Spoiler: I have data from the story in the title of this post, it's mostly what I expected it to be, I've just added it to HIBP where I've called it "Data Troll", and I'm going to give everyone a lot more context below. Here goes:
Headlines one-upping each other on the number of passwords exposed in a data breach have become somewhat of a sport in recent years. Each new story wants to present a number that surpasses the previous story, and the clickbait cycle continues. You can see it coming a mile away, and you just know the reality is somewhat less than the headline, but how much less?
And so it was in June when a story with this title hit the headlines: 16 billion passwords exposed in record-breaking data breach. I thought this would be another standard run-of-the-mill sensational headline that would catch a few eyeballs for a couple of days then be forgotten, but no, apparently not. It started with a huge volume of interest in Have I Been Pwned:
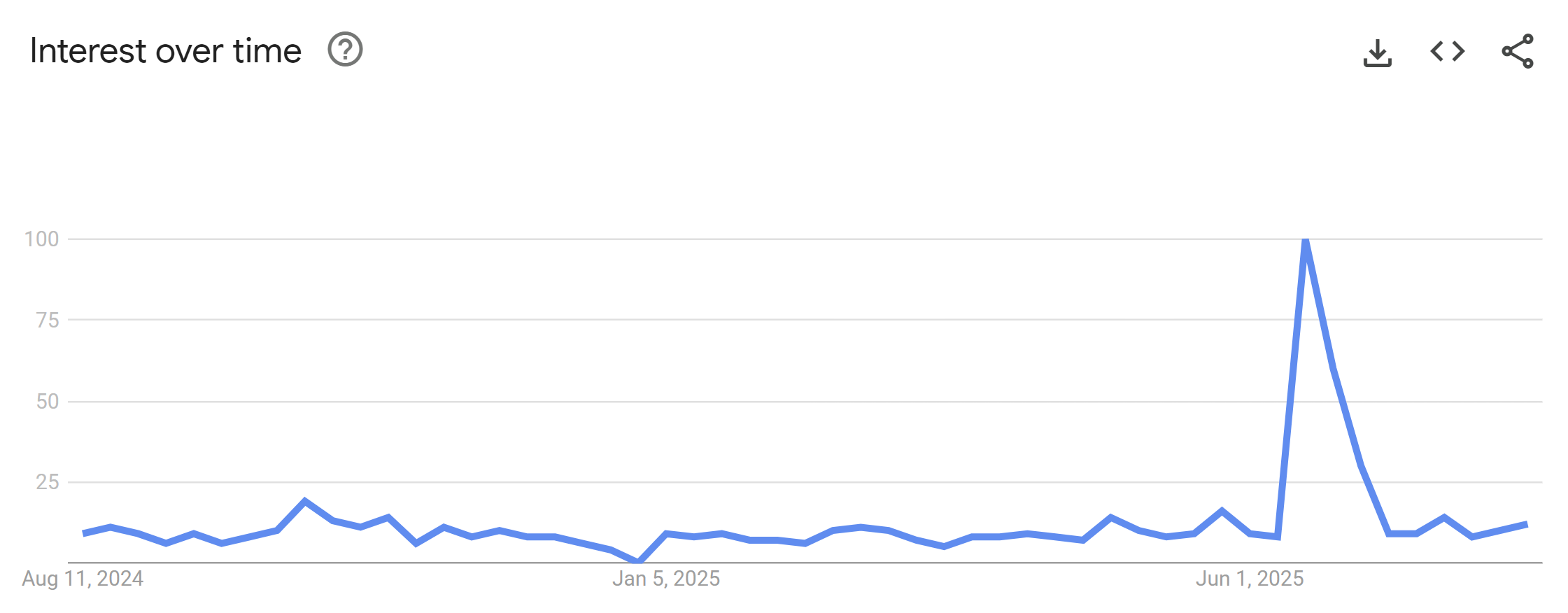
That's Google searches for my "little" project, which I found odd, because we hadn't put any data in HIBP! But that initial story gained so much traction and entered the mainstream media to the extent that many publications directed people to HIBP, and inevitably, there was a bunch of searching done to figure out what the service actually was. And the news is still coming out - this story landed on AOL just last week:

You know it's serious because of all the red and exclamation marks... but per the article, "you don't need to panic" 🤷♂️
Enough speculating, let's get into what's actually in here, and for that, I went straight to the source:
Bob is a quality researcher who has been very successful over the years at sniffing out breached data, some of which had previously ended up in HIBP as a result of his good work. So we had a chat about this trove, and the first thing he made clear was that this isn't a single source of exposure, but rather different infostealer data sets that have been publicly exposed this year. The headlines implying this was a massive breach are misleading; stealer logs are produced from individually compromised machines and occasionally bundled up and redistributed. Bob also pointed out that many of the data sets were no longer exposed, and he didn't have a copy of all of them. But he did have a subset of the data he was happy to send over for HIBP, so let's analyse that.
All told, the data Bob sent contained 10 JSON files totalling 775GB across 2.7B rows. An intial cursory check against HIBP showed more than 90% of the email addresses were already in there, and of those that were in previous stealer logs, there was a high correlation of matching website domains. What I mean by this is that if the data Bob sent had someone's email address and password captured when logging into Netflix and Spotify, that person was probably already in HIBP's stealer logs against Netflix and Spotify. In other words, there's a lot of data we've seen before.
So, what do we make of all this, especially since the corpus Bob sent is about 17% of the reported 16B headline? Let me speak generally about how these data sets tend to have hyperbolic headlines, and the numbers of actual impact are way smaller:
- There's usually duplication across files, as the same data appears multiple times
- There's also often duplication within the same file, again, as the same data reappears
- A "row" is an instance of someone's email address and password listed next to a website they're logging onto, so 100 distinct rows may all be one person
The corpus of data I received contained 2.7B rows, of which I was able to extract 325M unique stealer log entries. That's the number of rows I could successfully parse out website, email address and password values from. In my earlier example with the one person's credentials captured for both Netflix and Spotify, that would mean two unique stealer log records. All of this then distilled down to 109M unique email addresses across all the files, and that's the number you'll now see in HIBP. In other words, 2.7B -> 109M is a 96% reduction from headline to people. Could we apply the same maths to the 16B headline? We'll never know for sure, but I betcha the decrease is even greater; I doubt additional corpuses to the tune of that many billion would continue to add new email addresses, and the duplication ratio would increase.
Because it always comes up after loading stealer logs, a quick caveat:
Not all email addresses loaded into this breach will contain corresponding stealer log entries. This is because we have one process to regex out all the addresses (the code is open source), and another process that pulls rows with email addresses against valid websites and passwords.
And because I'll end up copying and pasting this over and over again in responses to queries, another caveat:
Presence in a stealer log is often an indicator of an infected device, but we have no data to indicate when it was infected. There will be a lot of old data in here, just as there's a lot of repackaged data.
Of the passwords in valid stealer log entries, there were 231M unique ones, and we'd seen 96% of them before. Those are now all in Pwned Passwords with updated prevalence counts and are searchable via the website and, of course, via the API. Speaking of which, those passwords are presently being searched a lot:
Every time I look, there's another billion (or two) pic.twitter.com/X7gflzWdCH
— Troy Hunt (@troyhunt) July 30, 2025
Of the 109M email addresses we could parse out of the corpus, 96% of them were already in HIBP (that number coincidentally matches the percentage of existing passwords we track). They weren't all from previous stealer logs, of course, but anecdotally, during my testing, I found a lot of crossover between this one and the ALIEN TXTBASE logs from earlier this year. Regardless, we added 4.4M new addresses from Data Troll that we'd never seen before, so that alone is significant. Not significant enough to justify hyperbolic headlines to the effect of "biggest ever", but still sizeable.
To summarise:
- The 16B headline distils down to a much smaller number of unique values of actual impact
- The data is largely from stealer logs that have been circulating for some time now
- It's certainly not fresh and doesn't pose any new risks that weren't already present
And lastly, there's that "Data Troll" title. When I first saw this story getting so much traction, the image I had in my mind was of a troll sitting on stashes of data. The mass media then picked this up and turned it into deliberately provocative headlines, manipulating the narrative to seek attention. Hopefully, this post tempers all that a little bit and brings some sanity back into the discussion. We need to take data exposures like this seriously, but it certainly didn't deserve the attention it got.