you can invoke it manually via the WebJobs portal) and I didn’t have to keep loading it up over my 4G connection! But yeah, something like this just requires patience and tweaking.
Let’s race ‘em!
Whilst we’re getting all asynchronous here, there’s absolutely no reason to load the entire breach into the Azure SQL DB before triggering the WebJobs to process it, all I needed was to ensure that the WebJob wasn’t trying to process a range of accounts which weren’t yet in the DB. What I did very early on was to insert the queue messages instructing WebJob 2 right after the SQL Bulk Copy process in WebJob 1 finished. What this meant was that there was a massive volume of new records flooding in via bulk copy whilst at the same time there were dozens of asynchronous web jobs pulling subsets of the data back out and inserting them into Table Storage.
All of this meant creating a little race: what was faster – inserting bulk records into SQL or sucking them back out into Table Storage? And what could I do to make the slower one the faster one? Which would then make another slower one and what could I do to that one to make it even faster again?
What I was interested in boiled down to this: how can I batch data into the Azure SQL DB as fast as possible (which I’d done through tuning bulk copy and DB service tier size) and ensure that an instance of WebJob 2 picks up the message from the queue quickly after it’s inserted. That latter point depends on factors such as how frequently queue messages are inserted, how long each message takes to process and how many WebJobs are running simultaneously. I could also measure that by how large the message queue was growing as the data was processed or in other words, were they getting backed up and not being processed.
Here’s what I found: I had the WebJobs configured to run up to 25 asynchronous instances in my job host configuration:
var config = new JobHostConfiguration(); config.Queues.BatchSize = 25; var host = new JobHost(config);
But they couldn’t keep up. Each new message being processed was falling further and further behind in terms of how long it had to sit in the queue for and only 20 minutes into the process, I was already seeing well over 800 messages in the queue and it was going up rapidly:

The initial thought was whether a batch size of 25 was enough – what if I just made it 50? Then I looked at the CPU utilisation in the Azure portal (the purple line):
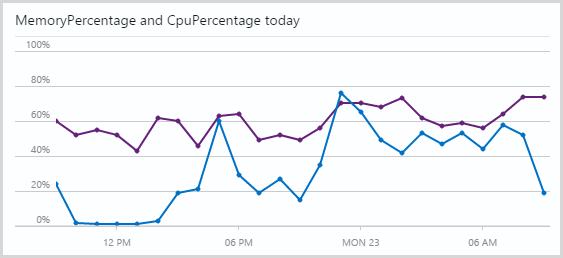
The machine was working hard and again, this thing has to actually support production traffic too so the last thing I want is for it to be hammered so hard it can’t still be responsive, especially at a time where traffic will likely be up if we’re talking about being in the wake of a large breach. In fact it was working so hard that autoscale kicked in and provisioned another machine. As I recently wrote, I now run a medium scale instance of an Azure website for this service and once this WebJob started really firing, one just wasn’t enough. In fact what I found was that even well after the original breach import process had finished (that took around four and a half hours as expected), those two instances were still required. I got up the next day and they were still there along with over four thousand messages queued for WebJob 2. So clearly I needed more instances, right?
I scaled out to four instances, let it all run for an hour than compared the stats:
2 instances allowed 273 WebJobs inserting into Table Storage to complete at an average of 15.62 emails per second each with a total throughput of 2.73 million accounts.
4 instances allowed 349 WebJobs inserting into Table Storage to complete at an average of 9.1 emails per second each with a total throughput of 3.49 million accounts.
Double the resources but only a 28% improvement – what gives?! And more importantly, why is the throughput only 15.62 emails per second and it actually drops to 9.1 when there’s effectively a parallel copy of the WebJobs that could, in theory, double the throughput? It had to be another dependency so the first thing I looked at was the Azure SQL DB – was I maxing out the DTUs by all those WebJobs grabbing 10k records at a time? Hardly:
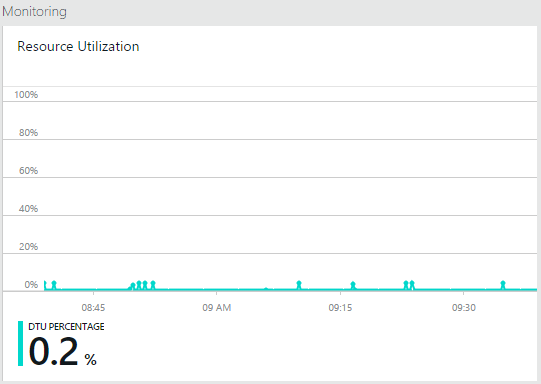
The other external dependency and likely bottleneck was Table Storage itself. Yes, it scales enormously well, but it still has performance objectives you’re bound to. But having said that, the scalability targets are in the order of 20k entities per second across an account and 2k per second across a single partition. That 3.49M is less than 1k per second and it’s spread over many partitions as each emails’ domain is the partition key and they were all randomly generated. The recommended performance optimisations were all in place (i.e. disabling Nagle), so what gives? There’s only one thing for this – MORE POWER! So I doubled the instance count to 8 medium machines and found this:
8 instances allowed 515 WebJobs inserting into Table Storage to complete at an average of 7.5 emails per second each with a total throughput of 5.15 million accounts.
Certainly an improvement, but equally not a linear one that’s commensurate with the additional instances and cost. However, this also flagged some rather good news with regards to my earlier concerns about the total duration to load 100M rows; this would all process in a “mere” 19 and a bit hours which was way more favourable than my original estimations when I first built the service. Regardless, in the spirit of more power being better, I doubled the queue batch size from 25 to 50 so now in theory, we should be looking at 8 times 50 simultaneous web jobs running. The result?
System.ArgumentOutOfRangeException
A little peeking through WebJobs assemblies and the reason becomes clear:
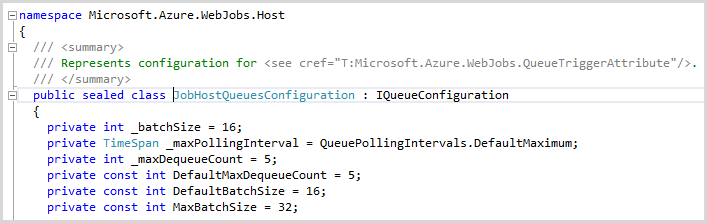
According to the last line, apparently too much asynchronicity is bad for you! So I simply turned everything up as high as it would go – the batch size to 32 and the instances of a medium server to 10. Here was the result:
10 instances each with a batch size of 32 allowed 1,014 WebJobs inserting into Table Storage to complete at an average of 11.0 emails per second each with a total throughput of 10.14 million accounts.
In other words, I can process the entire 100M rows in under 10 hours or if there’s another Adobe at 153M rows, 15 hours. The original concern about it taking a month is gone and that’s a massive win! Why do 320 simultaneous instances process at about twice the speed of the 200 I had with 8 instances of 25? And why does the average throughput go from 7.5 per second to 11? And why indeed is it even so low when I was originally seeing 58? I don’t have clear answers on these although it’s worth pointing out that you’re always going to see some variances in performance as against the objectives of the service. There are also other dependencies in my implementation which may have contributed to the variances and ideally someone would should up a little demo somewhere designed purely to show how fast WebJobs can put data into Table Storage. Any takers? :)
But what I do know is that in the race between SQL Bulk Copy and parallel WebJob Table Inserts, SQL wins by a mile and equally, the more WebJobs that are running, the faster things go. I can now confidently work on a benchmark of 10M accounts per hour. Well almost…
The one remaining fly in the ointment is that all this testing was done with only new records as a result of the email addresses being randomised. Often I’ll find as many as 20% of the accounts already existing in the system courtesy of prior breaches which actually means three hits on Table Storage – one to try and insert a new row which then results in a duplicate key exception, another to retrieve the existing row and then a third to insert the updated row. The bottom line is that my perf will suffer but then again, just the fluctuations in throughput from 7.5 to nearly 16 accounts per second (not the mention the 58 I was seeing in the original system) are far more significant than that so yeah, loads of variables.
Regardless of the variability of timing, here’s how the whole thing ended up looking:
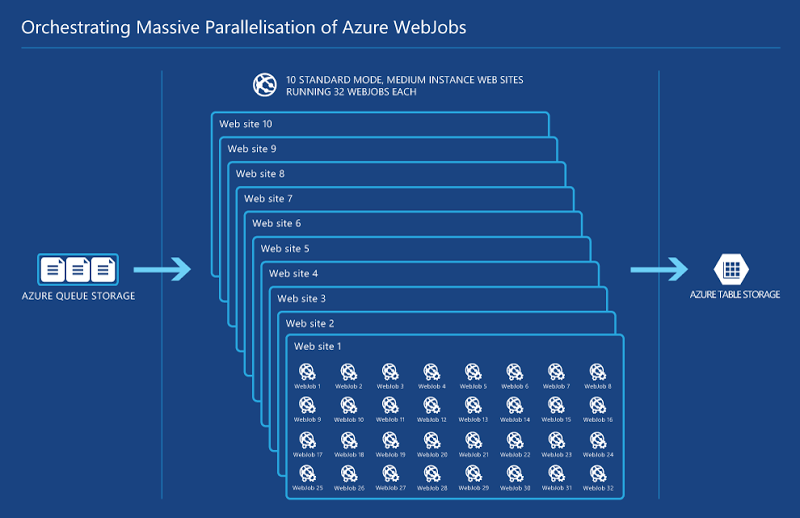
Building this feature was actually a lot of fun seeing how far I could push the technology. As for the “profit” bit in the title, it actually saves me a bunch of cash as I no longer need to spin up a VM to do this and far more importantly, it saves me time which is way more valuable than the mere cents I pay per hour for all these services. As I said in my blog post on taking donations last year, it’s the hours poured into this and the consequent sacrifices that are the real cost and compared to that, the amount I actually spend on Azure in cold hard cash is nothing.
Top tips for the future
A few things really stuck out when building this service and I thought it worth capturing them here.
Firstly, build to be blistering fast at max scale but make sure it survives at min scale. It’s tempting to always want to turn everything up to 11 and watch it fly, but most of the time the data to be processed will be way smaller than what I tested it with and I don’t need to say, make it process in 10 minutes instead of 20. It has to play nice when keeping resources small to minimise cost. In fact to that effect, I always test everything on the smallest possible scale and make it play as nice as possible with that. Scale is a bonus.
Secondly, test and measure everything. Obviously I saw some pretty inconsistent results here and it was only by having extensive timing and logging that I could work out what was going on where. Particularly for processes that are long running and in the background, you need stats on what’s happening. Without this, you’re guessing.
Thirdly – and this is the bit I really love – use cloud elasticity and scale to your advantage. I know that sounds like a statement from a marketing deck, but the ability to change how much perf you have on-demand is enormously powerful. I keep the database tier at S0 and the website at a single medium instance but when I need to, I can increase both ten-fold within minutes, pay a few extra bucks then bring them both back down when I’m done. That is awesome :)
Learn more about Azure on Pluralsight

I’ve just launched a new Pluralsight course and it’s actually the first one I’ve done that isn’t about security! Modernizing Your Websites with Azure Platform as a Service contains a heap of practical lessons on using Azure Websites and Azure SQL Databases (both are Microsoft’s PaaS offerings) and a significant amount of the content in that course has come from real world experiences tackling problems just like this one. It’s very practical, very hands on and a great resource if you want to learn more about the mechanics of how to use Azure websites and databases in the real world.