XSS protection: check!
No SQL injection: check!
Proper use of HTTPS: check!
Clickjacking defences: uh, click what now?!
This is one of those risks which doesn’t tend to get a lot of coverage but it can be a malicious little bugger when exploited by an attacker. Originally described by Jeremiah Grossman of WhiteHat Security fame back in 2008, a clickjacking attack relies on creating a veneer of authenticity under which lies a more sinister objective.
Imagine you visit a website and see the following:
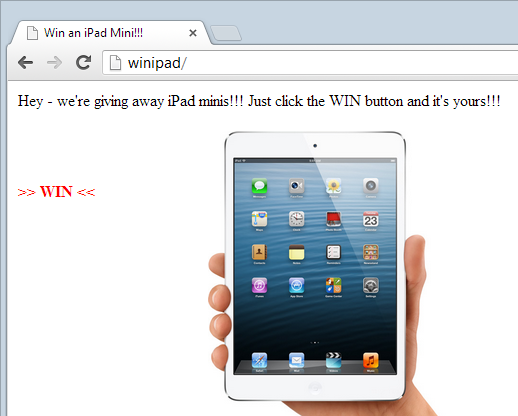
Free stuff is always good so you click on the big button and WAMMO! You’ve just been clickjacked. You see, whilst you think you just clicked a “WIN” link, in reality you just clicked this instead:
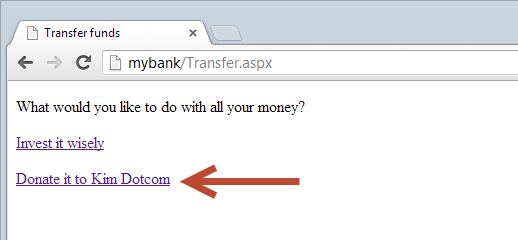
This, of course, is your bank. You are logged in and your bank provides a handy option to transfer all your money with a single click. But of course you don’t know you you’ve just given Mr Dotcom all your money because you never even saw the link. This is a very simple example of a clickjacking attack, let’s take a look at the mechanism underneath and then talk about defences.
Sleight of hand and other tricks
This is a little like a magician’s sleight of hand trick; your focus is on one particular area of interest (winning free goodies) and whilst you’re distracted by this, the real “magic” is happening just out of view. This all make a lot more sense when we toggle some opacities on the page, take a look at it again now:
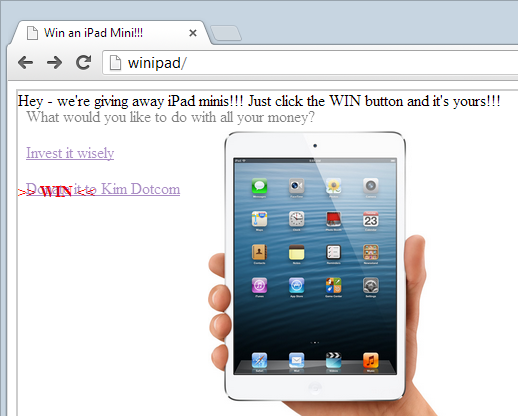
What you can see now is the bank’s page sitting in an iframe on top of the iPad page, it simply has the opacity set at 50%. Earlier on it was set to 0% which effectively meant it was hidden but still active.
Here’s another neat way to view this courtesy of Firefox’s 3D view:
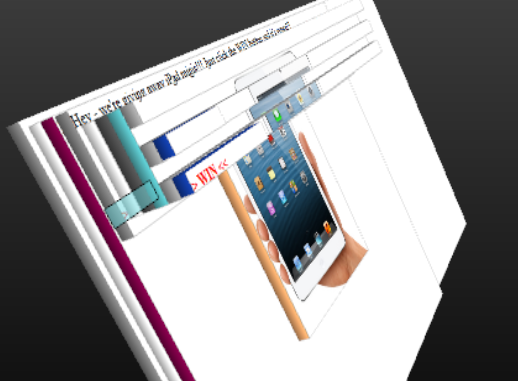
You can see the content that’s actually visible in the attack (such as the “Hey – we’re giving away…” text) sitting several layers deep and the highlighted turquoise box is actually the “WIN” text. The banking site is sitting on top of this which is why you can see several layers on top of it and the “WIN” text ultimately showing through them because of their opacity.
Here’s the key to a clickjacking attack: the target content is hidden and the attacker’s content sits over the top and effectively tricks the victim into clicking links they don’t know they’re clicking. Here’s what the markup of the attacker’s page looks like:
<div style="position: absolute; left: 10px; top: 10px;">Hey - we're giving away iPad minis!!! Just click the WIN button and it's yours!!!</div> <div style="position: absolute; left: 200px; top: 50px;"> <img src="http://images.apple.com/my/ipad-mini/overview/images/hero.jpg" width="250">
</div> <div style="position: absolute; left: 10px; top: 101px; color: red; font-weight: bold;">>> WIN <<</div> <iframe style="opacity: 0;" height="545" width="680" scrolling="no" src="http://mybank/Transfer.aspx"></iframe>
How easy is that?! Whack the target content in an iframe, hide it then position some rogue links underneath the ones you actually want them to click. Job done.
When we look at the request that was made by clicking on the “WIN” link (which of course was actually the “Donate” link), we see the following in Chrome’s developer tools:
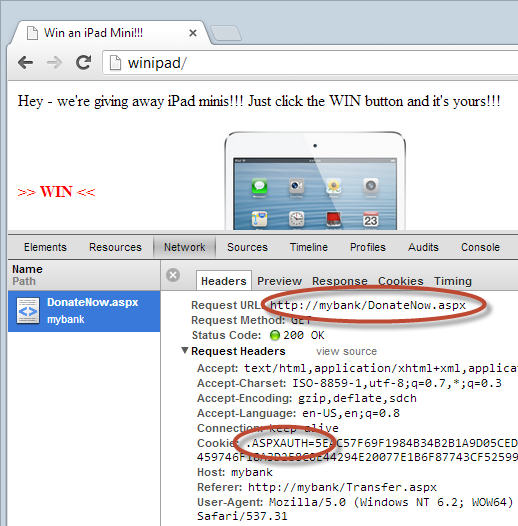
The two important highlighted areas here show the donate resource being requested and an auth cookie being passed with the request. Remember the significance of this – it persists your logged in state which means that for all intents and purposes, this is an authenticated requests from a logged in user, it’s just that they didn’t really intend to issue it. Now of course for something like a banking website or any other use case that takes advantage of an authenticated state, the user actually needs to be logged in. In that regard it’s a little like a cross site request forgery attack. There’s also a bit of broken authentication and session management going on insofar as also like CSRF, this is one of those cases where expiring sessions quickly is a great defence albeit at the expense of usability.
So that’s the execution of it, let’s take a look at the mitigations.
Frame busters (and frame buster busters)
The issue here is that the target site has been loaded up within an iframe. One way to address this is via a little JavaScript in the banking website which works as follows:
if (top.location != location) { top.location = self.location; }
Simple – if the page isn’t the URL in the address bar (and remember, this is our hypothetical banking site), then redirect the top location of the browser to this page so that it and it alone is loaded into the browser. In other words, the target page is literally “busting” out of the frame and taking over the entire browser window hence freeing itself of the malicious site. Job done? Not quite.
For every frame buster there is a frame buster buster. In a classic example of the arms race that is builders versus breakers, there are numerous ways this model can be circumvented. There’s a fantastic paper from a few years ago titled Busting Frame Busting: a Study of Clickjacking Vulnerabilities on Popular Sites that talks about this in detail but in short, frame buster busters use techniques such as:
- Nesting the victim site in two frames as the double framing causes the descendent frame navigation policy to disable the redirection
- Tapping into the onBeforeUnload event to cancel the redirection (albeit with some user input) when the frame buster attempts to unload the page
- Exploiting XSS filters designed to prohibit cross site scripting in order to cancel out the frame buster
Implementations differ by browser and by version and it becomes somewhat of a quagmire of conditional logic and varying degrees of success, but the real point is that frame busting via JavaScript is very patchy. We need a better mousetrap.
X-Frame-Options
Frame busters are hacks. Nasty, messy hacks of limited efficiency. What we really need is a simpler, more semantic means of specifying how and where a page may be used when it comes to being embedded in a frame and that's what we have in the X-Frame-Options (XFO) header. This one actually came out of Microsoft back in early 2009 so it’s been around for a while although evidence would suggest it hasn’t been extensively adopted.
Firstly a bit of response headers 101. When an HTTP header is preceded with “X-“ then it’s not strictly part of the HTTP spec. Anyone can make up their own headers to pass info around outside of the response body. Fortunately it’s a little more organised than that with the browser vendors agreeing to recognise the header and place some limitations on how the browser handles the page as a result. There’s actually a draft IETF spec for the header so we may see more formality at some point in the future.
You’ve got 3 different values for your XFO headers and I’ll quote from that draft IETF spec as it does a good job of describing them:
DENY
A browser receiving content with this header MUST NOT display
this content in any frame.
SAMEORIGIN
A browser receiving content with this header MUST NOT display
this content in any frame from a page of different origin than
the content itself.
If a browser or plugin can not reliably determine whether the
origin of the content and the frame have the same origin, this
MUST be treated as "DENY".
[TBD]current implementations do not display if the origin of
the top-level-browsing-context is different than the origin of
the page containing the X-FRAME-OPTIONS header.
ALLOW-FROM (followed by a URI of trusted origins)
A browser receiving content with this header MUST NOT display
this content in any frame from a page of different origin than
the listed origin. While this can expose the page to risks by
the trusted origin, in some cases it may be necessary to use
content from other domains.
For example: X-FRAME-OPTIONS: ALLOW-FROM
https://www.domain.com/
There is also the non-standard ALLOWALL value which does just what it sounds like it does – in theory. Apparently this value started getting served up by Google quite recently and got the browsers a little confused. Well more specifically, the browsers don’t recognise it as a valid value and consequently just ignored it which, of course, is exactly what the intention is and is the equivalent of having no XFO header at all. Except it isn’t really; when you see no header there are two possible options with the first being that the developer wants to allow the page to be embedded anywhere and the second that they never even thought to include it. My money is on the second option being by far and away the most prevalent situation and the ALLOWALL value is an explicit acknowledgement that a conscious decision has been made to allow embedding in frames. The intent is much clearer and far less implicit which IMHO is a good thing.
There is, however, some criticism of the XFO implementation as it stands. For example, it’s not possible to allow framing of content both from the same origin and from a trusted URI. In a similar vein, it’s also not possible to allow framing from multiple trusted URIs. Both of these are unfortunate shortcomings of the header as they’re very real scenarios. Allowing the browser to recognise multiple non-conflicting definitions of the header would be one approach but that doesn’t appear to be on the cards just now.
Moving on, XFO is all pretty simple and the browser support is very good with IE8 onwards implementing it as well as all the other major vendors for a number of versions now (Firefox 3.6, Safari 4, Chrome 4.1). What if a browser doesn’t implement it? Absolutely nothing, it will just carry on as usual and not put any constraints around the content being framed.
Assuming you don’t actually want a site embedded within other sites (which will usually be the case), just use it – it’s a few bytes of overhead to prevent a potentially rather malicious scenario. Ideally, you want to just deny access to browsers loading the page in a frame. If you really want to load your own pages into frames on the same site then you do the same origin trick or open it up further to another site with the “allow-from” syntax. Do be cautious though: things will break if you’re overzealous and inadvertently block content from loading into legitimate frames.
XFO in practice
Getting back to our original example, here’s what happens to that site once XFO denies embedding in a frame (I’ve left the opacity at 50%):
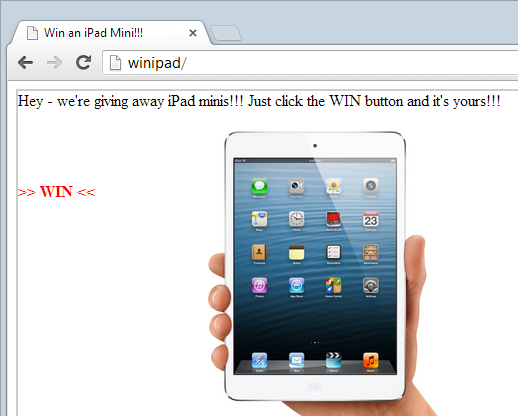
You see that? Of course you don’t, that’s the whole point! The banking site is no longer rendered in the browser, all you can see is the iframe border. Mind you, the banking site is still requested because after all, that’s the only way the browser can be instructed not to render it once it’s returned by the server. You can see this in Chrome’s network profiler:
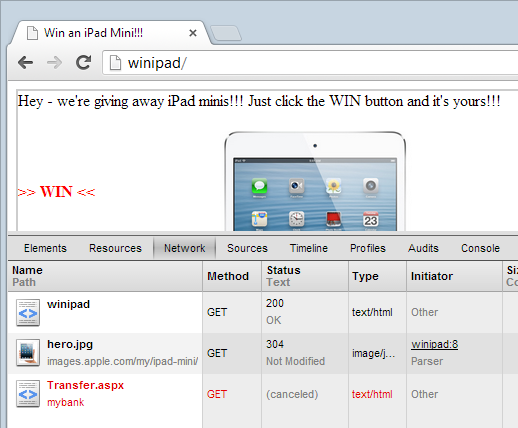
Check the status of that last request to Transfer.aspx – it’s now “cancelled” which is kind of right. As I said earlier, the request is actually still made and indeed you can inspect the response headers:
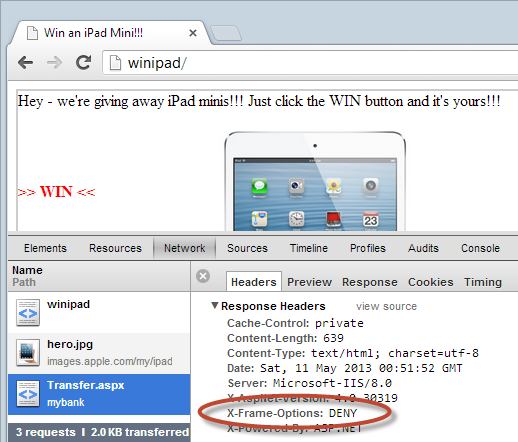
Just to close the loop on things, there’s that XFO header. Job done!
Protecting your ASP.NET app with NWebsec
Adding response headers to most frameworks is a piece of cake, ASP.NET included. Normally I’d just go and create a custom HTTP module and be done with it but being a fan of taking community projects that already work well, it’s worth checking out NWebsec first. This little package was created by André Klingsheim who has done a number of clever security things over the years. As with all good .NET packages it can be easily grabbed from NuGet:
PM> Install-Package NWebsec
One of the things I like about NWebsec is that it’s a configuration-only install; there’s no recompile, just drop in the libraries and setup the web.config and you’re done. For some people, this is quite advantageous. The other neat thing is that it tackles a bunch of other security related headers as well. For example, I just dropped it into ASafaWeb and used it to both add an XFO header and replace my existing HSTS header code with just a web.config configuration. Speaking of ASafaWeb…
Detecting the clickjack risk with ASafaWeb
As many of you will already know, I maintain a little security misconfiguration scanner called ASafaWeb which is the Automated Security Analyser for ASP.NET Websites. As the name suggests, it’s predominantly aimed at security misconfiguration of sites built on the Microsoft stack but its horizons are increasingly being broadened. For example, I recently added support for detecting HTTP only and secure cookies which, of course, works across any web platform that talks in HTTP.
Now I’ve added support for detecting XFO. It’s a real no-brainer for ASafaWeb as it just involves looking at the response headers of one of the requests it already makes so that’s no additional HTTP overhead by way of additional requests. Here’s what a sample scan looks like when no clickjacking defence exists:
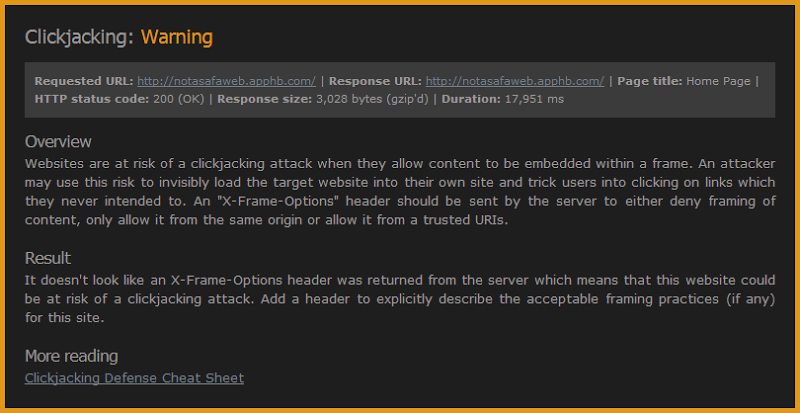
You’ll see that ASafaWeb flags it as a warning and there are a few different reasons for that. Firstly, it may be perfectly legitimate not to set an XFO header because there are cases where you want your content to be framed by other sites beyond what is feasible to describe with an ALLOW-FROM value. It’s rare, but there are cases. Secondly, flagging this an error alongside risks such as an exposed ELMAH log or a page stack trace is not really commensurate with the actual risk it poses. I did exactly the same thing with the excessive headers scan for the same reason. Finally, I’m going to take a guess here and say that 90%+ of sites are going to fail this scan. I do store de-identified logs so I’ll be able to validate this assumption once some data is collected, but marking almost every single scan someone does as having an “error” can be counter-productive, particularly when people also have scheduled scans which are only triggered when an error state occurs.
If this post has sparked your interest, go and drop some of your sites into ASafaWeb and you’ll quickly get an idea of how many are at risk of a clickjacking attack. It will almost certainly be many.
More on XFO
It’s interesting to look at how other websites implement XFO. For example, here’s what Facebook does:
X-Frame-Options: DENY
And Twitter:
x-frame-options: SAMEORIGIN
And even GitHub:
X-Frame-Options: deny
On the other hand, let’s look at what our “Big 4” Aussie banks do:
- ANZ – no XFO
- Commonwealth – nothing there
- Westpac – nada
- NAB – nope
Now of course the clickjacking risk can only really be exploited when there’s an advantage to be gained by a victim unknowingly clicking on a link, so for example once they’re actually logged on to their bank account and assuming it’s a mere single link click that doesn’t require follow-up action to actually impact a change. Maybe that usage pattern doesn’t exist behind the logons of those banks but at the end of the day, we’re just talking about a few bytes added to the response header so it’s not like implementing XFO is going to cause any tangible adverse impact.
Ultimately, this is just another one of those little additional security value-add features. It’s not exactly in the same league as SQL injection or cross site scripting, but as I’ve written before, it can be a real nuisance when leveraged against features such as a Facebook “like” buttons. Plus of course there are genuine cases where it can cause damage, particularly when combined with other sloppy practices such as far-reaching session expirations. Just add an XFO header and be done with it.