The other day my receiver for the home audio setup completely died. Kaput. So I go out to get another one and given a receiver is no larger than a couple of shoeboxes in size, I decide to drive the GT-R instead of taking the family estate. I love the GT-R because it’s enormous fun and I smile every time I drive it so given my requirements were well within the capacity allowance of the GT-R’s supercar proportions, it was the natural choice.
So I get to the shop with a smile one my face, find the right receiver and then… I see a TV. It’s not a big one, but it’s the perfect size for the bedroom which was still adorned with an old 4:3 CRT unit which was well past its prime. We negotiate and bundle the two units together price wise which works out quite nicely and ensures my smile remains in place. Then I try to put them in the car.
The receiver wasn’t a problem and that went straight into the boot. The TV, however, was a different story. I tried to move the passenger seat all the way forward and tilt it towards the dash then jam the TV into the two tiny seats in the back. No joy. I rotate the box and try and put it in the passenger seat but now the door won’t shut. I end up jamming the drivers seat forward which meant my 6’ 5” frame could barely fit and I couldn’t see out the rear view mirror. This was all highly amusing for those witnessing the scene and nothing erodes the cool factor of an attention-seeking car by seeing someone try to jam a TV into the back of it.
Clearly, the GT-R sucks and I should be rid of it. Yes it’ll get to 100kph in under 3 seconds and go well north of 300kph but it’s enormously impractical. It’s ok if you want to perform the simplest of tasks at huge speeds but anything complex (like carrying a TV), takes forever. And that got me thinking about this:
@troyhunt I'm not joking :) It's OK if you perform the simplest of tasks at huge scale but anything complex, takes forever.
— Paul Moore (@Paul_Reviews) May 24, 2015
Paul and I were having a bit of a chat about the virtues (or lack thereof, depending on your position) of Azure Table Storage. There are some common misconceptions about the right use cases for this storage construct and certainly it’s a chat I’ve had many times before so this is a good chance to clarify things. It’s one of those things that can be enormously powerful or enormously terrible depending on what you’re trying to do with it, something that resonates with the earlier GT-R carrying capacity conundrum.
I’ve been using Table Storage for the last couple of years as the predominant back end for Have I been pwned? (HIBP). I presently manage nearly 200 million rows of data in there and often serve many millions of requests to it per day. These requests pretty much always execute within 50ms and the actual Tables Storage lookup itself can be as little as 4ms. That’s regardless of load too – I’ve never had the site scale to huge volumes and seen Table Storage become a bottleneck and as I’ve documented many times now, that’s often with some pretty serious scale for a one-man built and supported website.
One of the Table Storage ![]() strengths for me as a “little guy” running a site is that the storage costs are almost free:
strengths for me as a “little guy” running a site is that the storage costs are almost free:![]()
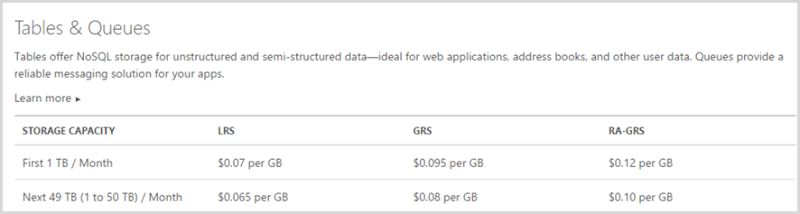
I’m hosting in the order of 16 GB of data and I’ve splashed out on geo redundant storage so call it $1.52 per month in costs there. That is all. No – hang on – I also have to pay for transactions:

Last month’s bill shows I did just under 25 million transactions which is both reads and writes so that’s another 90c, it’s important to factor that into the calculations too. Let’s be generous and round it up – say it’s $2 and 50c per month to store a couple of hundred million records accessed 25 million times in that month at a speed often measured in single digit milliseconds.
Ah, “but wait” you say, “it’s inefficient”!
@Scott_Helme @troyhunt @Azure storing multiple copies of the same data; pretty much step 1 in good database design.
— Paul Moore (@Paul_Reviews) May 24, 2015
And of course this is right, at least insofar as I do have a huge amount of redundancy in the Table Storage design. A perfect example of this is the way I store pastes in that all the metadata about the paste is stored against each every email address that was found in it. If there are 50k email addresses in a paste then I’ll have 50k occurrences of the paste name, author, date, URL and other entirely completely redundant pieces of data. This is massive duplication of the same data and goes against step 1 of good database design. It’s also a perfect use of Table Storage!
Back in the day, space was expensive, compute power was limited and normalisation provided a means of creating canonical representations of entities that could then be referenced by key from other tables. You’d write queries to chain relational entities together and often end up with a series of joins across the database. For the most part, this is fine, but at scale it becomes increasingly difficult and all the tricky indexes in the world can’t escape the fact that a couple of hundred million rows with multiple joins makes for hard work.
With a key value store like Table Storage, you’re usually pulling a single record back from the data repository. For example, every time you search HIBP you pull back a record with a partition key of the email’s domain and a row key of the alias. In the example mentioned above, the actual value of the record is the entire paste. This data is “write once, read many” in that it never changes. A paste is always a paste and the passage of time doesn’t change this so it doesn’t need a canonical record as you’d have in a normalised RDBMS. The redundant storage it leads to is something I need to pay for, of course, which means that I have to find an extra 7c a month for every gigabyte of data I add. At modern cloud scale and cost, it’s just a non-issue.
Now I do still use a SQL Azure Database in the HIBP design as well because frankly, there are things it does much better than Table Storage. For example, I can query it using TSQL which means being able to look for patterns across records, update large volumes of data in a single statement and when I need to, leverage the benefits of a normalised data structure to define canonical versions of entities I can change on a whim. I pay for this privilege, mind you:
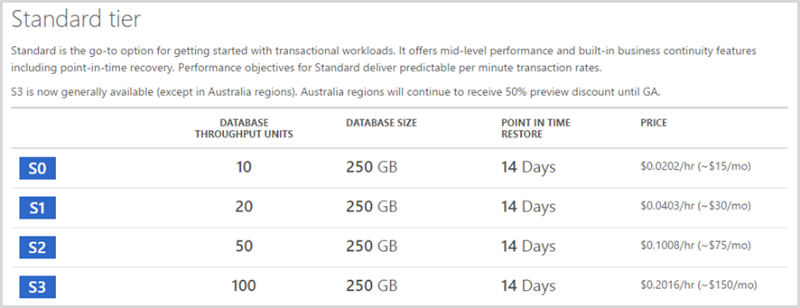
So that’s a six-fold cost increase on what I’m presently paying for Table Storage just for the cheapest “standard” database and that’s a pretty low-spec one too. I found myself needing to run at S2 levels for a while with HIBP which is thirty times the cost I’m paying for Table Storage and it was only after de-normalising the schema that I reduced the perf overhead enough to bring the cost down. This is the thing with most components of a system – you can usually increase the perf by throwing dollars at it.
Here’s the crux of the lesson: You need to decide what you’re optimising for and choose the right storage constructs for that. Sometimes, as with HIBP, that may even be a hybrid of NoSQL and SQL.
Table Storage optimises for read speeds and cost. My writes to it can be slow as I’ve explained before but that’s fine as it’s a background process that doesn’t hit the user experience. What’s important to me is that it’s fast when people search and that I can justify the expense.
Relational databases optimise for queryability. I use SQL Azure when I want to do things like see which of my subscribers exist in a breach (I temporarily load this data into SQL during import) so that I can figure out where there’s been a match. It’s great at finding the occurrence of one record within hundreds of thousands that also exists within a breach containing millions of rows. I can also keep the perf low and the cost down because again, it’s a background process.
NoSQL databases are not your father’s RDBMS and if you try to use them as such you will be very disappointed and inclined to proclaim many negative things about how awful Azure is (or other cloud platform used in an inefficient way, I might add). But if you want the supercar of cost and performance for key lookups, Azure Table Storage is where it’s at.