A little while back I took a look at some recently breached accounts and wrote A brief Sony password analysis. The results were alarming; passwords were relatively short (usually 6 to 10 characters), simple (less than 1% had a non-alphanumeric character) and predictable (more than a third were in a common password dictionary). What was even worse though was uniqueness; 92% of common accounts in the Sony systems reused passwords and even when I looked at a totally unrelated system – Gawker – reuse was still very high with over two thirds of common email addresses sharing the same password.
But there was one important question I left unanswered and that was how people choose their passwords. We now know that structurally, passwords almost always adhere to what we would consider “bad practices” but how are these passwords derived in the first place? What’s the personal significance which causes someone to choose a particular password?
It turns out there are some very recognisable patterns in the data. In fact the vast majority of passwords adhere to just a small handful of common selection practices. This is interesting research in that it begins to give a bit of insight into the thought process of the individuals who create passwords which conform to weak structural guidelines.
Source data and analysis process
The data I’m going to analyse comes from a variety of sources including the Sony and Gawker breaches I referenced in the previous post as well as other LulzSec releases including pron.com and a collection of their random logins. For each of these I have nothing more than an email address and a password – there are no other account attributes I can use to start drawing conclusions (i.e. physical address). There are about 300,000 accounts in all which should give us a reasonable cross section with which to make some observations on password selection.
There are three other sets of source data I’m going to use in this analysis:
- People names: this includes a list of about 26,000 common first and last names.
- Place names: this is everything from towns to states to countries and includes about 32,000 entries.
- English dictionary: exactly what it sounds like – around 190,000 words in a typical English dictionary.
I’m going to use these three sources of data to make some assumptions about where passwords may have been derived from. The three lists above are aggregated from various sources and whilst comprehensive, are certainly by no means complete. The bottom line is that some potential matches are going to be missed and the overall numbers will be lower than what they would be if the lists were 100% accurate.
In matching passwords to potential sources I’m going to be a bit more liberal than usual by ignoring both case and punctuation. Whilst these are extremely important to password entropy, they don’t have a part to play in terms of where people derive their password from. Whether I use “Troy” or “troy” as a password (and no, I don’t use either!), or “Troy Hunt” or “troyhunt”, I’ve still derived them from the same logical source. Besides, in my previous analysis 45% of all passwords contained only lowercase characters and as I mentioned earlier, less than 1% had any sort of punctuation anyway so it wouldn’t make a difference for a significant portion of the data set.
In the analysis I’m going to start with the most personal sources – such as someone’s name – and then move onto increasingly less personal sources such as places, then dictionary words and see how many passwords correlate to each. In a case like “June” where it could be either a name or a dictionary word, it will appear in whichever statistics I run first (people names, in this case), then won’t be counted again so we’ll get a discrete set of matches. The order of the results is more a logical priority than one of prevalence.
People names
I’ve started with people names because a name is simply one of the most personal attributes of someone’s identity. I also suspect they feature heavily when someone reaches into the recesses of their mind to come up with a password. Now of course the name is not necessarily the name of the account holder; it could be a spouse, the kids or even the family dog. Furthermore, it could be a first name, a middle name or a last name.
Here’s how they break down in terms of their prevalence within the total password set:
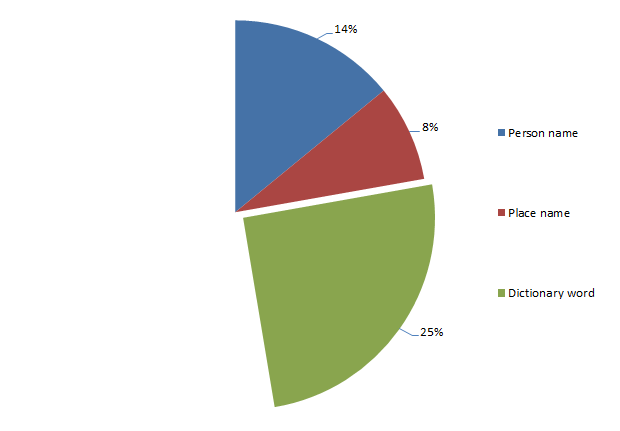
Passwords derived from a person’s name
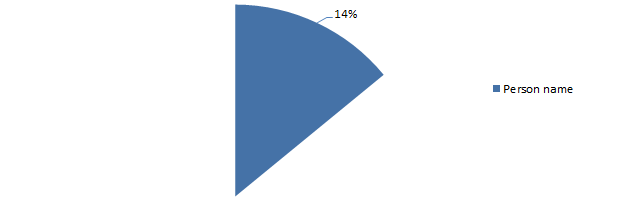
So what this graph is saying is that 14% of people create their password based on a person’s name. What does this look like? Well, pretty predictable really, here are the top three names as passwords:
- maggie
- michael
- jennifer
But there’s a bit more to the story; just because a password is derived from a person’s name doesn’t mean it’s a perfect match. For example, prepending or appending numbers to a name is a popular practice so whilst “troy21” may not be a perfect match to my name, the origin of it is still clear.
There are three common derivatives of a name which frequently appear in passwords:
- The addition of numbers
- The addition of symbols (possibly along with numbers)
- Reversing the name (with or without numbers and symbols)
The graph above includes these three practices and the propensity of them within people names breaks down as follows:
Structure of passwords derived from people names
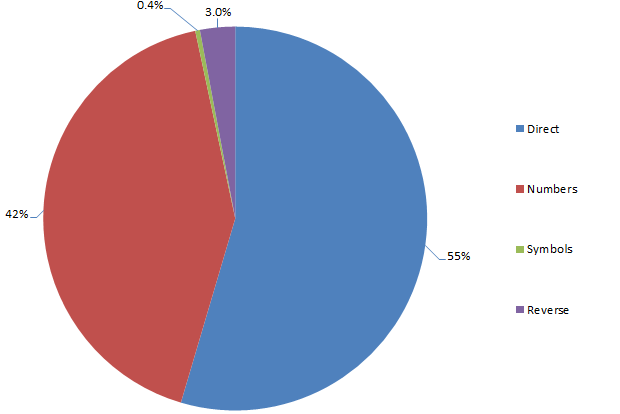
Obviously numbers are the favourites and they’re almost exclusively appended to the name rather than prepended. Furthermore, the appended number is very, very frequently just a “1”. Two digit numbers, likely representing a year, also feature quite frequently (year of birth, perhaps?) as do four digit numbers which I assume would imply the same thing (certainly it’s feasible based on the number range).
Use of symbols is quite rare but then again, as I mentioned right at the start of this post, less than 1% of passwords in my previous analysis had a symbol anyway so no big surprises there. The reversed names are obviously an attempt to obfuscate the password and decrease discoverability. In reality, a reversed name is still the same number and type of characters so passwords such as “trebor”, “nevets” and “samoht” are still going to be very vulnerable to brute force attacks such as by rainbow table.
Place names
Another very common practice is to use the name of a place in the password. This might be a city, a state or a country and it’s probably fair to speculate that these places have some degree of personal significance to the password creator. Here’s how prevalent those place names are:
Passwords derived from a place name
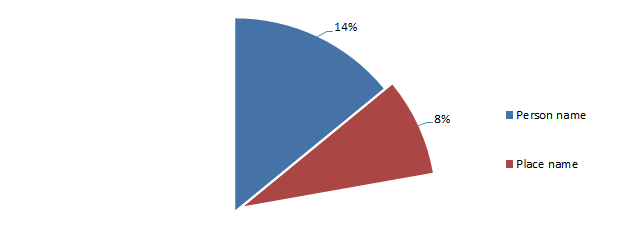
What we’re seeing here is that 8% of all passwords are based on a place name. The most popular place names included:
- dallas
- canada
- boston
The trick with place names is that very often they could also be people names (i.e. Victoria), which is not surprising given many places are named after people. Likewise, they’re very frequently dictionary names (i.e. Sunshine) and in both cases it’s simply impossible to make an assumption about what the individual was thinking when the password was created. Either way though, the central theme is still the same: the passwords are being derived from common words.
In terms of numbers, symbols and reversing tricks, it’s a pretty consistent result with what we saw previously with people names:
Structure of passwords derived from place names
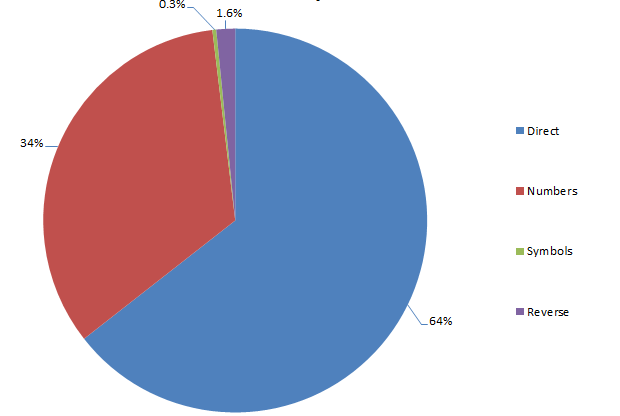
Once again, the old faithful “1” suffix is most popular. It’s as though people know they should mix character types but they take the easy way out instead of choosing truly random numbers and positioning them at unpredictable locations within the password.
Dictionary words
Here’s the big one, and it’s not at all surprising given the huge selection available. Dictionary words are by far and away the most popular source of password inspiration:
Passwords derived from a dictionary word
A huge 25% of passwords are derived directly from dictionary words. In reality, it’s probably somewhat higher than this as my dictionary had less than a couple of hundred thousand words. And they’re all only English language.
Top among the dictionary favourites are:
- password (oh dear)
- monkey
- dragon
The first one probably shouldn’t be such a surprise but still, wow! My password source of several hundred thousand accounts had nearly two and a half thousand “password” passwords which is not only a pretty poor choice given its clearly available in a dictionary, it’s also an insanely obvious one.
It’s a pretty similar story to people names and places when it comes to mixing up words with a bit of randomness:
Structure of passwords derived from dictionary words
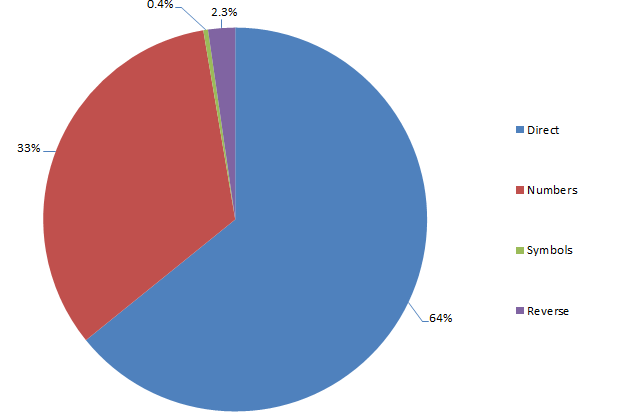
Same deal as before too – predominantly suffixes and predominantly predictable number patterns. I think we’re seeing a pattern here…
Numbers
Here’s another significant portion of passwords – numbers. I don’t mean numbers combined with words, I mean numbers and only numbers. In fact they feature rather significantly:
Passwords derived from numbers
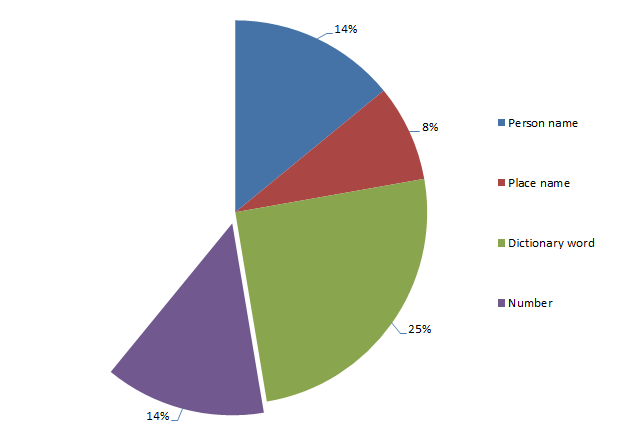
A total of 14% of passwords are purely numeric. If that seems kind of staggeringly high to you, wait until you see the three most popular number combinations:
- 123456
- 12345678
- 123456789
I don’t think we need to do much speculating about how these were derived. What’s a little more interesting though is the spread of lengths:
Length of purely numeric passwords
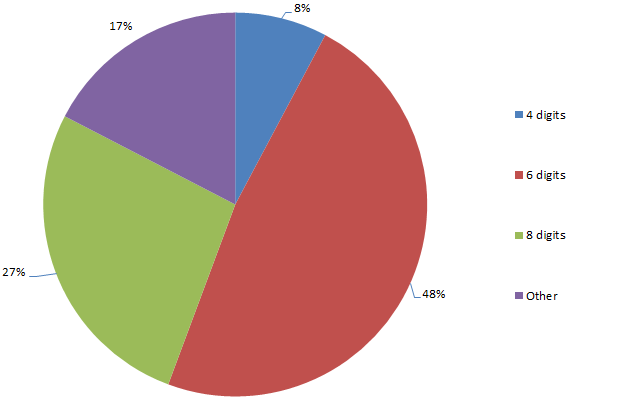
Why is this interesting? Well firstly, within a spread of numeric password lengths which range from 1 (yes, 1, and there’s a heap of ‘em) to 21, 83% of the passwords are either four, six or eight digits long. Is this a propensity for even numbered password lengths or something else?
For four digit passwords, the spread is pretty widely distributed in terms of number of occurrence, at least once you ignore “1234” (the most commonly used four digit password by a factor of ten). However, there’s quite a prevalence of numbers which could easily represent recent years (1984 is quite popular), so I suspect there’s often a date based significance. The other thing to consider is that given the propensity for password reuse and the fact that many PIN numbers are four digits, there’s a good chance these numbers are used on someone’s luggage or – gasp! – is the one they use to pull money from an ATM.
The thing about six digit numbers is that they very, very frequently represent dates in DDMMYY format (or MMDDYY for the Americans). The ranges of each three pairs of numbers in the password list suggest there’s a high likelihood that these passwords do indeed relate to dates, assumedly of some personal significance to the creator.
So what about the high prevalence of eight digit numbers? There’s some degree of numbers meeting a DDMMYYYYY format (or American equivalent), but for the most part, there’s no obvious pattern. Based on what we’ve seen so far there’s almost certainly a personal significance to the numbers but it’s not obvious from their format, at least not beyond those that adhere to obvious, memorable patterns such as “12345678” or “11223344”.
It might seem a bit liberal having a dedicated category for all passwords of one character type, but when you consider the extremely limited character set – ten as opposed to 95 (printable ASCII characters) – there’s obviously some very specific reasons for only choosing numbers.
Double words
We’re getting into the more abstract patterns here but one which does occur quite a bit is double words (i.e. “troytroy”):
Passwords comprised of double words
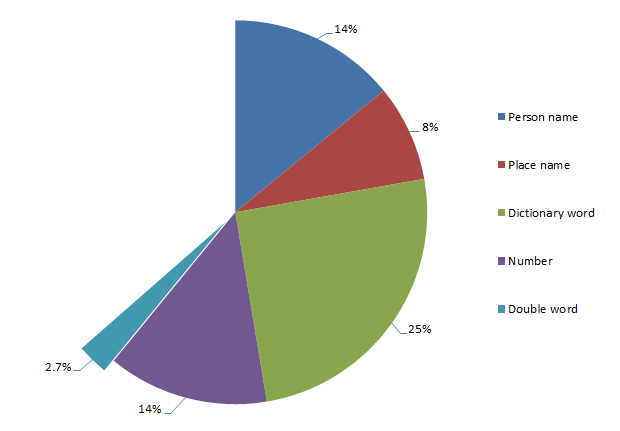
Again, we’re talking small numbers now, and less than 3% hardly sets the world on fire, but there’s a clear pattern nonetheless. Here’s what’s popping up most frequently:
- blahblah
- poopoo
- lovelove
As well as repeating words, there are also patterns of doubling up on other random characters. We could speculate the thought process is that this practice is enabling simple passwords of very short length to be literally doubled in size, but of course in many cases, they’re still short (eight characters or less), lowercase alphanumeric strings which is a pretty basic pattern.
Passwords found within email addresses
This is a pretty brazen attempt at simplifying the whole logon process – why struggle to remember a password when you can simply use the identity component of the email address? Confused? It would be like me taking the “troyhunt” out of troyhunt@hotmail.com and using that as my password. There’s a bit of that going on here:
Passwords derived from the email address
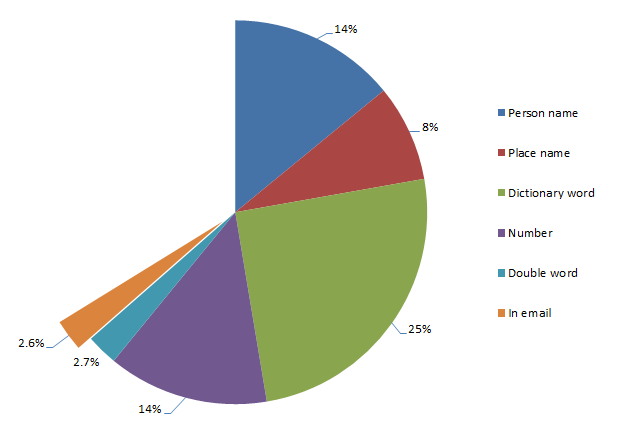
Ok, less than 3% is a small number but again – wow! – people actually do this! Let me illustrate with the domain excluded so there’s some degree of privacy retained:
- Email: murphy666@… Password: murphy666
- Email: baolihua@… Password: baolihua
- Email: racecar73@… Password: racecar73
The inspiration for these passwords is pretty clear – no more speculation needed!
Short phrases
This one is a little tricky to quantify as the only way of identifying the phrases was to literally eyeball the data and build up a phrase list based of the most common occurrences. However, I thought it was worthwhile pursuing and whilst the numbers below are inevitably lower than the true number (I didn’t read through every password), I know from previous experience that short phrases are often – and incorrectly – thought to be a “secure” form of password. Here’s what I found:
Passwords that are short phrases
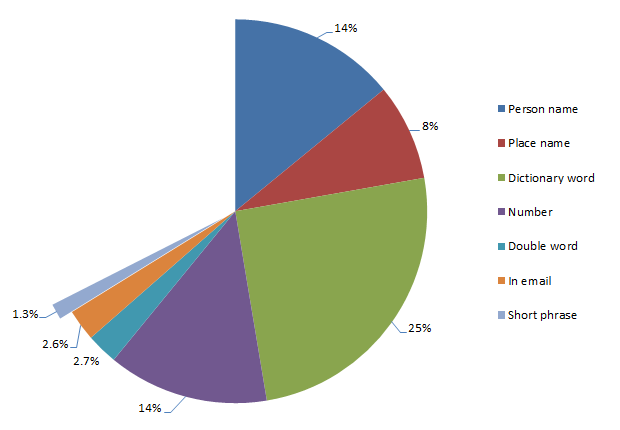
What sort of phrases are we looking at? Here’s the most popular few:
- trustno1
- letmein
- iloveyou
The first one is a little amusing given the context and that it appeared as agent Fox Mulder’s password in the X-Files series (not a great password role model!) The others are obviously simple and easy to remember which is a pattern repeated throughout most of the remaining phrases. Yes, they add length and variety (at least in a dictionary sense), but once again, they’re short, predominantly alphabet-centric lowercase passwords. The other thing is that they’re frequently found in password dictionaries (note – not English dictionaries, rather lists of common passwords). In fact “letmein” and “iloveyou” can both be fund in the popular darkc0de.lst password dictionary.
Keyboard patterns
Whilst we’re now getting down into small numbers, keyboard patterns have long been advocated by some as a “secure” means of creating passwords. The theory is that they don’t appear in English language dictionaries (although they often do in password dictionaries), and they’re easy to remember as they’re pattern based. Here’s how they features in the data set:
Passwords that are keyboard patterns
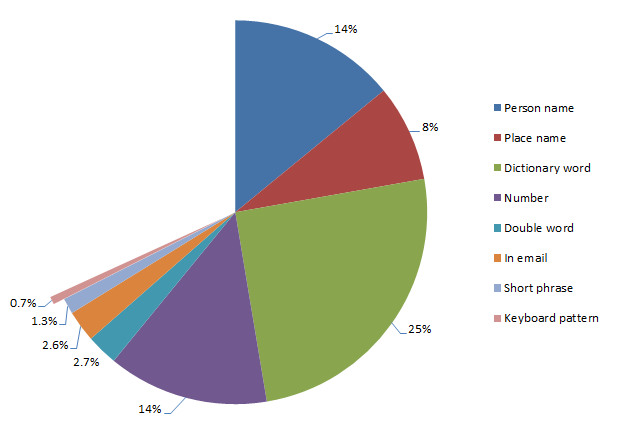
Again, this was based on me manually identifying patterns so inevitably I’ve missed a few but certainly I’ve caught a lot of the high frequency ones. Here’s the sort of patterns I’m regularly seeing:
- qwerty
- asdfgh
- asdf1234
Obviously in a case like the last example, they’re trying to mix things up a little but the pattern is still very clear:

Some of the more creative ones start to take different directions across the keyboard or add a bit of randomness to the recurrence of letters and numbers but the practice remains the same: predictable.
Related to the site
Whilst this is a very small result in terms of percentages, I thought it was a pattern worth commenting on as it’s quite a different approach to deriving a password. In this pattern, the password has a very direct link to the site in which it’s created, either based on name or other attributes relating to the nature of the site. Here’s how it breaks down:
Passwords related to the site they're created on
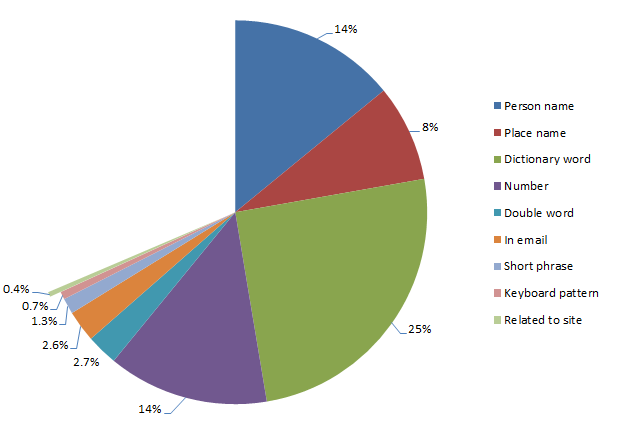
Let me put this into context:
- Site: Gawker Password: Gawker
- Site: Sony Pictures Password: sony123
- Site: pron.com Password: ilovepron
So once again we have password that are easy to recall based on a memorable attribute. Of course this is also a rather obvious attribute (it’s staring you in the face when you go to logon), and on that basis alone, it really doesn’t form a very robust password. Incidentally, some of these are rather amusing, particularly the ones from pron.com :)
Everything else
So what does that leave? Well, a rather large number of passwords which don’t comply with recognisable patterns or they simply slipped through my filters (the latter is highly likely and there would be a significant number of passwords in this category). Here’s what’s left:
Passwords not derived from sources in the above analysis
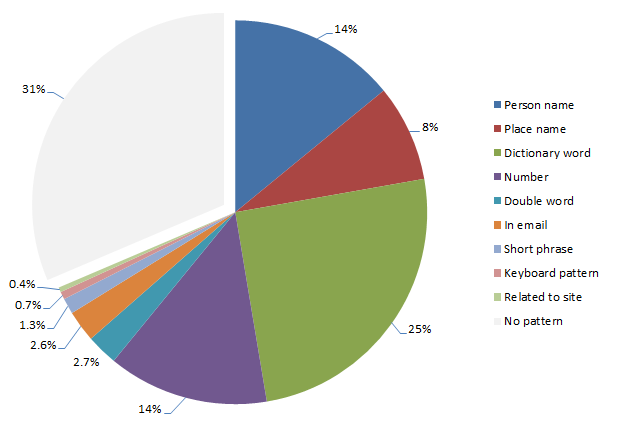
High prevalence, typical examples include:
- thx1138 (turns out this is a movie from forty years back)
- gundam (actually an anime series)
- ncc1701 (codename for the USS Enterprise in Star Trek)
So there’s a whole range of passwords out there which whilst they won’t be picked up by any of the patterns discussed above, do in fact relate to popular culture. This is a fairly obvious source of inspiration although one that’s difficult to define in a set word list.
Then of course there are simply passwords which don’t adhere to any discoverable pattern, for example “mw818283” (although interestingly a Google search does show this up in an online password dictionary). The thing is though, these fall into the minority and even if they are “strong” (long, random, unique), they’re now commonly available in password dictionaries to be used in future brute force attacks. Because my entire password database has come from compromised sites which are now readily available online, the reality is that none of these passwords should be used again. Ever.
Summary
So what do we make of all this? There are some obvious conclusions:
- Passwords are inspired by words of personal significance or other memorable patterns.
- Attempts to obfuscate or strengthen passwords usually follow predictable patterns.
- Truly random passwords are all but non-existent – they’re less than 1% of the data set.
A significant part of the problem is clearly websites implementing very lax password policies (or none at all based on the one character instances), where at the very least, there should be a robust minimum criteria. How high should the bar be set? Well, that’s another topic of much debate and there are obvious usability implications. Then there’s the idea of taking password requirements to a whole new level and doing what Hotmail has just done by actively disallowing vulnerable passwords.
But the intention of this post was always to identify how people are presently choosing their passwords and we have good insight into that now. Of course the next question is “how should people be choosing passwords”? The answer to this is simple: The only secure password is the one you can’t remember.