Let me pose a question: What’s the difference between these two URLs:
- http://[mydomain]/?foo=<script>
- http://[mydomain]/?foo=<script>
Nothing, right? Let’s plug that into two different browsers and see what they think:

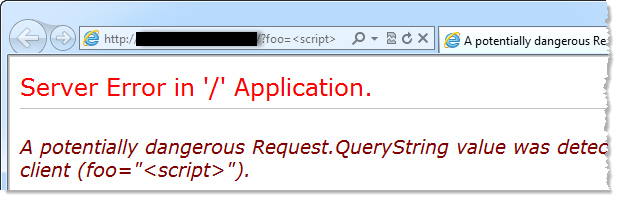
Ok, now it’s just getting weird and this brings me to the topic of the day: Recently a friendly supporter of ASafaWeb contacted me and said “Hey, how come ASafaWeb isn’t correctly identifying that my site is throwing custom errors?” Naturally the first thing I did was to run a scan on the site using my favourite Google-sourced browser:

I then double checked it manually in the browser and proceeded to tell the aforementioned friendly supporter that he was wrong. As is probably now evident by the browser screen grabs above, this was a bad move.
Let’s dig a little deeper into the HTTP requests both those browsers above are generating and see what Fiddler has to say. My expectation was that the user agent header was causing the different behaviour but it turns out this wasn’t the case:

See that? Chrome escapes illegal URL characters whereas IE happily passes them through to the server unmolested. This is Chrome 17 and IE9 – it’s entirely possible that other versions exhibit different behaviours.
So the first half of this story is interesting in so far as different browsers can make different requests with exactly the same URL in the address bar. The second half of the story is that request validation may or may not fire when the query string is encoded. For example, here’s another site loaded up in Chrome:
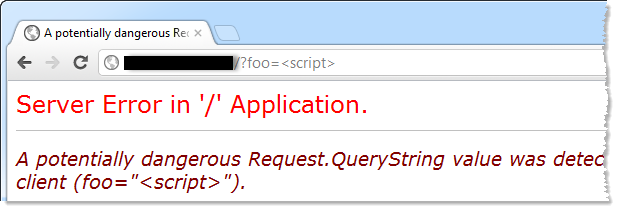
In this case, request validation is firing against the encoded <script> tag and returning an HTTP 500. If we look back a little earlier to that Fiddler trace, the site in question was returning 404 – it literally treated the encoded tag as a path for which it couldn’t find any content. Why does this happen? Damn good question, I’d love to know the answer! My best guess is that this isn’t an ASP.NET behaviour and instead there’s a web application firewall (WAF) sitting in front of the server and sending the request off as a 404. Why it would do this with encoded by not unencoded values is beyond me.
In terms of ASafaWeb, I make extensive use of the Uri class which by default, encodes any illegal characters in the address. As we now know, for some unknown reason this may not cause request validation to fire which in turn may not invoke custom errors which in turn may not illustrate that they have been incorrectly configured. As a result, the URI needs to be constructed without escaping which means using the Uri(String, Boolean) constructor where the boolean is a “dontEscape” parameter:
var uri = new Uri("http://[mydomain]/?foo=<script>", true);
Unfortunately, this constructor is also obsolete. Equally unfortunately, there doesn’t seem to be a nice alternative short of not using the Uri class and then manually handling URLs as strings which means all sorts of other pain. So I’ve used it anyway and ASafaWeb now correctly reports the status of the site in question as follows:

Very odd and ultimately a bit hacky but chalk that up as one more edge-case that ASafaWeb can now successfully handle.