
Cryptography is a fascinating component of computer systems. It’s one of those things which appears frequently (or at least should appear frequently), yet is often poorly understood and as a result, implemented badly.
Take a couple of recent high profile examples in the form of Gawker and rootkit.com. In both of these cases, data was encrypted yet it was ultimately exposed with what in retrospect, appears to be great ease.
The thing with both these cases is that their encryption implementations were done poorly. Yes, they could stand up and say “We encrypt our data”, but when the crunch came it turned out to be a pretty hollow statement. Then of course we have Sony Pictures where cryptography simply wasn’t implemented at all.
OWASP sets out to address poor cryptography implementations in part 7 of the Top 10 web application security risks. Let’s take a look at how this applies to .NET and what we need to do in order to implement cryptographic storage securely.
Defining insecure cryptographic storage
When OWASP talks about securely implementing cryptography, they’re not just talking about what form the persisted data takes, rather it encompasses the processes around the exercise of encrypting and decrypting data. For example, a very secure cryptographic storage implementation becomes worthless if interfaces are readily exposed which provide decrypted versions of the data. Likewise it’s essential that encryption keys are properly protected or again, the encrypted data itself suddenly becomes rather vulnerable.
Having said that, the OWASP summary keeps it quite succinct:
Many web applications do not properly protect sensitive data, such as credit cards, SSNs, and authentication credentials, with appropriate encryption or hashing. Attackers may steal or modify such weakly protected data to conduct identity theft, credit card fraud, or other crimes.
One thing the summary draws attention to which we’ll address very early in this piece is “encryption or hashing”. These are two different things although frequently grouped together under the one “encryption” heading.
Here’s how OWASP defines the vulnerability and impact:
| Threat Agents | Attack Vectors | Security Weakness | Technical Impacts | Business Impact | |
| Exploitability DIFFICULT | Prevalence UNCOMMON | Detectability DIFFICULT | Impact SEVERE | ||
| Consider the users of your system. Would they like to gain access to protected data they aren’t authorized for? What about internal administrators? | Attackers typically don’t break the crypto. They break something else, such as find keys, get clear text copies of data, or access data via channels that automatically decrypt. | The most common flaw in this area is simply not encrypting data that deserves encryption. When encryption is employed, unsafe key generation and storage, not rotating keys, and weak algorithm usage is common. Use of weak or unsalted hashes to protect passwords is also common. External attackers have difficulty detecting such flaws due to limited access. They usually must exploit something else first to gain the needed access. | Failure frequently compromises all data that should have been encrypted. Typically this information includes sensitive data such as health records, credentials, personal data, credit cards, etc. | Consider the business value of the lost data and impact to your reputation. What is your legal liability if this data is exposed? Also consider the damage to your reputation. | |
From here we can see a number of different crypto angles coming up: Is the right data encrypted? Are the keys protected? Is the source data exposed by interfaces? Is the hashing weak? This is showing us that as with the previous six posts in this series, the insecure crypto risk is far more than just a single discrete vulnerability; it’s a whole raft of practices that must be implemented securely if cryptographic storage is to be done well.
Disambiguation: encryption, hashing, salting
These three terms are thrown around a little interchangeably when in fact they all have totally unique, albeit related, purposes. Let’s establish the ground rules of what each one means before we begin applying them here.
Encryption is what most people are commonly referring to when using these terms but it is very specifically referring to transforming input text by way of an algorithm (or “cipher”) into an illegible format decipherable only to those who hold a suitable “key”. The output of the encryption process is commonly referred to as “ciphertext” upon which a decryption process can be applied (again, with a suitable key), in order to unlock the original input.
Hashing in cryptography is the process of creating a one-way digest of the input text such that it generates a fixed-length string that cannot be converted back to the original version. Repeating the hash process on the same input text will always produce the same output. In short, the input cannot be derived by inspecting the output of the process so it is unlike encryption in this regard.
Salting is a concept often related to hashing and it involves adding a random string to input text before the hashing process is executed. What this practice is trying to achieve is to add unpredictability to the hashing process such that the output is less regular and less vulnerable to a comparison of hashed common password against what is often referred to as a “rainbow table”. You’ll sometimes also see the salt referred to as a nonce (number used once).
Acronym soup: MD5, SHA, DES, AES
Now that encryption, hashing and salting are understood at a pretty high level, let’s move on to their implementations.
MD5 is a commonly found hashing algorithm. A shortfall of MD5 is that it’s not collision resistant in that it’s possible for two different input strings to produce the same hashed output using this algorithm. There have also been numerous discoveries which discredit the security and viability of the MD5 algorithm.
SHA is simply Secure Hash Algorithm, the purpose of which is pretty clear by its name. It comes in various flavours including SHA-0 through SHA-3, each representing an evolution of the hashing algorithm. These days it tends to be the most popular hashing algorithm (although not necessarily the most secure), and the one we’ll be referring to for implementation in ASP.NET.
DES stands for Data Encryption Standard and unlike the previous two acronyms, it has nothing to do with hashing. DES is a symmetric-key algorithm, a concept we’ll dig into a bit more shortly. Now going on 36 years old, DES is considered insecure and well and truly superseded, although that didn’t stop Gawker reportedly using it!
AES is Advanced Encryption Standard and is the successor to DES. It’s also one of the most commonly found encryption algorithm around today. As with the SHA hashing algorithm, AES is what we’ll be looking at inside ASP.NET. Incidentally, it was the AES implementation within ASP.NET which lead to the now infamous padding oracle vulnerability in September last year.
Symmetric encryption versus asymmetric encryption
The last concept we’ll tackle before actually getting into breaking some encryption is the concepts of symmetric-key and asymmetric-key (or “public key”) encryption. Put simply, symmetric encryption uses the same key to both encrypt and decrypt information. It’s a two-way algorithm; the same encryption algorithm can simply be applied in reverse to decrypt information. This is fine in circumstances where the end-to-end encryption and decryption process is handled in the one location such as where we may need to encrypt data before storing it then decrypt it before returning it to the user. So when all systems are under your control and you don’t actually need to know who encrypted the content, symmetric is just fine. Symmetric encryption is commonly implemented by the AES algorithm.
In asymmetric encryption we have different keys to encrypt and decrypt the data. The encryption key can be widely distributed (and hence known as a public-key), whilst the decryption key is kept private. We see asymmetric encryption on a daily basis in SSL implementations; browsers need access to the public-key in order to encrypt the message but only the server at the other end holds the private-key and consequently the ability to decrypt and read the message. So asymmetric encryption works just fine when we’re taking input from parties external to our own systems. Asymmetric encryption is commonly implemented via the RSA algorithm.
Anatomy of an insecure cryptographic storage attack
Let’s take a typical scenario: you’re building a web app which facilitates the creation of user accounts. Because you’re a conscientious developer you understand that passwords shouldn’t be stored in the database in plain text so you’re going to hash them first. Here’s how it looks:
Aesthetics aside, this is a pretty common scenario. However, it’s what’s behind the scenes that really count:
protected void SubmitButton_Click(object sender, EventArgs e) { var username = UsernameTextBox.Text; var sourcePassword = PasswordTextBox.Text; var passwordHash = GetMd5Hash(sourcePassword); CreateUser(username, passwordHash); ResultLabel.Text = "Created user " + username; UsernameTextBox.Text = string.Empty; PasswordTextBox.Text = string.Empty; }
Where the magic really happens (or more aptly, the “pain” as we’ll soon see), is in the GetMd5Hash function:
private static string GetMd5Hash(string input) { var hasher = MD5.Create(); var data = hasher.ComputeHash(Encoding.Default.GetBytes(input)); var builder = new StringBuilder();for (var i = 0; i < data.Length; i++)
{
builder.Append(data[i].ToString("x2"));
}return builder.ToString();
}
This is a perfectly valid MD5 hash function stolen directly off MSDN. I won’t delve into the CreateUser function referenced above, suffice to say it just plugs the username and hashed password directly into a database using your favourite ORM.
Let’s start making it interesting and generate a bunch of accounts. To make it as realistic as possible, I’m going to create 25 user accounts with usernames of “User[1-25]” and I’m going to use these 25 passwords:
123456, password, rootkit, 111111, 12345678, qwerty, 123456789, 123123, qwertyui, letmein, 12345, 1234, abc123, dvcfghyt, 0, r00tk1t, ìîñêâà, 1234567, 1234567890, 123, fuckyou, 11111111, master, aaaaaa, 1qaz2wsx
Why these 25? Because they’re the 25 most commonly used passwords as exposed by the recent rootkit.com attack. Here’s how the accounts look:
| Username | Password |
| User1 | 123456 |
| User2 | password |
| User3 | rootkit |
| User4 | 111111 |
| User5 | 12345678 |
| User6 | qwerty |
| User7 | 123456789 |
| User8 | 123123 |
| User9 | qwertyui |
| User10 | letmein |
| User11 | 12345 |
| User12 | 1234 |
| User13 | abc123 |
| User14 | dvcfghyt |
| User15 | 0 |
| User16 | r00tk1t |
| User17 | ìîñêâà |
| User18 | 1234567 |
| User19 | 1234567890 |
| User20 | 123 |
| User21 | fuckyou |
| User22 | 11111111 |
| User23 | master |
| User24 | aaaaaa |
| User25 | 1qaz2wsx |
So let’s create all these via the UI with nice MD5 hashes then take a look under the covers in the database:
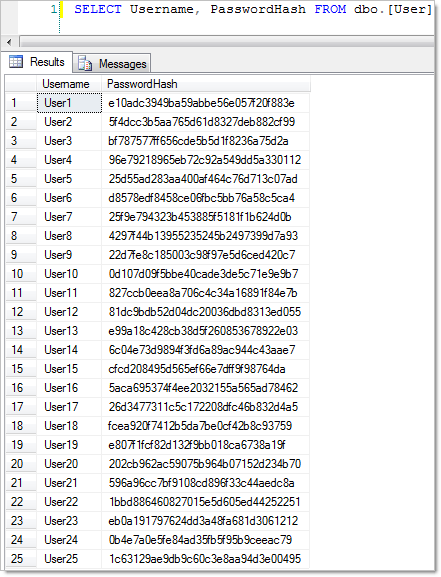
Pretty secure stuff huh? Well, no.
Now having said that, everything above is just fine while the database is kept secure and away from prying eyes. Where things start to go wrong is when it’s exposed and there’s any number of different ways this could happen. SQL injection attack, poorly protected backups, exposed SA account and on and on. Let’s now assume that this has happened and the attacker has the database of usernames and password hashes. Let’s save those hashes into a file called PasswordHashes.txt.
The problem with what we have above is that it’s vulnerable to attack by rainbow table (this sounds a lot friendlier than it really is). A rainbow table is a set of pre-computed hashes which in simple terms means that a bunch of (potential) passwords have already been passed through the MD5 hashing algorithm and are sitting there ready to be compared to the hashes in the database. It’s a little more complex than that with the hashes usually appearing in hash chains which significantly decrease the storage requirements. Actually, they’re stored along with the result of reduction functions but we’re diving into unnecessary detail now (you can always read more about in How Rainbow Tables Work).
Why use rainbow tables rather than just calculating the hashes on the fly? It’s what’s referred to as a time-memory trade-off in that it becomes more time efficient to load up a heap of pre-computed hashes into memory off the disk rather than to plug different strings into the hashing algorithm then compare the output directly to the password database. It costs more time upfront to create the rainbow tables but then comparison against the database is fast and it has the added benefit of being reusable across later cracking attempts.
There are a number of different ways of getting your hands on a rainbow table including downloading pre-computed ones and creating your own. In each instance, we need to remember that we’re talking about seriously large volumes of data which increase dramatically with the password entropy being tested for. A rainbow table of hashed four digit passwords is going to be miniscule in comparison to a rainbow table of up to eight character passwords with upper and lowercase letters and numbers.
For our purposes here today I’m going to be using RainbowCrack. It’s freely available and provides the functionality to both create your own rainbow table and then run them against the password database. In creating the rainbow table you can specify some password entropy parameters and in the name of time efficiency for demo purposes, I’m going to keep it fairly restricted. All the generated hashes will be based on password strings of between six and eight characters consisting of lowercase characters and numbers.
Now of course we already know the passwords in our database and it just so happens that 80% of them meet these criteria anyway. Were we really serious about cracking a typical database of passwords we’d be a lot more liberal in our password entropy assumptions but of course we’d also pay for it in terms of computational and disk capacity needs.
There are three steps to successfully using RainbowCrack, the first of which is to generate the rainbow tables. We’ll call rtgen with a bunch of parameters matching the password constraints we’ve defined and a few other black magic ones better explained in the tutorial:
rtgen md5 loweralpha-numeric 6 8 0 3800 33554432 0
The first thing you notice when generating the hashes is that the process is very CPU intensive:
In fact this is a good time to reflect on the fact that the availability of compute power is a fundamental factor in the efficiency of a brute force password cracking exercise. The more variations we can add to the password dictionary and greater the speed with which we can do it, the more likely we are to have success. In fact there’s a school of thought due to advances in quantum computing, the clock is ticking on encryption as we know it.
Back to RainbowCrack, the arduous process continues with updates around every 68 seconds:
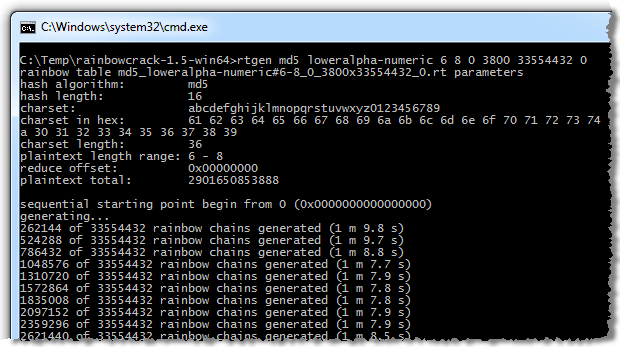
Let’s look at this for a moment – in this command we’re generating over thirty three and a half million rainbow chains at a rate of about 3,800 a second which means about two and a half hours all up. This is on a mere 1.6 GHz quad core i7 laptop – ok, not mere as a workhorse by today’s standard but for the purpose of large computational work it’s not exactly cutting edge.
Anyway, once the process is through we end up with a 512MB rainbow table sitting there on the file system. Now it needs a bit of “post-processing” which RainbowCrack refers to as a sorting process so we fire up the following command:
rtsort md5_loweralpha-numeric#6-8_0_3800x33554432_0.rt
This one is a quickie and it executes in a matter of seconds.
But wait – there’s more! The rainbow table we generated then sorted was only for table and part index of zero (the fifth and eight parameters in the rtgen command related to the reduce function). We’ll do another five table generations with incrementing table indexes (this all starts to get very mathematical, have a read of Making a Faster Cryptanalytic Time-Memory Trade-Off if you really want to delve into it). If we don’t do this, the range of discoverable password hashes will be very small.
For the sake of time, we’ll leave the part indexes and accept we’re not going to be able to break all the passwords in this demo. If you take a look at a typical command set for lower alphanumeric rainbow tables, you’ll see why we’re going to keep this a bit succinct.
Let’s put the following into a batch file, set it running then sleep on it:
rtgen md5 loweralpha-numeric 6 8 1 3800 33554432 0 rtgen md5 loweralpha-numeric 6 8 2 3800 33554432 0 rtgen md5 loweralpha-numeric 6 8 3 3800 33554432 0 rtgen md5 loweralpha-numeric 6 8 4 3800 33554432 0 rtgen md5 loweralpha-numeric 6 8 5 3800 33554432 0rtsort md5_loweralpha-numeric#6-8_1_3800x33554432_0.rt
rtsort md5_loweralpha-numeric#6-8_2_3800x33554432_0.rt
rtsort md5_loweralpha-numeric#6-8_3_3800x33554432_0.rt
rtsort md5_loweralpha-numeric#6-8_4_3800x33554432_0.rt
rtsort md5_loweralpha-numeric#6-8_5_3800x33554432_0.rt
Sometime the following day…
Now for the fun bit – actually “cracking” the passwords from the database. Of course what we mean by this term is really just that we’re going to match the hashes against the rainbow tables, but that doesn’t sound quite as interesting.
This time I’m going to fire up rcrack_gui.exe and get a bit more graphical for a change. We’ll start up by loading our existing hashes from the PasswordHashes.txt file:
Doing this will give us all the existing hashes loaded up but as yet, without the plaintext equivalents:
In order to actually resolve the hashes to plain text, we’ll need to load up the rainbow tables as well so let’s just grab everything in the directory where we created them earlier:
As soon as we do this RainbowCrack begins processing. And after a short while:
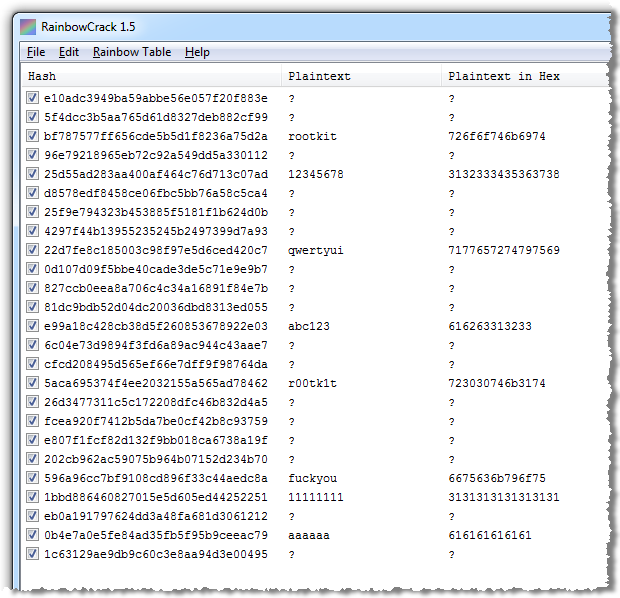
Now it’s getting interesting! RainbowCrack successfully managed to resolve eight of the password hashes to their plaintext equivalents. We could have achieved a much higher number closer to or equal to 20 had we computed more tables with wider character sets, length ranges and different part indexes (they actually talk about a 99.9% success rate), but after 15 hours of generating rainbow tables, I think the results so far are sufficient. The point has been made; the hashed passwords are vulnerable to rainbow tables.
Here are the stats of the crack:
plaintext found: 8 of 25
total time: 70.43 s
time of chain traverse: 68.52 s
time of alarm check: 1.19 s
time of wait: 0.00 s
time of other operation: 0.73 s
time of disk read: 9.72 s
hash & reduce calculation of chain traverse: 858727800
hash & reduce calculation of alarm check: 12114933
number of alarm: 9633
speed of chain traverse: 12.53 million/s
speed of alarm check: 10.20 million/s
This shows the real power of rainbow tables; yes, it took 15 hours to generate them in the first place but then we were moving through over twelve and a half million chains a second. But we’ve still only got hashes and some plain text equivalents, let’s suck the results back into the database and join them all up:
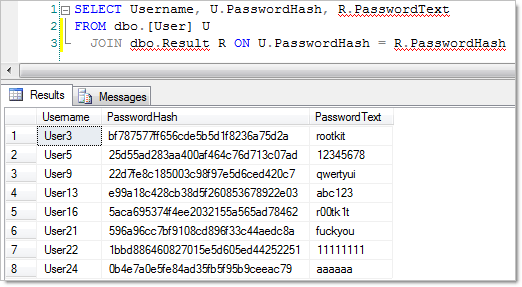
Bingo. Hashed passwords successfully compromised.
What made this possible?
The problem with the original code above was that it was just a single, direct hash of the password which made it predictable. You see, an MD5 hash of a string is always an MD5 hash of a string. There’s no key used in the algorithm to vary the output and it doesn’t matter where the hash is generated. As such, it left us vulnerable to having our hashes compared against a large set with plain text equivalents which in this case was our rainbow tables.
You might say “Yes, but this only worked because there were obviously other systems which failed in order to first disclose the database”, and you’d be right. RainbowCrack is only any good once there have been a series of other failures resulting in data disclosure. The thing is though, it’s not an uncommon occurrence. I mentioned rootkit.com earlier on and it’s perfectly analogous to the example above as the accounts were just straight MD5 hashes with no salt. Reportedly, 44% of the accounts were cracked using a dictionary of about 10 M entries in less than 5 minutes. But there have also been other significant braches of a similar nature; Gawker late last year was another big one and then there’s the mother of all customer disclosures, Sony (we’re getting somewhere near 100 million accounts exposed across numerous breaches now).
The point is that breaches happen and the role of security in software is to apply layered defences. You don’t just apply security principles at one point; you layer them throughout the design so that the compromise of one or two vulnerabilities doesn’t bring the whole damn show crashing down.
Getting back to our hashes, what we needed to do was to add some unpredictability to the output of the hash process. After all, the exploit only worked because we knew what to look for in that we could compare the database to pre-computed hashes.
Salting your hashes
Think of a salt as just a random piece of data. Now, if we combine that random piece of data with the password before the password is hashed we’ll end up with a significantly higher degree of variability in the output of the hashing process. But if we just defined the one salt then reused it for all users an attacker could simply regenerate the rainbow tables with the single salt included with each plaintext string before hashing.
What we really need is a random salt which is different for every single user. Of course if we take this approach we also need to know what salt was used for what user otherwise we’ll have no way of recreating the same hash when the user logs on. What this means is that the salt has to sit in the database with the hashed password and the username.
Now, before you start thinking “Hey, this sounds kind of risky”, remember that because the salt is different for each user, if you wanted to start creating rainbow tables you’d need to repeat the entire process for every single account. It’s no longer possible to simply take a hashed password list and run it through a tool like RainbowCrack, at least not within a reasonable timeframe.
So what does this change code wise? Well, the first thing is that we need a mechanism of generating some cryptographically strong random bytes to create our salt:
private static string CreateSalt(int size)
{
var rng = new RNGCryptoServiceProvider();
var buff = new byte[size];
rng.GetBytes(buff);
return Convert.ToBase64String(buff);
}
We’ll also want to go back to the original hashing function and make sure it takes the salt and appends it to the password before actually creating the hash:
private static string GetMd5Hash(string input, string salt)
{
var hasher = MD5.Create();
var data = hasher.ComputeHash(Encoding.Default.GetBytes(input + salt));
var builder = new StringBuilder();for (var i = 0; i < data.Length; i++)
{
builder.Append(data[i].ToString("x2"));
}return builder.ToString();
}
Don’t fly off the handle about using MD5 just yet – read on!
In terms of tying it all together, the earlier button click event needs to create the salt (we’ll make it 8 bytes), pass it to the hashing function and also pass it over to the method which is going to save the user to the data layer (remember we need to store the salt):
var username = UsernameTextBox.Text;
var sourcePassword = PasswordTextBox.Text;
var salt = CreateSalt(8);
var passwordHash = GetMd5Hash(sourcePassword, salt);
CreateUser(username, passwordHash, salt);
Now let’s recreate all those original user accounts and see how the database looks:

Excellent, now we have passwords hashed with a salt and the salt itself ready to recreate the process when a user logs on. Now let’s try dumping this into a text file and running RainbowCrack against it:

Ah, that’s better! Not one single password hash matched to the rainbow table. Of course there’s no way there could have been a match (short of a hash collision); the source text was completely randomised via the salt. Just to prove the point, let’s create two new users and call them “Same1” and “Same2”, both with a password of “Passw0rd”. Here’s how they look:

Totally different salts and consequently, totally different password hashes. Perfect.
About the only thing we haven’t really touched on is the logon process for reasons explained in the next section. Suffice to say the logon method will simply pull back the appropriate record for the provided username then send the password entered by the user back to the GetMd5Hash function along with the salt. If the return value from that function matches the password hash in the database, logon is successful.
But why did I use MD5 for all this? Hasn’t it been discredited over and again? Yes, and were we to be serious about this we’d use SHA (at the very least), but in terms of demonstrating the vulnerability of non-salted hashes and the use of rainbow tables to break them, it’s all pretty much of a muchness. If you were going to manage the salting and hashing process yourself, it would simply be a matter of substituting the MD5 reference for SHA.
But even SHA has its problems, one of them being that it’s too fast. Now this sounds like an odd “problem”, don’t we always want computational processes to be as fast as possible? The problem with speed in hashing processes is that the faster you can hash, the faster you can run a brute force attack on a hashed database. In this case, latency can actually be desirable; speed is exactly what you don’t want in a password hash function. The problem is that access to fast processing is getting easier and easier which means you end up with situations like Amazon EC2 providing the perfect hash cracking platform for less than a cup of coffee.
You don’t want the logon process to grind to halt, but the difference between a hash computation going from 3 milliseconds to 300 milliseconds, for example, won’t be noticed by the end user but has a 100 fold impact on the duration required to resolve the hash to plain text. This is one of the attractive attributes of bcrypt in that it uses the computationally expensive Blowfish algorithm.
But of course latency can always be added to hashing process of other algorithms simply by iterating the hash. Rather than just passing the source string in, hashing it and storing the output in the database, iterative hashing repeats the process – and consequently the latency - many times over. Often this will be referred to as key stretching in that it effectively increases the amount of time required to brute force the hashed value.
Just one final comment now that we have a reasonable understanding of what’s involved in password hashing: You know those password reminder services which send you your password when you forget it? Or those banks or airlines where the operator will read your password to you over the phone (hopefully after ascertaining your identity)? Clearly there’s no hashing going on there. At best your password is encrypted but in all likelihood it’s just sitting there in plain text. One thing is for sure though, it hasn’t been properly hashed.
Using the ASP.NET membership provider
Now that we’ve established how to create properly salted hashes in a web app yourself, don’t do it! The reason for this is simple and it’s that Microsoft have already done the hard work for us and given us the membership provider in ASP.NET. The thing about the membership provider is that it doesn’t just salt and hash your passwords for you but rather its part of a much richer ecosystem to support registration and account management in ASP.NET.
The other thing about the membership provider is that it plays very nice with some of the native ASP.NET controls that are already baked into the framework. For example:
Between the provider and the controls, account functionality like password resets (note: not “password retrieval”!), minimum password criteria, password changes, account lockout after subsequent failed attempts, secret question and answer and a few other bits and pieces are all supported right out of the box. In fact it’s so easy to configure you can have the whole thing up and running within 5 minutes including the password cryptography done right.
The fastest way to get up and running is to start with a brand new ASP.NET Web Application:
Now we just create a new SQL database then run aspnet_regsql from the Visual Studio Command Prompt. This fires up the setup wizard which allows you to specify the server, database and credentials which will be used to create a bunch of DB objects:
If we now take a look in the database we can see a bunch of new tables:
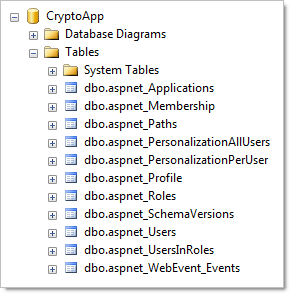
And a whole heap of new stored procedures (no fancy ORMs here):
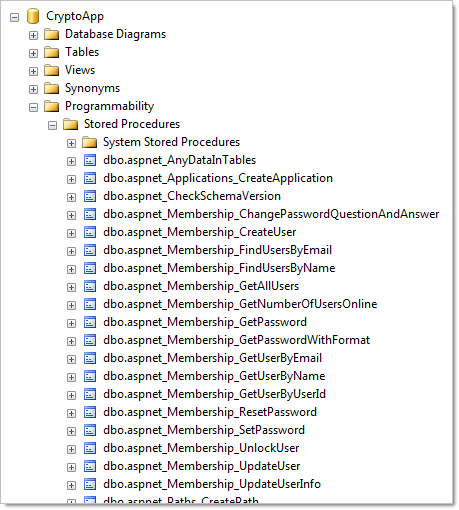
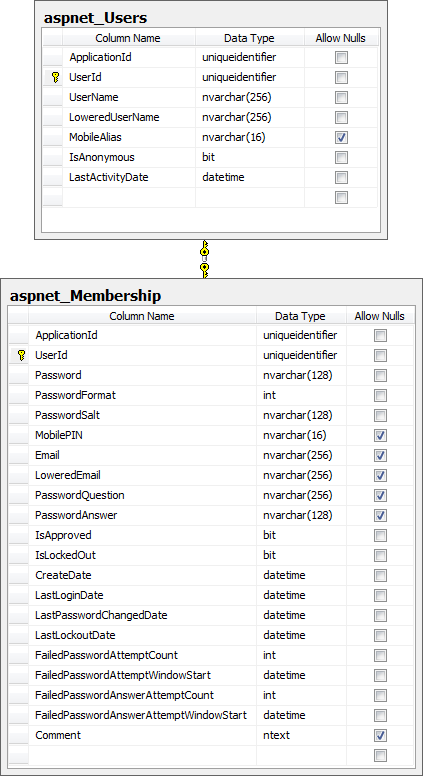
You can tell just by looking at both the tables and procedures that a lot of typical account management functionality is already built in (creating users, resetting passwords, etc.) The nuts and bolts of the actual user accounts can be found in the aspnet_Users and aspnet_Membership tables:
The only thing left to do is to point our new web app at the database by configuring the connection string named “ApplicationServices” then give it a run. On the login page we’ll find a link to register and create a new account. Let’s fill in some typical info:
The whole point of this exercise was to demonstrate how the membership provider handles cryptographic storage of the password so let’s take a look into the two tables we mentioned earlier:
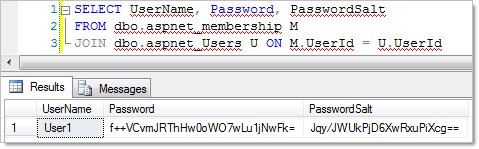
So there we go, a username stored along with a hashed password and the corresponding salt and not a single line of code written to do it! And by default its hashed using SHA1 too so no concern about poor old MD5 (it can be changed to more secure SHA variants if desired).
There are two really important points to be made in this section: Firstly, you can save yourself a heap of work by leveraging the native functionality within .NET and the provider model gives you loads of extensibility if you want to extend the behaviour to bespoke requirements. Secondly, when it comes to security, the more stuff you can pull straight out of the .NET framework and avoid rolling yourself, the better. There’s just too much scope for error and unless you’re really confident with what you’re doing and have strong reasons why the membership provider can’t do the job, stick with it.
Edit: With the passing of time, this is proving to be an insufficiently secure approach. Read my posts on Our password hashing has no clothes and Stronger password hashing in .NET with Microsoft’s universal providers for more information.
Encrypting and decrypting
Hashing is just great for managing passwords, but what happens when we actually need to get the data back out again? What happens, for example, when we want to store sensitive data in a secure persistent fashion but need to be able to pull it back out again when we want to view it?
We’re now moving into the symmetric encryption realm and the most commonly used mechanism of implementing this within .NET is AES. There are other symmetric algorithms such as DES, but over time this has been proven to be quite weak so we’ll steer away from this here. AES is really pretty straight forward:
Ok, all jokes aside, the details of the AES implementation (or other cryptographic implementations for that matter), isn’t really the point. For us developers, it’s more about understanding which algorithms are considered strong and how to appropriately apply them.
Whilst the above image is still front of mind, here’s one really essential little piece of advice: don’t even think about writing your own crypto algorithm. Seriously, this is a very complex piece of work and there are very few places which would require – and indeed very few people who would be capable of competently writing – a bespoke algorithm. Chances are you’ll end up with something only partially effective at best.
When it comes to symmetric encryption, there are two important factors we need in order to encrypt then decrypt:
- An encryption key. Because this is symmetric encryption we’ll be using the same key for data going in and data coming out. Just like the key to your house, we want to look after this guy and keep it stored safely (more on that shortly).
- An initialisation vector, also known as an IV. The IV is a random piece of data used in combination with the key to both encrypt and decrypt the data. It’s regenerated for each piece of encrypted data and it needs to be stored with the output of the process in order to turn it back into something comprehensible.
If we’re going to go down the AES path we’re going to need at least a 128 bit key and to keep things easy, we’ll generate it from a salted password. We’ll need to store the password and salt (we’ll come back to how to do that securely), but once we have these, generating the key and IV is easy:
private void GetKeyAndIVFromPasswordAndSalt(string password, byte[] salt, SymmetricAlgorithm symmetricAlgorithm, ref byte[] key, ref byte[] iv) { var rfc2898DeriveBytes = new Rfc2898DeriveBytes(password, salt); key = rfc2898DeriveBytes.GetBytes(symmetricAlgorithm.KeySize / 8); iv = rfc2898DeriveBytes.GetBytes(symmetricAlgorithm.BlockSize / 8); }
Once we have the key and the IV, we can use the RijndaelManaged class to encrypt the string and bring back a byte array:
static byte[] Encrypt(string clearText, byte[] key, byte[] iv) { var clearTextBytes = Encoding.Default.GetBytes(clearText); var rijndael = new RijndaelManaged(); var transform = rijndael.CreateEncryptor(key, iv); var outputStream = new MemoryStream(); var inputStream = new CryptoStream(outputStream, transform, CryptoStreamMode.Write); inputStream.Write(clearTextBytes, 0, clearText.Length); inputStream.FlushFinalBlock(); return outputStream.ToArray(); }
And then a similar process in reverse:
static string Decrypt(byte[] cipherText, byte[] key, byte[] iv) { var rijndael = new RijndaelManaged(); var transform = rijndael.CreateDecryptor(key, iv); var outputStream = new MemoryStream(); var inputStream = new CryptoStream(outputStream, transform, CryptoStreamMode.Write); inputStream.Write(cipherText, 0, cipherText.Length); inputStream.FlushFinalBlock(); var outputBytes = outputStream.ToArray(); return Encoding.Default.GetString(outputBytes); }
Just one quick point on the above: we wrote quite a bit of boilerplate code which can be abstracted away by using the Cryptography Application Block in the Enterprise Library. The application block doesn’t quite transforms the way cryptography is implemented, but it can make life a little easier and code a little more maintainable.
Let’s now tie it all together in a hypothetical implementation. Let’s imagine we need to store a driver’s license number for customers. Because it’s just a little proof of concept, we’ll enter the license in via a text box, encrypt it then use a little LINQ to SQL to save it then pull all the licenses back out, decrypt them and write them to the page. All in code behind on a button click event (hey – it’s a demo!):
protected void SubmitButton_Click(object sender, EventArgs e) { var key = new byte[16]; var iv = new byte[16]; var saltBytes = Encoding.Default.GetBytes(_salt); var algorithm = SymmetricAlgorithm.Create("AES"); GetKeyAndIVFromPasswordAndSalt(_password, saltBytes, algorithm, ref key, ref iv);var sourceString = InputStringTextBox.Text;
var ciphertext = Encrypt(sourceString, key, iv);var dc = new CryptoAppDataContext();
var customer = new Customer { EncLicenseNumber = ciphertext, IV = iv };
dc.Customers.InsertOnSubmit(customer);
dc.SubmitChanges();var customers = dc.Customers.Select(c =>
Decrypt(c.EncLicenseNumber.ToArray(), key, c.IV.ToArray()));
CustomerGrid.DataSource = customers;
CustomerGrid.DataBind();
}
The data layer looks like this (we already know the IV is always 16 bytes, we’ll assume the license ciphertext might be up to 32 bytes):

And here’s what we get in the UI:

So this gives us the full cycle; nice plain text input, AES encrypted ciphertext stored as binary data types in the database then a clean decryption back to the original string. But where does the “_password” value come from? This is where things get a bit tricky…
Key management
Here’s the sting in the encryption tail – looking after your keys. A fundamental component in the success of a cryptography scheme is being able to properly protect the keys, be that the single key for symmetric encryption or the private key for asymmetric encryption.
Before I come back to actual key management strategies, here are a few “encryption key 101” concepts:
- Keep keys unique. Some encryption attack mechanisms benefit from having greater volumes of data encrypted with the same key. Mixing up the keys is a good way to add some unpredictability to the process.
- Protect the keys. Once a key is disclosed, the data it protects can be considered as good as open.
- Always store keys away from the data. It probably goes without saying, but if the very piece of information which is required to unlock the encrypted data – the key – is conveniently located with the data itself, a data breach will likely expose even encrypted data.
- Keys should have a defined lifecycle. This includes specifying how they are generated, distributed, stored, used, replaced, updated (including any rekeying implications), revoked, deleted and expired.
Getting back to key management, the problem is simply that protecting keys in a fashion where they can’t easily be disclosed in a compromised environment is extremely tricky. Barry Dorrans, author of Beginning ASP.NET Security, summarised it very succinctly on Stack Overflow:
Key Management Systems get sold for large amounts of money by trusted vendors because solving the problem is hard.
So the usual ways of storing application configuration data go right out the window. You can’t drop them into the web.config (even if it’s encrypted as that’s easily reversed if access to the machine is gained), you can’t put them it in the database as then you’ve got the encrypted data and keys stored in the same location (big no-no), so what’s left?
There are a few options and to be honest, none of them are real pretty. In theory, keys should be protected in a “key vault” which is akin to a physical vault; big and strong with very limited access. One route is to use a certificate to encrypt the key then store it in the Windows Certificate Store. Unfortunately a full compromise of the machine will quickly bring this route undone.
Another popular approach is to skip the custom encryption implementation and key management altogether and just go direct to the Windows Data Protection API (DPAPI). This can cause some other dramas in terms of using the one key store for potentially multiple tenants in the same environment and you need to ensure the DPAPI key store is backed up on a regular basis. There is also some contention that reverse engineering of DPAPI is possible, although certainly this is not a trivial exercise.
But there’s a more practical angle to be considered when talking about encryption and it has absolutely nothing to do with algorithms, keys or ciphers and it’s simply this: if you don’t absolutely, positively need to hold data of a nature which requires cryptographic storage, don’t do it!
A pragmatic approach to encryption
Everything you’ve read so far is very much is very much along the lines of how cryptography can be applied in .NET. However there are two other very important, non-technical questions to answer; what needs to be protected and why it needs to be protected.
In terms of “what”, the best way to reduce the risk of data disclosure is simply not to have it in the first place. This may sound like a flippant statement, but quite often applications are found to be storing data they simply do not require. Every extra field adds both additional programming effort and additional risk. Is the customer’s birthdate really required? Is it absolutely necessary to persistently store their credit card details? And so on and so forth.
In terms of “why”, I’m talking about why a particular piece of data needs to be protected cryptographically and one of the best ways to look at this is by defining a threat model. I talked about threat models back in Part 2 about XSS where use case scenarios were mapped against the potential for untrusted data to cause damage. In a cryptography capacity, the dimensions change a little but the concept is the same.
One approach to determining the necessity of cryptographic storage is to map data attributes against the risks associated with disclosure, modification and loss then assess both the seriousness and likelihood. For example, here’s a mapping using a three point scale with one being low and three being high:
| Data object | Seriousness | Likelihood | Storage / cryptography method | ||||
|---|---|---|---|---|---|---|---|
| D | M | L | D | M | L | ||
| Authentication credentials | 3 | 2 | 1 | 2 | 1 | 1 | Plain text username, salted & hashed password |
| Credit card details | 3 | 1 | 1 | 2 | 2 | 1 | All symmetrically encrypted |
| Customer address | 2 | 2 | 2 | 2 | 1 | 1 | Plain text |
D = Disclosure, M = Modification, L = Loss
Disclosing a credit card is serious business but modifying or losing it is not quite as critical. Still, the disclosure impact is sufficient enough to warrant symmetric encryption even if the likelihood isn’t high (plus if you want to be anywhere neat PCI compliant, you don’t have a choice). A customer’s address, on the other hand, is not quite as serious although modification or loss may be more problematic than with a credit card. All in all, encryption may not be required but other protection mechanisms (such as a disaster recovery strategy), would be quite important.
These metrics are not necessarily going to be the same in every scenario, the intention is to suggest that there needs to be a process behind the election of data requiring cryptographic storage rather than the simple assumption that everything needs to a) be stored and b) have the overhead of cryptography thrown at it.
Whilst we’re talking about selective encryption, one very important concept is that the ability to decrypt persistent data via the application front end is constrained to a bare minimum. One thing you definitely don’t want to do is tie the encryption system to the access control system. For example, logging on with administrator privileges should not automatically provide access to decrypted content. Separate the two into autonomous sub-components of the system and apply the principle of least privilege enthusiastically.
Summary
The thing to remember with all of this is that ultimately, cryptographic storage is really the last line of defence. It’s all that’s left after many of the topics discussed in this series have already failed. But cryptography is also far from infallible and we’ve seen both a typical real world example of this and numerous other potential exploits where the development team could stand up and say “Yes, we have encryption!”, but in reality, it was done very poorly.
But of course even when implemented well, cryptography is by no means a guarantee that data is secure. When even the NSA is saying there’s no such thing as “secure” anymore, this becomes more an exercise of making a data breach increasingly difficult as opposed to making it impossible.
And really that’s the theme with this whole series; continue to introduce barriers to entry which whilst not absolute, do start to make the exercise of breaching a web application’s security system an insurmountable task. As the NSA has said, we can’t get “secure” but we can damn well try and get as close to it as possible.
Resources
- OWASP Cryptographic Storage Cheat Sheet
- Project RainbowCrack
- Enough With The Rainbow Tables: What You Need To Know About Secure Password Schemes