Over recent weeks, I've begun planning the release of the 3rd version of Pwned Passwords. If you cast your mind back, version 1 came along in August last year and contained 320M passwords. I made all the data downloadable as SHA-1 hashes (for reasons explained in that post) and stood up a basic API to enable anyone to query it by plain text password or hash. Then in Feb, version 2 landed and brought the password count up to just over half a billion whilst also adding a count to each password indicating how many times it had been seen. Far more significantly though, it introduced the k-anonymity search model that Cloudflare worked on and that's when things really took off. Only about 6 weeks ago, I wrote about some of the awesome use cases I was seeing and shared a couple of graphs; 37 million requests in the month to May 29 then 5.5M requests in a single day towards the end of that period. These days, however, things are very different - here's the last 24 hours at the time of writing:
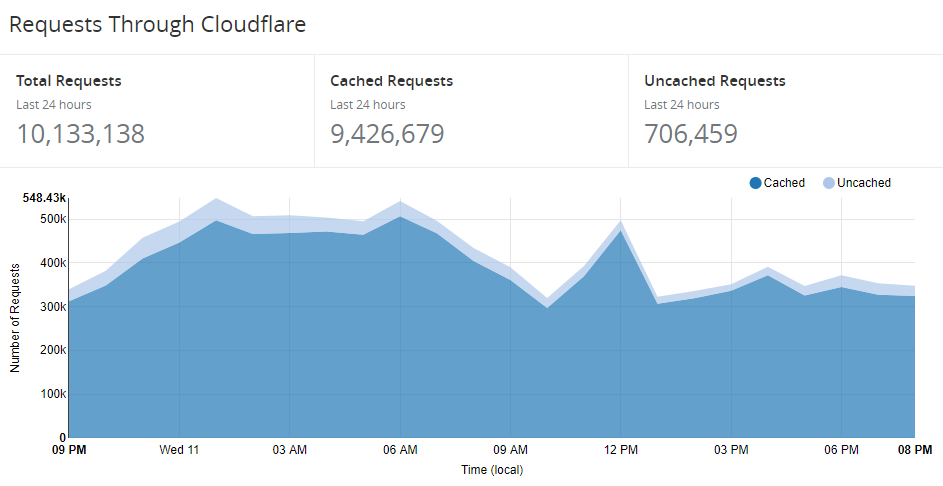
Only the day before I excitedly shared a new record that was more than 1 million requests lower than this graph. In short, the service is growing fast. (Incidentally, if you're wondering what this costs me to run it, I shared detailed numbers a couple of weeks ago.)
But inevitably the question arises - when will the next version land? I kept collecting plain text passwords as I processed data breaches with the thinking that I'd have a good sense of when the scale was sufficient to publish a V3. It's not a trivial task - crunching the data, updating the counts, dumping it into different formats, uploading tens of GBs (over Aussie internet...), preparing the torrents - so it was never going to happen regularly. Eventually, the catalyst came by virtue of the data I loaded 2 days ago in the 111 million Pemiblanc credential stuffing list. People wanted to see their passwords so they could better understand their exposure and I took the tried and tested stance of "I never store that information against your email address because of the risk it poses". But, of course, I do have the Pwned Passwords service which allows people to check their passwords whilst also retaining the anonymity of the secret itself.
So that's the background, let me now talk about what's in this release.
What's New?
We'll start with the raw numbers: in total, there are 517,238,891 passwords which is 15.6M more than in V2. That's only about just over a 3% increase but that number belies the sheer scale of additional data that's gone into this. In all, just the new V3 data had 194,092,745 total passwords in it, it's just that the vast majority of them were already in the system. This speaks to the prevalence of password reuse but also to the diminishing returns when loading new data; because there's already so many passwords in there, new breaches - even sizable ones - aren't adding many new ones.
The other thing that changes with V3 is the counts on the existing passwords. For example, the worst password in V2 was "123456" which had been seen 20,760,336 times. In V3, it's still the worst password (surprise, surprise), except the count has now been upped to 22,390,492 due to it being seen in the new breach corpuses.
Functionally, there are no breaking changes to the V3 API which was obviously pretty important given the extent of the existing dependencies. The size of the responses increases slightly, of course, but only by a few percent. The average hash range size goes from 478 to 493 but it's returned via super-efficient brotli compressed responses (or gzip if the client doesn't support br) and I highly doubt anyone will see any measurable difference there.
One addition I did make to the API is to add a Last-Modified header to each response. The primary reason for this is to help consumers of the service identify whether they've received a V2 response (the Last-Modified value will be in Feb) or a V3 response. That's important because of caching at both the Cloudflare level and in the client. Let's talk about that for a moment.
The Cache Situation
The reason my costs are so low for running this (and incidentally, there are absolutely zero commercial angles to Pwned Passwords) is due to a combination of the efficiency of Azure Functions and Cloudflare aggressively caching the responses. Here's the cache stats from the last 24 hours:
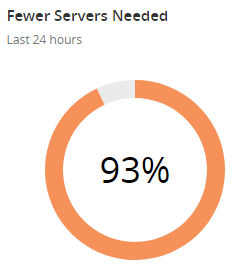
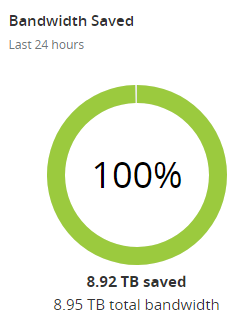
The reason the bandwidth saving rounds to "all of it" is because Cloudflare also caches the downloadable hashes which are big. Point being that they're taking a huge amount of traffic off the back end and were it not for them, I'd be seeing 14 times more requests hitting Azure. A big part of how I make that happen is with a 31-day cache expiry header, which brings us to the following problem:
Right after I push the button on this new set of data, I'm going to invalidate the Cloudflare cache which will immediately multiply my traffic 14x. It'll reduce quickly as requests start being returned from Cloudflare cache again, but I'm kinda curious about what my Azure charts are going to look like if I'm honest! I'll take a hit on the server, but at least that's within my control and it'll get the API returning fresh V3 results.
Clients are trickier because if someone has already done a search for a hash prefix (remember, that's what is being sent with k-anonymity), they may still see V2 results after V3 has already been flushed through the Cloudflare cache. Now frankly, when there's only 3% more data I'm not too worried and time will fix that problem anyway, but I'd be remiss if I didn't highlight it here. Or, of course, you can flush the cache for api.pwnedpasswords.com or use a different browser. My original plan had been to gradually reduce the cache period but I didn't anticipate the Pemiblanc data and the reaction regarding access to passwords. I should have.
Moving on, let me touch on the quality of data itself because that's also important to understand.
Control Characters and Data Integrity
One of the biggest problems in creating this resource is the quality of the source data. Not only am I talking about the way plain text passwords are stored in the original site (and yes, that still occurs with alarming regularity), but the way they're then dumped out by whoever breached that site. Then there's the large aggregation lists like Exploit.in, Antipublic and indeed the Pemiblanc list that prompted the V3 release; all of these have passwords cobbled together from many different sources and whoever has done that doesn't always have the most hygienic of data handling practices.
The next challenge is that I need to get my import process right. When I first grabbed the passwords out of the Pemiblanc data, I used SQL bcp wrapped in a PowerShell script to enumerate through all the files in the data set and extract the passwords which resulted in 50M ones not already in Pwned Passwords. However, it was only when doing manual verification of the data in preparation for the V3 release that I realised this import process had added control characters to the data set, namely tabs and carriage returns. Once I stripped those out, the unique passwords in that data set I hadn't seen before dropped all the way down to 3.3M. Still a significant number, but clearly much less than originally thought.
I spent a big chunk of yesterday working on the data quality and I'm confident V3 is in good shape. That's not to say there aren't passwords in there that might still contain some junk - there are - but it's a tiny slice of the overall data set and frankly, that doesn't matter. If, for example, 1% of the "passwords" contain junk (and I'm sure it's only a tiny fraction of that), the worst that can happen is either a password that was in a breach isn't found in Pwned Passwords (for example, because I imported a control character) or one that wasn't in a breach returns a hit anyway (for example, because the delimiting of the source data was off and I imported a rogue semicolon). But as soon as a password starts appearing in multiple incidents (i.e. it's a bad one), the chances of it being missed go way down to near zero anyway.
And while I'm talking about data quality, in V2 I inadvertently added trailing whitespace characters to the end of every line in the downloadable files. I later realised the sqlcmd utility pads the results unless the -W switch was present so V3 has included that and makes the data a little cleaner for those downloading the whole lot.
Checking Your Passwords in 1Password
As it specifically relates to the Pemiblanc situation, clearly people want to know if a password they've been using is in that data set. The easiest possible way I know of to do this is to use the Watchtower feature within 1Password to check your entire vault:
If you use 1Password account you now have a brand new Watchtower integrated with @haveibeenpwned API. Thank you, @troyhunt ❤️
— Roustem Karimov (@roustem) May 3, 2018
Also, looks like I have to update some passwords ? pic.twitter.com/toyyNRPI4h
This feature was built into 1Password 7 and is available on both the Mac and PC versions. It's a single-click to scan your entire vault of passwords and get a result like the one above.
Of course, this is predicated on being a 1Password user and if that's not you, you're pretty much down to checking them one-by-one via the Have I Been Pwned website or scripting out the checks against the API. And if you're not using a password manager at all and are worried about the Pemiblanc breach (or all the other ones), now seems like a perfect time to start using one!
Summary
So that's the V3 story and everything that's gone into making it what it is today. It's a much more incremental change than V2 was and I think that's reflective of the service now being in a pretty stable, steady state. As always, I welcome your comments below and I hope this background has been useful.