Last August, I launched a little feature within Have I Been Pwned (HIBP) I called Pwned Passwords. This was a list of 320 million passwords from a range of different data breaches which organisations could use to better protect their own systems. How? NIST explains:
When processing requests to establish and change memorized secrets, verifiers SHALL compare the prospective secrets against a list that contains values known to be commonly-used, expected, or compromised.
They then go on to recommend that passwords "obtained from previous breach corpuses" should be disallowed and that the service should "advise the subscriber that they need to select a different secret". This makes a lot of sense when you think about it: if someone is signing up to a service with a password that has previously appeared in a data breach, either it's the same person reusing their passwords (bad) or two different people who through mere coincidence, have chosen exactly the same password. In reality, this means they probably both have dogs with the same name or some other personal attribute they're naming their passwords after (also bad).
Now all of this was great advice from NIST, but they stopped short of providing the one thing organisations really need to make all this work: the passwords themselves. That's why I created Pwned Passwords - because there was a gap that needed filling - and let's face it, I do have access to rather a lot of them courtesy of running HIBP. So 6 months ago I launched the service and today, I'm pleased to launch version 2 with more passwords, more features and something I'm particularly excited about - more privacy. Here's what it's all about:
There's Now 501,636,842 Pwned Passwords
Back at the V1 launch, I explained how the original data set was comprised of sources such as the Anti Public and Exploit.in combo lists as well as "a variety of other data sources". In V2, I've expanded that to include a bunch of data sources along with 2 major ones:
- The 711 million record Onliner Spambot dump. This was a lot of work to parse varying data formats and if you read the comments on that blog post, you'll get a sense of how much people wanted this (and why it was problematic).
- The 1.4B clear text credentials from the "dark web". This data resulted in many totally overblown news stories (and contributed to my "dark web" FUD blog post last week), but it did serve as a useful reference for V2. This data also had a bunch of integrity problems which meant the actual number was somewhat less. For example, the exact same username and password pairs appearing with different delimiters:

There's also a heap of other separate sources there where passwords were available in plain text. As with V1, I'm not going to name them here, suffice to say it's a broad collection from many more breaches than I used in the original version. It's taken a heap of effort to parse through these but it's helped build that list up to beyond the half billion mark which is a significant amount of data. From a defensive standpoint, this is good - more data means more ability to block risky passwords.
But I haven't just added data, I've also removed some. Let me explain why and to begin with, let's do a quick recap on the rationale for hashing them.
They're Still SHA-1 Hashed, But with Some Junk Removed
When I launched V1, I explained why I SHA-1 hashed them:
It doesn't matter that SHA1 is a fast algorithm unsuitable for storing your customers' passwords with because that's not what we're doing here, it's simply about ensuring the source passwords are not immediately visible.
That's still 100% true as of today. There are certainly those that don't agree with this approach; they claim that either the data is easily discoverable enough online anyway or conversely, that SHA-1 is an insufficiently robust algorithm for password storage. They're right, too - on both points - but that's not what this is about. The entire point is to ensure that any personal info in the source data is obfuscated such that it requires a concerted effort to remove the protection, but that the data is still usable for its intended purposes. SHA-1 has done that in V1 and I'm still confident enough in the model to use the same approach in V2.
One of the things that did surprise me a little in V1 was the effort some folks went to in order to crack the passwords. I was surprised primarily because the vast majority of those passwords were already available in the clear via the 2 combo lists I mentioned earlier anyway, so why bother? Just download the (easily discoverable) lists! The penny that later dropped was that it presented a challenge - and people like challenges!
One upside from people cracking the passwords for fun was that CynoSure Prime managed to identify a bunch of junk. Due to the integrity of the source data being a bit patchy in places, there were entries such as the following.
- $HEX[e3eeeb]
- 6dcc978317511fd8
- <div align=\\\'center\\\' style=\\\'font:bold 11px Verdana; width:310px\\\'><a style=\\\'background-color:#eeeeee;display:block;width:310px;border:solid 2px black; padding:5px\\\' href=\\\'http://...
Of course, it's possible people actually used these strings as passwords but applying a bit of Occam's Razor suggests that it's simply parsing issues upstream of this data set. In total, CynoSure Prime identified 3,472,226 junk records which I've removed in V2. (Incidentally, these are the same guys that found the shortcomings in Ashley Madison's password storage approach back in 2015 - they do quality work!)
Frankly though, there's little point in removing a few million junk strings. It reduced the overall data size of V2 by 0.69% and other than the tiny fraction of extra bytes added to the set, it makes no practical difference to how the data is used. On that point and in terms of extraneous records, I want to be really clear about the following:
This list is not perfect - it's not meant to be perfect - and there will be some junk due to input data quality and some missing passwords because they weren't in the source data sets. It's simply meant to be a list of strings that pose an elevated risk if used for passwords and for that purpose, it's enormously effective.
Whilst the total number of records included in V2 is significant, it also doesn't tell the whole story and indeed the feedback from V1 was that the 320M passwords needed something more: an indicator of just how bad each one really was.
Each Password Now Has a Count Next to It
Is the password "abc123" worse than "acl567"? Most password strength meters would consider them equivalent because mathematically, they are. But as I've said before, password strength indicators help people make ill-informed choices and this is a perfect example of that. They're both terrible passwords - don't get me wrong - but a predictable keyboard pattern makes the former much worse and that's now reflected in the Pwned Passwords data.
Now on the one hand, you could argue that once a password has appeared breached even just once, it's unfit for future use. It'll go into password dictionaries, be tested against the username it was next to and forever more be a weak choice regardless of where it appears in the future. However, I got a lot of feedback from V1 along the lines of "simply blocking 320M passwords is a usability nightmare". Blocking half a billion, even more so.
In V2, every single password has a count next to it. What this means is that next to "abc123" you'll see 2,670,319 - that's how many times it appeared in my data sources. Obviously with a number that high, it appeared many times over in the same sources because many people chose the same password. The password "acl567", on the other hand, only appeared once. Having visibility to the prevalence means, for example, you might outright block every password that's appeared 100 times or more and force the user to choose another one (there are 1,858,690 of those in the data set), strongly recommend they choose a different password where it's appeared between 20 and 99 times (there's a further 9,985,150 of those), and merely flag the record if it's in the source data less than 20 times. Of course, the password "acl567" may well be deemed too weak by the requirements of the site even without Pwned Passwords so this is by no means the only test a site should apply.
In total, there were 3,033,858,815 occurrences of those 501,636,842 unique passwords. In other words, on average, each password appeared 6 times across various data breaches. In some cases, the same password appeared many times in the one incident - often thousands of times - because that's how many people chose the same damn password!
Now, having said all that, in the lead-up to the launch of V2 I've had people argue vehemently that they all should be blocked or that none of them should be blocked or any combination in between. That's not up to me, that's up to whoever uses this data, my job is simply to give people enough information to be able to make informed decisions. My own subjective view on this is that "it depends"; different risk levels, different audiences and different mitigating controls should all factor into this decision.
I Haven't Included Password Length
One request that came up a few times was to include a length attribute on each password hash. This way, those using the data could exclude passwords from the original data set that fall beneath their minimum password length requirements. The thinking there being that it would reduce the data size they're searching through thus realising some performance (and possibly financial) gains. But there are many reasons why this ultimately didn't make sense:
The first is that from the perspective of protecting the source data (remember, it contains PII in places), explicitly specifying the length greatly reduces the effort required to crack the passwords. Yes, I know I said earlier that the hashing approach wasn't meant to be highly resilient, but providing a length would be significantly detrimental to the protection that SHA-1 does provide.
Then, I actually got a bit scientific about it and looked at what minimum length password websites required. In fact, that's why I wrote the piece on minimum length by the world's top sites a couple of weeks back; I wanted to put hard numbers on it. 11 of the 15 sites I referred to had a minimum length of 6 chars or less. When I then went and looked at the data set I was using, excluding passwords of less than 6 chars would have only reduced the set by less than 1% Excluding anything under 8 chars would have reduced it by just under 16%. They're very small numbers.
Then there's the overhead required to host and search this data, that is the overhead those organisations who use it will incur. It should be very close to nothing with the whole half billion data set. Chuck it in a storage construct like Azure Table Storage and you're looking at single digit dollars per month with single digit millisecond lookup times. There's no need for this to be any more complex than that.
So in short, it put the protection of the hashing at greater risk, there was very little value gained and it's easy to implement this in a way that's fast and cheap anyway. Some people will disagree, but a lot of thought went into this and I'm confident that the conclusion was the right one.
Downloading the Data
And now to the pointy bit - downloading the data. As with V1, there's one big 7z archive you can go and pull down immediately from the Pwned Passwords page on HIBP. Also as before, it's available via direct download from the site or via torrent. I want to strongly encourage you to take it via the torrent, let me explain why:
The underlying storage construct for this data is Azure Blob storage. If I was to serve the file directly from there, I'd cop a very hefty data bill. Cloudflare came to rescue in V1 and gave me a free plan that enabled a file of that size to be cached as their edge nodes. The impact of that on my bill was massive:
Another massive thanks to @Cloudflare for supporting the @haveibeenpwned Pwned Passwords, just did the maths on how much it saved me - whoa! pic.twitter.com/70kki5Uw7o
— Troy Hunt (@troyhunt) August 15, 2017
Imagine the discussion I'd be having with my wife if it wasn't for Cloudflare's support! And that was before another 6 months' worth of downloads too. Cloudflare might have given me the service for free, but they still have to pay for bandwidth so I'd like to ask for your support in pulling the data down via torrents rather than from the direct download link. To that effect, the UI actively encourages you to grab the torrent:

If you can't grab the torrent (and I'm conscious there are, for example, corporate environments where torrents are blocked), then download it direct but do your bit to help me out by supporting the folks supporting me where you can. As with V1, the torrent file is served directly from HIBP's Blob Storage and you'll find a SHA-1 hash of the Pwned Passwords file next to it so you can check integrity if you're so inclined.
So that's the download - go forth and do good things with it! Now for something else cool and that's the online search.
Querying the Data Online
In V1, I stood up an online search feature where you could plug in a password and see if it appeared in the data set. That sat on top of an API which I also made available for independent consumption should people wish to use it. And many people did use it. In fact, some of the entrants to my competition to win a Lenovo laptop leveraged that particular endpoint including the winner of the competition, 16,year-old Félix Giffard. He created PasswordSecurity.info which directly consumes the Pwned Passwords API via the client side:
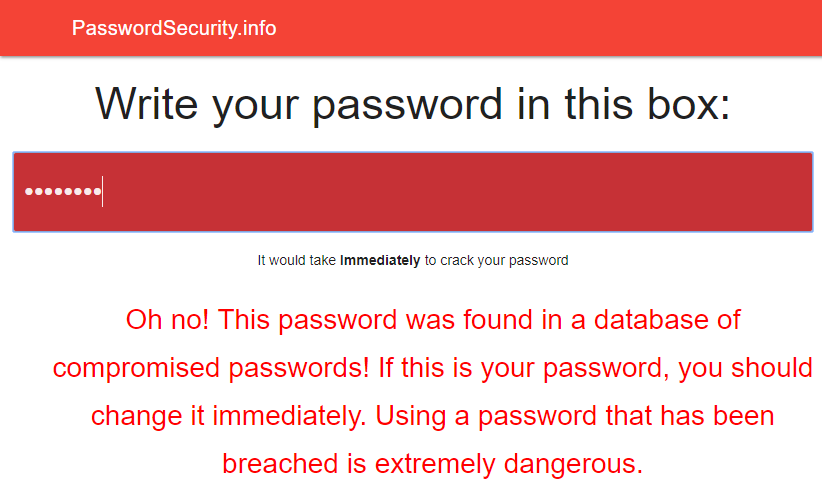
Getting back to the online search, being conscious of not wanting to send the wrong message to people, immediately before the search box I put a very clear, very bold message: "Do not send any password you actively use to a third-party service - even this one!"
But people don't always read these things. The service got a heap of press and millions of people descended on the site to check their passwords. At least I assume it was their passwords, I certainly don't log those searches but based on the news articles and social media commentary, yeah, it would have been a heap of real passwords. And I'm actually ok with that - let me explain:
As much as I don't want to encourage people to plug their real password(s) into random third-party sites, I can guarantee that a sizable number of people got a positive hit and then changed their security hygiene as a result. One of the biggest things that's resonated with me in running HIBP is how much impact it's had on changing user behaviour. Seeing either your email address or your password pwned has a way of making people reconsider some of their security decisions.
The online search works almost identically to V1 albeit with the count of the password now represented too:
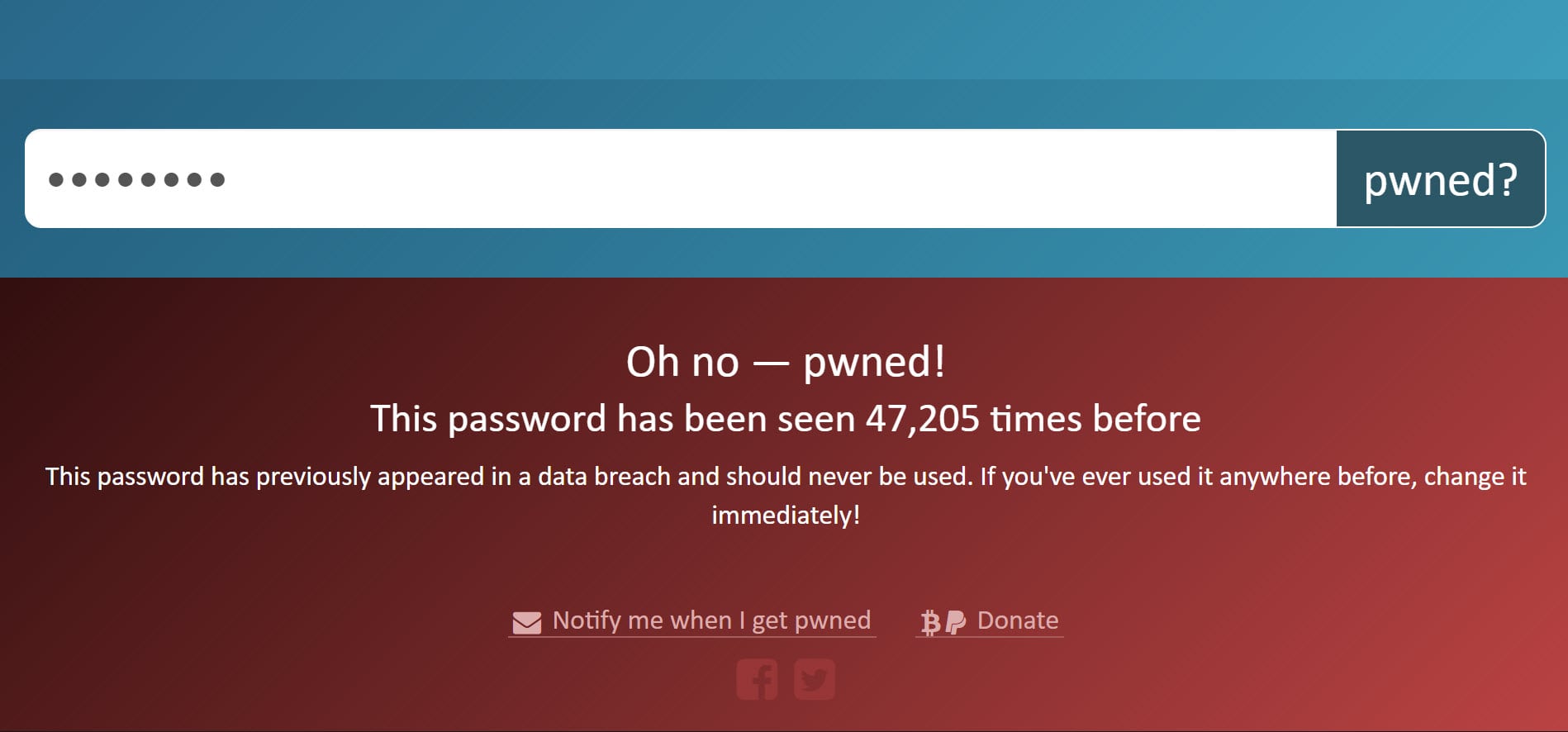
Pretty simple stuff and for the most part, also pretty familiar. But there's one really important - and really cool - difference. Let me explain:
Cloudflare, Privacy and k-Anonymity
In what proved to be very fortuitous timing, Junade Ali from Cloudflare reached out to me last month with an idea. They wanted to build a tool to search through Pwned Passwords V1 but to do so in a way that allowed external parties to use it and maintain anonymity. You see, the problem with my existing implementation was that whilst you could pass just a SHA-1 hash of the password, if it returned a hit and I was to take that and reverse it back to the clear (which I could easily do because I created the hashes in the first place!) I'd know the password. That made the service hard to justify sending real passwords to.
Junade's idea was different though; he proposed using a mathematical property called k-anonymity and within the scope of Pwned Passwords, it works like this: imagine if you wanted to check whether the password "P@ssw0rd" exists in the data set. (Incidentally, the hackers have worked out people do stuff like this. I know, it sucks. They're onto us.) The SHA-1 hash of that string is "21BD12DC183F740EE76F27B78EB39C8AD972A757" so what we're going to do is take just the first 5 characters, in this case that means "21BD1". That gets sent to the Pwned Passwords API and it responds with 475 hash suffixes (that is everything after "21BD1") and a count of how many times the original password has been seen. For example:
- (21BD1) 0018A45C4D1DEF81644B54AB7F969B88D65:1 (password "lauragpe")
- (21BD1) 00D4F6E8FA6EECAD2A3AA415EEC418D38EC:2 (password "alexguo029")
- (21BD1) 011053FD0102E94D6AE2F8B83D76FAF94F6:1 (password "BDnd9102")
- (21BD1) 012A7CA357541F0AC487871FEEC1891C49C:2 (password "melobie")
- (21BD1) 0136E006E24E7D152139815FB0FC6A50B15:2 (password "quvekyny")
- ...
I added the prefix in brackets beforehand and the source passwords in brackets afterwards simply to illustrate what we're doing here; they're all just different strings that hash down to values with the same first 5 characters. In other words, they're all within the same "range" and you'll see that term referenced more later on. Using this model, someone searching the data set just gets back the hash suffixes and counts (everything in bold after the first 5 chars) and they can then see if everything after the first 5 chars of their hash matches any of the returned strings. Now keep in mind that as far as I'm concerned, the partial hash I was sent could be any one of 475 different possible values. Or it could be something totally different, I simply don't know and therein lies the anonymity value.
For the sake of perspective, here are some stats on what this means for the data within Pwned Passwords:
- Every hash prefix from 00000 to FFFFF is populated with data (16^5 combinations)
- The average number of hashes returned is 478
- The smallest is 381 (hash prefixes "E0812" and "E613D")
- The largest is 584 (hash prefixes "00000" and "4A4E8")
Junade has written a great piece that's just gone live on Cloudflare's blog titled Validating Leaked Passwords with k-Anonymity and he goes into more depth in that piece. As he explains, there are other cryptographic approaches which could also address the desire for anonymity (for example, private set intersections), but not with the ease and level of simplicity Junade proposed. I loved it so much that I offered to build and run it as a service out of HIBP. Junade (and Cloudflare) thought that was a great idea so they offered to point folks over to the HIBP version rather than build out something totally separate. That's a partnership I'm enormously happy with I appreciate their confidence in my running it.
This model of anonymity is what now sits behind the online search feature. You can see it in action by trying a search for "P@ssw0rd" which will return the screen in the previous image. If we drop down and take a look at the dev tools, here's the actual request that's been made:

The password has been hashed client side and just the first 5 characters passed to the API (I'll talk more about the mechanics of that shortly). Here's what then comes back in the response:

As mentioned earlier, there are 475 hashes beginning with "21BD1", but only 1 which matches the remainder of the hash for "P@ssw0rd" and that record indicates that the password has previously been seen 47,205 times. And that's it - that's what I've done with Cloudflare's support and that's what we've done together to protect anonymity and make the service available to everyone. Let me now talk about how you can use the API.
Consuming the API (and the Mechanics Behind the Range Search)
The existing API documentation on HIBP has been updated so you can go there for all the implementation details. There are a few things in particular I want to call out though:
Firstly, you'll notice that I'm serving this API from a different domain to the other HIBP APIs and indeed from V1 of the Pwned Passwords service. For V2, I've stood up an Azure Function on the api.pwnedpasswords.com domain which gets the API out of the HIBP website and running on serverless infrastructure instead. I've written about Azure Functions in the past and they're an awesome way of building a highly scalable, resilient "code as a service" architecture. It ensures that load comes off the HIBP website and that I can scale the Pwned Passwords service infinitely, albeit with a line directly to my wallet! It's also given me the flexibility to do things like trim off a bunch of excessive headers such as the content security policy HIBP uses (that's of no use to a lone API endpoint).
Secondly, the existing API (that many people have created dependencies on!) still works just fine. Note: due to the success of the k-anonymity model, searching by password was discontinued on the 1st of June 2018. It also points to the storage repository for V2 of the password set so it's now searching through the full half billion records. I'll leave this running for the foreseeable future, but if you are using it then I'd prefer you roll over to the endpoint on api.pwnedpasswords.com for the reasons mentioned above, and for these other reasons:
If you were using the original API via HTTP GET, rolling over to the new one changes absolutely nothing in your implementation other than the URL which will look like this:
GET https://api.pwnedpasswords.com/pwnedpassword/{password}It'll still return HTTP 200 when a password is found and 404 when it's not. The only difference (and this shouldn't break any existing usages), is that the 200 response now also contains a count in the body by way of a single integer:
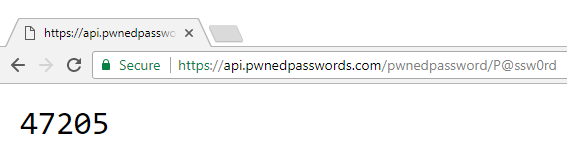
And as before, you can always pass a hash if preferred:

But, of course, we've just had the anonymity chat and you would have seen the path for calling that endpoint earlier on. Just to point it out again here, you can pass the first 5 chars of the hash to this address:
https://api.pwnedpasswords.com/range/{hashPrefix}Which returns a result like this:
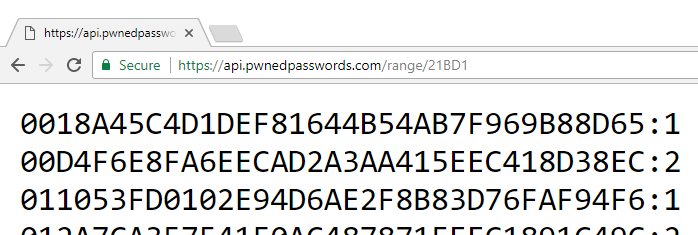
Remember, these are all hash suffixes (followed by a count) so the full value of the first hash, for example, is "21BD10018A45C4D1DEF81644B54AB7F969B88D65". Incidentally, input to the API is not case sensitive so "21bd1" works just as well as "21BD1". All hash suffixes returned (and indeed those provided in the downloadable data) are uppercase simply because that's the default output from SQL Server's HASHBYTES function (I processed the source data in a local RDBMS instance).
Unlike the original version, there's no rate-limiting. That was a construct I needed primarily to protect personal data in the breached account search (i.e. when you search for your email address amongst data breaches), but I extended it to Pwned Passwords as well to help protect the infrastructure. Now running on serverless Azure Functions, I don't have that concern so I've dropped it altogether. I'd also dropped version numbers, I'll deal with that when I need them which may not be for a long time (if ever).
Now, a few more things around some design decisions I've made: I'm very wary of the potential impact on my wallet of running the service this way. It's one thing to stand up V1 that only returned an HTTP response code, was rate-limited and really wasn't designed to be called in bulk by a single consumer (considering the privacy implications), it's quite another to do what I've done with V2, especially when each search of the range API returns hundreds of records. That "P@ssw0rd" search, for example, returns 9,730 bytes when gzipped (that's a pretty average size) and I'm paying for egress bandwidth out of Azure, the execution of the function and the call to the underlying storage. Tiny amounts each time, mind you, but I've had to reduce that impact on me as far as possible through a range of measures.
For example, the result of that range query is not a neatly formatted piece of JSON, it's just colon delimited rows. That impacts my ability to add attributes at a later date and pretty much locks in the current version to today's behaviour, but it saves on the response size. Yes, I know some curly braces and quotes wouldn't add a lot of size, but every byte counts when volumes get large.
You'll also notice there's a long max-age on the cache-control header:

This is 31 days' worth of cache and the subsequent Cloudflare cache status header explains why: by routing through their infrastructure, they can aggressively cache these results which ensures not only is the response lightning fast (remember, they presently have 121 edge nodes around the world so there's one near you), but that I don't wear the financial hit of people hammering my origin. Especially when you consider the extent to which multiple people use the same password, when we're talking about the range search where many different passwords have identical hash prefixes, there's some significant benefits to be had from caching. As mentioned earlier, there are 16^5 different hash prefixes (1,048,576) within the range of 00000 to FFFFF so you can see how extensive usage would benefit greatly from caching across many millions of searches. The performance difference alone when comparing a cached result with a non-cached one makes a compelling argument:

This means that even though the response is significantly larger than in V1, if I can serve a request to the new API from cache there's actually a massive improvement. Here's a series of hits to V1 where every single time, the request had to go all the way to the origin server, hit the API and then query 320M records:
In order to make aggressive caching feasible, I'm also only supporting HTTP GET. Now, some people will lose their minds over this because they'll say "that means it goes into logs and you'll track the passwords being searched for". If you're worried about me tracking anything, don't use the service. That's not intended to be a flippant statement, rather a simple acknowledgment that you need to trust the operator of the service if you're going to be sending passwords in any shape or form. Offsetting that is the whole k-Anonymity situation; even if you don't trust the service or you think logs may be leaked and abused (and incidentally, nothing is explicitly logged, they're transient system logs at most), the range search goes a very long way to protecting the source. If you still don't trust it, then just download the hashes and host them yourself. No really, that's the whole point of making them available and in all honesty, if it was me building on top of these hashes then I'd definitely be querying my own repository of them.
In summary, if you're using the range search then you get protection of the source password well in excess of what I was able to do in V1 plus it's massively faster if anyone else has done a search for any password that hashes down to the same first 5 characters of SHA-1. Plus, it helps me out an awful lot in terms of keeping the costs down!
Pwned Passwords in Action
Lastly, I want to call out a number of examples of the first generation of Pwned Passwords in action. My hope is that they inspire others to build on top of this data set and ultimately, make a positive difference to web security for everyone.
For example, Workbooks.com (they make CRM software, among other things) explains to customers that a Pwned Password is weak or has previously appeared in a data breach.
Then there's Colloq (they help you discover conferences) who've written up a great piece with loads of performance stats about their implementation of the data.
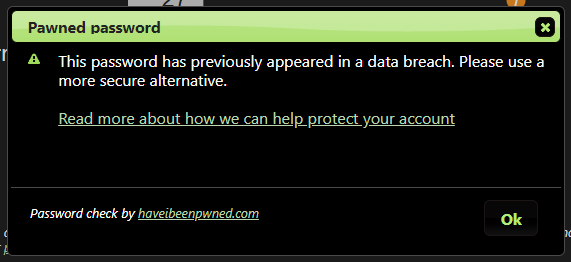
Or try creating an account on Toepoke with a password of "P@ssw0rd" and see how that goes for you:
safepass.me also picked up the data and wrapped it into an offline commercial Active Directory filter (plus a free home version).
On the mobile front, there's Pwned Pass in the Google Play store which sits on top of the existing API.
This is All Still Free (and I Still Like Beer!)
Nothing gains traction like free things! Keeping HIBP free to search your address (or your entire domain) was the best thing I ever did in terms of making it stick. A few months after I launched the service, I stood up a donations page where you could buy me some beers (or coffee or other things). It only went up after people specifically asked for it ("hey awesome service, can I get you a coffee?") and I've been really happy with the responses to it. As I say on the page, it's more the time commitment that really costs me (I'm independent so while I'm building something like Pwned Passwords, I'm not doing something else), but there are also costs that may surprise you:
Just burned through $100 of mobile data so that I could finish processing Pwned Passwords this weekend. 110kbps on unlimited broadband plan or 8,286kbps on 4G at $10/GB. It was going to be hard to get it live next week otherwise ?
— Troy Hunt (@troyhunt) February 17, 2018
This is one of those true "Australianisms" courtesy of the fact my up-speed maxes out at about 1.5Mbps (and is then shared across all the things in my house that send data out). Down-speed is about 114 but getting anything up is a nightmare. (And for Aussie friends, no, there's no NBN available in my area of the Gold Coast yet, but apparently it's not far off.) And no, this is not a solvable problem by doing everything in the cloud and there are many reasons why that wouldn't have worked (I'll blog them at a later date).
If you want to help kick in for these costs and shout me a sympathy coffee or beer(s), it's still very much appreciated!
Closing
Pwned Passwords V2 is now live! Everything you need to use them is over on the Pwned Passwords page of HIBP where you can check them online, learn about the API or just download the whole lot. All those models are free, unrestricted and don't even require attribution if you don't want to provide it, just take what's there and go do good things with it ?