So that little project Scott Helme and I took on - WhyNoHTTPS.com - seems to have garnered quite a bit of attention. We had about 81k visitors drop by on the first day and for the most part, the feedback has been overwhelmingly positive. Most people have said it's great to have the data surfaced publicly and they've used that list to put some pressure on sites to up their game. We're already seeing some sites on the Day 1 list go HTTPS (although frankly, if the site is that large and they've done it that quickly then I doubt it's because of our list), and really, that's the best possible outcome of this project - seeing websites drop off because an insecure request is now redirected to a secure one.
In the launch blog post, I wrote about the nuances of assessing whether a site redirects insecure requests appropriately. The tl;dr of it was that there's a bunch of factors that can lead to pretty inconsistent behaviour. Just read the comments there and you'll see a heap of them along the lines of "Hey Troy, site X is redirecting to HTTPS and shouldn't be on there", followed by me saying "No they're not, here's the evidence". For example, roblox.com:
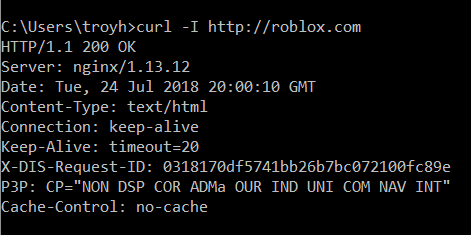
And if you're going to roblox.com over the insecure scheme now and thinking "these guys have got it wrong", look at the requests the browser makes:
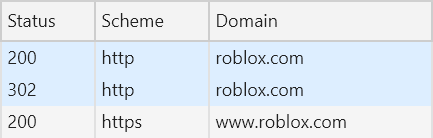
If we drill into the response of that first request, we can see how it's all tied together:
It's a rather bizarre redirect model where it sets a cookie then reloads the same insecure path but by virtue of having said cookie present, that request then redirects to HTTPS. I'm going to talk more about this later on in terms of why it doesn't warrant removing Roblox from the list, for now I just wanted to highlight how inconsistent redirects can be and how what you observe in the browser may not be consistent with what's on WhyNoHTTPS.com.
Moving on, we wanted to get an updated list out ASAP because there are indeed sites that are going secure and they deserve that recognition. However, that's turned out to be a non-trivial task and I want to explain why here.
What Causes a Site to be Removed From WhyNoHTTPS.com?
Well, when it starts redirecting everyone to HTTPS by default, right? Easy? No.
I ran Scott's latest crawl of the Alexa Top 1M sites and grabbed the JSON for sites served over HTTP (he makes all of these publicly accessible so you can follow along if you'd like). I then pumped it into a local DB and worked out what had dropped off the list from Day 1 and found sites that included the following domains:
Nope, nope and nope. Each one of them still sticks on HTTP, even in the browser which would otherwise follow client-side script redirects. So what gives?
What we have to be conscious of that these 3 sites stuck out because they weren't on Scott's like of HTTP sites. However, they also weren't on his list of HTTPS sites (also available for you to download), so, again, what gives? Quite simply, the crawler couldn't get a response from the site. The site could have been down, the network connection could have dropped or the crawler itself could have been blocked (although note that it should be indistinguishable from a normal browser as far as the server is concerned). So what should we do?
My biggest concern was that now we have a baseline on the site with the Day 1 data, deviations from that state will be seen by many people. If we publish an update and sberbank.ru drops of the list and everyone is like "good on you Sberbank" (and yes, that is a bank), that would be rather misleading and wouldn't do much for confidence in our project.
So what if we go the other way? I mean what if instead of listing everything in the HTTP list, we took the entire 1M list and just subtracted the HTTPS one? This changes the business rule from "the site loaded over HTTP" to "the site didn't load over HTTPS". Anything caught in the gaps between those 2 is then flagged as not doing HTTPS. So I ran the numbers from the latest scan, and here they are:
- Of the top 1M sites, there were 451,938 in the HTTP list and 399,179 in the HTTPS list
- In total, that means 851,117 sites were logged as loading over either HTTP or HTTPS
- Subsequently, 148,883 sites couldn't be accounted for because they simply didn't return a response
Nearly 15% is a lot and that's worrying because there could easily be a heap of false-positives in there. For example, the list includes Instagram, Google in Russia and Netflix. They all do HTTPS.
Consequently, the HTTP list alone won't cut it and the Alexa Top 1M list minus the HTTPS list also won't cut it either, so what are we left with? There was only one way forward:
- All the sites explicitly returning content over HTTP to the crawler and not redirecting make the list
- All the sites that never returned any response need to be tested entirely independently and if they don't redirect, they make the list
That last point may seem redundant but after some quick checks, I found that I could consistently get responses from sites on the 15% gap list where Scott's crawler couldn't. Maybe it's my location, maybe it's because I wrote my own that inevitably behaves slightly differently, I don't know, the point is that this effectively gives those 148,883 sites a second chance at serving content over HTTPS.
But that doesn't always work either! Of the top 10K Alexa ranked domains in that gap list, I still couldn't get a response from 2,907 of them. I was still finding domains which simply wouldn't resolve at all, for example the top 3 are:
These were the 81st, 118th and 162nd top ranked sites respectively and even manually testing them in the browser, none of them go anywhere. The first 2 don't resolve at all and the 3rd one redirects to home.resultieser.com which then, itself, doesn't resolve. I don't know why they make the Alexa Top 1M list (certainly not that high in the order) and I've not dug into it any further so if you have ideas on why this is, leave a comment below.
The bottom line is that we're down to about 4% and a bit of the Alexa Top 1M we simply can't account for and a bunch of those definitely don't go anywhere. I'd like to have a perfect list but the reality of it is that we never will so we just need to do our best within the constraints that we have.
As of now, our first revision of sites not supporting HTTPS is now live at whynohttps.com
I would have liked to have gotten a revised list out earlier but it's because of idiosyncrasies like those above that it took a while to get there. This is also the reason we haven't automated it yet; I'd love to rebuild the index on the site nightly, but right now it really needs that extra bit of human validation to make sure everything is spot on. Automation is definitely on the cards though.
Is it OK to Redirect Without a 30X?
I want to touch on a question that came up quite a few times and indeed I showed this behaviour earlier on with Roblox. What happens if a website doesn't respond with a redirect in the HTTP response header? Is an HTTP 200 and a meta refresh tag or some funky JS sufficient? Let's address that by starting with precisely what these response codes mean.
An HTTP 301 is "Moved Permanently", that is forever and a day the client should assume the resource is no longer at the requested location and is instead now at the location returned in the "Location" header. For example, take this request for troyhunt.com over HTTP:
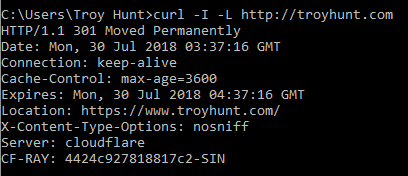
You can see "301 Moved Permanently" on the second line then further down,
Location: https://www.troyhunt.com/I'm telling any client that attempts to request that naked domain name (without www) over the insecure scheme that it should always refer to my site securely and with the www prefix. This is the correct way to redirect from HTTP to HTTPS; a 301 response with the final destination URL in that location header. You'll see sites sometimes doing multiple redirects which doesn't influence how we grade them HTTPS wise, but is inefficient as each redirect requires another request from the client.
Then there's HTTP 302 which is "Found", that is the resource has been temporarily redirected to the location in the response header. This is not want you want when using the status code to redirect people from HTTP to HTTPS because this shouldn't be a temporary situation, it should be permanent. Always do HTTPS all of the time and 301 is the semantically correct response code to do just that. We will still flag the site as redirecting to HTTPS if a 302 is used, but it's not ideal.
As you'll see from the Mozilla articles I linked to on those status codes, this has an impact on SEO. A 301 indicates that crawlers should index the content on the page being redirected to, a 302 indicates that they shouldn't. Browsers will also permanently cache a 301 redirect. Now this actually is important in terms of HTTPS because it ensures the same request for an insecure URL issued at a later date is sent securely before being sent over the wire where it's at risk of interception. (And yes, I'll get to HSTS shortly, let's just finish on status codes first.)
Meta refresh tags and client-side script are not "correct" implementations of redirects from insecure to secure schemes. Yes, they usually work, but they also have exceptions. For example, look at what happens to Roblox if I disable JS in Chrome:
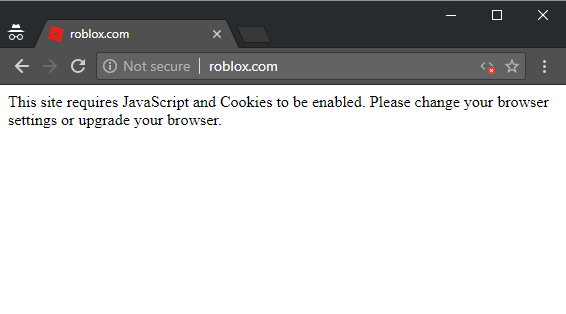
This simply isn't a sufficient implementation of HTTPS as it's just served the entire page over HTTP without any redirect. I have no idea why Roblox has taken this approach, it's very unusual and it's hard to see what upside they're gaining from it.
Of course, the other issue is that particularly in a case such as Roblox's, it's extremely difficult for a parser to reliably figure out if HTTPS redirection is happening. We'd have to somehow programmatically work out that there's a cookie being set and the page reloaded then the behaviour changing when the cookie is there. Consequently, a semantically correct redirect is the only thing what will keep the site off the HTTP list.
But a 301 is only the first step, let's talk about HSTS.
HSTS
Let me reiterate that last sentence - a 301 is the first step - because whilst there are other steps after that, you're not going anywhere without first 301'ing insecure requests. I'm going to delve into HSTS now and just in case that's a new acronym for you, have a read of Understanding HTTP Strict Transport Security (HSTS) and preloading it into the browser if need be.
There are a couple of dependencies for properly implementing HSTS and they're worthwhile understanding before we proceed because I'm going to highlight a case where it hasn't been understood. The first is that the browser will only honour the response header when returned over an HTTPS connection. Yes, you can return an HSTS header over HTTP but the browser will ignore it (think of the havoc and MitM could cause if it didn't...)
Next is that if you want to preload HSTS (which is really where you want to be), there are certain criteria to be met:
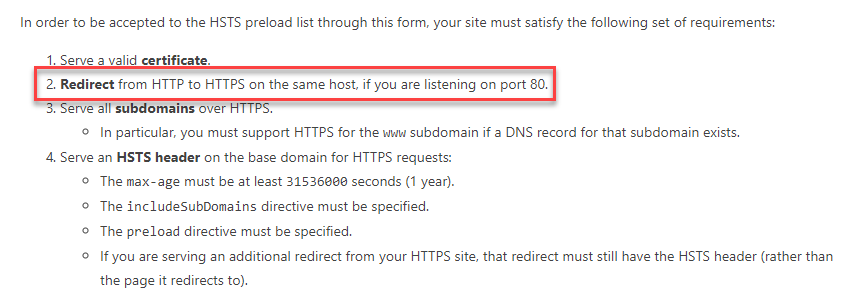
I've highlighted the key one because that speaks to one of the misunderstandings I saw in the wake of us launching the site. Let me illustrate with this site:
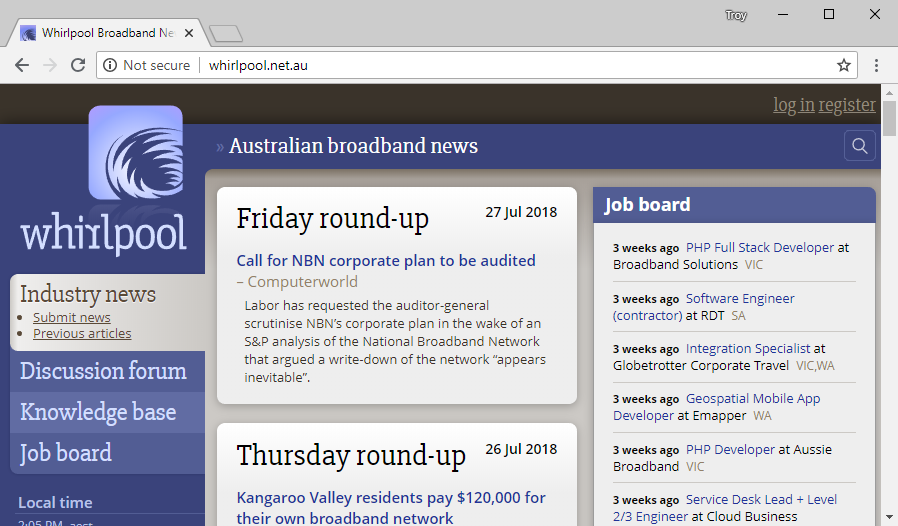
This is the 4th largest Aussie site to make the list and it's a popular local one with an active forum. A thread sprung up last week about some local media coverage getting its inclusion on WhyNoHTTPS.com wrong which judging by the image above, is clearly not correct. There's some "passionate" backwards and forwards there as people are prone to do on forums, amongst which there's some genuinely insightful commentary. But there's also this from the operator of the site:

The first para is best skipped so getting to the HSTS bit, this is missing the most fundamental requirement for HSTS: you must redirect from insecure requests. (There's also the whole point of a 301 putting requests on the secure scheme ASAP in order to dramatically reduce the number of requests sent insecurely.) Just as hstspreload.org explains in the earlier image, without a redirect from HTTP to HTTPS you can't preload. And just in case you're thinking, "ah, but the Whirlpool forum in question is on a subdomain of forums.whirlpool.net.au", firstly, it doesn't redirect from HTTP to HTTPS (that only happens once proceeding to the login page) and secondly, you can't preload subdomains:
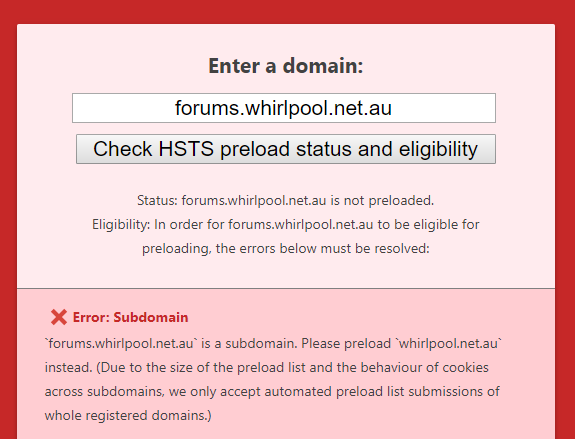
What you end up with on a site like Whirlpool which isn't consistently redirecting insure requests to secure ones is a bit of a hodgepodge of security postures which leads to things like this:
Interestingly, I get this message on Safari 11.1.2: pic.twitter.com/NWlfqQtcXT
— Anthony Eden (@anthony_eden) July 26, 2018
So I'll end this section the way I began it: HTTP 301 is the first step to doing HTTPS right and if a site can't do that on request to the domain then it deserves a place on WhyNoHTTPS.com.
Giving People Actionable Advice
One change we've made to the site since launch is to address precisely the sort of thing we saw in the Whirlpool case above: help fill knowledge gaps by providing actionable resources. As a result, you'll now see this on the site:

If there's other good ones you know that fill in the sorts of knowledge gaps you see people with when going HTTPS, do please let me know in the comments.
Summary
One of the design decisions I made early on was to only show the top 100 sites globally and the top 50 on a country-by-country basis. The reason was simply to avoid getting into all the sorts of nuanced debates that people have already had about a much broader collection of sites. If ever we get a much more reliable means of addressing all the sorts of edge cases I outlined above that might change, but for now keeping it simple is making it easier to manage.
If nothing else, I hope this post illustrates just how much effort has gone into trying to represent fair and accurate accounts of who's doing HTTPS properly and who's not.