Actually, it’s even worse than that – it’s really 67.37% – but let’s not split hairs over that right now. The point is that it’s an alarmingly high number for what amounts to very simple configuration vulnerabilities. The numbers come courtesy of ASafaWeb, the Automated Security Analyser for ASP.NET Websites which is a free online scanner at asafaweb.com.
When I built ASafaWeb, I designed it from the ground up to anonymously log scan results. The anonymity means I don’t know which sites are being scanned or who is doing the scanning, but I do know the result of each scan which allows me to aggregate these into some meaningful data.
Let me walk you through these results and offer a bit of insight as to where things are going wrong when ASP.NET web sites are published. Hopefully this will be a bit of a “call to action” which helps developers understand where they might need to do a bit of tweaking in their apps.
Analysis
First things first; the analysis excludes the following:
- Scans on the ASafaWeb test site.
- Scans for sites not identified as an ASP.NET website (this is identified by the response headers, any error pages disclosing the framework or the presence of View State on the site). Of course it’s possible – indeed it’s desirable – that the headers don’t expose this information, but it’s also extremely rare.
- Scans run before Jan 1 this year or from April 1 onwards (call it a clean quarter). All results are from Jan / Feb / March.
What I really want to do is give a picture of how your average ASP.NET website is configured so this filter criterion is really important. Take these out and we now have a sample size of 7,184 scans to analyse.
One thing to keep in mind is that ASafaWeb scans aren’t fool proof; false positives happen. Not very much, mind you, but it’s a factor. Another factor is that the scans have been getting better as various edge cases or general opportunities for improvement are identified. For example, last week I added support for error messages in other languages. Before that – and included in the sample the stats in this post came from – a classic yellow screen of death in German wouldn’t have been classed as an error.
Likewise, just this weekend I added a bit more intelligence around the way scans occur against URLs with a path beneath them. The problem is that when you see a URL like http://mysite.com/foo, you don’t know if foo is the root of the app or if you have to go all the way back to just the domain. If it is the app root, this is the path where resources such as tracing and ELMAH will be found but if it’s not, you have go up a level. And you have to do this without making excessive (and very expensive) HTTP requests. Tricky.
So the point is that these numbers are on the conservative side.
Custom errors and stack traces
When we talk about custom errors in a security sense, there are really two separate issues we’re talking about:
- Does the customErrors node of the web.config have the mode attribute set to either “On” or “RemoteOnly”. If it doesn’t, we’ll get a yellow screen of death with full stack trace.
- Does the customErrors node of the web.config have the defaultRedirect attribute set to a valid page.
In other words, is the Yellow Screen of Death (YSOD) making an appearance. As a refresher for those familiar with ASP.NET and a brief intro for those who aren’t, here’s what an error page looks like when both of the above items are misconfigured:
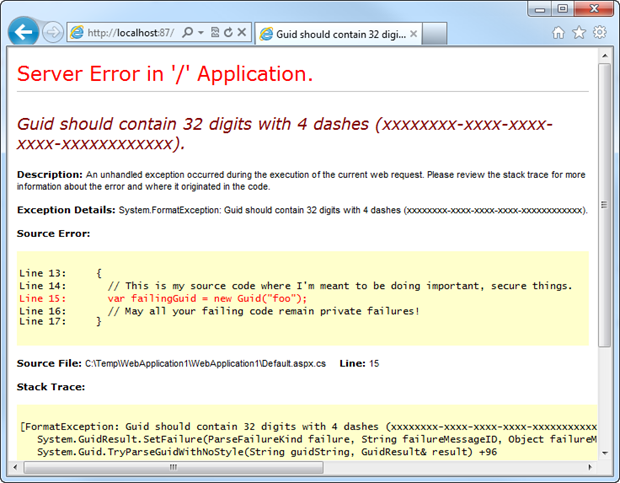
Now the big issue with the error message above is that we’re leaking internal code to the outside world. This gives an attacker an enormous advantage as they can begin to probe the application and discover how the thing is put together which in turn better equips them to identify vulnerabilities. Particularly in apps where error handling is poor (such as casting untrusted data to a particular type without a “try-parse” style approach), this is a serious risk.
But scroll down a bit further and there’s also this:
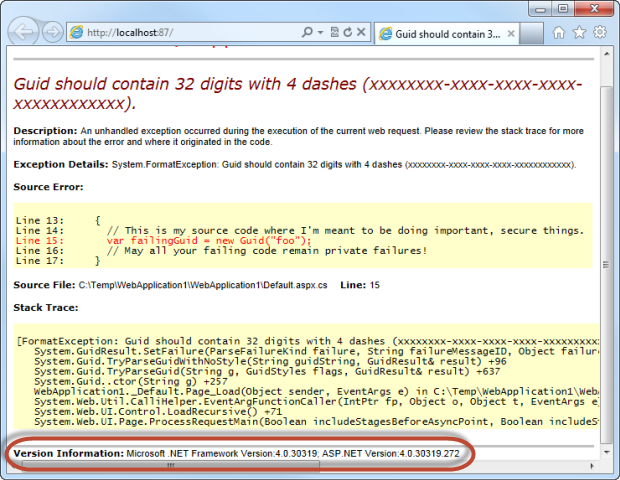
Now this goes back to a recent post titled Shhh… don’t let your response headers talk too loudly. In this post I talked about the risk if information disclosure of things like IIS, ASP.NET and MVC versions via the headers. No matter how silently you configure your headers, if your custom error aren’t configured you’re going to be leaking out the version information anyway.
In this scenario, the web.config is effectively declaring custom errors like this:
<customErrors mode="Off" />
By turning custom errors off, the internal error bubbles up to the browser and the site is figuratively caught with its pants down around its ankles. Turning custom errors on improves things, but not by a lot:
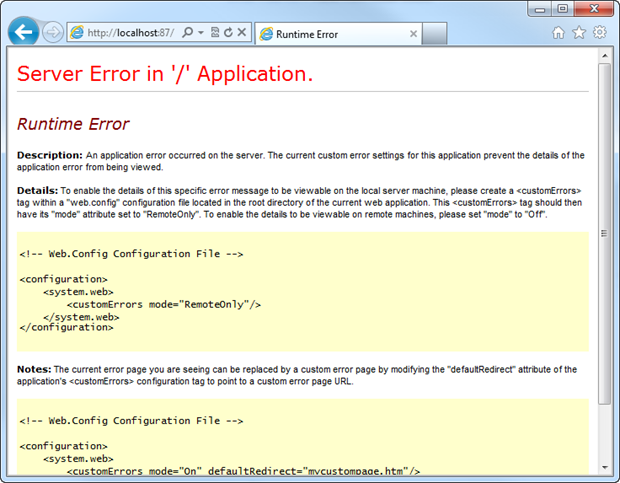
Ok, so the stack trace and internal implementation of the code is gone, but we’re still disclosing that the app can’t handle the request; it’s literally an unhandled exception and that alone is enough knowledge to start probing further.
Here’s what we really want to see:
<customErrors mode="On" defaultRedirect="~/Error.aspx" />
When a default redirect is defined, we end up with something more like this:
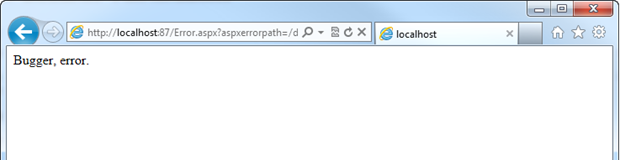
Now of course you’d normally base this on your site’s template and be a bit friendlier about it – like I’ve done with ASafaWeb – but you get the idea. By defining the page we’d like the app to serve when things go wrong, we avoid disclosing the fact that the error is unhandled. We can configure custom errors to serve up different error pages based on different HTTP status codes (you might want to handle a 404 “Page not found” differently, for example), but so long as that YSOD isn’t making an appearance, that’s what we’re on about here.
There are other scenarios where having custom errors on without a default redirect causes dramas. For example, a couple of years back we had the whole padding oracle issue which lead to Scott Guthrie giving very explicit guidance:
It is not enough to simply turn on CustomErrors or have it set to RemoteOnly.
Whilst that episode is now well and truly behind us, it serves as a little reminder that you need to keep your apps locked down as well as possible not just to protect against the vulnerabilities we know about today, but the ones that are yet to make an appearance. I’ve also seen many reports from penetration testers and serious enterprise grade dynamic security analysis tools that call this out, insisting that YSODs not make an appearance regardless of whether they’re accompanied by a stack trace or not.
One final thing: the UX of a YSOD sucks! Give a nice friendly error page and keep your users happier than what they would otherwise be when something goes wrong.
That lengthy intro was to set context because improperly configured custom errors is where the lion’s share of problems lie. Let’s take a look:
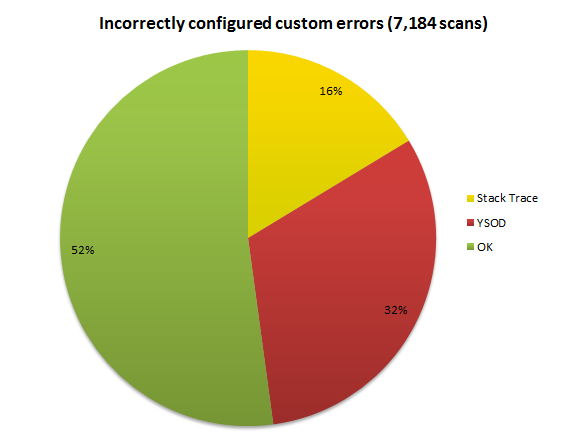
Relating this back to the preamble about how custom errors works, 16% of sites have them turned off altogether while another 32% have them turned on but don’t have a default redirect page defined. This is huge – we’re talking nearly half of all ASP.NET websites that have such a fundamentally basic configuration wrong.
Request validation
Next up is request validation or as I like to refer to it, .NET’s little XSS safety net. Request validation as it stands today (and it changes a bit tomorrow), means that a request with a potentially malicious payload such as you’d find in a reflective XSS attack will (usually) be prohibited from executing. For example:
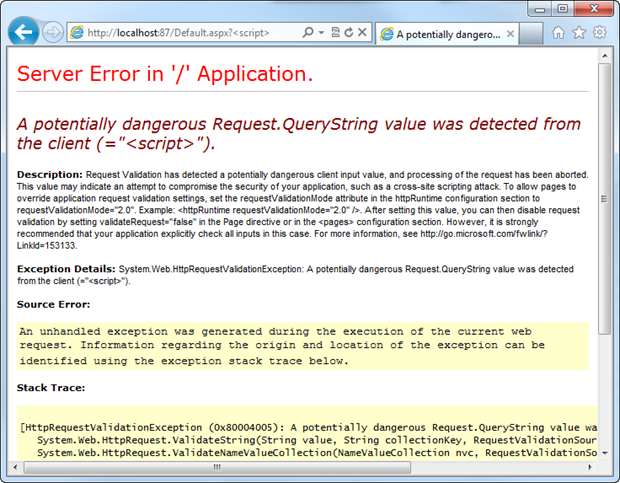
Note the query string in the URL – ASP.NET has trapped this early and decided it’s bad news hence the error page (although of course this would normally be redirect to a friendly error page). The great thing about request validation is that even if you know absolutely nothing about XSS (which is an alarmingly common scenario), there is some level of defence offered by the framework.
Before anyone gets too uppity about the merits of request validation, it is not a substitute for the sort of practices I talk about in part 2 of my OWASP series for .NET devs, namely whitelist validation and correct output encoding. What it does is exactly what I alluded to earlier; gives you a safety net if other good practices are skipped.
Request validation is on by default and you have to explicitly turn it off in the web.config to disable it:
<pages validateRequest="false" />
Or disable it at the page level:
<%@ Page Language="C#" ValidateRequest="false" %>
Why would you do this? One of the most common use cases for doing so is to allow HTML markup to be posted to the server, for example when using a rich text editor. Of course this is a perfectly valid use case, but with it comes risks…
Which brings us neatly to DotNetNuke. You see DNN turns it off across the entire site because every single page is a little mini content management system. I get that – there’s an understandable use-case for it – but it also means they get their proverbial asses handed to them by simple XSS vulnerabilities which would otherwise be caught by request validation.
So what’s the answer to a problem like DNN’s? Use ASP.NET 4.5. Hang on – what?! We’re about to get some very important improvements around support for unvalidated requests which means a product like DNN will be able to leave request validation turned on but access specific request data with an “Unvalidated” call which won’t invoke request validation. This means they can leave it turned on and get that implicit protection through features like search but not have it get in the way of their CMS.
But there are many, many occurrences of developers just stuffing up. They turn it off across the site because one little admin feature is being obstructed or they blindly repeat forum guidance without understanding the impact. This is why the results look like this:
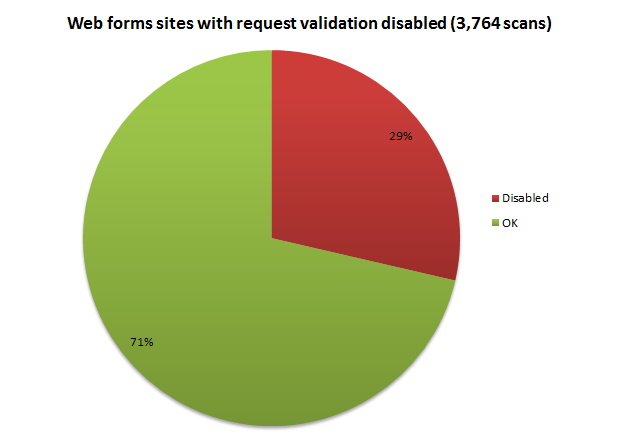
The first thing you might notice here is that the sample size is smaller – almost half. This is partly explained in the title and because of the way web forms sites handle request validation, it’s easy just to append a malicious payload to the query string as I did in the browser image earlier on. This gets processed and request validation (hopefully) fires. Not so with MVC (or obviously a straight HTML website) so unless there’s View State in the site’s source, this test isn’t run.
Hash DoS
Who remembers hash DoS? Only a little over three months ago, this was the exploit shown by researchers over in Germany which meant a well-crafted HTTP POST request with a large collection of carefully constructed form variables could cause some pretty serious hash collisions. The problem with hash collisions is that they’re computationally expensive and if you can cause enough of them, the server starts having trouble doing the stuff it’s actually meant to do. The bottom line was that as little as a single carefully crafted HTTP request could shut things down. Ouch!
Microsoft reacted quickly and released and released MS11-100, a critical out-of-band patch. Now that “out-of-band” bit is important; normally Microsoft releases a bunch of patches on the second Tuesday of each month which has become known as Patch Tuesday. IT organisations expect this and organise themselves around handling these releases. For Microsoft to release a patch out-of-band means they take it very, very seriously, so much so that they can’t possible wait until the next Patch Tuesday.
This makes the following graph a bit extraordinary:
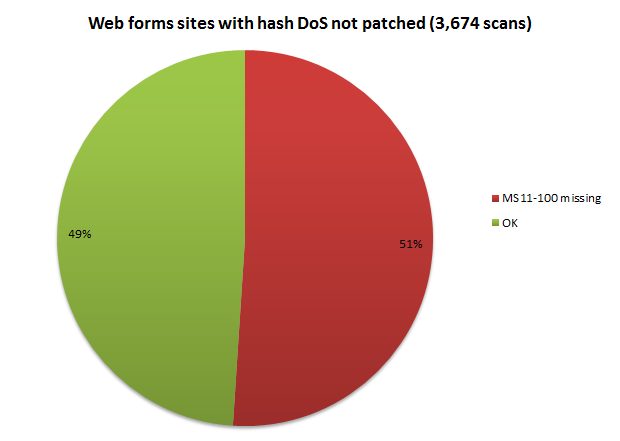
There are some caveats with this result as it’s a bit tricky to test: Firstly, the scan works by posting 1,001 form variables to the site, one more than what the threshold is before the patch kicks in and causes an error which is what we’re looking for to ascertain it’s been installed. Secondly, the Request.Form object needs to be accessed in order for this event to occur. This will happen implicitly in a web forms app, but in an MVC app, it’s dependent on the implementation of the site.
In short, the MVC scans mean lots of warnings where ASafaWeb essentially apologies and says “I’m not sure” so I’ve based the results purely around the web forms sites. Given it sits on an identical hosting model to other ASP.NET websites and we’ve got a good sample size, the high proportion of unpatched machines should be reflected across the board anyway.
But of course we’d expect lots of sites to fail very early on as hosts rushed to patch their systems. After all, this was released right at the end of December when patching machines is usually not the first thing on most server admins’ minds. Let’s see how the failure rate has changed over time:
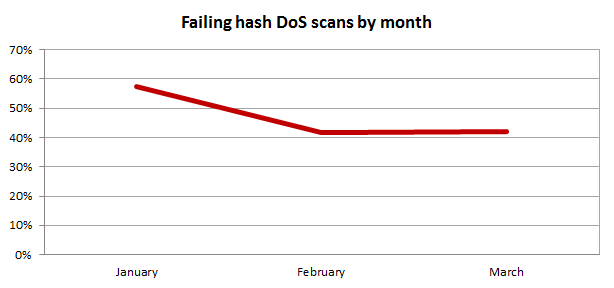
So we’ve had the expected initially high finding in Jan, but what’s surprising is that in the two months following the failure rate of this scan is still very high – 42% actually. In fact there’s even an infinitesimally small increase from Feb to March (about 0.2%), so clearly there are a lot of servers remaining unpatched. One little HTTP request folks, that’s all it takes…
ELMAH
The whole ELMAH security situation is an interesting one. For the unfamiliar, the very excellent Error Logging Modules and Handlers library is a popular way of capturing and reviewing errors which occur on your ASP.NET website. I use it extensively in ASafaWeb myself (among other places).
A few months ago I wrote about ASP.NET session hijacking with Google and ELMAH which, in short, showed there were many, many sites exposing ELMAH logs – which of course, are discoverable by Google – that contain enough information to allow you to take on the session of another authorised user. Actually, that’s only the beginning because there’s enough info in the ELMAH logs to do all sorts of other nefarious things.
There’s a comprehensive overview of what’s in ELMAH in the above link, but this snapshot gives you a quick sense of the level of detail that can be obtained:
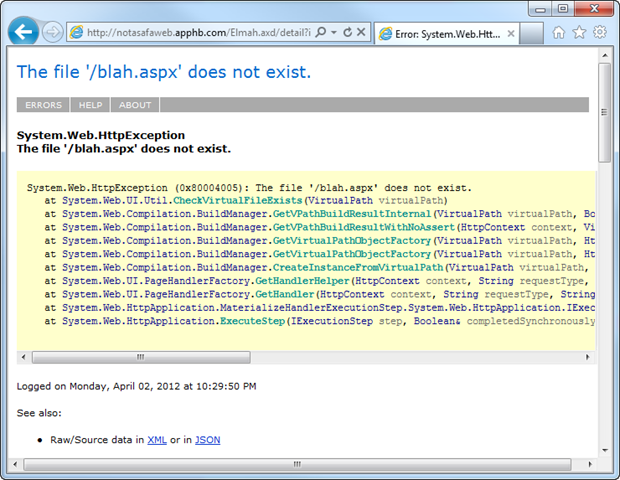
Anyway, the thing that makes this one particularly interesting is that the security guidance on the ELMAH website was wrong (it has since been rectified) and if followed would still leave the ELMAH logs accessible. Obviously it’s a very unfortunate situation and as a result there are plenty of ELMAH enabled websites out there that think they’re secure, but they’re not. Then again, there are plenty that just never really even thought about it!
Here’s what ASafaWeb has found:
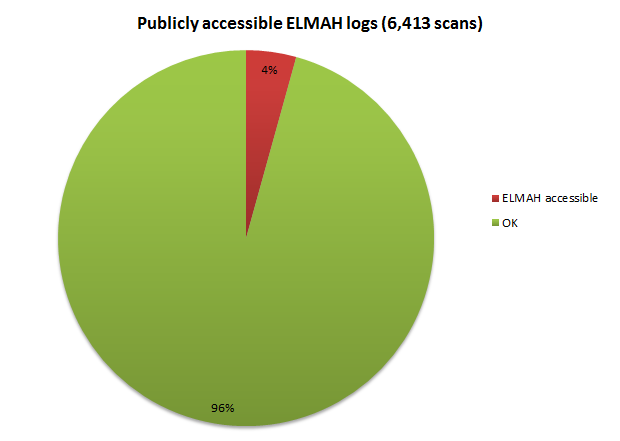
The total number of scans is a little lower than in previous results as the ELAMH test was added part way into Jan. 4% looks like a small number, but consider also that in the grand scheme of things, ELMAH is only installed in a small number of ASP.NET websites. What percentage of these are insecure? 20%? 30%? I’m not sure, but I know that it’s a significant portion of the sites that implement ELMAH.
Tracing
If I’m honest, I’m pleasantly surprised by this result:
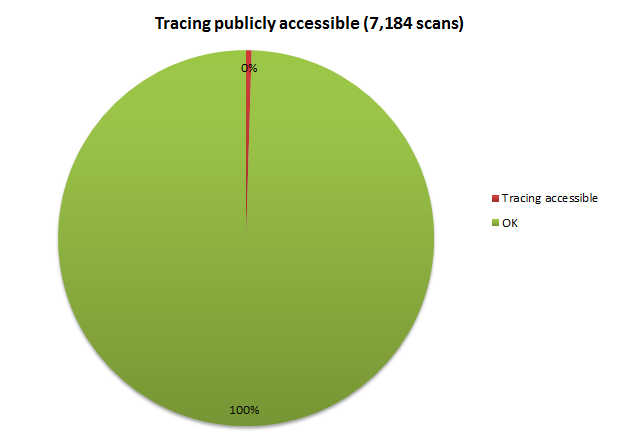
Whilst it’s rounded down to 0%, there were actually 34 scans which found it left on. Tracing is pretty serious business security wise as it turns up all sorts of juicy pieces of info, much of which we saw back in the ELMAH scan:
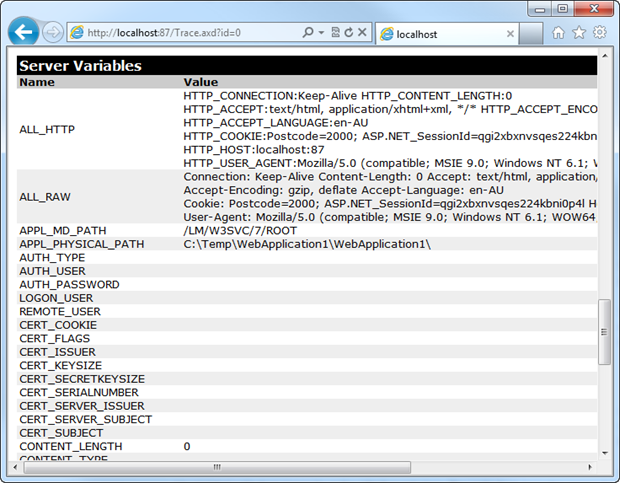
Server variables, web form control tree, framework version and timing of events. Useful stuff to both the good guys and bad guys but fortunately very rarely exposed, according to the stats.
Summary
Here’s the thing with every single one of the findings above: they’re absolutely dead simple to fix. This is not about rewriting code or re-architecting websites; it’s about getting a couple of little config settings right (and ensuring your host keeps their environment patched in the case of hash DoS).
This is one of those “with great power comes great responsibility” scenarios; ASP.NET is an incredibly powerful environment which lets you do amazing things with ease, but that ease also extends to the configurability and creates the opportunity to leave gaping holes in websites without even noticing it.
That’s another common theme I see – developers who completely and utterly understand everything written above but still have vulnerable sites. It only takes a little error in the config transforms or some absentmindedness when testing and that’s it, she’s wide open. Plus there’s not visual evidence of the exposed vulnerability – you have to go and specifically look for these in the site and the reality is that this doesn’t always happen.
ASafaWeb was built to identify these vulnerabilities quickly and automatically and by all accounts, it’s found a good lot of them. But there’s a lot more to come – websites don’t stay static and checking your site with a one off scan is good for today, but what about tomorrow? I’m not going to give too much away just now, but there’s going to be a very nice solution to this just around the corner. For now, check your site and make sure none of those little simple – but potentially severe – configurations are missing.