Who remembers what it was like to build web apps on a shared development server? I mean the model where developers huddled around shared drives mapped to the same UNC path and worked on the same set of files with reckless abandon then fired them up in the browser right off the same sever.
Maybe this is an entirely foreign concept to you but I certainly have vivid memories from the late 90s of building classic ASP apps (ye olde VB script) in Dreamweaver, side by side my fellow developers working on the same set of files on the same mapped path. I clearly recall the vocal nature of this way of working; “Have you closed the CSS file? I need to add a class”. And I definitely remember the find and replace episodes, a process only safe to execute once every developer saved their work and closed all their files.
Then there was source control. Well, sort of. Depending on where I was at the time, an “advanced” environment might have Visual Source Safe (let’s not get started on that one right now), CVS or even Rational Clear Case. But normally it would be the classic pattern of selecting the root folder of the app then going “CTRL-C –> CTRL-V –> Rename” with the date appended at key points in the project.
In retrospect, there were probably better ways of doing it a dozen years back but certainly the practices above were reasonably common. But today, no one in their right mind would consider building apps this way. It’s simply not done, and for good reason.
So why are so many people building the databases behind their web applications this way? Is the data layer really that special that it needs to be approached entirely differently? Do the lessons hard learnt since the last century no longer apply?
What are we talking about here?
Just so there’s no confusion, let’s be clear about what we’re talking about. The shared database development model involves the developers building the web app layer in the usual fashion (Visual Studio running locally, files stored on the developer’s PC) yet all connecting to a remote database server and working directly on the same DB. It looks something like this:
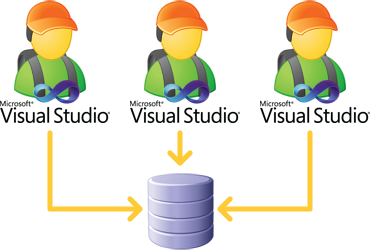
Usually they’d be working with the likes of SQL Management Studio running locally and connected to the remote environment. When the app actually runs locally, all data connections are going out to the shared, central environment. There is no local instance of SQL Server on the developers’ machines.
The alternative, of course, is dedicated development databases. Things now look a little bit different:
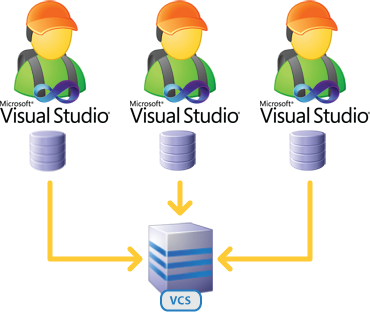
Obviously each developer has their own version of the database but perhaps the biggest difference to the earlier model is the necessity of a version control system. Which brings us very nicely to the next issue.
Database source control is no longer negotiable
Let’s get one thing clear early on because it’s going to come up a bit; if you’re not putting your database under source control, you’ve got a big issue. In times gone by, versioning databases wasn’t easy but we’ve now got numerous tools at our disposal to elevate the DB to a first class VCS citizen.
In terms of .NET, there’s obviously the official Microsoft Team Foundation Route but there are also offerings from third parties such as Red Gate’s SQL Source Control. Around the middle of last year I wrote about Rocking your SQL Source Control world with Red Gate and then Foolproof Atomic Versioning of Applications a little after that, both of which go into detail about the importance and value of versioning your databases. So I won’t repeat the message here. Just make sure you’re doing it, ok?
The “last writer wins” problem
The obvious problem with collectively working on a shared database is that when it comes to the problem of multiple developers working on the same object at the same time, it’s a case of “last writer wins”. No merge, no conflict management, just the last guy getting his way.
In order to mitigate the risk of this happening, you have to implement social mechanisms to work around the problem. So you’re back to developers communicating backwards and forwards in an attempt to keep their fellow coders out of their work in progress. It’s clumsy, it’s labour intensive and it will fail. It’s just a matter of time.
The “experimentation” problem
An essential part of software development is experimentation. Unless you’re a true believer in the waterfall mantra of “design then build” and two shall only ever progress in that sequence, you’re inevitably going to build some code that sucks and consequently change direction. This is healthy, its part of the continuous improvement cycle we all implicitly exercise every time we build software.
What’s not healthy is exposing your experimentation to the other developers in the team such that it negatively impacts on their work. Whether this be removing dependencies which breaks their code or adding objects which unexpectedly change the result of their ORM layer generation, experimentation is about you trying different approaches and not forcing it upon your team. In short, you need your own sandbox to play in which spans each layer of the application.
Martin Fowler has a nice summary in his article about Evolutionary Database Design:
Evolutionary design recognizes that people learn by trying things out. In programming terms developers experiment with how to implement a certain feature and may make a few attempts before settling down to a preferred alternative. Database design can be like that too. As a result it's important for each developer to have their own sandbox where they can experiment, and not have their changes affect anyone else.
Experimentation without external detriment requires you to be selfish and demand your own play space.
The “unpredictable data state” problem
Whilst the “last writer wins” scenario can be largely mitigated by how the developers work (segmentation of tasks, social communication before changes, etc.), the unpredictable state of the data is a whole new level of trouble.
The problem is simply that databases tend to change as the applications on top of them are used. I don’t mean “change” as in the object level, rather the data within the tables. It’s the whole reason we’ve got the things in the first place; so that we may manipulate and persist the state of the data.
Let’s take a typical scenario. We’ve got an app with an authentication module and administration layer and each of the developers have created accounts which they can test with. But the guy building the administration layer wants to test how the app behaves with no accounts in it. Now we’ve got a problem because deleting the existing accounts impacts on the development of the other team members.
This is a very basic scenario and it’s usually only once things become more complex that the trouble really begins. Complex scenarios that are highly dependent on the state of data, for example, become a nightmare when you simply can’t control how it’s being changed. Unpredictability is not your friend when it comes to building software.
The “unstable integration tests” problem
If integration tests with data dependencies exist (I’ll refrain from calling them “unit tests” if we’re talking about having a data dependency), having a predictable data state is absolutely essential. Any expectation of a function returning a predictable set of data goes right out the window when the test is running against a fluid environment.
Obviously having a system with a constantly changing set of data is a bit of a predictability anti-pattern. You must be able to continuously run these tests against a predictable, stable set of data and that’s never going to be an environment where everyone is continuously evolving both the schema and the data.
The “objects missing in VCS” problem
One of the problems with working in a shared database is that one of the primary objectives for using source control – continuous codebase integration with the work of your peers – goes right out the window. You see, when every change is central and immediately available to everyone, what’s the driver to commit?
Of course what’s really happening here is that the shared model is simply allowing a bad practice to creep in without repercussion. This is an interesting side-benefit of working with dedicated databases and this pattern comes up in a few different places. The trick is to look at the issue in a “glass half full” fashion – dedicated development databases drive good VCS practice – rather than in the “glass half empty” way which would be to say the dedicated databases make it difficult to share work.
The “disconnected commuter” problem
Using a shared development database forces you to be connected to the network at all times. If you want to take work with you and slip some development time in on the train or work through the weekend in the comfort of your own home, you’re only going to have half the solution available. Yes, there are often VPN solutions or other means of remote access but you’re starting to increase the friction of working productively.
The same problem extends to working effectively with those outside the network segment which contains the shared database. Want to send work out to a partner for a few weeks? Sure, you can do that by backing up the DB and sending it out but the chances are you’re going to have issues integrating back into the trunk of development if the project is really not geared for distributed database development.
This issue may not be a problem for many, but it’s unnecessarily prohibitive. It shows that the project has been tightly coupled to a single internal implementation of a database server and this is always going to result in more difficulties further down the line. More on that in a subsequent post when I look at continuous integration and automatic deployment of databases.
The “sysadmin” problem
One of the problems with development in any environment, including a database server, is that there are times when elevated privileges are required. When this environment is shared, there are potential consequences well beyond the scope of a single application.
Here’s a case in point; I recently suggested to a developer that their performance tuning could benefit from some SQL Server Profiler analysis to take a closer look at things like reads and writes. This particular case involved a shared database so the next thing that happens is I get an email back with an image like this:
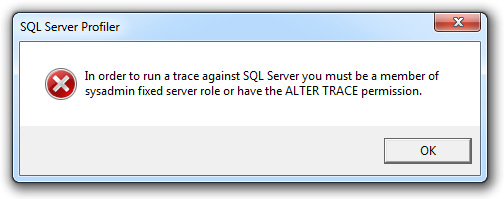
Frankly, I don’t want the guy to be sysadmin on a box that may contain totally unrelated databases he probably shouldn’t have access to. I could give him ALTER TRACE permissions (and ultimately, I did), but of course this has to be set at the master database level so now he has the right to inspect every query across every database.
This discussion would never have even taken place in the dedicated local database scenario. He would have simply already had the rights and it would have been dealt with locally. There are plenty of similar scenarios where the rights a developer needs to do their job exceed what should be granted in a shared environment.
The “unexpected performance profiling” problem
Continuing from the previous point, performance profiling in a shared environment where you have no control over the other processes running on the machine is an absolute nightmare. That query which takes 20 seconds to run one moment can easily blow out to 50 seconds a moment later. Why? You have no idea.
Whilst it’s always a bit tricky getting consistent results from any sort of performance profiling, the worst thing that can happen in the midst of this is other processes getting in your way. When you’re doing this locally, you have both visibility and control over these processes.
Of course there are cases where performance profiling on a PC is simply not going to yield constructive results. For example, huge volumes of data which would normally be queried on seriously specced servers. But for the purposes of everyday development, having a predictable environment is a pretty important part of performance tuning a developer would normally do.
The “non-representational latency” problem
So let’s say you’re working on a shared database which is inevitably located on a server in a data centre. Where exactly is that? How many milliseconds of latency are being added to each round trip?
The problem is that in a world of data centre consolidation (and rightly so, I might add), you’re quite possibly going to be loading up a whole heap of additional latency to each ADO.NET connection which is going to be non-representational of the target live environment. I’m guessing you don’t have the same sort of gigabit Ethernet connectivity from your PC as the production web application server will have and that creates a little bit of a problem.
It’s a problem in that the application performance in the development environment is going to be comparatively sluggish. The degree of comparative sluggishness will depend on the latency and the amount of activity over the wire but, for example, 150ms to a remote SQL server coupled with a chatty application is not going to make for a very accurate representation of real world app performance.
The “my development machine is crap” problem
Of course the “problem” with developing databases locally is the necessity to run SQL Server on the PC. I say “problem” in quotes because the issue is not so much that SQL Server is asking too much of the machine, it’s that developers are all too frequently given crap PCs.
If developers are given machines which struggle to concurrently run Visual Studio, SQL Server and the usual “business as usual” tools (Outlook, Word, etc.), there is a bigger underlying problem to be addressed. This is not an overly demanding requirement!
Here’s the underlying problem; developers are not cheap. In Australia, your average developer is costing about $90k a year. There are then a whole bunch of other costs to contend with such as floor space, equipment (other than the PC), operating expenses (such as payroll) and on and on and on. Conservatively call it $100k annually or around $420 for each day they work.
On the other hand, fast PCs are cheap. I recently replaced an aging laptop and the difference in price between a run of the mill machine designed for the desk jockey who lives in the Office productivity suite and an 8GB, SSD, i7 machine was $0.60 a day over a three year lifespan. Put it this way – if you fit the $90k/y bill and you’ve read this far (say 10 minutes), you’ve just consumed three weeks worth of super-fast machine machine upgrade based on your hourly rate and the time cost of reading this post. Enough said.
And yes, yes, I know developers and costs are a lot cheaper in other countries. So let’s assume only $25k annually; you’re still looking at over $100 a day for these guys and a $0.60 cost to fundamentally improve their productivity. If you need to debate the mathematics of this with anyone, it’s probably time to have a good hard look at how conducive the environment is to having a productive, fulfilling role. For some essential further reading, check out Jeff Atwood’s Programmer's Bill of Rights.
The “SQL Server Developer Edition” solution
Microsoft provides the perfect model for developing DBs locally in the SQL Server Developer Edition. This is effectively a full blown Enterprise edition licensed for non-production use. Chances are you already have a license if you have an MSDN subscription but even if you don’t, its dirt cheap.
Installed locally, it can easily be configured so the service doesn’t start automatically if you’re really worried about it dragging down the performance of your PC when you’re not even using it:
But having said that, unless you’re seriously pounding it the resource usage is pretty small. Mine is sitting there consuming only 340MB of memory (about 4% of what’s on the machine) and 0.4% of CPU. So unless you’re running under-specced hardware (again, this is reflective of a deeper problem), the performance impact shouldn’t even be noticeable.
The “script it all” solution
One great thing about decentralising your development database is that it forces you to script a “ready state” of data. Versioning of database objects is one thing, and it’s obviously essential, but we all know most apps won’t play nice if they start out with zero records in them. All sorts of reference data is usually required to initialise a database so the problem now becomes how you get that there.
Initialising database state via SQL scripts forces you to think clearly about what it is your application needs to function. Rather than just organically growing reference records as required, you need to think through the purpose of each table and what it needs to contain in order to achieve that “ready state”.
The other big bonus is that this script then goes into source control. It gets versioned along with the DB objects and persists in VCS for perpetuity.
Finally, scripts are fantastic for automation. It means that at any time you can pull a revision from VCS and have a clean, repeatable installation of the application. Tie that into a continuous integration environment and you now have one click deployment of the entire app. More on that in a later blog post.
The “this will damn well force you to do it right” solution
Working on dedicated local databases forces a number of good practices which could otherwise be circumvented in the shared world. The obvious one is source control; if you’re not versioning your database objects and reference data, you’re doing it wrong and you simply can’t get away with it any more if the only way your colleagues can get the changes is via VCS.
Following on from the source control point, in order for this to work effectively and not break builds, work needs to modularised and committed atomically. You can no longer get away with randomly changing unrelated parts of the application lest you begin “breaking the build” for others, something which is generally not received very positively by your peers. This is a good thing; it forces more thoughtful design and conscious completion of tasks.
And of course you can’t get away with running SQL Server on that crap PC with a single GB of RAM and an old 5,000 RPM disk. You actually have to get a half decent machine – I mean one that is actually suitable for building software on!
So you see, the whole shared development database model is actually a mask for many of the practices you might might not be doing properly to begin with. Working autonomously on a local DB becomes a self-perpetuating cycle of practice improvement as it simply won't let you get away with taking nasty shortcuts.
Summary
If you’re working in the shared development database model, chances are you’ve simply inherited the practice. Take a good look around; are you really working this way because it’s the most effective possible way of building software? Or is it because of unnecessary environmental constraints?
The thing is, developing locally on dedicated databases is not only better for the process of database development, it’s better for configuration which means better for deployment. It’s also better for development processes in general (experimentation, modularisation of work, etc.) and solves all sorts of other problems which arise from the communal DB model.
So really, what’s stopping you?