I noticed an odd trend when reviewing the ELMAH logs in Have I been pwned? recently. I was seeing a lot of 404 “Page not found” errors for paths like this:
/gen204?client=te-lib-alt&trans=confSum=982,numLowConf=0,numPhrases=1,cB15=1,cB19=1 /gen204?client=te-lib-alt&trans=confSum=4726,numLowConf=0,numPhrases=5,cB15=1,cB19=4 /gen204?client=te-lib-alt&trans=confSum=2000,numLowConf=0,numPhrases=2,cB20=2
Uh, ok, this doesn’t look like the usual randomised attack, what’s going on here? Often you find it’s bots (not necessarily malicious ones) that cause 404s by crawling the web looking for certain patterns. I pulled the user agent strings from the ELMAH logs (querying the XML it stores is dead easy), and found a lot of this sort of thing:
Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0) Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36
Nothing unusual there, these are all pretty normal UA strings and what’s more, they’re spread across multiple versions of browsers and operating systems. The referrer for each of these references is also the HIBP site – it’s not being loaded up from an external source. Nothing jumping out there then.
Ok, so let’s start looking at IP addresses. Loads of different ones there so they’re not coming from a single point of attack or other centralised process, let’s take a look at where they’re located. Here’s where the first one I checked was:
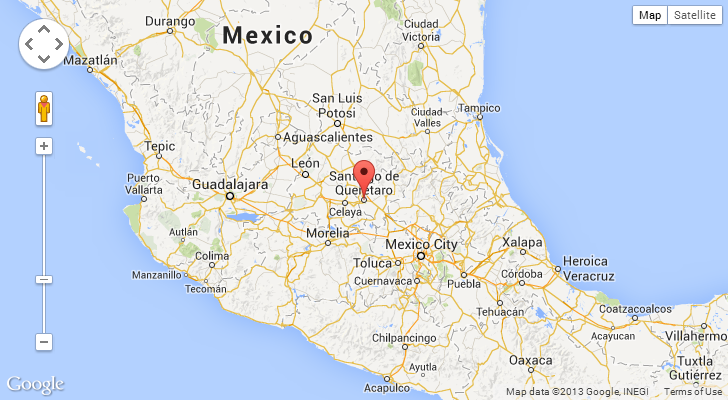
Here’s the next one:
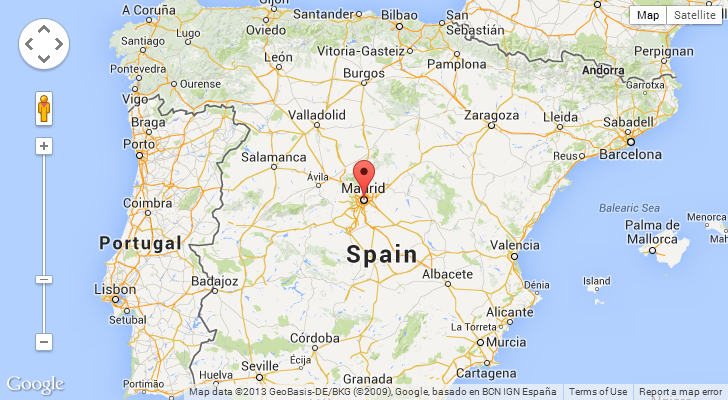
And another one:
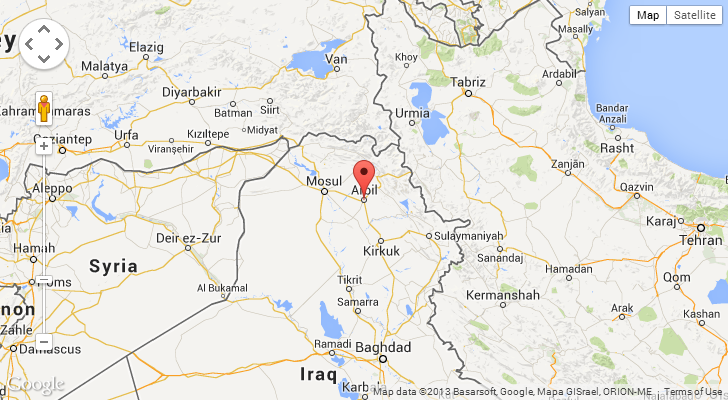
I think we’re seeing a trend here – these are foreign countries! Ok, that’s a relative term so let me rephrase: they’re non-English speaking countries. This is on a site with a very heavy US presence so having the IPs belong to the countries above makes them outliers. Let’s look at the HTTP_ACCEPT_LANGUAGE values:
fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4 ru-RU,ru;q=0.8,en-US;q=0.6,en;q=0.4 ar,en-US;q=0.8,en;q=0.6
Ok, that seals it; under normal operating conditions, the vast majority of the site audience is sending some derivative of en- as their primary language yet the vast majority of the gen204 requests are from non-English browsers. Why is it so? Translations, or more specifically, Google translate. Here’s how I came to that conclusion:
Usually you can quickly identify this sort of pattern by a quick Google search, but not in this case (and this is largely the catalyst for this blog post). In fact the Google results were very odd, for example:
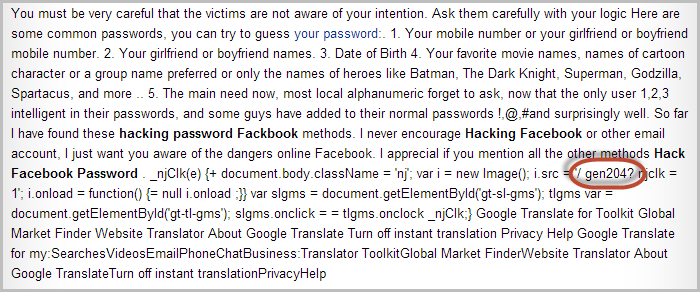
There it is in that mess of JavaScript that’s been emitted to the page. Here it is again:

Also in a mess of JavaScript. This isn’t being rendered by the DOM either, it’s in the page source when it’s loaded from the server. It’s almost like it’s persistent XSS, except it has no apparent functional upside for an attacker.
But the script is useful in another way – both instances (and others I haven’t repeated here), refer to Google Translate – there’s the link. If we prettify the JS, here’s the important bit in terms of where gen204 is appearing:
_njClk(e) { document.body.className += ' nj'; var i = new Image(); i.src = '/gen204?njclk=1'; i.onload = function () { i.onload = null; }; }
That’s enough to draw some conclusions:
- The gen204 reference is coming from the Google Translate script
- It appears to be executing in the DOM context of the target site
- The script above is setting an image source of gen204 plus a query string
- I have no idea why this is happening (although best guess is a browser plugin)
On that last point, whilst I haven’t gone deep enough down the rabbit hole to explain why this is happening, I’ve seen enough to conclude it’s nothing that requires any effort on my part. It’s not a broken reference on my site nor is it a malicious attack, it’s simply some screwy JavaScript looking for something that doesn’t exist.