A race to the bottom is a market condition in which there is a surplus of a commodity relative to the demand for it. Often the term is used to describe labour conditions (workers versus jobs), and in simple supply and demand terms, once there's so much of something all vying for the attention of those consuming it, the value of it plummets.
On reflecting over the last 3 and a half weeks, this is where we seem to be with credential stuffing lists today and I want to use this blog post to explain the thinking whilst also addressing specific questions I've had regarding Collections #2 through #5.
The 773 Million Record "Collection #1" Data Breach
On Thursday 17 Jan, I loaded 773M records into Have I Been Pwned (HIBP) which I titled "Collection #1". I explained how this data originated from multiple different sources and was likely obtained over a period of many years before being amalgamated together and passed around as one massive stash. There were 2.7B rows of email addresses and passwords in total, but only 1.6B them were unique (my own identical record appeared half a dozen times). In other words, there was a huge amount of redundancy.
I made the call to load the data into HIBP based primarily on 3 facts:
- The data was sufficiently unique: more than 18% of the email addresses had not been seen in HIBP before
- The data was in broad circulation: multiple parties had contacted me and passed on Collection #1
- There was a large number of previously unseen passwords: of the 21M unique ones, half of them weren't already in HIBP's Pwned Passwords
Being conscious that there would be many questions about this data and that the origins and impact of it could be easily misrepresented, I carefully detailed every important fact. I pushed the blog post out on that Thursday morning my time and later that day, hopped on a plane to Europe. As the rest of world woke up to the story, all hell broke loose. I have never, ever received so many emails, tweets, blog comments and every other form of communication you can imagine in such a short period of time. I'd also never seen so much traffic on HIBP:
A week after the start of unprecedented traffic levels on @haveibeenpwned, I thought I'd share some stats on volumes and how everything performed, beginning with the total number of users to the site: pic.twitter.com/WAGzOTwNxx
— Troy Hunt (@troyhunt) January 24, 2019
I spent a significant part of the flight chewing through Emirates' bandwidth just responding to messages. I landed in Oslo, met friends and drove up into the mountains for a snowboarding trip with the flood of communications continuing. Jet lagged, overwhelmed by it all and frankly, just wanting downtime with good company, I turned on the out of office, closed comments on the blog post and almost completely stopped engaging on Twitter. (Side note: Scott Helme and I talked about burnout in my weekly update from London, in part due to the experiences I had dealing with the above.)
If I'm honest, that experience with the flood of communication coupled with disconnecting from life for a few days in a remote cabin with friends had a profound effect on me in many ways. I'm sure I'll talk more about them in future, but one was that I've very consciously reduced my engagement on email and Twitter frankly, to save my sanity. That's a bit tangential here though, back to Collection #1.
I'm frustrated about the hyperbole this incident managed to attract. The mass media picked it up with gusto and it made headlines all around the world in the most mainstream of publications. Inevitably, whether deliberately for the headlines or accidentally because it's simply not the world they live in, the truth was stretched time and time again. Despite my best efforts to report everything I knew with candour, things got out of control. For the most part I ignored this, only occasionally venting my frustration as someone brought it to the fore:
There were more than 3k words in that blog post detailing every single thing I knew about the data, what specifically do you think was missing?
— Troy Hunt (@troyhunt) January 25, 2019
Of course, there was nothing missing from the post and each time I asked the question it was met with silence. (Incidentally, Lorenzo who wrote that Motherboard piece is a top-notch infosec journo I've worked with many times before and he reported accurately in that piece.) I'm sharing this because I want to ensure that those who expressed their dismay at the way this story unfolded understand that it bugged the hell out of me too.
But I will say this: because this incident reached an unprecedented number of people and gained such worldwide traction, the impact of it on normal, everyday people's behaviour was significant. They learned about the phenomenon that is data breaches and credential stuffing lists, they read about password managers and 2FA and inevitably, many of them subsequently made behavioural changes to their security practices. Over-inflated headlines or not, the outcome of this on everyday consumers was positive.
The Other Collections
When I was originally contacted about Collection #1, that was the extent I knew of this series - that there was 1 collection. But very quickly it became apparent that it was merely the first of 5 collections and it was far from the biggest. Collection #1 was 87GB of data but collections #2 through #5 totalled another 845GB on top of that. Instead of the 2.7B rows from the Collection #1, the headlines were now talking about 25B which, admittedly, is quite the catchy title. Dozens of people reached out to me with links to the additional data and indeed, the media lapped up news of the larger collections as well. Inevitably, I got bombarded with questions about the subsequent collections:
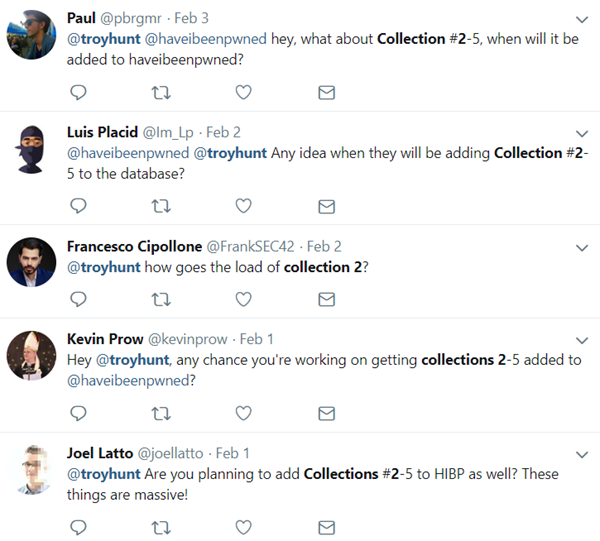
Keeping in mind my previous comments about overwhelming amounts of communication and workload, the thought of processing a 10x volume of data over Collection #1 wasn't exactly exciting me. Nevertheless, I grabbed the additional collections whilst travelling, flew home just over a week ago and began analysis. Before doing that, I had a working theory that the subsequent collections would be more of the same, but I wanted hard numbers on it so I began running the data against the existing 6.5B records in HIBP.
Spam, Spam, Spam Everywhere
Back when I originally began looking at Collection #1, one of the first things I did was to run a sample selection of email addresses against HIBP to get a sense of how many of them were unique. As mentioned earlier, it turned out to be just over 18% which was quite significant for such a large list. The very first thing I did with collections #2 through #5 was to choose slices of the data and check them against HIBP. This meant choosing a random file from amongst the 85k+ in the data, extracting all the email addresses then grabbing a random 100 sample and looking for uniqueness. After checking hundreds of files, here's when I found:
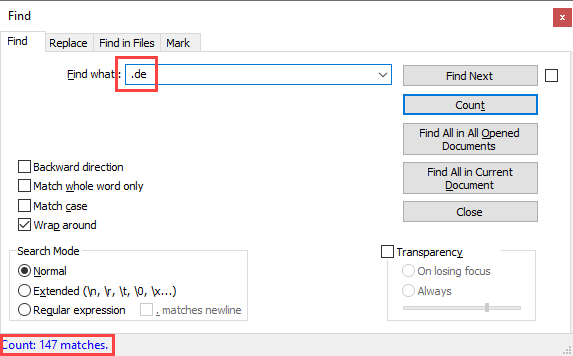
Tested 457 files, 280 were a 100% match
Tested 44,426 addresses, found 5,282 unique ones not already in HIBP, only 11.89 % uniqueFor the sake of transparency, I've published the complete output of this process which shows just how much crossover there is with existing data. As you scroll through that list, you'll see that over 61% of the files tested were a 100% match to HIBP; every single one of those random 100 email addresses tested was already in there. (Sidenote: after running the report, I realised that some of the source files didn't contain email addresses and as such reported "Of 0 random email addresses, 0 are already in HIBP". That's fine, but it skewed the 61% number down as the file was counted as not being an exact match.)
Some of these were quite predictable:
Collection #5\Collection #5\Dump HASH\www.babynames.com.txt
Of 100 random email addresses, 100 are already in HIBPThere's an easy explanation for that:
New breach: Baby Names had 846k records breached "at least 10 years ago" according to the operators of the site. The exposed data included email addresses and passwords stored as salted MD5 hashes. 86% were already in @haveibeenpwned https://t.co/LGaAniJH32
— Have I Been Pwned (@haveibeenpwned) October 24, 2018
Then there were files at the other end of the extreme:
Collection #5\Collection #5\EU combos\49.txt
Of 100 random email addresses, 1 are already in HIBPCurious, I took a closer look and found 100k rows heavily orientated towards Eastern European TLDs; over 20k .ua (Ukraine), another 10k .uz (Uzbekistan), 5k .kz (Kazakhstan) etc. I have no idea how many of these are actual addresses nor which breaches they originated from if they're indeed genuine, obviously there's nothing given away by the file name. The problem with all of this data (as with Collection #1), is that it's just about impossible to establish authenticity and a bunch of it is very likely not what it's represented to be.
Here's a perfect example: when running the check, one of the very first results I saw was this one:

It piqued my interest as it's an Aussie TLD for a site I'd never heard of yet apparently, 100% of the email addresses are already in HIBP. So I delved into the file and was immediately struck by the occurrence of a different TLD which, upon counting its occurrences across the 436-line file, showed a strangely high hit rate:
The file itself was then a combination of email addresses and SHA-1 hashes along with email addresses and then simply the number 1 after it. This is unusual as not only is there no consistency to the format, but it's also clearly comprised of different types of information.
During the course of the last week, I had a few chats with Vinny Troia of Night Lion Security. Vinny has supported HIBP in the past with data he's located floating around the web and we had a good discussion about the nature of these collections which he was also analysing. He also lamented the volume of garbage in them, pointing to examples such as this (the asterisks all represent the same 4-digit number):
"ddd-****01@yahoo.com","revoltec"
"ddd-****0@hotmail.fr","****0"
"ddd-****0@hotmail.fr","cats654"
"ddd-****0@hotmail.fr","cats654("
"ddd-****0@hotmail.fr","Cats654****0"
"ddd-****0@hotmail.fr","ddd-****0"
"ddd-****0@hotmail.fr","ddd****0"
"ddd-****0@hotmail.fr","revoltec"
"ddd****0@hotmail.fr","revoltec"
"ddd-****0@mail.ru","Cats654****0"
"ddd-****0@rambler.ru","Cats654****0"
"ddd-****0@yandex.ru","Cats654****0"
"ddd-****1@mail.ru","Cats654****0"
"ddd-****2@mail.ru","Cats654****0"
"ddd-****9@mail.ru","Cats654****0"Then there's my own data. I'd already found it in Collection #1 half a dozen times with an old throwaway password I had legitimately used many years ago. I noted it in the original blog post but didn't dig any further. This time, however, I probed deeper; I wanted context for the data.
Here it is in "Collection #2\Collection #2\DUMPS dehashed\thegioididong.com.txt"
I had to look up thegioididong.com in order to work out what it was. Turns out it's a Vietnamese e-commerce site selling phones so yeah, not exactly the sort of place I'd frequent.
And here it is in "Collection #5\DUMP dehashed\DropBox.com add pass.txt":
No, I've not screwed up the image, the file it's in is identical to the Vietnamese phone one. The password is identical too and firstly, under no circumstances did I ever use that password on Dropbox and secondly, the password I had in the Dropbox breach was randomly generated and exposed as a bcrypt hash I shared publicly when reporting on the breach.
So you see my point about "spam, spam, spam" - these collections are absolutely riddled with junk. That's not to say they don't contain legitimate usernames and passwords because quite clearly, some of them are, rather that the actual unique legitimate entries across all the collections is a small subset of what the headlines suggest.
It's a Very Deep Bottom
Following the events above, I received dozens of messages (maybe even hundreds, I honestly lost track) about other collections of credentials. Not collections represented as being part of the same series (i.e. Collection #6), but rather entirely separate sets of data. A few thousand here from a phishing page, a few hundred thousand over there in a public Google Doc, untold numbers more in pastes that HIBP may not have already indexed. I've seen a lot of breached data over a lot of years but even for me, I was honestly left a bit stunned by all of this. It. Just. Never. Ends.
A couple of days ago there was a story going around about yet another collection of data that began as follows:
A massive 600 gigabyte file containing about 2.2 billion compromised usernames and passwords has been spotted floating about the dark web, freely available to anyone who cares to download it via torrent.
As I've lamented before, stories of the dark web are frequently exaggerated and the reality is that huge volumes of data like this are socialised much more broadly "on the clear web" than the headlines suggest. For example:

I could go on with literally dozens of similar examples; a billion credentials here, another few billion there, many freely circulating and others costing inconsequential amounts of money:

And every time you think you've seen how deep the iceberg goes, you realise it's just another tip floating around a sea of our personal data:
/$$ /$$$$$$ /$$$$$$$ /$$$$$$ /$$ /$$ /$$$$$$ /$$$$$$ /$$ /$$
/$$$$ /$$__ $$ | $$__ $$|_ $$_/| $$ | $$ |_ $$_/ /$$__ $$| $$$ | $$
|_ $$ |__/ \ $$ | $$ \ $$ | $$ | $$ | $$ | $$ | $$ \ $$| $$$$| $$
| $$ /$$$$$/ | $$$$$$$ | $$ | $$ | $$ | $$ | $$ | $$| $$ $$ $$
| $$ |___ $$ | $$__ $$ | $$ | $$ | $$ | $$ | $$ | $$| $$ $$$$
| $$ /$$ \ $$ | $$ \ $$ | $$ | $$ | $$ | $$ | $$ | $$| $$\ $$$
/$$$$$$| $$$$$$/ | $$$$$$$/ /$$$$$$| $$$$$$$$| $$$$$$$$ /$$$$$$| $$$$$$/| $$ \ $$
|______/ \______/ |_______/ |______/|________/|________/|______/ \______/ |__/ \__/
/$$ /$$$$$$$$ /$$ /$$ /$$$$$$ /$$$$$$ /$$ /$$$$$$ /$$
/$$/| $$_____/| $$$ /$$$ /$$__ $$|_ $$_/| $$ /$$__ $$| $$
/$$/ | $$ | $$$$ /$$$$| $$ \ $$ | $$ | $$ | $$ \__/ \ $$
/$$/ | $$$$$ | $$ $$/$$ $$| $$$$$$$$ | $$ | $$ | $$$$$$ \ $$
/$$/ | $$__/ | $$ $$$| $$| $$__ $$ | $$ | $$ \____ $$ \ $$
/$$/ | $$ | $$\ $ | $$| $$ | $$ | $$ | $$ /$$ \ $$ \ $$
/$$/ | $$$$$$$$| $$ \/ | $$| $$ | $$ /$$$$$$| $$$$$$$$| $$$$$$/ \ $$
|__/ |________/|__/ |__/|__/ |__/|______/|________/ \______/ \__/ In case the ASCII art is lost on you, that's "13 BILLION /EMAILS\" in a readme file accompanied by an 88GB file containing that number of email and password pairs. It was about this time that the penny finally dropped in terms of just how comedic it was becoming to have numbers that seemed both artificially large and apparently there for shock value. It's like I'd seen this somewhere before...

All of this data in all of these locations has caused me to ask some pretty fundamental questions about the point of these lists as they relate to HIBP:
What's the point of loading billions after billions of email addresses from credential stuffing lists? What makes a new list worth adding to the 6.5B addresses already in HIBP? And if I'm going to be honest with myself, what's changed since I loaded Collection #1 that would cause me not to load subsequent lists?
The answer to the last question is a combination of the frenzy that first list created coupled with the emergence of untold numbers of other lists. What's changed is that there's way more data circulating than I've ever seen before and if I go loading all of that into HIBP, I fear the signal to noise ratio will go through the floor. Some people already felt that was the case with Collection #1 and whilst I still maintain loading that list was the right thing to do in the climate of the time, a constant stream of notifications about old incidents that have merely re-purposed the same data is quickly going to create a groundswell of unhappy subscribers.
Summary
Somehow, the Collection #1 incident turned into a feeding frenzy of media, breach traders, security firms and industry voices alike, all vying for a piece of the attention. Whilst there was undoubtedly value in the awareness it created, an increasing infatuation on which list is the largest or who's sitting on the largest stash of data is just downright counterproductive. It becomes a sideshow of superlative news headlines as the discussion turns to "who's is biggest" rather than "what should we actually be doing about this".
For now, I don't see subsequent lists like these going into HIBP unless there's something sufficiently unique about them. Users of the service have a pretty good idea by now where they've been exposed and what they should do about it, I want to keep focusing on the discrete incidents that are clearly attributable back to a source. Speaking of which:
New self-submitted breach: devkitPro had 1,508 accounts impacted in a data breach last week. Exposed data included email addresses, private messages and phpBB salted hashes. 79% were already in @haveibeenpwned. Read more: https://t.co/ZiUWZCGwd0
— Troy Hunt (@troyhunt) February 11, 2019