Since launching version 2 of Pwned Passwords with the k-anonymity model just over 2 years ago now, the thing has really gone nuts (read that blog post for background otherwise nothing from here on will make much sense). All sorts of organisations are employing the service to keep passwords from previous data breaches from being used again and subsequently, putting their customers at heightened risk. For example, this just a couple of days ago:
This is cool: @identityauto is integrating @haveibeenpwned's Pwned Passwords into their RapidIdentity product. Very slick! pic.twitter.com/64d9p8hQq6
— Troy Hunt (@troyhunt) March 3, 2020
The anonymity implementation means consumers of the service can hit the API without disclosing what password is actually being searched for; the only thing sent to Have I Been Pwned (HIBP) is the first 5 characters of a SHA-1 hash. If, for example, someone tried to use a password of "P@ssw0rd" (because hackers haven't worked out people use character substitution...), we begin by taking the SHA-1 hash of the entire string:
21bd12dc183f740ee76f27b78eb39c8ad972a757Now we take just the first 5 characters and make a request like this:
GET https://api.pwnedpasswords.com/range/21bd1Amongst the 528 results returned are the following 5 lines:
2D6980B9098804E7A83DC5831BFBAF3927F:1
2D8D1B3FAACCA6A3C6A91617B2FA32E2F57:1
2DC183F740EE76F27B78EB39C8AD972A757:52579
2DE4C0087846D223DBBCCF071614590F300:2
2DEA2B1D02714099E4B7A874B4364D518F6:1The row in the middle is the suffix of the complete SHA-1 hash of the searched password. The consumer can search through this result set and if the suffix exists, know that the original password has appeared in a data breach and in this case, know that it's appeared 52,579 times. The anonymity value is that from my perspective running the service, all I know is that someone is searching for "21bd1". They could be searching for any password whose SHA-1 hash begins with those characters. For example, they could be searching for the password "020293" which has a SHA-1 hash of 21bd192580cad5c57296f8488df190d23046b05f (note the first 5 chars) and has been seen 3,474 times before. Or the password "sparky50" which has a SHA-1 hash of 21bd16d4a08cb51c8b88fc8ce07742974d7d541d and has been seen 485 times before. Or any other string whose hash begins with those first 5 chars and ends with any other combination of 35 hexadecimal values. The potential range is astronomically large hence the privacy provisions.
But what if someone was sitting on the wire between the consumer of the service and HIBP? What if they could observe the traffic? Well there's HTTPS from top to bottom so job done! Mostly - there's a gap and it's an obscure one but a gap nonetheless. To demonstrate, let's take another password and this time it's "P@ssw0rd2" (see what I did there - this is a really scalable approach suitable for dealing with mandated password rotation policies ?). Here's the SHA-1 hash of that string:
9e823816a6a507e61b90e00f5be3b695f6896a7dNow, let's just fire up the browser and hit the Pwned Passwords API with the first password from earlier on then this one. Here's what you'll see in the dev tools:

See that? The responses are different sizes. The first one has the aforementioned 528 rows whilst the new search has 523. Plus, passwords beginning with the first hash prefix have been seen a total of 59,087 times whilst the second one has a sum of 2,139. Different content, different response sizes.
Let's add another variable by loading them both up in Fiddler then requesting more hash ranges in incrementing sequence:
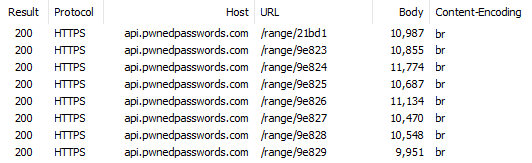
Firstly, every response is slightly different in size thus reconfirming the earlier observation in Chrome. Secondly, each response is brotli compressed which is something I'll come back to a little later. But while we're here, check out just how much more efficient br is than gzip:

That's about a 29% improvement in response size which is pretty amazing for just a tweak of the request header (assuming your client can support brotli, of course).
Here's the crux of all this: if someone can intercept requests between a consumer of the Pwned Passwords service and the Cloudflare edge node it's hitting (remember, pretty much every request is served directly from Cloudflare), they may be able to determine the hash prefix being searched for. What they can't do is determine the actual full hash. Depending on the nature of the service consumer, they may also have absolutely no idea whose password is being searched for. As an example, if you're creating an account on the Co-op website in the UK and their server then calls out to Pwned Passwords to check it (good on them for doing this too!), anyone intercepting the request could possibly see that it came from their service but would lack the context of whose password was being checked. On the other hand, a client running on my own desktop making calls to Pwned Passwords could identify me as the source of the request for the hash prefix if the traffic could be tied back to other identifying data (i.e. my IP address). A lot needs to line up for this to cause any practical risks, but let's talk mitigation anyway. Let's talk about padding in cryptography:
In cryptography, padding is any of a number of distinct practices which all include adding data to the beginning, middle, or end of a message prior to encryption. In classical cryptography, padding may include adding nonsense phrases to a message to obscure the fact that many messages end in predictable ways, e.g. sincerely yours.
The value proposition for Pwned Passwords is that by introducing padding we can abstract the actual size of the underlying response from the observable size that someone may see on the wire. This issue and associated fix was recently brought to Junade's (who created the k-anonymity model for Pwned Passwords) and my attention by Matt Weir who created an excellent proof of concept analysis which is worth a look if you'd like to understand things in more depth. Following discussions between the 3 of us, Junade has implemented the ability to add padding directly within the Cloudflare worker (huge thanks to Junade for doing all this "at the edge" meaning I didn't have any "real" work to do!) It's easy to enable padding by adding the following header when requesting the Pwned Passwords API:
GET https://api.pwnedpasswords.com/range/21bd1
Add-Padding: trueIf we try the two requests from earlier with padding enabled, we now see the following results:

Those response sizes and now massively larger because they've been padded out and that's the first thing to understand about this approach: padding adds privacy, but it also adds bytes. But it'd be no good if the padding size was constant either as you'd be back in the same place as before regarding predictability. Let's make another half dozen requests to that last hash range with the padding header on:
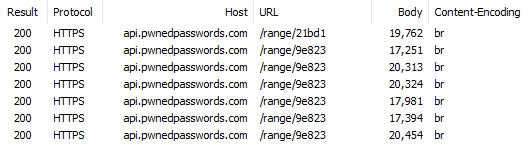
As you can see, the response sizes vary. What this means is that for an attacker sitting on the wire, even if every request was for the same hash prefix they'd have no idea which one it was as there's no observable consistency in the responses.
So, where does the padding come from? Let's take that 9e823 hash prefix (remember, it previously had 523 results) and see what it looks like now:

See how from lines 524 onwards every hash has a value of "0"? In total, this particular request had 993 rows. The request before that had 846. The one before that was 873. By enabling the header you're adding a random number of rows such that the total number (including legitimate ones) is between 800 and 1,000. Each one of those rows with a random hash suffix represents it as having been seen zero times. We chose these numbers as they give us a heap of buffer to expand the total volume of Pwned Passwords in the future without impacting the response sizes. Of course, if enough new passwords were added (let's say it doubles), the maths would need to change but that's easily done back in that Cloudflare worker.
One thing to keep in mind if you're considering implementing the padding is how you handle those zero occurrence padding rows. For example, if the hash you were searching for matched one of the generated suffixes then unless you specifically discard it due to the zero value, you'd end up with a false positive (then again, this is effectively a hash collision and the chances of that happening randomly are exceptionally remote).
Oh - and before someone jumps on my case about the use of the word "random", Cloudflare is using their famous lava lamps as a source of entropy which is pretty awesome:
Great catching up @troyhunt at the @Cloudflare today - in front of the famous lava lamp wall. pic.twitter.com/4KDQfhUfWy
— Junade Ali (@IcyApril) March 15, 2018
Using padding needs to be an opt-in feature as enabling it by default could cause all sorts of unexpected behaviour for existing consumers, most notably due to the response sizes increasing massively and the presence of the zero-occurrence hash suffixes. The benefit provided by introducing padding also depends on many different variables specific to the consumer's own circumstances. My own personal view is that the real-world risk is extremely remote as your worst-case scenario is that an adversary could determine the hash prefix alone which, due to the k-anonymity model, still protects the value of the original hash and thus the password. But now consumers of the service have the option and just like before, they can also just download the complete hash set and run the entire thing offline without any API dependencies whatsoever if they'd prefer.
Lastly, a big thanks to Matt for his work on this and to Junade for so easily rolling it into the Cloudflare worker. Junade has also written up a piece on this where he provides some more technical insights such as the impact of compression on padding. Check that out and also check out the official HIBP API docs, this is now fully covered there too.