I will not run web security analysers without first understanding web security.
I will not run web security analysers without first understanding web security.
I will not run web security analysers without first understanding web security.
Are we clear now? Good, because as neat as tools like I’m about to discuss are, nothing good comes from putting them in the hands of people who can’t properly interpret the results and grasp the concepts of what dynamic analysis scanners can and cannot cover. If you’re looking for a tool to do all the hard work for you without actually understanding what’s going on, this isn’t the post you want to read! (Yes, there are places that sell “security in a box”, no, do not trust them!)
That said, Netsparker is rather awesome at automating the often laborious process which is trawling through a website and looking for risks. I do this all the time and it quickly becomes both repetitive and time consuming. But it also very often bears fruit, in fact this is why I wrote the Pluralsight course titled Hack Yourself First: How to go on the Cyber-Offense. The whole premise of this course is about how to identify insecure patterns in web apps, how to exploit those patterns and then most importantly, how the secure patterns look and how they defend against attacks. If I’m honest, it’s my favourite course to date and I reckon it’s a “must watch” for all web developers, although I will acknowledge some bias :)
Speaking of Hack Yourself First, have you seen this train-wreck of a website?
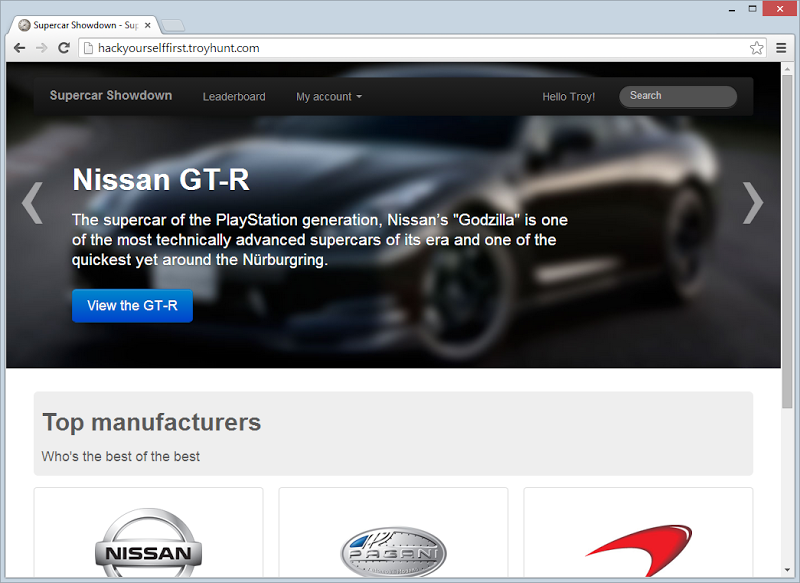
This is the site I built specifically for the course and it’s publicly accessible at hackyourselffirst.troyhunt.com. It also has about 50 serious security vulnerabilities in it. These are the sorts of vulnerabilities I’ve seen over many, many reviews of web security over the years and I’ve built them all into the one mother of an insecure site. It’s the kind of site that Netsparker should have a field day with so let’s see what it finds shall we?
About Netsparker (and how to get it)
First things first: Netsparker has kindly given me a license for their Professional version and that’s enabled me to write this post. I’m often asked about dynamic analysis tools and I wanted to have the material here on my blog to explain what they do and don’t do so that I could have a canonical resource on the topic. That said, I’ve long been an advocate of Netsparker without incentivisation simply because I believe it’s the easiest on-demand, do it yourself dynamic security analysis tool for the audience I speak to. tl;dr – I’m writing this because it’s a great product and I want to.
I’ve used the term “dynamic analysis” a few times now so let me quickly quantify that. When we talk about analysing source code (i.e. you’re inspecting the C# code of a .NET application), that’s static analysis in that you’re inspecting code that’s lying dormant – it’s not actually executing when the analysis is done. When you have access to the source via static analysis, you’ll pick up everything from poor variable naming to unused methods to actual serious security risks like how credentials are stored. In dynamic analysis, the code is actually running when it’s tested and in a case like Netsparker (and many other security tools), you’re remotely testing the code in that you’re hitting a website over HTTP. This has some drawbacks insofar as a bunch of bad internal code practices can’t be identified (not unless they surface themselves via the website), but it also has its strengths, primarily that it’s easy to run dynamic analysis on the spot against any website. It’s also a much more accurate representation of the level of access an attacker has to a website and the underlying webserver infrastructure.
Moving on, you can grab the software from netsparker.com and there’s even a free Community Edition to get you started if you don’t want to pay money right away (there’s also a demo edition they can hook you up with and run against their test site). Naturally you get some limitations with this edition so check out the comparison chart if you want to know what’s in and what’s out. The guys at Netsparker have also offered to support readers here with a fully functional trial of the whole thing so read the very bottom of this post for more info.
Cost wise, “Community” is free, “Standard” is $1.95k/y but is limited to 3 websites and “Professional” is $5.95k/y but you can go nuts on as many sites as you like. Standard and Pro have the same feature set so if you’re primarily interested in a single site or 3, you can get all the bells and whistles for under $2k. All the prices come down a lot if you commit to a few years which is pretty typical for most services these days. I’ll come back to costs a little later because it’s important to understand them in the context of what the product is delivering. For now, let’s get on with actually using the thing.
Running the scan
One of the reasons why I’ve always espoused the virtues of Netsparker is that it’s just so damn easy to get started with. It can be as simple as entering the URL and then just letting the scan run:
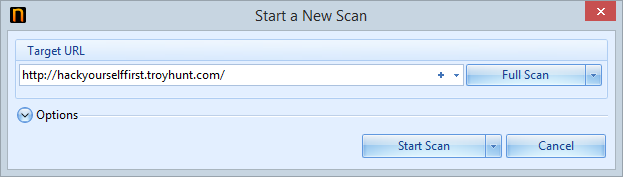
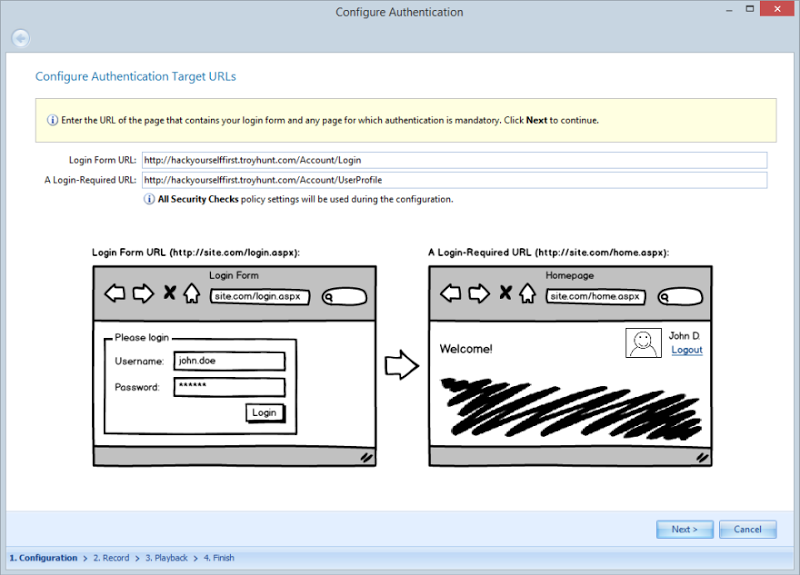
That works just fine for a public website that’s anonymously accessible, but this one provides a facility for users to authenticate and then perform actions under an identity. I want to get a good idea of the security profile of services which require authorisation as well so I’ve hit the little arrow next to “Start Scan” and elected to configure forms auth. What that means is that I now need to define where the login form is and also provide a URL that shouldn’t be accessible via anonymous users:
Once I do that, the login form is rendered in an inbuilt browser window and I can provide credentials that enable me to authenticate:
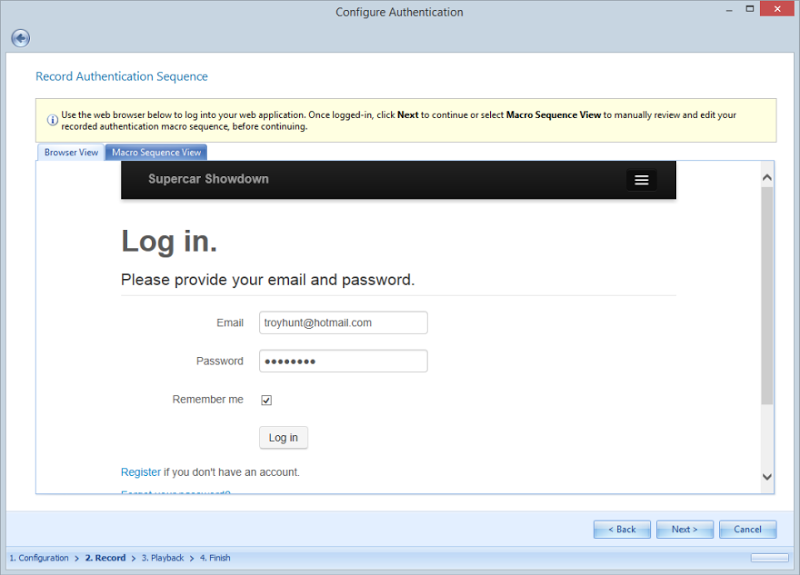
This is Netsparker essentially recording a macro of the process so that it can be repeated again during the scan process. Just to confirm the login process was correctly record and the macro successful, Netsparker now shows a logged in view and a logged out view:
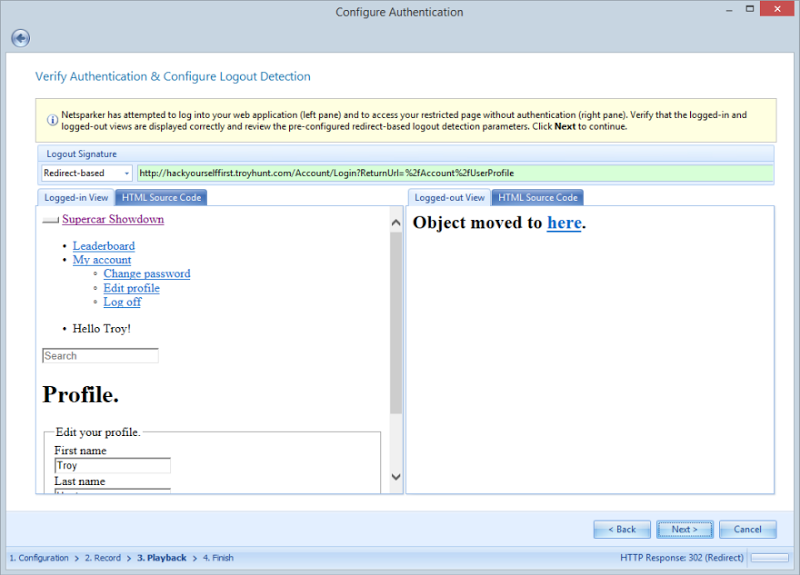
We’re seeing “Object moved” on the logged out view as an attempt to access the profile page whilst not authenticated causes a 302 redirect to the login page.
That’s the end of that, we can now kick the scan off and let it go nuts. But just before we do…
Take a look at just how much stuff is configurable in a scan and the breadth of attack patterns it covers:
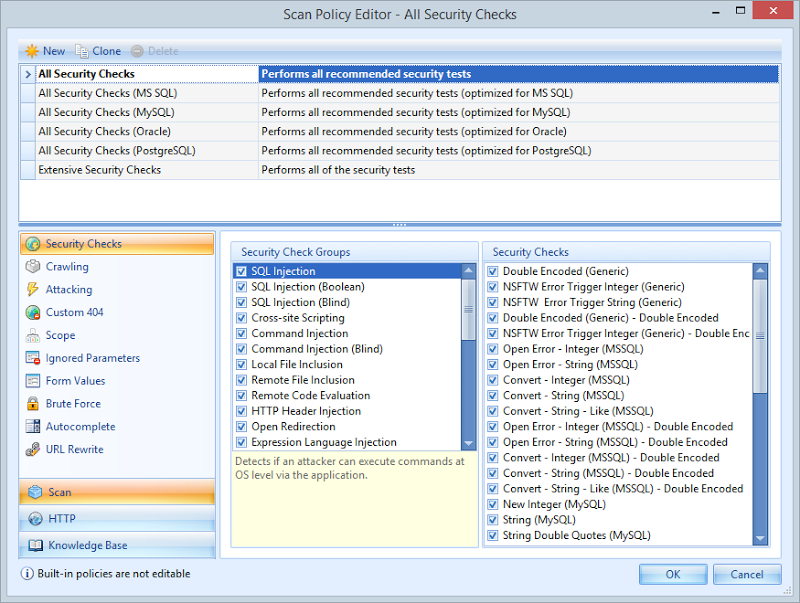
I won’t go through these in detail (grab a demo version for that), but I will point out that you can tailor the security checks based on the database back end which then has an impact on the SQL injection tests. Many of the attack vectors are tailored to the DB back end so there’s no point, for example, throwing specific attacks designed only for Oracle at a system you know to be running SQL Server. That can obviously have an impact on the duration of the test which can become quite lengthy on a large site.
Enough of that, let’s run it!
Website behaviour during and after the scan
Predictably, things are going to go a little nuts during the scan. This site is sitting on Microsoft Azure so I can get some nice monitoring stats directly out of the management portal while the scan runs and as you can see, we’re suddenly getting a lot of IO and a lot of errors:
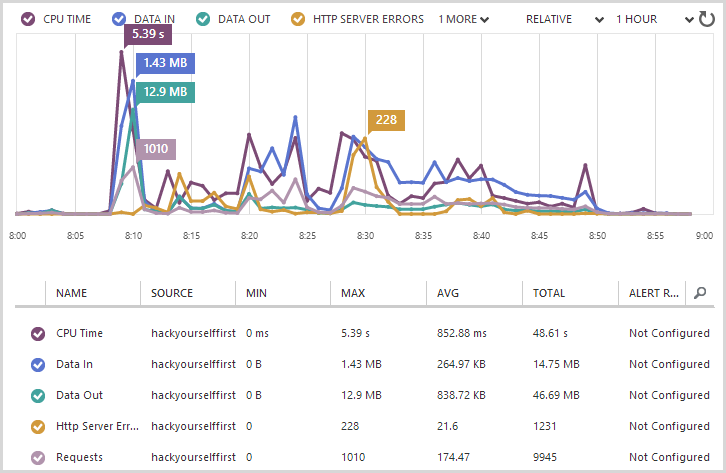
Errors are inevitable as many of the attempted attack vectors will cause internal exceptions. For example, ASP.NET’s request validation will usually fire as soon as a cross site scripting attack is attempted. Likewise, many SQL injection attacks cause errors and indeed error-based SQL injection is one of the most commonly used exploits against websites. The point is that it makes it look like the wheels are coming off the website, the question is whether those errors are giving Netsparker any juicy info or not.
Browsing back over to the site, the first immediately apparent thing is that suddenly there are a heap of votes against some of the cars that weren’t there before (Pagani started with 3, McLaren with 4 and Koenigsegg with 2):
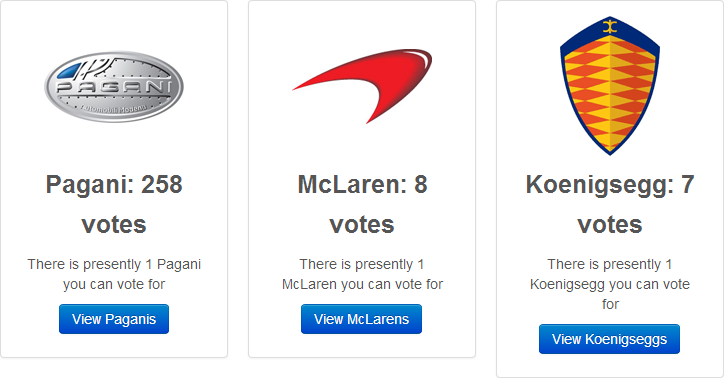
Well I can’t argue with its penchant for the Pagani! I’ve shown this image to reinforce that data may be manipulated as part of this process. It required an HTTP POST request in order to submit all those votes and the tool happily made these. Do consider whether this is something you should really be running in your test environment instead (more on that soon).
Let’s take a look at the Huayra and see what’s happened:
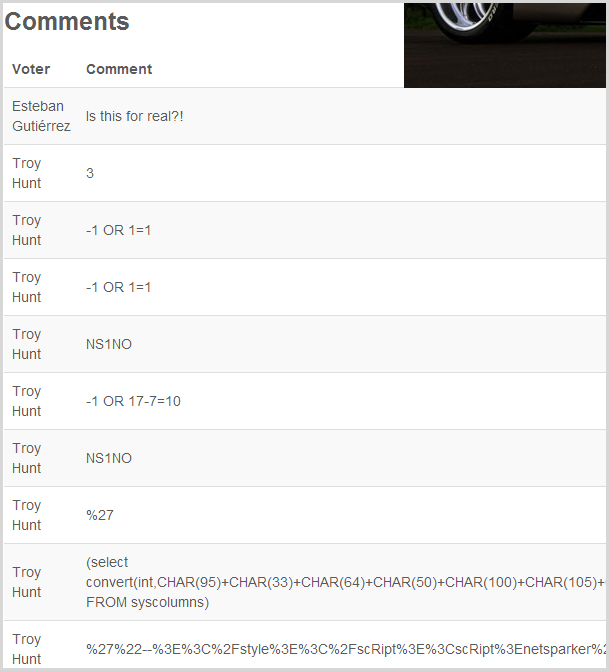
Ok, so here we have a heap of typical SQL injection pattern attacks and the list goes on well beyond what I’ve shown here. (Incidentally, you’re seeing my ID everywhere as it was my credentials I used when I configured Netsparker to logon via forma auth earlier on.) The attack patterns are all the usual SQL injection suspects: simple boolean conditions, attempts to force internal errors, obfuscation via character encoding, timing attacks and so on and so forth. I also found the comments had attempts at exploiting local file inclusion vulnerabilities (trying to pull an internal file outside the intended scope of the web app) so clearly it’s not just SQL injection being tested for via this particular vector.
Of course this raises one very important point: be very careful about using tools like this in a production environment. If you do have a SQL injection vulnerability, you may well find your data either in a terrible state of disrepair or nuked completely. (Incidentally, I’m not saying that Netsparker will consciously issue delete commands or drop tables, but that if you have a serious SQLi risk like this then you’d want to work on the assumption that it will be nuked!) You really want to run this on a test environment first or at the very least, be ready to restore production data if things go wrong. Of course the other way of looking at it is that you should run these tools in production because if you’re going to have a SQL injection vulnerability, it’s better you find it first in an ethical fashion rather than an attacker finding it and pastebining all your datas. Then again, you may also find that even with no SQL injection risk the data is manipulated – what if the app correctly parameterises input and simply passes it through to the underlying query which happens to be an insert or an update? tl;dr – consider the pros and cons, sometimes one makes sense and the other doesn’t.
So that’s the website covered, let’s move onto the results because after all, that’s what we’re really interested in here.
The scan summary
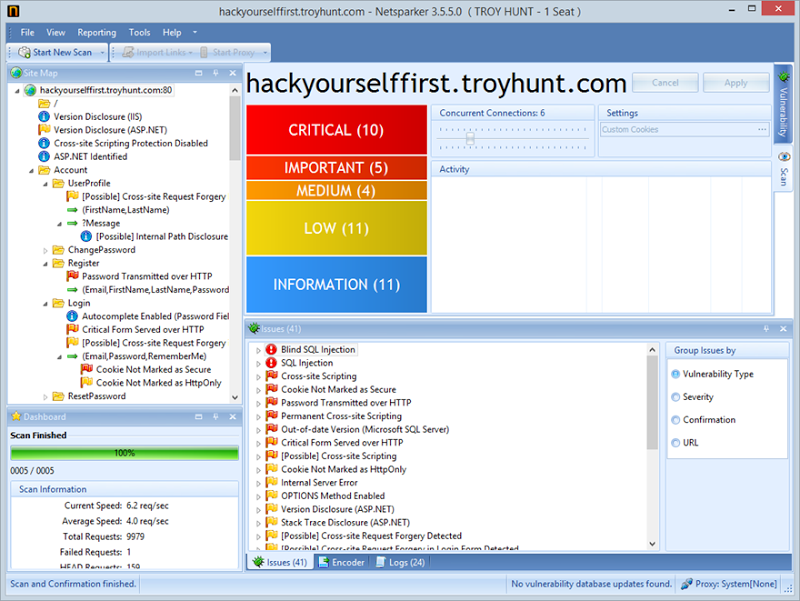
Getting back to Netsparker itself, once the scan wraps up we get a nice GUI with the results. We’ve got a fully mapped out directory tree, stats on the scan (4 requests a second and nearly 10k in total), and then some traffic lights and issues list:
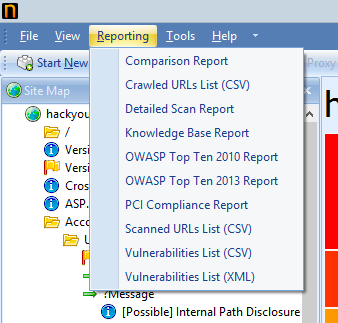
For people that would rather trawl through results themselves, I’ve exported the whole thing in PDF format which you can download for yourself. There are a bunch of different report formats you can pump the data out to depending on how you want to use it:
Moving on, risk classification is pretty common across this class of tool and inevitably your eye is going to go straight to the critical stuff. This particular scan has a good spread of findings across the risk categorisation so it’s a good example to run with. Let’s start delving into them and see how good a job it’s done of picking up vulns.
Critical findings
There were 10 critical findings and they break down like this:
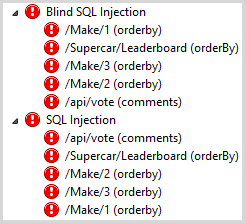
One of the first thing you’ll notice is that there appears to be some redundancy; according to the semantically formed URLs, 3 different “makes” (Nissan, McLaren, Pagani) are at risk of a blind SQL injection attack. Of course without even looking at the code we could safely assume that this is simply a parameterised path and indeed makes 4 and 5 and 6 and so on are all at risk of the same vulnerability. You can see the same pattern under the SQL Injection node beneath that and whilst as a human it’s quite easy to determine that this is the one risk on multiple paths, it’s harder for an automated script to make that determination, particularly when the path may not be as obvious as an auto-incrementing integer.
And therein lies one of the first important lessons about these tools and why I had the very repetitive opening paragraph; the ease with which this report was generated was awesome, but without being able to properly interpret the results you’re ask risk of drawing false conclusions. Of course it’s more than just that too in that ultimately you want to ensure whoever it is that has a report like this land in their inbox with a “pleez fix” message needs to understand the risk and what to do next. Indeed this is exactly why I created the OWASP Top 10 for .NET developers series, because I was seeing devs get these reports and have absolutely no idea what to do with them! More on that later though, let’s get back to those critical findings.
What I really like about Netsparker is that when we drill into a finding like that first blind injection one, there’s a great explanation that’s very easily legible:
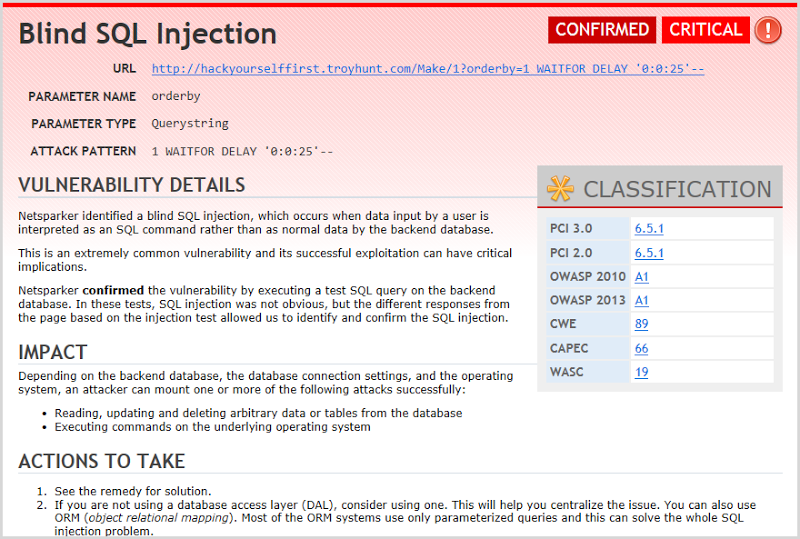
What this is saying is that by injecting a “WAITFOR DELAY” SQL statement into the path, Netsparker was able to cause the database to execute this arbitrary piece of syntax thus validating that the app is at risk of a time-based injection attack. If why this matters is a foreign concept, check out my post on Everything you wanted to know about SQL injection (but were afraid to ask). Netsparker is entirely correct – there is a blind injection attack risk – but it’s also the same resource with the same vulnerability that then appears further down the tree under the “SQL Injection” node. In short, out of those 10 critical risks, 6 of them are the one resource requiring the one piece of work. Again, understanding how to interpret these reports is key.
Moving on though, there’s heaps of info on what the vuln is, the impact, what to do next then a whole bunch of stuff that scrolls off the screen including some very handy links to things like the OWASP SQL Injection page. Speaking of OWASP, it also features in the classification table at mid-right so you can drill down exactly into how the OWASP Top 10 views this risk. If you’re setting the Top 10 as a set of security requirements for your apps (and you should be), this is a good correlation.
I won’t dwell much more on the injection risks other than to point out the one for the /api/vote path:
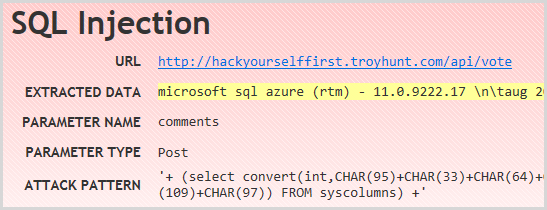
The reason this is significant is that Netsparker has actually found what is a client side async JavaScript call using jQuery. It’s also a POST request and indeed this is the resource that populated the DB with all those votes we saw in the earlier screen grab. It’s important as it demonstrates that the tool is doing much more than just crawling links, indeed it’s determining how the app would behave in the browser and learning of potential attack vectors it should probe. In an increasingly async world, that’s pretty essential.
Important findings
Onto the next tier of criticality and here’s what we’re seeing:
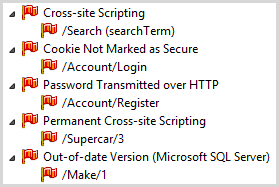
Most of these are discrete and we’re actually seeing different vulnerabilities here without any doubling up. Let’s touch on each:
Firstly, yes, there’s a reflected XSS risk on the search page and Netsparker kindly provides this link to test it: http://hackyourselffirst.troyhunt.com/Search?searchTerm=%27%2Balert(9)%2B%27 – that’s your classic alert box XSS proof right there.
Next up is the insecure cookie and yes, I did (deliberately!) neglect to flag the cookie called “AuthCookie” as secure so yes, it would be sent over an unencrypted connection which would be bad if you were worried about a man in the middle attack (and you should be when it’s an auth cookie, refer to Firesheep if you’re not sure why that’s important). But of course there are times where you might legitimately want a cookie to not be flagged as secure (i.e. simply persisting someone’s name over both secure and insecure schemes) so you want to watch out for false positives on that one. Let’s be clear too – that’s not a criticism of Netsparker – that finding could be either wrong or right depending on how the site has been implemented.
Passwords being submitted over HTTP on registration is both self-explanatory and nasty. It’s also very easy to observe yourself so yes, it’s nice to get the report stating it but you can also just “eyeball” this one.
The permanent XSS finding (also often referred to as “persistent” XSS) is a pretty nifty one because it requires a bit more orchestration. When XSS is persisted, it’s actually in the data layer so for example, it’s saved when a form is submitted and then unlike reflected XSS which relies on someone clicking a malicious URL with the XSS payload, the persisted XSS is shown to everyone. It’s nifty because it requires the scanning tool to identify an entry point to save the data then an exit point where it’s rendered back to the screen. The former depends on missing validation at input and the latter depends on missing encoding on output. You can see both the URL with the XSS and the infection URL on the summary screen:
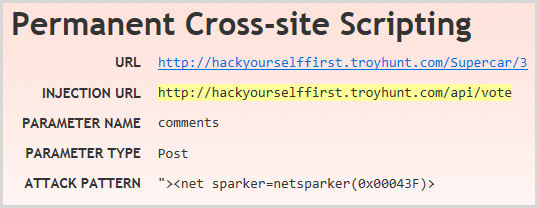
The final important finding is an interesting one because depending on how you look at it, it could be viewed as a false positive:
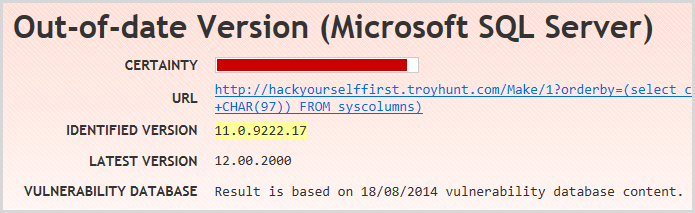
Yes, the current version of SQL Server is 12 (also known as SQL Server 2014) and yes, version 11 (AKA SQL Server 2012) has been superseded, but this is all running on SQL Azure which is a PaaS offering. Not only is it not full blown SQL Server as we know it (there are numerous small differences), you also have no control over the version as it’s simply “SQL as a service”. (Incidentally, I’ve provided the Netsparker guys with this feedback and they’ve taken it on board.) You could also argue that your DB being one gen behind current version is a whole different risk to, say, persistent XSS, but we could also be here all day disagreeing with people about the relative risks of various security findings!
Medium Findings
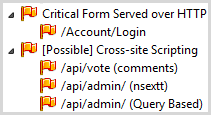
This one is a little interesting in terms of the second set of findings:
But we’ll start with the first and it’s spot on – the login form is loaded over HTTP. Netsparker very adeptly identifies and summarises exactly what I’ve been ranting on about for years:
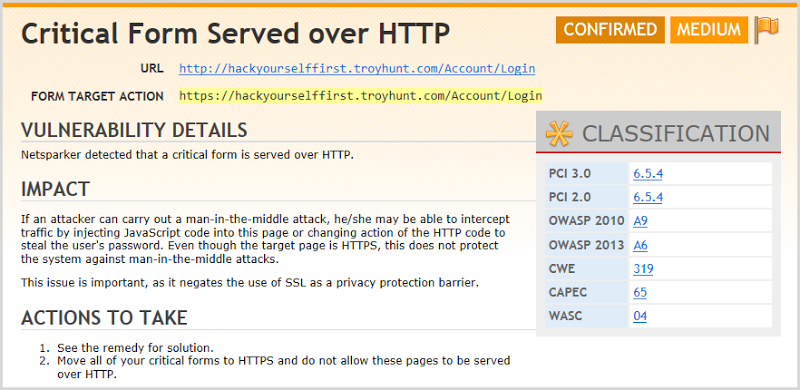
Note the key observation here (and indeed the source of much of my ire): the login form posts to an HTTPS address thus encrypts the credentials under normal operating conditions, but because it loads the form over an insecure connection you can have no confidence that your data is actually going to be sent to the right location!
It’s the “possible” cross-site scripting findings that are the interesting ones. None of these pose an exploitable risk, the first because there is no possibility of reflecting the input in the response (although this resource was the vector for the persistent XSS identified earlier) and the next two because no resource actually exists that would accept that attack pattern (it’s attempting to hit /api/admin/?nsextt=). The latter is a little more interesting in that the error message does reflect the input parameter, but it’s correctly encoded for the JSON response in which it’s returned. There shouldn’t be an attack vector on any of these, but of course that’s why’re they’ve flagged as “possible”.
And this is a key point to make about all tools of this nature – they cannot replace the humans nor can they reliably and consistently get it right without producing any false positives whatsoever. You have to know the system, know the risk and know the attack pattern in order to draw a conclusion on these. Again, per the opening para, you’ve gotta have a grip on your app sec to begin with before playing with these tools.
Last thing – how did Netsparker find the “/api/admin” path?! It’s not linked in from any public pages, so what gives? Ah, but it is referenced from the robots.txt file and as I explain in the course, listing paths in this resource can sometimes have an entirely opposite effect to desired when the resource is not properly secured. Yes, it’s still ignored by search engines (if they follow the rules), but it’s also an awesome little roadmap to the site for attackers. I’m happy to see this one picked up.
Low findings
I’m not going to go through all these in detail, but I will give you a quick snapshot:
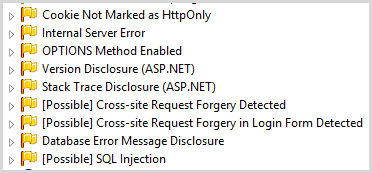
There’s some good stuff in here and it aligns with many of the risks I’ve deliberately introduced into the app. Things like the auth cookie not being HttpOnly is a good one, although I’m not convinced that’s a low risk whilst a missing secure cookie flag is classified as “important”. Stack trace is another and of course this is a very specific ASP.NET pattern too so good seeing how Netsparker identifies discrete behaviour in popular frameworks. Version disclosure is via noisy response headers and the DB message disclosure is, of course, the very same vector that was used for the error-based SQL injection attack so possibly a bit of doubling up there.
Information findings
This is a bit of a mixed bag of stuff you may be very indifferent about (email address disclosure, say on a “contact us” page) and stuff you really should be paying attention to (cross-site scripting protection disabled by way of the X-XSS-Protection response header):
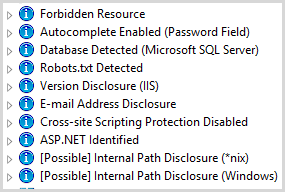
As you’d expect from findings with this sort of classification, it’s the sort of stuff you really need to independently assess and draw your own conclusions from. That’s not to say it isn’t useful, in fact I think it’s very useful for automating checks of basic stuff that would otherwise be easy yet repetitive and can be automated away, such as checking for autocomplete on a login form or checking you’re disclosing framework versions. Simple stuff, but I’d rather the computers do the hard work!
Knowledge base
One of features that’s quite neat is the Knowledge Base which reports on a bunch of things that could just be informational, or could be used to then exploit the system:
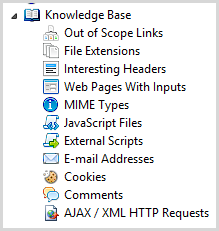
Some of this was actually extremely useful, for example it found the hidden comment about the database backup in the /secret/admin path (don’t laugh, I’ve seen this done):

That path was also pulled from the robots.txt so good use of that guy again.
It also found a cookie called “Password”:
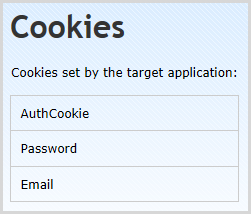
Yes, that’s something that should never go in a cookie and yes, people actually do this. Now of course Netsparker doesn’t know that this cookie contains sensitive data that should never be in a cookie to begin with and it would have to make some fairly big assumptions in order to draw that conclusion. The point is that this is actually a really serious risk and by virtue of surfacing the information in a fashion that it can be reviewed, it’s more likely to be picked up by someone running through the report.
Business logic flaws (and how we’re all smarter than machines)
One of the really serious vulns in this app is that you can vote as anyone else by virtue of manipulating the user ID that’s sent to the voting API and simply substituting it with another integer. Netsparker didn’t find this and it would be a hard ask for it to – it would have to understand the semantic intent of the “userId” parameter and that it could be changed to another value in such a way that it circumvented a security control. In fact the closest it got to this is listing the parameter in the Knowledge Base under “AJAX / XML HTTP Requests”:
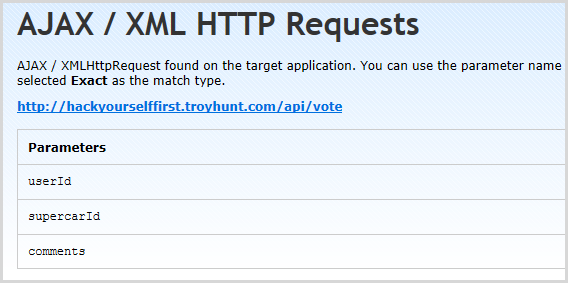
This is actually useful – if I saw this when testing an app the first thing I’d do is go and recreate the request with a different user ID. Of course I could also easily discover this myself by testing the vote feature anyway but again, having it surfaced this way is more likely to bring it to your attention.
Netsparker also wasn’t able to identify that the business logic which disables the vote button on a car you’ve already voted for can be circumvented by directly calling that same API from above and simply sending the supercar ID for a vehicle you’ve already voted on – there’s no server side control to restrict multiple votes for the same car. Same deal again though in that whilst it’s a very serious security flaw, it takes human smarts to pick it up.
There’s a poignant point to be made here about manual attack and penetration tests. Sitting a human down who gains an innate understanding of the business rules and then sets out to break them simply can’t be replicated by machines. I poked fun at “security in a box” earlier on and it’s for reasons like this that many people scorn automated tools. Some of them (like Netsparker) are very good, but don’t assume for one moment that it’s going to find every possible risk in your app because it simply won’t happen. Password storage is another good example – dynamic analysis won’t glean that they’re sitting there in plain text, in fact even manual penetration tests won’t necessarily discover that (not unless the system is emailing them to you, for example when your forget it), and in a case like that you’re back to static analysis of the code itself. Add trained humans with access to code and now you’re getting somewhere!
What did Netsparker miss?
And now for the one that many of you have inevitably been waiting for – what didn’t Netsparker find that it should (or could) have? Last year I invited people to hack me first (there was incentive by way of free Pluralsight passes) and detail what they found in the comments on that blog post. There were hundreds of comments and heaps of vulns found so that’s a good reference point. Let’s go through some of them and I’ll self-classify the risks into high, medium and low. I won’t include vulns that definitely require business logic knowledge as you could never expect those to be found in the first place. Also keep in mind that many of these require a number of things to fall into place or certain knowledge to be had that could be very difficult to automate, but it’s important to understand what aspects of security are not covered above and beyond just those business logic observations.
High:
- The password is sent via email on signup and when using the forgotten password feature. This would be hard to test without registering with a valid email, monitoring the mailbox then inspecting the email contents after signup and reset.
- When changing password, the new and confirm fields are pre-populated with the existing password. A pre-populated password field could be detected programmatically.
- Passwords are not stored as cryptographically strong hashes. This can be derived from either of the two previous points and IMHO, is a pretty major observation.
- There’s no re-authentication required by way of providing the existing password before it’s changed. It might not be an exact science to programmatically identify this, but it could be captured as a “possible” risk.
- The remember me feature sets a Base64 encoded password in a cookie. Identifying the presence of a remember me feature would usually be possible by looking for a checkbox at login and comparing the differences in response from normal login versus remembered login would be telling, at least to the point of flagging it as a “possible” finding.
- There’s a mass assignment risk on the “edit profile” page which allows you to send an “IsAdmin” parameter in the POST request and elevate privileges. You could view this as the sort of risk that is more business logic or at the very least, difficult to identify via automation. Then again, the presence of the field is discoverable via other risks (such as the SQL injection one), but I’m drawing a bit of a long bow by saying the relevance could be implied by any sort of automated fashion.
- The registration has client side validation on attributes such as password strength but no server side validation. It’s a little tricky to automatically identify as you need to be able to parse out the client script and establish the rules, but if this was possible you could then automate the tests against whether their server side counterparts existed or not.
- There’s no brute force protection on the login page. This one should be easily identified by firing login requests at the page and seeing if the response changes. Of course it could also result in account lockout as well but that might just be a test that gets held back to the end of the scan.
Medium:
- The password field has a very “low bar” for both min and max strength (accepts a single char password and maxes out at 10 chars plus won’t allow “special” chars). IMHO this could easily be an automated test, at least the max length attribute on the password field could be.
- The account is locked out as soon as the password reset process is initialised (a new one is sent via email). Once again, this could be tested automatically as a final step in the scan as once done, the account is no longer accessible unless the email is retrieved and actioned.
Low:
- There’s an account enumeration risk on the reset feature (it tells you whether the email exists or not). There’d be a bit of fuzzy logic required to interpret the response from the system, but a different response from a known existing account versus a known non-existing account would be a good sign that something is up. But then of course in a case like this, the reset feature might actually lock the account out so that’s another problem to deal with.
- There’s no XFO header to prevent clickjacking attacks. This would be dead easy to detect as it’s in the response header of each request. It might only be a low finding (although I’ve certainly seen security teams use it as a show-stopper), but it’s useful info that can be reliably detected.
I shared these findings with the Netsparker guys before publishing this post (it’s the only thing in this post I shared with them for comment before publishing) and they’ve taken it all on board. Some of them are on the cards already and will appear in future releases, others may not due to the reasons I listed above, namely increased likelihood or false positives or bespoke business logic that’s difficult to automate.
Transient data states and inconsistent results
Here’s the thing about websites – they change. Your data state is in one position today which makes certain features visible or invisible then in another state tomorrow and the feature availability changes. For example, in my demo site, if you vote on a vehicle you can no longer vote on that same vehicle again (well actually you can as there’s a logic vuln, but the “vote” button disappears). If Netsparker is running under an identity that’s voted on every vehicle, it won’t see the option to vote and consequently would never get the opportunity to discover the SQL injection flaw in the vote API.
The point is that you need to consider what your data state is in before running a scan. As I’ve said multiple times throughout this post, you really want to think about what the right environment to run this scan is in the first place (remember, it may change your data) and ideally you’d have the ability to restore a test environment to a known data state so that at least the results were consistent over time. Ultimately though, this is one of those “it depends” things – you know the pros and cons by now.
The Netsparker value proposition
I’ll spare you the “because getting pwned is expensive” spiel because that understanding is a given. Ok, maybe it’s not as widely understood as it should be, but if you’re a regular reader here you’ll have a bit of a sense of that. Instead, let’s focus on the value proposition of Netsparker in an environment that’s already got an awareness of the value of app sec.
The main thing is automation of otherwise laborious tasks; nothing that Netsparker does can’t be done be humans. The problem with humans is that they’re very expensive for what they do. Checking cookie attributes and output encoding and error configuration is all easy and it all takes me a bunch of time to get done. But it’s a repeatable, automatable process and for the same reason I created ASafaWeb to check basic security config settings, Netsparker makes a lot of sense for checking a much, much broader gamut of web security risks.
The other area where it really makes sense is that you can easily put it in the hands of developers who may not be hard core security pros. There are plenty of tools for the latter, but they often don’t speak the language of the former. I’ve seen more confused to-ing and fro-ing between these groups than I’ve had hot dinners and that’s a cost that’s rarely captured in the TCO of building software.
Because you can put this in the hands of devs, you can also bring those security checks way forward in the lifecycle of the project and start running security assessments very early on. In fact a few years back I wrote about Continuous web application security scanning with Netsparker and TeamCity and that’s still a very good idea. We’ve all seen the graphs that show the cost of fixing broken stuff (bugs, optimisations, vulns) exponentially escalating over time, right? Get on top of the sort of things found in the report above early and the amount of effort it saves later on can translate into considerable dollars.
Of course how much it’s worth is a very case by case question. On the one hand, yeah, it kicks off at around a couple of grand a year and that sounds like a bit but on the other hand, that’s only about what I spend on coffee. Ok, maybe I’m drinking too much coffee (although that’s only $5 and something a day), but the real value proposition is in what I don’t have to do as a result. For many people, it will also mean the increased confidence they’ll have in their security posture as well and that’s something that’s hard to put a value on.
Summary
First up, there’s a heap of other bits and pieces Netsparker does that I didn’t touch on, particularly when it comes to configuration before the scan. There are also other findings I didn’t drill down into so go and grab the report I exported if you’d like to trawl through those yourself.
Next, I hope this makes it clear where the value proposition of automated scanning tools of all flavours is. They’re great for picking up the stuff that matches known bad patterns and they play a valuable role in doing that, but they don’t replace the humans who can mount attacks against the app logic – those guys are still critical.
Finally, I’ll finish where I began: you’ve got to have trained developers who know their app sec. At the end of the day, someone needs to take these findings and actually plug the holes and you don’t do that just by making the report look good, you do it by understanding the underlying risk, how it’s exploited, the mitigation patterns in your framework of choice and then actually writing secure code you understand! If this isn’t ingrained in developers yet, check out my Pluralsight security courses (and ping me if you’d like a free pass). Netsparker is simply a great companion on that journey.
Oh – one last thing – if you want an unrestricted trial of Netsparker to run against your own domains, hit them on contact@netsparker.com and tell them you read about it here. Happy scanning!