More than 3 years ago now, Scott Helme and I launched a little project called Why No HTTPS? It listed the world's largest websites that didn't properly redirect insecure requests to secure ones. We updated it December before last and pleasingly, noted that more websites than ever were doing the right thing and forcing browsers down the secure path. That's the good news, the bad news is that there are still some really wacky, unexplainable anti-HTTPS views out there, but those voices are increasingly less relevant as the browsers march forward:
Beginning in M94, Chrome will offer HTTPS-First Mode, which will attempt to upgrade all page loads to HTTPS and display a full-page warning before loading sites that don’t support it.
That's next month and whilst it will be opt-in, I've no doubt it's a glimpse into a future where browsers will do more by default to protect their users. Here's what a site that refuses to do HTTPS looks like in Chrome Canary with "Always use secure connections" turned on:
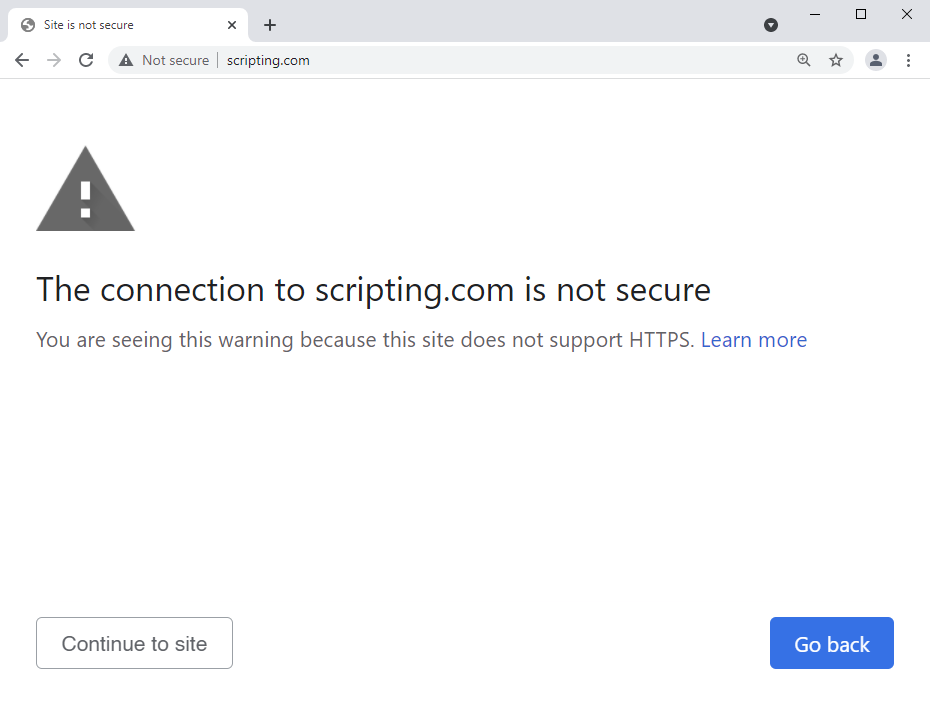
Those who push back with claims that Google is a guest on the web that's pointing a gun at it in a massive book-burning exercise that will destroy its history and it would be better to just send readers a zipped archive of websites (no, really, I'm not making this up!) will be increasingly marginalised as everyone else becomes increasingly secure 🙂
Moving on, let me give you a quick recap of where this data comes from and how to interpret the results.
Crawler.ninja
For some years now, Scott has run a service at crawler.ninja which does a nightly aggregation of various security aspects on the top million websites. He crawls the sites from a US IP address using request headers that emulate a common browser. The top million is defined by Tranco and Scott uses it to produce 2 other lists which drive this little project:
These lists don't add up to 1 million. There are various reasons for this, including that some sites simply won't respond to Scott's crawler. There are also sites that respond differently to Scott's crawler than they do to a normal web browser thus leading to inconsistent (and sometimes, unreproducible) results. This isn't an exact science not just because of gaps within the top million, but also because of how sites are assigned to countries. Let's drill down on that:
Country Mappings
This is a really, really imprecise approach but in short, it's a combination of TLD and Alexa definition. It's imprecise because of websites like Lush:
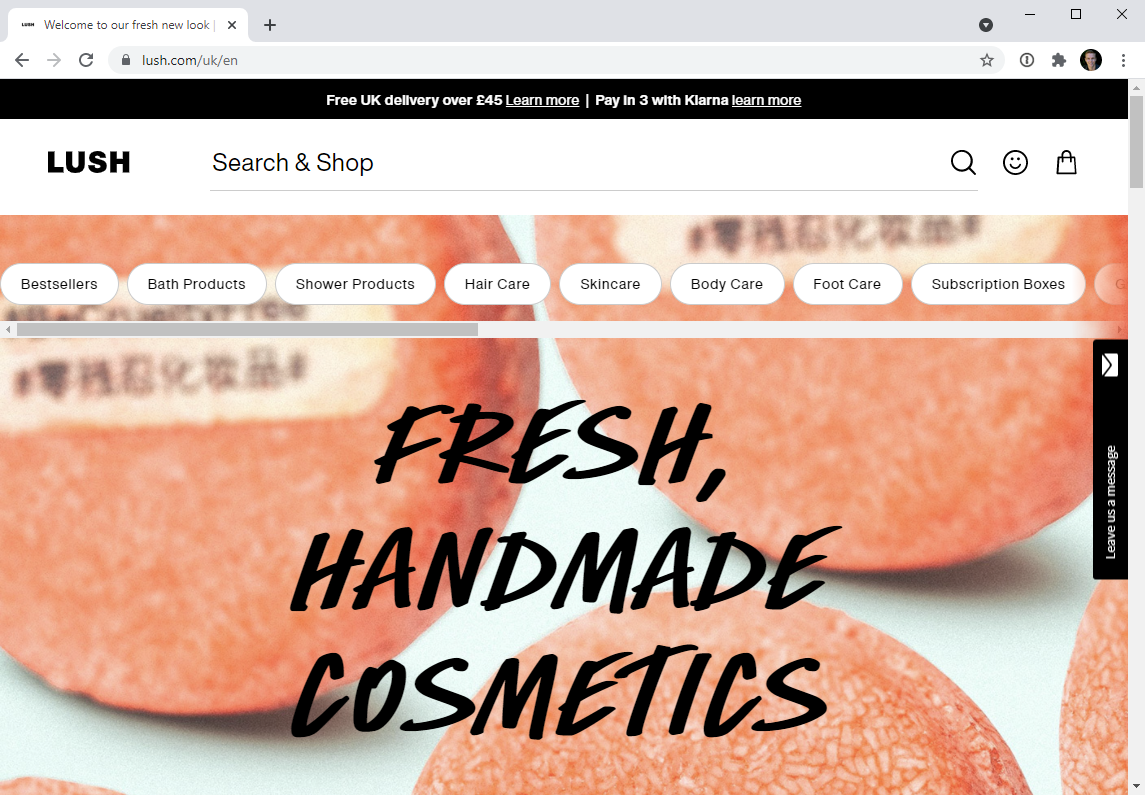
If I go to lush.com, I end up on a path which indicates I'm on the UK version and I see a price represented in GBP. Even though we have Lush in Australia, I'm seeing content obviously designed for the other side of the world. Hmmm... I wonder where Alexa says Lush is based, let's try this API: https://data.alexa.com/data?cli=10&url=lush.com
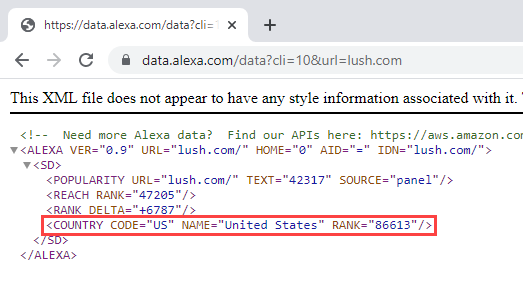
Huh, it's American. So I fire up Nord VPN and exit through a US node in an incognito window and I get... exactly the same UK page. But hey, why is Lush here in the first place when we're seeing a padlock in the browser? Let's drill down:
(Perceived) False Positives
Here's what happens when I cURL http://lush.com:
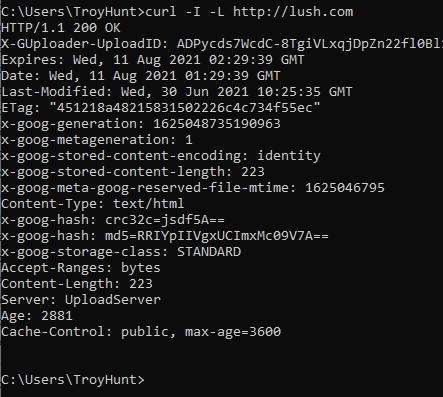
I get an HTTP 200. The website responds over the insecure scheme (which is normal) but then doesn't redirect me with (ideally) an HTTP 301 "Permanent Redirect". The difference in behaviour can be explained when looking at the response body instead of the headers:
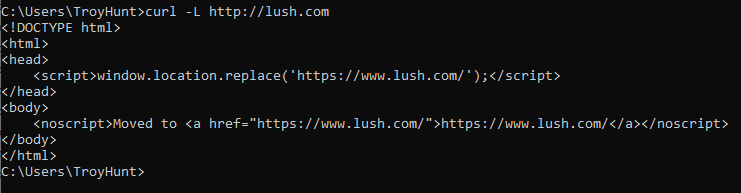
This just isn't how to do redirects. Without a proper response code and location header, the client is left to interpret markup without the semantic intent provided by headers. That's why services such as HSTS Preload get very unhappy:
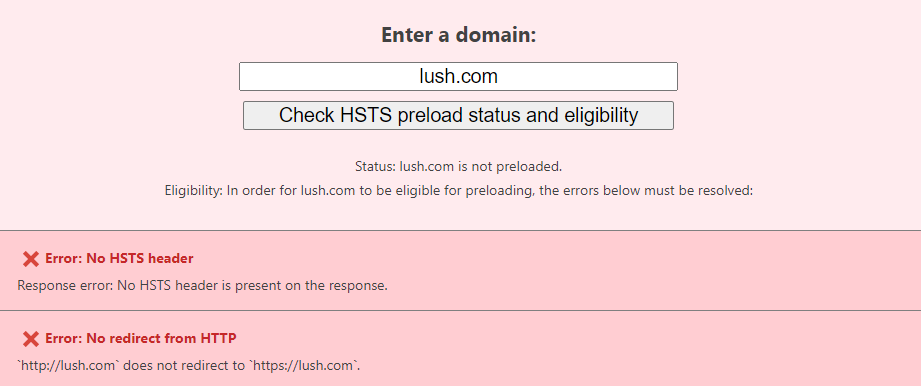
Obviously Lush doesn't want to be preloaded otherwise the directive would be specified in their HSTS response header (yes, they do have one), the point is that redirects need to be done right if the site doesn't want to make the list here.
Reporting False Positives
There'll be a few. If you're confident there's a false positive such as a domain incorrectly associated to a country or a website definitely redirecting to HTTPS correctly (do try cURL'ing it from the command line), leave a comment below and I can manually override the data. I'll fix any I agree with, but some of them may never be quite right. I mean, where does chinese-embassy.org.uk belong? The UK? China? And why is it the 31,443rd most popular site in the world and it just returns "Not Found [CFN #0005]". I have absolutely no idea 🤷♂️
Data on GitHub
Finally, all the data that drives the site is available in a public GitHub repository. Feel free to go and check it out there, diff it with the last version and generally just do whatever you please with it. Actually, if there's one thing you could do that would nudge everything in the right direction, check out the top sites not doing HTTPS right in your country and give them a bit of a nudge. Point them here, send them to the whynohttps.com and maybe even prompt them to check out the resources on the bottom of the page. Help make the web a better place, one site at a time 😊