It has a cool name and a logo - this must be serious! Since Heartbleed, bug branding has become a bit of a thing and more than anything, it points to the way vulnerabilities like these are represented by the press. It helps with headlines and I'm sure it does wonderful things for bug (brand?) recognition, but it also has a way of drumming up excitement and sensationalism in a way that isn't always commensurate with the actual risk.
That said, the Cloudflare bug is bad, but the question we need to be asking is "how bad"? I saw the news break yesterday morning my time and I've been following it closely since. As I've written a lot about Cloudflare in the past and been very supportive of their service, I've had a lot of questions from people. I want to share my take on it - both the good stuff and the bad stuff - and per the title above, I'm going to be very pragmatic about the whole thing.
Before I get started and if you haven't read it already, start with Project Zero's outline of the bug then move onto Cloudflare's detailed blog post on the issue (that's the chronological order they were written in). Do read the comment threads on both too, they each contain valuable background and insight. Right, assuming you now understand the background, let's jump into it.
The problem is that we just can't measure it
This, more than anything, is the problem with this bug. When there's a data breach - let's say Dropbox - we can say "there were 68 million accounts impacted, here's what was lost and here's everyone we need to notify". With Cloudflare's bug, it's enormously hard to identify exactly who's been impacted and to quantify the risk.
Cloudflare refer to memory being leaked from only "0.00003% of requests" which sounds very small. I commented earlier today that you've got a better chance of winning the lotto which is mathematically correct, but there are two very important things to note with this figure:
Firstly, Cloudflare serves an almost unfathomably large amount of traffic. I wrote a course on Getting Started with CloudFlare Security in mid-2015 and they were serving 5 trillion requests a month at that time and I assume much more as of today. The bottom line is that we're looking at millions of requests per month potentially leaking data. Depending on how you look at it (and how you want to spin it, in some cases), it's either a tiny fraction of traffic or a large number of requests. In reality, it's both.
Secondly, the way they phrase it is "1 in every 3,300,000 HTTP requests through Cloudflare potentially resulting in memory leakage". Now think back to both Project Zero's and Cloudflare's write-ups on the incident: these are requests to pages with malformed tags which result in the leakage of memory from other sites. This is something they could feasibly measure because they can look at the percentage of traffic they're serving with the funky markup. However, what they're highly unlikely to be able to measure is how many totally unrelated sites had their traffic leaked by that small percentage and frankly, I can't see any way that we'll ever know.
Unknown facts create a media vacuum and encourage speculation
This incident has led to some pretty sensational headlines on stories that do a lot of talking but not much establishing of actual facts. For the reasons outlined above, it's a hard thing to do and the numbers we have don't really tell us the entire picture. It's one of the reasons I waited a day and a half before writing anything - I wanted to fully understand the issue and focus on the facts.
For example, Cloudflare has said that "we discovered exposed data on approximately 150 of Cloudflare's customers" which sounds like a very small number when they have a couple of million websites within their service. However, this relates to customer data found in caches such as Google's search engine or in other words, incidents where they could emphatically prove that customer data had been leaked. The term that immediately comes to mind here is "absence of evidence is not evidence of absence"; there could be other data that's been exposed in places they simply don't know about.
On the other hand, the premise that "every Cloudflare site ever is at risk" is nonsense. For example, this very blog runs through Cloudflare as do hundreds of thousands of other sites that contain absolutely nothing of a private nature. I've been pointed at a GitHub repository listing sites behind Cloudflare many times now as though it's a canonical list of everything that's at risk. This blog is in there. My wife's blog is in there. The sample site I used in my Cloudflare course is in there. None of these were put at any risk whatsoever by this bug because they have no traffic that can't be shared with everyone.
As much as the headlines paint this as a bad bug (and it is bad, even by their own admission), it's not as bad and the scope is not as broad and the impact is not as significant as a large amount of the press I've read is implying. When this was eventually identified, it took one of the world's best bug hunters to find it; even with the enormous volumes of traffic moving through their infrastructure, nobody else (that we know of) had found this bug. It was so obscure and manifested itself in such a tiny fraction of requests that even with the huge number of people continually inspecting traffic on all sorts of sites behind Cloudflare, it took Tavis to find it.
What's the impact (and reactions) regarding sensitive data?
Another reason for waiting to write this post was that I wanted to see how organisations were responding to the incident. I was curious, for example, what approaches would be taken to protect customer credentials. I was monitoring things this morning and saw a variety of responses. For example, Creative Commons forced a password reset. Cubits recommended people change their passwords as well as resetting their 2FA and rotating API keys. Bugcrowd decided to invalidate all sessions and like Cubits, recommended rotating API keys and advising that customers should change their passwords. Vultr merely used the incident as an opportunity to "remind you of best security practices".
There are multiple different classes of sensitive data involved here so let's look at the whole thing pragmatically and we'll begin with passwords. Frankly, these are the least likely to be impacted because requests involving passwords are such a tiny fraction of overall requests made to a site. You provide passwords on registration, login and password change and other than those three features, passwords typically never accompany either the request or the response (exceptions are rare and usually pretty screwy). If we were to attempt to put a number on it, using a typical website is going to result in only one in hundreds or even thousands of requests actually sending a password. All those requests to pages, images, JavaScript files, CSS etc. will go out password free. It's a tiny fraction of the at-risk 0.00003% of requests to Cloudflare that would actually contain passwords.
Auth tokens, however, are another story. Typically, these are going to be sent on every authenticated request, even those for static assets as the token is usually a cookie valid for the same domain that serves all content (larger sites serving static assets from other host names being an exception). On the other hand, they're only going to be sent whilst a user is actually auth'd so every request on this site, for example, wouldn't have anything of use for hijacking sessions. Again, we're looking at a subset of that 0.00003% number and of the tokens that were exposed, they're only any good whilst they haven't expired so ones caught in cache in particular may be useless by the time they're grabbed.
It's sensitive data like this which is of particular concern:
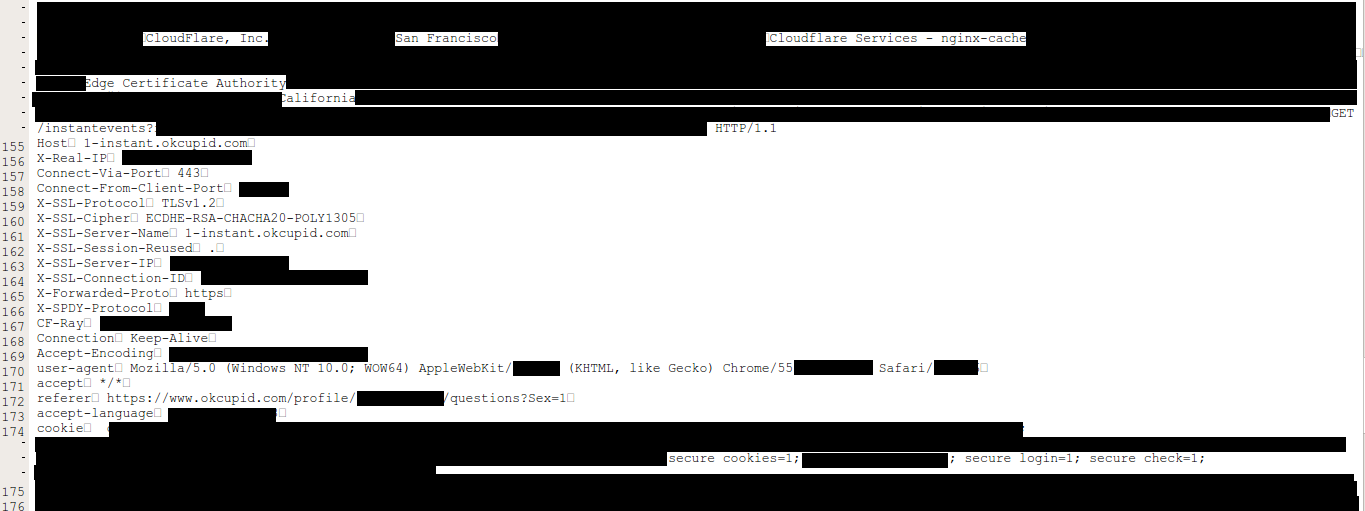
This was shared by Tavis in the Project Zero post and it contains OK Cupid data. There are other screen caps in that post from the likes of Fitbit and Uber, all grabbed from Google's cache and all containing various levels of personal information. It's entirely possible that some of these were accessed by other parties and contain information that can't simply be reset like an auth token can be. Again, Cloudflare believes this impacted 150 customers which is a small portion of their overall client base, but it's still not going to be a pleasant experience for those organisations and it may make for some very uncomfortable discussions with their customers.
Password resets and session expirations are protecting against the unknown
I'm yet to hear of a single organisation saying that they've seen any malicious activity against their services or customers as a result of the bug. Mind you, it would be hard to know, such is the nature of credential abuse, session hijacking (by obtaining auth tokens) and indeed obtaining sensitive personal information. Regardless, organisations are proactively addressing this in the way I described above with the likes of Bugcrowd so let's focus on that for a bit.
The equation many organisations will be grappling with is whether they should inconvenience and potentially alarm customers to protect against a risk they're not sure they've actually been impacted by. I can't give a blanket answer on what everyone should do, but I can frame the discussions they should be having.
Emails to customers about security incidents pose multiple challenges. One of them is that regardless of how carefully worded they are, people often interpret them as a risk present in the service they use and that can impact trust and confidence. Brand value and reputation are fragile and an email going out with a title like "Important security update" is always going to raise eyebrows. There's also the subsequent support demand this may create - will customers email back with questions? Will they phone help desks? Or will it possibly even create a sudden influx of traffic that may be difficult to handle if you're asking people to change passwords?
Then there's the benefit that proactively contacting customers would have. Here I'd be thinking about factors such as the value of the asset being protected; a comments section on a media site is a very different proposition to an online account that could be exploited for financial gain (i.e. Uber). There's also the question of what technical mitigations may already be in place, for example the short expiration of sessions which greatly reduces the likelihood of auth tokens being exploited.
I've heard some people say that password resets should be done proactively because even if a particular Cloudflare customer's traffic wasn't leaked, someone else's could have been and passwords may have been reused. That argument doesn't really stack up though because we could have exactly the same discussion after every single data breach. That scenario alone doesn't pose sufficient risk to justify the impact of forcing a password reset which is a high-friction action that most impacted Cloudflare customers don't seem to be resorting to.
That last point above is important if people want to be guided by the general consensus: I'm not seeing mass password resets. Of the formal communication organisations have sent, resets like Creative Commons' above are the exception with the norm appearing to be general security advice and perhaps session expiration such as Bugcrowd has done. Cloudflare obviously tried to clean up as much cached data as possible before news broke and whilst they didn't get it all, I suspect the cleanup was sufficient and the risk deemed low enough that many organisations are not deeming it as necessary to send any communication at all.
So in short, the actions above are pre-emptive and they do have risks as well as upsides. In almost all cases, organisations taking these measures are protecting against the unknown, that is if they're taking any measures at all.
Will I stop using Cloudflare?
No. This is where we need a bit of common sense about the whole thing so let me explain my take on it:
Very often when I look at security incidents, I see a series of failures. As the story unravels, a picture emerges of a company that's made multiple miss-steps with technology, communication and general respect for their customers. A couple of times this week I've alluded to a major breach I've been working on and when I publish that early next week, you'll see exactly what I mean. That's not Cloudflare; they had a bad bug that turned around and severely bit them on the arse, but that's an exceptional situation for them, not part of a pattern.
When you look at the bug they had, you can see how it would occur and for those of us in the software industry, you can imagine how one of us could have just as easily written it at the time. I like that they've written it up as transparently as they have and it's hard to look at anything of significance they've done post-incident and say they should have done it differently.
Having said that, there are some things they need to do better too. I've seen a number of comments about offering Tavis a t-shirt for his efforts and at present, that's the top reward offered by their bug bounty program (other than free access to their services). That may seem a small and insignificant part of a much more serious incident, but it's been called out a number of times and I'd be remiss not to list it here. A vulnerability of this nature disclosed ethically is worth more than a token gesture and I hope we see their bug bounty program reflect that in the future.
Moving on, the bigger question we should be asking here is not whether or not to trust Cloudflare, but whether or not we should trust other parties with our traffic at all. As it stands now with this bug squashed, there's no reason to trust them any less than counterparts such as Imperva. They play in the same realm and could one day be faced with the same risk where data from one customer is exposed to another by virtue of a bug running on shared infrastructure. Let's follow that thinking even further: I run Have I been pwned (HIBP) on Azure's App Service which is a PaaS implementation where TLS is terminated upstream of my logical infrastructure. They could have a bug in their model which again, cross-contaminates traffic sharing the same physical resources. Or perhaps there's a bad enough bug in Amazon's hypervisor implementation that AWS customers cross-contaminate across VPSs. You can see my point here - it's a slippery slope once you start saying "I no longer trust other parties with my data".
But then you turn the discussion around and say "if not services like these, then what"? The reason there are millions of websites behind Cloudflare is because it's such a valuable service. It's made a huge difference to the way I run HIBP, for example, and it's protected both that service and a huge number of others from the likes of DDoS attacks. It's also significantly reduced my costs by virtue of caching traffic and relieving my origin servers of huge amounts of load. That poses a great deal of value and that's an essential part of the equation for anyone weighing up whether it makes sense to stick with Cloudflare.
To start wrapping up, I really like this observation by David Heinemeier Hansson (the creator of Ruby on Rails):
Good software is uncommon because writing it is hard. In the abstract, we all know that it is hard. We talk incessantly about how it’s hard. And yet, we also collectively seem shocked — just shocked! — when the expectable happens and the software we’re exposed to or is working on turns out poor.
Software is complex. Cloudflare's is certainly not "poor", but even the best has bugs and whilst we should continue striving to improve it, we've also come to expect that it will occasionally go wrong in spectacular fashion. I'll leave you with one thing I can pretty safely say: Cloudflare has never been as security conscious as what they are right now!