Three weeks ago today, I wrote about implementing a rate limit on the Have I been pwned (HIBP) API and the original plan was to have it begin a week from today. I want to talk more about why the rate limit was required and why I've had to bring it forward to today.
As I explained in the original post, there were multiple reasons for the rate limit including high volumes of API calls impacting system performance (they were ramping up faster than Azure could auto-scale), the cost to me personally of supporting the traffic (I pay for all of this out of my own pocket), and finally, my desire to ensure the system is used for ethical purposes to the fullest extent possible. It's this last one I want to share more detail on here.
In the weeks leading up to the original rate limit post, I was seeing large volumes of requests adhering to patterns that I wasn't confident indicated ethical use. These included:
- Alphabetically working through a large volume of addresses on mail provider domains
- Obfuscating the user agent by randomising strings across a broad range of otherwise legitimate browser UAs
- Serving the requests from hundreds of different IP addresses, predominantly in Eastern Europe
- Actively adapting request patterns to avoid counter-abuse measures I had in place
That third point in particular is typical botnet behaviour; otherwise legitimate machines infected with malware acting on behalf of a malicious party. Azure captures a small snapshot of rolling log files in W3C extended format (usually just the last hour of activity, I don't explicitly retain any logs) and from these I could see patterns such as this:
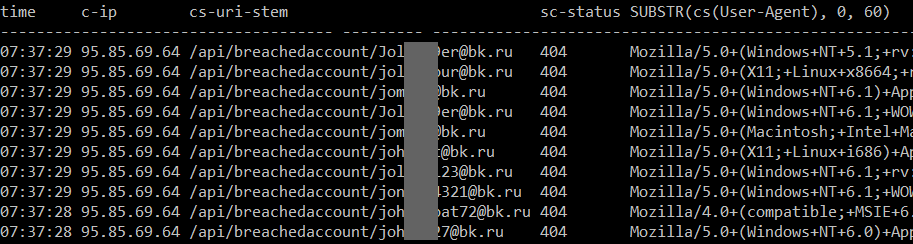
In this case, they're all from the same Russian IP address, all on the bk.ru domain which redirects to the mail.ru mail service and none of them are in HIBP anyway (they're all returning 404). I'd frequently see volumes of around 12k requests per minute coming from 2 or 3 IP addresses. One of the countermeasures I used was to simply block the addresses and return 403 with a response body referring to the acceptable use terms of the API, but those IPs would quickly be replaced with others following the same pattern. This was easily handled on my end by the minimum infrastructure scale I normally run and at worst, another instance of a medium Azure web site might have been added to handle it. This meant it wasn't a big problem in terms of scale and consequently cost (even though it was causing increased transaction times), but clearly the patterns in the bullet points above are not something I wanted to be seeing. That was the status quo until two days ago when I started seeing traffic patterns like this:
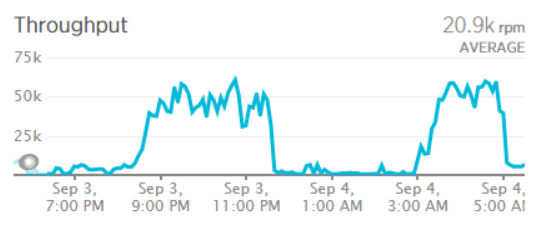
Now we're talking about sustained traffic of up to 60k requests per minute. Remember, each of those is searching 1.3 billion records and when you're doing that a thousand times a second, it's gonna consume a lot of overhead to support it. It was hurting performance, it was hurting my wallet and it was hurting availability:
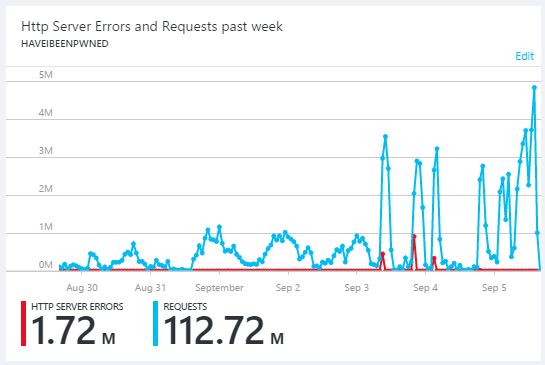
The image above is traffic over the preceding week. In the last few days of August, the graph shows the suspicious usage patterns described above then in the first few days of September, high levels of sustained organic traffic (normal users with a web browser) of many hundreds of thousands of visitors a day due to the Dropbox incident and subsequent extensive press coverage. However, get to September 3 and you'll see the traffic rocketing up to the levels in the earlier image. I can only speculate on the reasons for this and I suspect it's related to the abuse countermeasures I implemented but clearly, something major changed in the traffic patterns.
The real concern availability wise though is those little red blips on September 3 and 4. Because the traffic was coming on so hard and so fast, I wasn't able to scale quickly enough. The reason for this is that I configure the Azure infrastructure to autoscale and it looks like this:
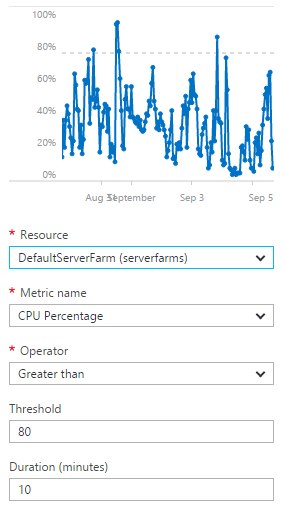
What you're seeing here is the conditions that need to be met to cause the infrastructure to scale, namely that the CPU overhead exceeds an average of 80% across a duration of 10 minutes. Now that's fine when traffic ramps up even very quickly in an organic fashion, but when it suddenly goes through the roof in mere seconds then you can be looking at minutes before extra scale is added. That scale may not be enough either - I'm adding 1 instance at a time then allowing 10 minutes to see how performance goes before adding another one. When you're suddenly hit with load that requires many additional servers, some of those requests result in errors. At peak, I was seeing 125k requests a minute and when that volume of traffic is suddenly thrown at a scale that's serving "mere" thousands of requests a minute, you're gonna have problems. And that's not cool.
Downtime on a service like this impacts confidence in a domain where trust and integrity are everything. Even mere minutes of downtime is unacceptable as far as I'm concerned and fortunately it was never more than short periods of time, but that was too much. Yes, it's a free service and it would have been a much more uncomfortable situation if I was charging money for it, but it's still a professionally run service and I wasn't willing to have downtime.
I fixed the problem in the immediate term by simply throwing money at it. I scaled up to Azure's S3 Standard App Service (what we used to know as a "large" web server) and then out to 5 of them and just left it there. It cost me money out of my own pocket, but fortunately I got a good number of donations from the Dropbox incident last week so it's only right to invest back into the service. That investment meant that even as the service continued being hammered on Saturday night, errors remained somewhat of a rarity:
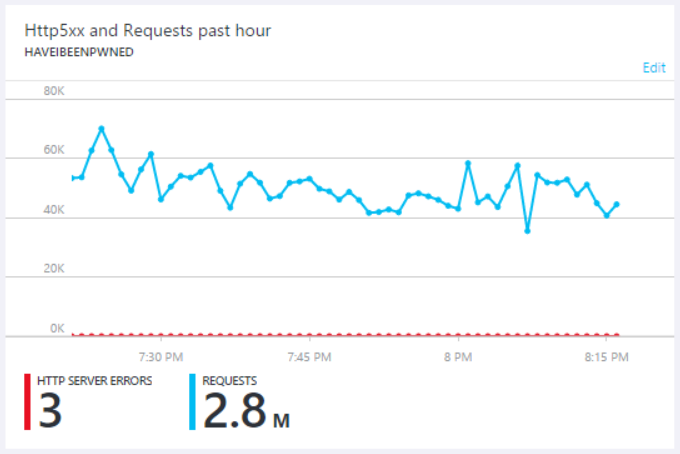
That's just what I was seeing on the Azure end though and whilst it was regularly processing up to 70k requests a minute, there were other dropouts I identified via external monitoring services. Granted, they'd be mostly evident to whatever was hammering the service (which seems fair), but inevitably it was impacting legitimate users too. At the end of the day though, I have a fundamental problem with essentially paying to keep the system abusable and there were no guarantees the traffic wouldn't dramatically ramp up again either.
So I introduced the rate limit early. I didn't want to inconvenience any legitimate users who still needed the extra week, but even more than that I wanted to keep the service fast and reliable for the masses.
However, with the API no longer abusable in the same way, attention turned to simply hammering the root of the site with HTTP GET requests. For a good portion of today, the site received unprecedented levels of sustained traffic:
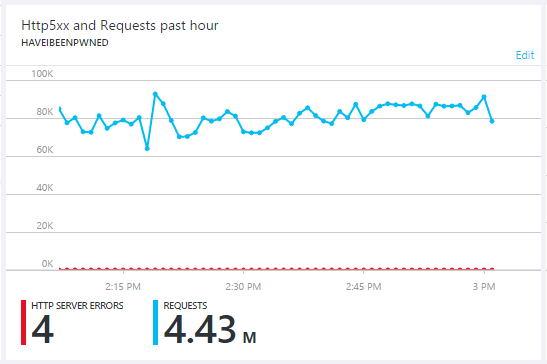
I did a bit of tuning at various points to be able to absorb the traffic, which is one of the reasons why there's a failure rate of less than one in a million requests. The external monitoring showed everything running reliably and the application responsiveness has also remained exactly where I'd like it to be:
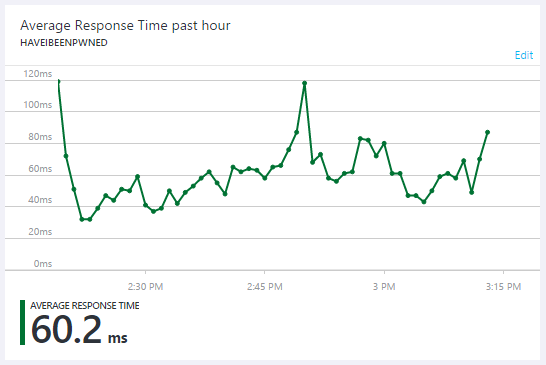
But this traffic is no longer API abuse, it's an attempted DDoS. There is absolutely no value in the responses that are returned by making GET requests to the root of the website beyond the satisfaction gained by the adversary if they're able to impact service continuity. I can only speculate that it's frustration being vented at no longer having unbridled access to the API and I understand that - clearly it was very useful to someone in unlimited form. Equally, I hope they can understand why leaving it unlimited was no longer tenable for me.
So that's why the rate limit was brought in early, to ensure I can keep running the service reliably, cost effectively and ethically. I've always been as transparent as possible with how HIBP runs and cases like this are no exception. I've been connecting with people potentially impacted by the limit over the last few weeks and moving the timeline forward should have little to no impact on the ethical users of the system. If it does though, please contact me and I'll make sure I support legitimate use cases to continue using the service in a responsible way.
And lastly, I will write more about the things I've learned from this experience and I'm already dropping a lot of detail into a draft blog post. For now though, I'll keep things a little quiet on that front, but what I will say again is that those donations have been enormously helpful and have made it much easier for me to ensure the service stays up. If you'd like to help, the donations page lists some of the things I'd normally spend the money on (and I guarantee you, I do!) although for the next little while, assume it'll go to "The HIBP Anti-DDoS Fund".