
Remember the good old days when a website used to be nothing more than a bunch of files on a web server and a database back end? Life was simple, easy to manage and gloriously inefficient. Wait – what? That’s right, all we had was a hammer and we consequently treated every challenge like the proverbial nail that it was so we solved it in the same way with the same tools over and over again. It didn’t matter that an ASP.NET website on IIS was woefully inadequate at scheduling events, that’s all we had and we made it work. Likewise with SQL Server; it was massive overkill for many simple data persistence requirements but we’d spent the money on the licenses and we had an unhealthy dose of loss aversion coupled with a dearth of viable alternatives.
This was the old world and if you’re still working this way, you’re missing out big time. You’re probably spending way too much money and making life way too hard on yourself. But let’s also be realistic – there are a heap of bits in the “new world” and that means a lot of stuff to learn and wrap your head around. The breadth and depth of services that constitute what we know of as Microsoft Azure are, without a doubt, impressive. When you look at infographics like this you start to get a sense of just how comprehensive the platform is. You also get a bit overwhelmed with how many services there are and perhaps confused as to how you should tie them together.
I thought I’d take that aforementioned infographic and turn it into what Have I been pwned? (HIBP) is today. Oh – and speaking of today – it’s exactly one year since I launched HIBP! One of the key reasons I built the service in the first place was to get hands on with all the Azure services you’ll read about below. I had no idea how popular the service would be when I set out to build it and how well it would demonstrate the cloud value propositions that come with massively fluctuating scale, large volumes of data storage and a feature set that is distributed across a range of discrete cloud services.
Here’s the infographic, click through for a high-res PNG or go vector with PDF and read on after that for more details on how it’s all put together.

So that’s the big picture, now let me fill in the details.
The clients
I went down the responsive web route from the outset with a view to making everything play as nice as possible across the broadest range of devices. I discarded IE8 from the outset (remember when that was still a thing?!) and focused on CSS media queries and design that adapted to the device form. From very early on, I also made an API available publicly and freely. The search feature was already making async requests to a Web API endpoint anyway, publishing an API spec was a simple step from there.
On that web interface, I’ve been a bit obsessive in optimising the bejesus out of everything I possibly can, as you can see from posts like Micro optimising web content for unexpected, wild success and Measure, optimise then measure again: further refining “Have I been pwned?”. It was experiences like paying for 15GB of jQuery downloads in a day that prompted me to really look at how I structured the way the browser was talking to the service to optimise both performance and cost. (Pro tip – don’t pay for bandwidth you don’t need to!)
Standing up an unlimited API with no authentication requirement has also been a bit interesting. I’m yet to see any behaviour that I’d class as malicious in terms of impact on HIBP, but I’ll often see a few hours’ worth of high requests per minute to the server without it being reflected in Google Analytics (it’s only logging browser activity). You can actually see the requests flat-lining at what is inevitably the maximum throughput the client’s connection allows, but I’m yet to see it actually cause HIBP itself to max out an instance.
The deployment process
Everything is in a private GitHub repository and makes use of feature branches extensively. I probably wouldn’t say “religiously”, but I do aim to keep the master branch in a ready state of deployment. I don’t put any NuGet packages in there, it only pollutes the repository with things that can be pulled back down by either the IDE or the build environment as required anyway. It makes versioning simpler when there’s a package update and keeps the repository size lighter.
In terms of deployment, I merge master into a “deploy” branch and push back to GitHub. Kudu then jumps in and does its magic (do read up on what Kudu can do if you deploy to Azure but haven’t used the browser-based Kudu service, it’s quite awesome), pulling the deploy branch and deploying the site. All of this happens to a staging deployment on Azure – it’s not immediately live. This gives me an environment I can play with to make sure everything is behaving then I just swap that deployment with the current live one using Azure’s staged deployment feature.
If this process is new to you, you can see how to set most of it up in my World’s Greatest Azure Demo walkthrough which is a free 1 hour 20 minute video.
The website
Obviously this is the coalface of what people see when they come to the site. I run it as the smallest possible standard instance available in the Azure website offerings (a single 1.6GHz CPU with 1.75GB of RAM) which gives a well-optimised site a heap of performance until load gets serious. When that happens, I allow it to scale out automatically to as many as 10 instances so we’re also talking a ten-fold increase in website capacity. As required, I can also scale up to a “Large” website instance which in my testing, is effectively a four-fold increase again (there’s always the “Medium” instance which is about double “Small” and half “Large” in terms of the traffic it will support). The bottom line is that the site sits there using only 2.5% of the available scale which means I only pay for 2.5% of the available scale until I actually need more.
Speaking of scale, this is the sort of scenario I need to cater for:
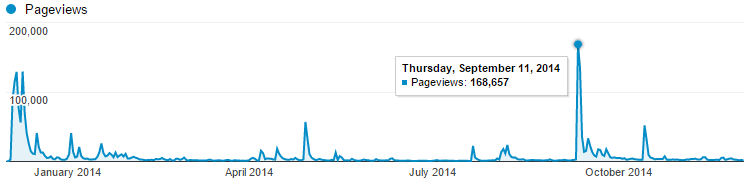
That’s just the last few months and it doesn’t include hits to the API which occur every single time there is a search for a pwned account so you can pretty much double those numbers in terms of traffic to the server. The cloud value proposition of rapid elasticity is never more apparent than when you go from a few hundred requests in an hour to 30,000 of them which is what happened on September 11 when everyone got stressed about the alleged Gmail hack. I learned a bunch of things about how that sort of scale works back then after which I learned I couldn’t trust any of the figures as New Relic was eating up all my CPU due to a bug! Inevitably I’ll see traffic of this scale (and probably way higher) many times in the future yet and it will be good to have an opportunity for a more objective analysis of performance. It’s crazy just how far that small website instance can scale when the app is built for performance…
The CDNs
I unashamedly steal other peoples’ bandwidth. Well kind of – I use public CDNs for everything I can which means jQuery, Bootstrap and Font Awesome. One of the key reasons is that it means I don’t pay for the data (I mentioned earlier how I paid for 15GB of jQuery alone in a single day once) but it also gets these libraries served from locations that are most convenient to the user. There’s also the added bonus that if they’ve visited another site using the same version of, say jQuery from the same CDN, it’s already cached in their browser and there’ll be no loading it over the web.
I’m also making use of the Azure CDN for the pwned companies’ logos. I dump it into blob storage, set a long cache expiry on it and magic happens as it’s distributed around the globe. Since I originally set this up, you can actually point a CDN endpoint to a path on a website rather than just to a blob storage location, but by doing this I don’t need to deploy the site when a new breach is added. I tend to use Visual Studio’s Azure integration points quite a lot so I just use the server explorer to browse on over to the blob and drop the file there. This helped get the site an excellent performance grade and there are now very small gains left to be had.
Monitoring and alerts
It’d be really hard to properly support this service without a heap of info about how it’s behaving. The native Azure monitoring is great for understanding what’s going on internally within the service, particularly when it comes to how things will scale and what you’ll be billed for. There’s more than enough information in there that you should never have any surprises come the end of the month when the bill lands. In fact that’s something that surprises me – that some people say they were surprised! Get your alerts right and you’ll know very early when something is happening to a resource that could hit your bottom line.
New Relic has been invaluable for tracing down performance to a very fine grain which includes what’s happening at the individual transaction or database query level. The alerts it sends are often the first indication of an outage and having a monitoring service independent of the hosting platform is something that sits rather well with me. Oh – and it’s a free add on when you stand up an Azure website so the price is awesome!
Raygun.io – I have nothing but good things to say about these guys. Go and check out my post on Error logging and tracking done right with Raygun.io if you want the detail but in short, this captures all my unhandled exceptions (including things like 404s so they’re not necessarily all my fault!) and triages them in a way that I can focus on stuff that’s important and not get distracted by noise. I’ve used services like ASP.NET Health Monitoring and ELMAH before and whilst they were very handy, the noise they generate can be deafening. I use Raygun.io religiously for HIBP and its proven extremely valuable.
Breach processing
Whichever way you cut it, so long as I want to verify the legitimacy of breaches before putting them in the system and then automatically notifying a bunch of people that they’ve been pwned, it’ll take some effort. Many breaches come from very questionable sources and when it’s a zip or binaries I tend to pull them straight into a “sandbox” VM, that is one that I’m happy to blow away at any time. I only turn it on when I need it so for all intents and purposes, it’s free.
Occasionally I need some serious scale for analysing large breaches. Adobe is the canonical example of this and I’ve previously written about Using high-spec Azure SQL Server for short term intensive data processing. In fact in that post, I grabbed the biggest freakin’ SQL Server VM I could get my hands on because frankly, time is money! I mean my time is money – I don’t want to waste it sitting around waiting for stuff to happen and for the sake of $3.14 an hour for the biggest VM I could get at the time, it just makes sense.
Once I have a clean set of data (namely a unique collection of email addresses and if they exist, usernames), I use a VM dedicated to importing the breach and then emailing out notifications. This runs a console app that takes care of the process and is probably the least cloud-like implementation in the entire system. However it’s a small overhead for an infrequent process (albeit a very important one) and there are challenges in becoming more cloud-like which I’ll talk about a bit later.
Storage
“You need a data layer therefor thou shalt use SQL Server”. Ugh – heard this before? Not that there’s anything specifically wrong with SQL Server, it’s an excellent RDBMS, but you don’t always need an RDBMS. I made the call very early on to use Azure table storage for managing the breached data (and later the pastes as well) and I’ve never looked back. I explain the rationale in my post on Working with 154 million records on Azure Table Storage – the story of “Have I been pwned?” but in short, table storage is massively fast for looking up data by a key and it’s a fraction of the price of SQL Azure.
But I also use SQL Azure. Wait – two data persistence technologies?! Computers can do that?! I jest, but there is a popular (mis)conception out there that you must pick a singular implementation and stick with it. In my experience, it makes much more sense to use table storage in the places it excels (price and speed when looking up by key) and SQL Azure where it makes sense (queryability). The big stuff I retrieve by partition and row key is the breach data, the little stuff I query is the subscriptions and when required, sending and tracking notifications. It works beautifully harmoniously!
In terms of how the data is backed up, it’s a bit of a mixed bag. Firstly, there’s built-in redundancy against failure by virtue of multiple locally redundant copies of the data (this isn’t something I configure, it’s just part of the managed service). I’ve manually configured Godzilla protection which is to say that I’ve enabled geo redundant storage such that a disaster of monstrous proportions in the West US data centre where HIBP is hosted will still leave a copy of everything in a totally separate region which assumedly, Godzilla has not impacted.
For SQL Azure, I’m using the “Basic” service tier which gives me the ability to roll back to any previous version of the data within the previous week. This is really neat and it replaces the more manual approach I’d written about in the Godzilla link above. That model was on the old “Web” tier and it involved taking daily backups into blob storage which meant replicating the DB and then consequently paying double for it as you get hit with a full day of charges each time it runs. Now, the backup is implicit although the basic tier is only locally redundant. I could go to the “Standard” tier and get a 14 day restore window and also make the backup geo redundant but the cost triples ($5 up to a lofty $15/m!). Instead, I’m using a combination of the basic plan’s auto-restore and still using the old manual backup process albeit on a weekly basis (this means the cost increases by one seventh rather than doubles as it did before) with a 28 day retention period and the DB is backed up to blob storage which is geo redundant. The bottom line is full local redundancy with near-instant rollback to any point in the last week plus the ability to rollback to a weekly backup anywhere up to a month back and it’s geo redundant.
One other thing about the basic tier – it’s rated at 5 DTUs or “Database Throughput Units” which is effectively a measure of performance tier you can read about in Azure SQL Database Service Tiers and Performance Levels. So how does that perform under serious load? The SQL DB is very rarely hit; each breach has a row in there but it’s cached in-process in the app for 5 mins so 12 times an hour there are 34 rows returned (one for each current breach). If a breach search gets a hit, the name of the breach is matched to one of those cached records. All paste data is in table storage so no SQL Azure hit there which just leaves notification signups which are a (comparatively) low throughput at the best of times and they can also tolerate slightly higher latency. The percentage of DTU utilisation can be monitored in the portal so it’s easy to keep an eye on if it’s causing problems and then just scale it up accordingly. I hammered it with a large query just for kicks and watched the DTU percentage max out:
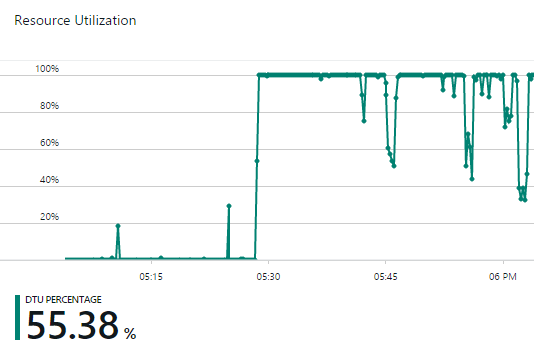
I will likely try not to do that too often…
The paste service
I launched this service a few months back and it’s been absolutely fantastic. I was going to write a dedicated blog post on how it was put together, but somehow it morphed into this one that covers everything. Just as a refresher, the premise is simply this: Pastebin (and to a lesser extent, other similar paste services), is often the first place a data dump appears. There’s a Twitter account called @dumpmon which monitors Pastebin (among others) for new pastes that match a pattern indicating it’s probably a data breach dump and then auto-tweets it out. HIBP now monitors that tweet stream for new pastes and then automatically imports them with impacted accounts being searchable on HIBP within a median time of 33 seconds after first appearing on Pastebin.
Clearly this all needed a bunch of background processing which included monitoring the @dumpmon account, retrieving pastes and sending notifications. I decided to stand up one Azure Worker Role just to watch the @dumpmon Twitter feed. Every time there’s a tweet that announces a dump containing emails, HIBP knows about it within 2 or 3 seconds. To ensure the whole thing is idempotent, the worker role stores a reference to the tweet in SQL Azure and always checks that I haven’t already retrieved it before any further processing. It then drops the URL of the paste only into Azure Queue Storage so that’s the only job this worker role has – get new tweets and queue the paste URL.
There’s then a separate worker role which monitors the queue. When a new message appears, the worker role pops it off the queue and makes sure that the paste hasn’t previously been retrieved. This is not redundant with the check in the previous paragraph – that one ensures tweets aren’t double-processed, this one ensures pastes aren’t. The distinction is important as it creates a clear abstraction between the two tasks and leaves the door open to me populating the queue with paste URLs from a different source. Anyway, once popped off the queue and verified as unique, the paste is retrieved, unique email addresses are extracted via regex, data is saved to table storage then emails are sent to impacted subscribers. Once everything has completed successfully, the message is deleted from the queue. The beauty of queue storage is that the message is automatically returned to the queue 30 seconds after having been popped so if anything fails catastrophically before it’s programmatically deleted then the message itself isn’t lost.
At present, all of this remains implemented by a single instance of each worker role which is just fine as the @dumpmon tweets come in slow enough to make everything very sequential. In theory, I could scale out multiple instances of the roles if I was dealing with high volumes and wanted massive async processing of large data volumes (and I’m not ruling that out for processing new breaches…) but for now, this works just fine as is.
The additional services
There are a few here so I’ll reel them off quickly. Mandrill is working great for email and I rolled over to that from SendGrid recently which was also great but I found I was getting a better spam rating, a more comprehensive dashboard and better pricing with Mandrill.
RSS via FeedBurner gets load and bandwidth off HIBP which are good things for both scalability and cost. I wrote about how I put this together a couple of weeks ago so check that out if you want more info.
The WHOIS API is necessary to get email addresses from domains so that I can email them as a means of ownership verification on domain-wide searches. Of course I’d love to get this service for free (it’s actually one of the more expensive things I pay for), but certainly when I implemented it, I couldn’t reliably pull that data across TLDs. Speak up if you know of a better way!
I added the UserVoice page just a week ago in response to lots of good ideas that needed a better triage mechanism and a means of prioritisation. I’ll also use that to flesh out ideas further and discuss the various challenges in implementing the things people are looking for (see the “+” syntax discussion as an example of that) so do use your votes to contribute ideas and join in the discussion.
DNSimple is not GoDaddy which is immediately advantageous. It’s run by exceptionally smart people who don’t work for GoDaddy and I’ve had nothing but great support from them. It’s dead easy to use, it’s super fast and it’s not GoDad… ok, just go here and read why.
What I’d do differently…
The good news is that all the fundamentals are sound and the service does exactly what it needs to based on today’s requirements. Probably the main thing I’d improve is the process of importing a new breach as it is a bit labour intensive right now. To a degree, that’s unavoidable when I want to validate the legitimacy of a breach, the main scope for improvement is the import process which presently involves remoting into a VM and running commands.
Ideally, that breach import process would be far more parallelised and far more automated. It might mean just dropping a dump into blob storage somewhere which then fires off a process to auto-extract all the email addresses and queue them for processing. The trick is dealing with scale – Adobe was a 2.9GB zip file containing 152M records and let me make a prophecy now: we will see that scale topped at some time in the future. That creates some very challenging problems when it comes to merging them into the existing result set and then sending notifications.
The other thing I’d do differently if there was sufficient scale to justify it is split the API out from the website. Putting it on a separate domain running it on a separate website instance would start to give me more options around scale, namely that the bits serving the HTML could be tuned and scaled entirely independently of the bits serving the JSON. Particularly when you consider the latter can be hit pretty heavily independently of the former, this makes sense but again, only when there’s enough consistent demand to justify it (although of course I could always do that now and put them on the same web hosting plan using the same resources at no additional cost then move to a dedicated set of resources at a later date).
Taking that thinking even further, I could scale the API out to Azure’s API Management service in the future, but it doesn’t come cheap. There’s a bunch of stuff this would allow me to do in terms of scale and management, but it’s the sort of thing that wouldn’t happen unless the demand justified it as it simply doesn't solve problems I currently have, at least it doesn’t solve enough of them!
Same deal again with potentially using Azure Traffic Manager to scale the service out to more regions around the globe rather than just sitting the website in the one location. Yes, I could do this but at the moment it’s rare to use all the resources I already have at my disposal (namely that one website) so whilst it would get traffic that much closer to the consumers, it’d at least double the website cost. With super fast pages and good use of CDNs already, it’s a problem I don’t yet have although it would be a nice problem to have :)
What I wouldn’t do differently…
While I’m here, let me touch on a couple of things I wouldn’t do differently with regards to two recent outages. This week I had very intermittent DNS for the better part of the working day due to DNSimple being hit with a massive DDoS attack:
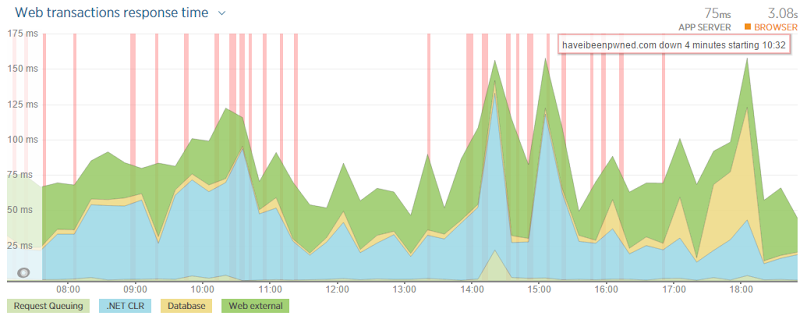
A couple of weeks before that, Azure got hit with a serious outage that also knocked HIBP offline for a good whack of the day. I have no intention of changing either service for one key reason: I’ve got a huge amount of confidence in those running these services. It’s the same with Raygun.io for that matter (although without the outage) in that to my mind, the vision and execution of how all these guys work is spot on. Outages happen to everyone and if they haven’t happened yet, they will at some time or another. I’m confident those experiences will improve the services and they’ll benefit from lessons learned, lessons not yet learned by those who’ve not had to deal with these issues yet. Don’t get me wrong – if I kept seeing outages then I’d absolutely reassess the situation, but we’re a long way from that in these cases.
Supporting HIBP
Back in March, I wrote about Donations, why I don’t need them and why I’m now accepting them for “Have I been pwned?”. As I said at the time, the cost of running the service is negligible and indeed that’s a massively positive endorsement of Azure and the things it lets you do for less than coffee money. That’s actually gotten cheaper both in real terms (some prices have fallen plus the SQL cost is down due to the change in backup processes mentioned earlier) and in relative terms (I’m using the website service for additional things without paying any more money). But I also explained that the real cost was in time and the sacrifices made so that all this can work the way it does.
I came up with 10 different things of varying value that illustrated the sacrifices that get made to make the magic happen:
![]()

![]()
![]()

![]()
![]()
![]()

![]()
I’m enormously grateful to those who have shown support and helped keep this service running through the encouragement they’ve provided both monetarily and just by virtue of positive words. I’m still doing the PayPal thing but a bunch of people wanted to throw me a slice of Bitcoin too so I’ve added support for that and it’s all over on the donate page.
Next…
The UserVoice page is probably the best indication of the user-facing features you can expect to see next and I intend to take a good bite out of that over the coming Christmas holidays. Beyond that though is a never ending stream of backend stuff, everything from better optimising the email notifications for legibility and spam-friendliness to using more of Azure’s features to improve the service. Some of this things you’ll see, others you may just “feel” in terms of things being a little slicker.
I hope this overview has been useful in helping you understand not just how HIBP has been put together, but also how a range of Azure features can be combined to provide a service like this at such a negligible price. We couldn’t do this even just a few years ago, at least not with this degree of ease and as awesome as it is, we’ll look back at this again in a year and a bunch of what you’ve read here today will be done in a better, cheaper and more readily consumable fashion. It’s just a very exciting time to be building software!