Edit (1 day later): After posting this, the party responsible for leaking the data turned around and said "that was only a small part of it, here's the whole thing", and released records encompassing a further 14M records. I've added those into HIBP and will shortly be re-sending notifications to people monitoring domains as the count of impacted addresses will likely have changed. Everything else about the subsequent dataset is consistent with what you'll read below in terms of structure, patterns and conclusions.
The same threat actor has leaked larger amounts of data from LinkedIn dated 2023. They claim this new data contains 35M lines and is 12 GB uncompressed. They also issue an apology to @troyhunt. #Breach #Clearnet #DarkWeb #DarkWebInformer #Database #Leaks #Leaked #LinkedIn https://t.co/qBFAofvppU pic.twitter.com/Clg5o92b6t
— Dark Web Informer (@DarkWebInformer) November 7, 2023
I like to think of investigating data breaches as a sort of scientific search for truth. You start out with a theory (a set of data coming from an alleged source), but you don't have a vested interested in whether the claim is true or not, rather you follow the evidence and see where it leads. Verification that supports the alleged source is usually quite straightforward, but disproving a claim can be a rather time consuming exercise, especially when a dataset contains fragments of truth mixed in with data that is anything but. Which is what we have here today.
To lead with the conclusion and save you reading all the details if you're not inclined, the dataset so many people flagged me this week titled "Linkedin Database 2023 2.5 Millions" turned out to be a combination of publicly available LinkedIn profile data and 5.8M email addresses mostly fabricated from a combination of first and last name. It all began with this tweet:
A threat actor has allegedly leaked a database from LinkedIn @LinkedIn dated 2023. They claim the database shows emails, profile data, phones, full names, and more confidential info. #Breach #Clearnet #DarkWeb #DarkWebInformer #Database #Leaks #Leaked #LinkedIn pic.twitter.com/8MQecKc1vz
— Dark Web Informer (@DarkWebInformer) November 4, 2023
All good lies are believable at face value; is it feasible a massive corpus of LinkedIn data is floating around? Well, they were proper breached in 2012 to the tune of 164M records (by which I mean that incident was genuinely internal data such as email addresses and passwords extracted out by a vulnerability), then they were massively scraped in 2021 with another 126M records going into Have I Been Pwned (HIBP). So, when you see a claim like the one above, it seems highly feasible at face value which is what many people take it at. But I'm a bit more suspicious than most people 🙂
First, the claim:
This one is similar to my twitter data scrapped [sic] but for linkedin plus 2023
Now, there's a whole debate about whether scraped data is breached data and indeed whether the definition of it even matters. With the rising prevalence of scraped data, this topic came up enough that I wrote a dedicated blog post about it a couple of years ago and concluded the following in terms of how we should define the term "breach":
A data breach occurs when information is obtained by an unauthorised party in a fashion in which it was not intended to be made available
Which makes scrapes like this alleged one a breach. If indeed it was accurate, LinkedIn data had been taken and redistributed in a way it was never intended to be by either the service itself or the individuals whose data was in this corpus. So, it's something to take seriously, and that warranted further investigation.
I scrolled through the 10M+ rows of data (many records spanned multiple rows due to line returns), and my eyes fell on a fellow Aussie who for the purposes of this exercise we'll call "EM", being the initials of her first and last name. Whilst the data I'm going to refer to is either public by design or fabricated, I don't want to use a real person as an example without their consent so let's just play it safe. Here's a fragment of EM's record:
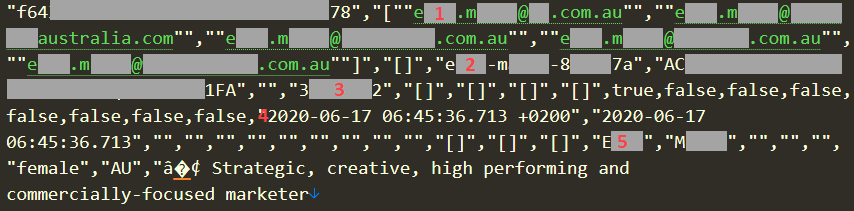
There are 5 noteworthy parts of this I that immediately caught my attention:
- There are 5 different email addresses here with the alias for each one represented in "[first name].[last name]@" form. These exist in a column titled "PROFILE_USERNAMES". (Incidentally, this is why the headline of 2.5M accounts expands out to 5.8M email addresses as there are often multiple addresses per account.)
- There's a LinkedIn profile ID in the form of "[first name]-[last name]-[random hexadecimal chars]" under a column titled "PROFILE_LINKEDIN_ID". That successfully loaded EM's legitimate profile at https://www.linkedin.com/in/[id]/
- The numeric value in the "PROFILE_LINKEDIN_MEMBER_ID" column matched with the value on EM's profile from the previous point.
- The 2 dates starting with "2020-" are in columns titled "PROFILE_FETCHED_AT" and "PROFILE_LINKEDIN_FETCHED_AT". I assume these are self-explanatory.
- EM's first and last name, precisely as it appears in each of her 5 email addresses.
On its own, this record would be unremarkable. It'd be entirely feasible - this could very well be legit - except when you keep looking through the remainder of the data. A pattern quickly emerged and I'm going to bold it here because it's the smoking gun that ultimately indicates that a bunch of this data is fake:
Every single record with multiple email addresses had exactly the same alias on completely unrelated domains and it was almost always in the form of "[first name].[last name]@".
Representing email addresses in this fashion is certainly common, but it's far from ubiquitous, and that's easy to demonstrate. For example, I have tons of emails from Pluralsight so I dig one out from my friend "CU":
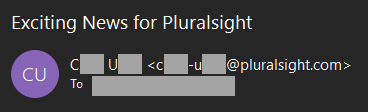
There's no dot, rather a dash. Every single real Pluralsight email address I looked at was a dash rather than a dot, yet when I delved into the alleged LinkedIn data and dig out another sample Pluralsight address, here's what I found:

That's not LM's real address because it has a dot instead of a dash. Every. Single. One. Is. Fake.
Let's try this the other way around and load up the existing breached accounts in HIBP for the domain of one of EM's alleged email addresses and see how they're formed:
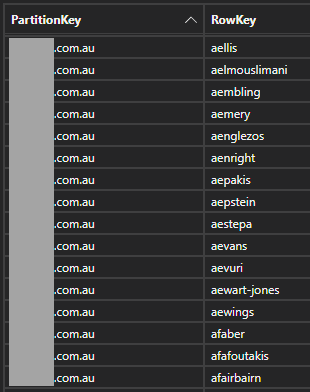
That's definitely not the same format as EM's address, not by a long shot. And time and time again, the same pattern of addresses in the corpus of data in the original tweet emerged, drawing me to what seems to be a pretty logical conclusion:
Each email address was fabricated by taking the actual domain of a company the individual legitimately worked at and then constructing the alias from their name.
And these are legitimate companies too because every single LinkedIn profile I checked had all the cues of accurate information and each domain I checked in the corpus of data was indeed the correct one for the company they worked at. I imagine someone has effectively worked through the following logic:
- Get a list of LinkedIn profiles whether that be by ID or username or simply parsing them out of crawler results
- Scrape the profiles and pull down legitimate information about each individual, including their employment history
- Resolve the domain for each company they worked at and construct the email addresses
- Profit?
On that final point, what is the point? The data wasn't being sold in that original tweet, rather it was freely downloadable. But per the date on EM's profile, the data could have been obtained much earlier and previously monetised. And on that, the date wasn't constant across records, rather there was a broad range of them as recent as July last year and as old as... well, I stopped when the records got older than me. What is this?!
I suspect the answer may partly lie in the column headings which I've pasted here in their entirety:
"PROFILE_KEY", "PROFILE_USERNAMES", "PROFILE_SPENDESK_IDS", "PROFILE_LINKEDIN_PUBLIC_IDENTIFIER", "PROFILE_LINKEDIN_ID", "PROFILE_SALES_NAVIGATOR_ID", "PROFILE_LINKEDIN_MEMBER_ID", "PROFILE_SALESFORCE_IDS", "PROFILE_AUTOPILOT_IDS", "PROFILE_PIPL_IDS", "PROFILE_HUBSPOT_IDS", "PROFILE_HAS_LINKEDIN_SOURCE", "PROFILE_HAS_SALES_NAVIGATOR_SOURCE", "PROFILE_HAS_SALESFORCE_SOURCE", "PROFILE_HAS_SPENDESK_SOURCE", "PROFILE_HAS_ASGARD_SOURCE", "PROFILE_HAS_AUTOPILOT_SOURCE", "PROFILE_HAS_PIPL_SOURCE", "PROFILE_HAS_HUBSPOT_SOURCE", "PROFILE_FETCHED_AT", "PROFILE_LINKEDIN_FETCHED_AT", "PROFILE_SALES_NAVIGATOR_FETCHED_AT", "PROFILE_SALESFORCE_FETCHED_AT", "PROFILE_SPENDESK_FETCHED_AT", "PROFILE_ASGARD_FETCHED_AT", "PROFILE_AUTOPILOT_FETCHED_AT", "PROFILE_PIPL_FETCHED_AT", "PROFILE_HUBSPOT_FETCHED_AT", "PROFILE_LINKEDIN_IS_NOT_FOUND", "PROFILE_SALES_NAVIGATOR_IS_NOT_FOUND", "PROFILE_EMAILS", "PROFILE_PERSONAL_EMAILS", "PROFILE_PHONES", "PROFILE_FIRST_NAME", "PROFILE_LAST_NAME", "PROFILE_TEAM", "PROFILE_HIERARCHY", "PROFILE_PERSONA", "PROFILE_GENDER", "PROFILE_COUNTRY_CODE", "PROFILE_SUMMARY", "PROFILE_INDUSTRY_NAME", "PROFILE_BIRTH_YEAR", "PROFILE_MARVIN_SEARCHES", "PROFILE_POSITION_STARTED_AT", "PROFILE_POSITION_TITLE", "PROFILE_POSITION_LOCATION", "PROFILE_POSITION_DESCRIPTION", "PROFILE_COMPANY_NAME", "PROFILE_COMPANY_LINKEDIN_ID", "PROFILE_COMPANY_LINKEDIN_UNIVERSAL_NAME", "PROFILE_COMPANY_SALESFORCE_ID", "PROFILE_COMPANY_SPENDESK_ID", "PROFILE_COMPANY_HUBSPOT_ID", "PROFILE_SKILLS", "PROFILE_LANGUAGES", "PROFILE_SCHOOLS", "PROFILE_EXTERNAL_SEARCHES", "PROFILE_LINKEDIN_HEADLINE", "PROFILE_LINKEDIN_LOCATION", "PROFILE_SALESFORCE_CREATED_AT", "PROFILE_SALESFORCE_STATUS", "PROFILE_SALESFORCE_LAST_ACTIVITY_AT", "PROFILE_SALESFORCE_OWNER_CONTACT_ID", "PROFILE_SALESFORCE_OWNER_CONTACT_NAME", "PROFILE_SPENDESK_SIGNUP_AT", "PROFILE_SPENDESK_DELETED_AT", "PROFILE_SPENDESK_ROLES", "PROFILE_SPENDESK_AVERAGE_NPS_SCORE", "PROFILE_SPENDESK_NPS_SCORES_COUNT", "PROFILE_SPENDESK_FIRST_NPS_SCORE", "PROFILE_SPENDESK_LAST_NPS_SCORE", "PROFILE_SPENDESK_LAST_NPS_SCORE_SENT_AT", "PROFILE_SPENDESK_PAYMENTS_COUNT", "PROFILE_SPENDESK_TOTAL_EUR_SPENT", "PROFILE_SPENDESK_ACTIVE_SUBSCRIPTIONS_COUNT", "PROFILE_SPENDESK_LAST_ACTIVITY_AT", "PROFILE_AUTOPILOT_MAIL_CLICKED_COUNT", "PROFILE_AUTOPILOT_LAST_MAIL_CLICKED_AT", "PROFILE_AUTOPILOT_MAIL_OPENED_COUNT", "PROFILE_AUTOPILOT_LAST_MAIL_OPENED_AT", "PROFILE_AUTOPILOT_MAIL_RECEIVED_COUNT", "PROFILE_AUTOPILOT_LAST_MAIL_RECEIVED_AT", "PROFILE_AUTOPILOT_MAIL_UNSUBSCRIBED_AT", "PROFILE_AUTOPILOT_MAIL_REPLIED_AT", "PROFILE_AUTOPILOT_LISTS", "PROFILE_AUTOPILOT_SEGMENTS", "PROFILE_HUBSPOT_CFO_CONNECT_SLACK_MEMBER_STATUS", "PROFILE_HUBSPOT_IS_CFO_CONNECT_MEETUPS_MEMBER", "PROFILE_HUBSPOT_CFO_CONNECT_AREAS_OF_EXPERTISE", "PROFILE_HUBSPOT_CORPORATE_FINANCE_EXPERIENCE_YEARS_RANGE"
Check out some of those names: LinkedIn is obviously there, but so is Salesforce and Spendesk and Hubspot, among others. This reads more like an aggregation of multiple sources than it does data solely scraped from LinkedIn. My hope is that in posting this someone might pop up and say "I recognise those column headings, they're from..." Who knows.
So, here's where that leaves us: this data is a combination of information sourced from public LinkedIn profiles, fabricated emails address and in part (anecdotally based on simply eyeballing the data this is a small part), the other sources in the column headings above. But the people are real, the companies are real, the domains are real and in many cases, the email addresses themselves are real. There are over 1.8k HIBP subscribers in the data set and this is folks that have double opted-in so they've successfully received an email to that address in the past. Further, when the data was loaded into HIBP there were nearly a million email addresses that were already in the system so evidently, they were addresses that had previously been in use. Which stands to reason because even if every address was constructed by an algorithm, the pattern is common enough that there'll be a bunch of hits.
Because the conclusion is that there's a significant component of legitimate data in this corpus, I've loaded it into HIBP. But because there are also a significant number of fabricated email addresses in there, I've flagged it as a spam list which means the addresses won't impact the scale of anyone's paid subscription if they're monitoring domains. And whilst I know some people will suggest it shouldn't go in at all, time and time again when I've polled the public about similar incidents the overwhelming majority of people have said "we want to know about it then we'll make up our own minds what action needs to be taken". And in this case, even if you find an email address on your domain that doesn't actually exist, that person who either currently works at your company or previously did has still had their personal data dumped in this corpus. That's something most people will still want to know.
Lastly, one of the main reasons I decided to invest hours into this today is that I loathe disinformation and I hate people using that to then make statements that are completely off base. I'm looking at my Twitter feed now and see people angry at LinkedIn for this, blaming an insider due to recent layoffs there, accusing them of mishandling our data and so on and so forth. No, not this time, the evidence has led us somewhere completely different.