It's almost 3 years ago now that I launched the Have I been pwned (HIBP) API and made it free and unlimited. No dollars, no rate limits just query it at will and results not flagged as sensitive will be returned. Since then it's been called, well, I don't know how many times but at the least, it's well into the hundreds of millions if not billions. I've always been pretty clear on not logging searches or tracking anything personally identifiable and that combined with attempting to squeeze out every last bit of performance whilst keeping costs low have meant not tracking the API calls over time. What I do know though is that often my traffic will do this:
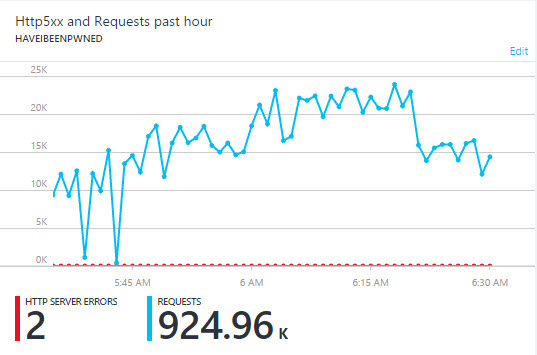
What you're looking at here is 925k requests to HIBP over the period of an hour. It's peaking at about 24k requests a minute and each of those requests is searching through 1.3 billion records. As I've written many times before on Azure, the way I achieve this scale is by allowing the platform to add web instances in response to demand. At present, if CPU utilisation goes over 80% across a 10-minute period then I add an instance. Once it drops down under 40%, I take one away. It means my CPU utilisation for the period above looks like this:
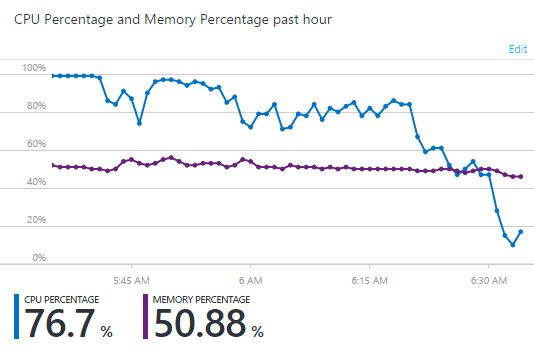
You can see utilisation at 100% early on then dropping over time as additional instances are added to the web farm. This causes several problems that I want to address here.
Why high volumes of API calls are problematic
Firstly, the API is being called in a way which means requests are going from a steady organic state to full thrust in a matter of seconds. This maxes out the CPU and degrades the performance for everyone until more instances are put on. Autoscale works beautifully when traffic ramps up steadily, but I'm going to wear a perf hit when it suddenly goes off the charts.
Secondly, money. I've always run this with the cost objective of paying "less than I spend on coffee". Particularly over the last few months (and traffic patterns over that period is the catalyst for this blog posts), I've found myself needing to drink more and more coffee at ever increasing prices in order to reach that stated goal which is, well, not really what I want to be doing.
But there's another issue beyond performance and cost that I've become increasingly conscious of, and that's ethical use. This is a hard one for an API of this nature; you want it to be easily consumable but you also don't want it being abused. Whilst I publish acceptable use guidelines, that serves primarily as a point of recourse for me ("hey, you're not playing nice per the stated guidelines...") than it does as enforcement to ensure it's used in the right way. The very first point in those guidelines is that the API should not be used to cause harm to other people but as the data set grows, the likelihood of this happening increases. Recently, there's been various indicators that the API has been used in ways that aren't in keeping with the spirit of why it was created and whilst I won't go into the details of it here, it's not something that I want to see continuing.
What all of this means - the cost, perf impact and potential for abuse - is this: starting on September 12, the free API will be rate limited to 1 request per IP address per second. Let me talk through the rationale behind this method of rate limiting:
One of the most important considerations for me was not breaking legitimate applications using the API. As you'll see on the API consumers page, a bunch of people have made really neat apps that do positive things for online security in a way that's entirely consistent with how I'd hoped it'd be used. If I'd added an auth requirement, these would break without first reworking them and whilst there are times where that might make sense for certain APIs, I didn't want to break anything unless absolutely necessary. When that API is hit directly from the client consuming it such that the requests are distributed out to many different IP addresses (i.e. when the consumer is a mobile app), they're not going to be making more than 1 request a second anyway.
For anyone scanning multiple addresses in quick succession via an automated script, the rate limit still gets you 3.6k requests an hour. If, for example, you're scanning through your organisation's emails then that's just fine for a small to medium sized company. What it'll do though is make it significantly less feasible to scan through a huge address list. What I'm trying to stop here is doing this for the purpose of identifying otherwise random individuals. However, for legitimate use cases, there's another avenue:
Using the API for commercial purposes
I'm still making commercial options available. Just over a year ago I wrote about a commercial offering with HIBP which allows an organisation to proactively monitor email addresses and domains. By "proactively", I mean there's a web hook implementation which reaches out to an API endpoint on the customer's side and notifies them when there's a hit. There's also the ability to search through both email addresses and domains without rate limit and including sensitive breaches. I want to clearly explain the caveats around this though:
There are a small collection of organisations presently using the commercial offering. They're monitoring accounts where either there has been express permission given by the email address owner ("I would like you to watch for occurrences of my address as part of the identity protection services you provide...") or the owner of the domain ("We would like to monitor where our company's email addresses are appearing..."). I speak to every single organisation using this service; not colloquially "speak" as in an anonymous messaging chat, rather we talk via Skype and I work with them to help them use the data in a positive way. They sign a contract outlining expectations of how the data can be used and we establish an ongoing commercial relationship. What it means is that I have a very high degree of confidence that they're using the data in an ethical way in the best interests of those who own the accounts they're monitoring.
With all that now said, let me talk about how this is technically implemented and what you should keep in mind if you're calling the API at a rate that could exceed the limit.
Technical implementation
Every time the API is hit, the IP address of the caller is stored in cache for a duration of 1 second. When the inbound request arrives, the cache is searched and if the IP is found, an HTTP 429 "Too Many Requests" response code is returned. If the IP isn't found in cache, the request is processes as per usual. The rate limiting is implemented independently on the breaches and pastes APIs to ensure users of the web interface can asynchronously hit both without the second one being rejected. The POST action to the root of the website also implements the same logic to ensure it can't be screen scraped (this is usually just a fallback for if JavaScript is disabled).
Per the spec, I'm also returning a "Retry-After" after header which specifies how long the client should wait before issuing another request. However, this value is expressed in seconds and when I'm allowing one request per second, it pretty much always rounds down to zero. If you're coding to cater for the retry then I'd still pay attention to the header in case I change the rate later on.
Here's what a sample rate limited response looks like:
HTTP/1.1 429 Retry-After: 0 Rate limit exceeded, refer to acceptable use of the API: https://haveibeenpwned.com/API/v2#AcceptableUse
This is the simplest possible implementation I could conceive of. It has no requirements for additional data repositories (cache is stored in-process), it has almost zero overhead as the cache duration is so short and as I said earlier, it requires no changes on the consumers' end (unless they're exceeding the rate limit, of course).
This is also not foolproof; requests could exceed 1 per second if there are multiple instances of the web front end running due to scale out (the in-process cache is machine specific). Someone could also fire up a botnet and hammer it from different IPs all around the globe. However, compared to the present state where I'm frequently seeing many hundreds of requests per second, the rate limiting approach still makes a massive difference either in the volume of possible requests or the financial resources required to make them (i.e. renting a botnet). But it doesn't have to be perfect, it just has to be much better than it presently is.
Testing the rate limit behaviour
The rate limit feature is now fully active in the HIBP staging environment. In fact, both environments are running an identical code base right now and the rate limit is merely feature-toggled to "off" in production. If you're going to need to modify your consuming client to adapt the number of calls it makes, I strongly suggest you play in this environment before the rollover next month.
Help support HIBP by playing nice
I'm going to continue trying to keep as much of HIBP as easily accessible and freely available as possible. To do this, I need the community's support by working within the rate limits. The implementation above will ensure valid responses aren't returned at a rate of more than 1 a second, but it won't stop people hammering it and getting a plethora of 429 responses before getting a valid one. There are other avenues available to block these clients outright but I'd far prefer requests were just kept within the rate limit and the service was used responsibility.
Further to that (and this is the bit where I need to be a bit more serious), I will start blocking abusive clients that aren't adhering to the existing acceptable use guidelines before the rate limit kicks in on the 12th. These guidelines have been documented on the API page for some time now and I've embellished them a little further over the weekend. It's only those that are quite blatantly using the API contrary to the way it's intended to be used that will be impacted and those folks have a pretty good idea of who they are.
As always, please provide your comments below if you've got any feedback you think I really should take on board. I've ensured there's 4 weeks of lead time precisely for that reason and to make sure that anyone who may be exceeding it has time to consider the right path forward.
Update: I've had some great feedback from people and also done a heap of testing. I'd like to provide a few updates that cover a minor evolution of this model:
- I've set the cache expiry to "sliding" rather than "absolute". What this means is that the expiration period resets every time it's accessed which consequently penalises the client if they attempt to retry too soon. This is primarily due to concern over clients hammering the API until they get a valid response code rather than waiting for the Retry-After period to pass.
- The rate limit has been slowed to one request per 1.5 seconds. The primary reason for this is that 1 second is the default cache flush interval for ASP.NET and I was finding a race condition when the retry was 1 second which caused the sliding expiration to fail and behave like absolute expiration. Even 1.1 seconds was a bit flaky so I've gone with 1.5 seconds which should still be plenty for normal usage (although I'll definitely take any feedback to the contrary). Thanks to Nick Craver for his explanation of the problem.
- The Retry-After header now always rounds up to the next whole second. Combined with the sliding expiration model meaning that the retry period resets on every request, this means that at the pre-set rate the value will always be 2. As mentioned above, pay attention to this and use it in your code just in case it changes in the future.
Keep in mind that whilst the rate limit is coded at precisely 1.5 seconds in the app, network idiosyncrasies can mean that if you send requests at precisely every 1.5 seconds you may still see 429 responses as the previous request need only have taken 1ms longer to arrive than the subsequent one. I've been testing this extensively and reissuing requests at precisely 1.5 second intervals caused a number of 429s but 1.6 second intervals had a perfect success rate.
These changes are now all reflected in the API documentation and I'm still on track for rolling over to the rate limit model on September 12. All the changes covered in the update here are live in the staging environment right now so you can continue to test there before the rollover in production.