In the immortal words of Ricky Bobby, I wanna go fast. When I launched Pwned Passwords V2 last week, I made it fast - real fast - and I want to talk briefly here about why that was important, how I did it and then how I've since shaved another 56% off the load time for requests that hit the origin. And a bunch of other cool perf stuff while I'm here.
Why Speed Matters for Pwned Passwords
Firstly, read the previous post about k-Anonymity and protecting the privacy of passwords to save me repeating it all here. I've been amazed at how quickly this has been adopted since I pushed it out very early on Thursday morning my time. Perhaps most notably is 1Password's use of the service having pushed out integration within 27 hours. They had no prior noticed of this either, they just got down to business and did it as soon as I launched.
Read through the comments on that original blog post and you'll see a heap of other integrations too. Perhaps my favourite though is this one:
Beauty of @Cloudflare Workers is that it was easy to integrate @troyhunt's new pwned password service to add a header indicating whether a POSTed password is pwned or not. Then the server can warn the user.https://t.co/SmCgwV1tpn
— John Graham-Cumming (@jgrahamc) February 24, 2018
John is the CTO of Cloudflare and his model uses a Cloudflare Worker. This makes it possible to add that little bit of code to Cloudflare's "edges" (effectively the 122 data centres they have around the world sitting between browsers and servers), grab the password that's submitted by, say, a login request then check if it's been pwned and return the result in a response header. It's a beautifully elegant solution because there's no code to run on the server side and it can execute async whilst the original request is being processed by the origin server. Of course, you still need to do something with the newly added header indicating pwn status, but you get the idea.
If people are adding this service into their sites, it has to be fast. Super-fast. It can't block requests whilst searching through a large DB of half a billion records, if it's to be successful then responses must be lightening quick. There's also a direct line between execution time and the cost I incur because I'm using Azure Functions which are priced as follows:
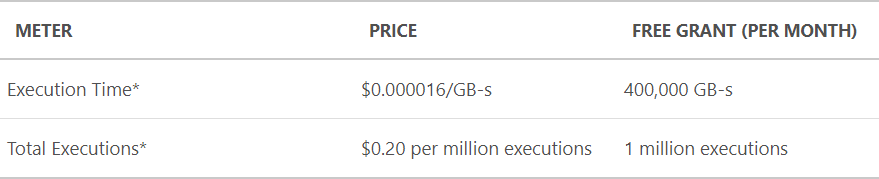
If I can keep execution time and resource consumption down, I can keep costs down. But further to that, if I can keep the number of executions down then that too will reduce my bill. Let's talk about how I'm doing that:
Reducing Executions and Load Time with Cloudflare Cache
When data in Pwned Passwords is queried using the k-Anonymity model, the request looks like this:
https://api.pwnedpasswords.com/range/21BD1The last part of the path is the first 5 characters of the SHA-1 hash of the password being searched for which in this case, was "P@ssw0rd". The response to that request is very aggressively cached at Cloudflare's end such that in the last 24 hours, 47% of the requests have been served directly by their cache and never actually hit my Azure Function:
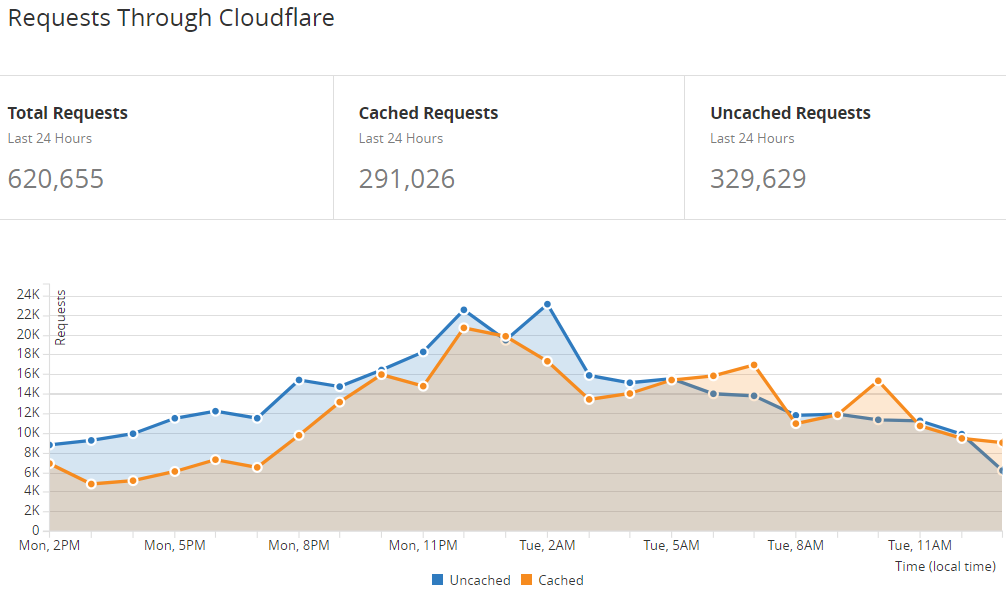
I actually thought this number would be higher, steadily increasing as people did queries that gradually exhausted the 16^5 range for hash prefixes 00000 through FFFFF. Eventually, I theorised, there'd be 1,048,576 entries sitting in Cloudflare's cache, only refreshing themselves from the origin after they expired a month later. In practice, however, cache eviction logic turns out to be a little more nuanced than that and after many discussions with Junade at Cloudflare (he came up with the k-Anonymity model for Pwned Passwords), it seems that things are as well-optimised as they're going to get for the moment. That may change in the future, but for now I needed to look further for more optimisation.
(A quick tangential footnote on this: the password search page on HIBP is really aggressively cached at Cloudflare. When I've had sudden, large influxes of traffic due to media coverage, only low single-digit percentages of it has hit my origin site then the search itself has gone to the Azure Function meaning almost no requests hitting the HIBP service even when things ramp right up.)
Table Storage Versus Blob Storage
I've been a massive proponent of Azure's Table Storage for years now. This is the construct that underlies all the breached email addresses that presently sit in HIBP and it's worked absolutely flawlessly. (Side note: we also use Azure Table Storage for all the reports in Report URI.) One of the observations I've long made about Table Storage is that it provides an alternate or even complementary storage model to the classic RDBMS approach. Over many years in a corporate environment, I'd constantly hear this:
Oh, we're building a web application so we'll be needing a SQL Server database
Sometimes, this was true, but more often than not it was a reflection of doing things the way they'd always been done as opposed to choosing the most optimal technology for the job. In my post from a few years ago on the architecture of HIBP, I showed how I used both Table Storage and SQL Azure to compliment each other. I picked the best bits from both and even today, that's still precisely the same storage choice I'd make. But on reflecting about the decisions I made for Pwned Passwords V2, I found myself having fallen into that same trap of "doing what I've always done".
Here's what V2 of Pwned Passwords looks like in Table Storage:
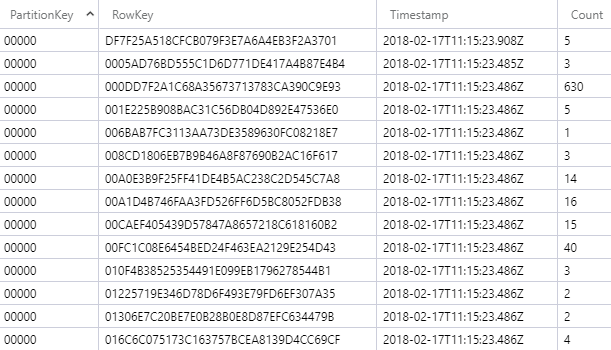
The first 5 chars of the hash are the partition key, the remainder of the hash is the row key and then there's a count attribute (Azure adds in the Timestamp automatically). This made it very fast to look up by individual hash (just segment it into two parts and query by partition and row key), but also very easy to pull a complete hash range for the k-Anonymity model as I just dragged in the entire partition. When I analysed the function execution time, here's what I found:
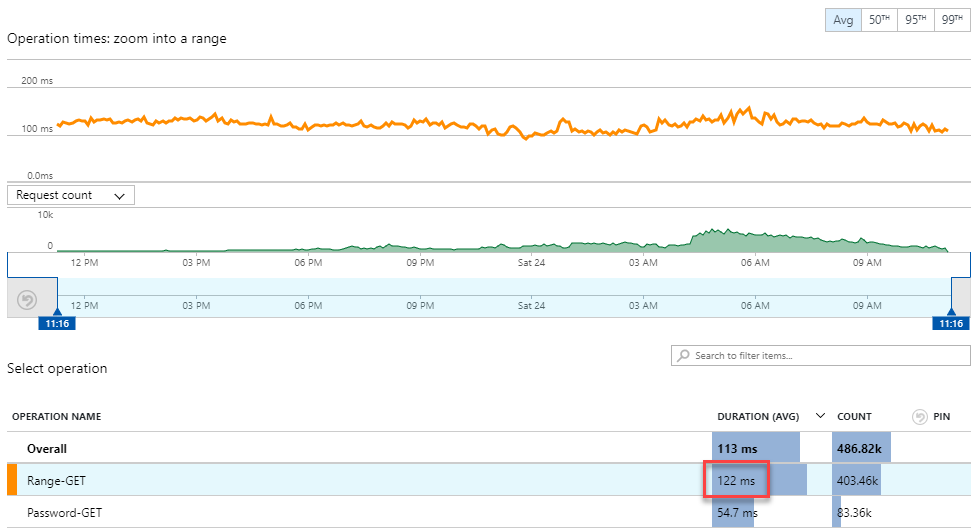
Very linear performance that barely changes with volume. Those 403k requests executed in an average of 122ms which is predominantly comprised of the function reaching out to table storage, grabbing the partition and deserialising it before returning it in the response. The execution time also had a pretty well-distributed range with 50% of them running in 100ms or lower:
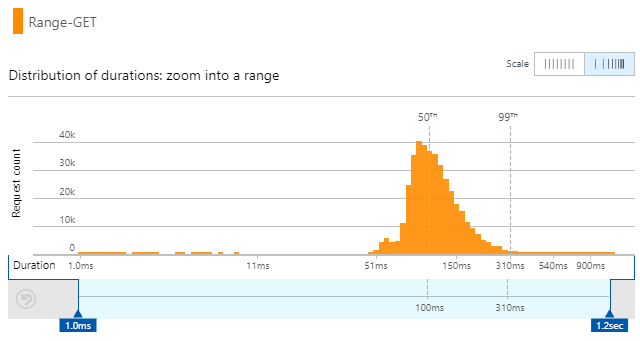
But then, I started thinking about it more: why am I using Table Storage? I mean why sit the data in a queryable construct when ultimately, that range search simply pulls back one of 1,048,576 different results that don't change! Yes, they'll change when I release a V3, but I went 6 months between V1 and V2 and I don't expect anything to change again any time soon. Plus, when it does change, it'll be a complete rollover in one go; I'll still have 1,048,576 different ranges just with, say, 750M hashes. Would it be faster if I just exported the data into 1,048,576 separate files, dropped them into Blob Storage then pulled back the exact file I needed from the function? Kinda like this:
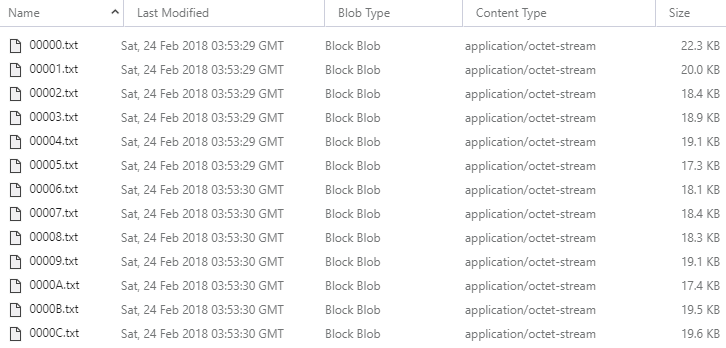
And then the file has precisely the contents you get in the existing API response:

tl;dr - can I pull a pre-prepared file from a blob faster than I can pull a complete partition from a table? Actually, yes, a lot faster:
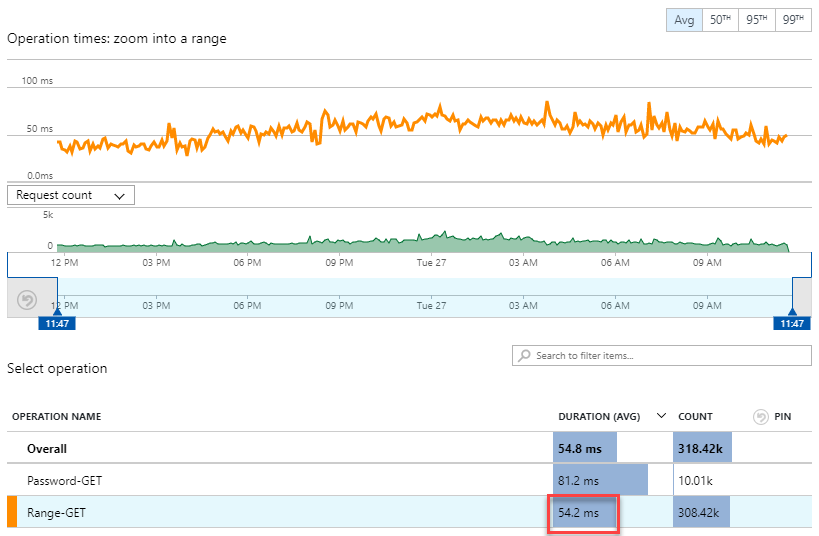
That's just shaved 56% off the execution time! 122ms down to only 54.2ms. That's with no change to the publicly facing API and an identical response body returned. The distribution of those times is where it gets particularly interesting:
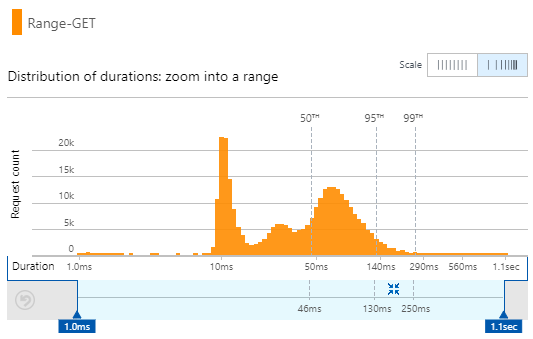
Half of the queries now execute in 46ms or less! The interesting bit is that the distribution of execution times is a lot more erratic so the performance of this model isn't as consistent, but it's an awful lot faster. Still, look at that cluster of requests at only 10ms - wow!
For now, I can switch between the two back end repositories with a simple config setting so if I find, for example, that perf degrades on blob storage when larger volumes occur, I can always roll back in an instant.
Let me touch on a couple of other really neat perf things.
Argo
We all know the internet is a collection of interconnected nodes with traffic bouncing around between them in order to carry your request to the origin server and then return you a response. But what's the most optimal route for the traffic? The shortest distance? Not necessarily because there's factors such as congestion and the reliability of particular nodes or connections to deal with. But typically, that's not something you really have control over, I mean in terms of deciding which route your traffic should take.
Back in May last year, Cloudflare launched Argo which promised the following:
Cloudflare’s Argo is able to deliver content across our network with dramatically reduced latency, increased reliability, heightened encryption, and reduced cost vs. an equivalent path across the open Internet. The results are impressive: an average 35% decrease in latency, a 27% decrease in connection errors, and a 60% decrease in cache misses. Websites, APIs, and applications using Argo have seen bandwidth bills fall by more than half and speed improvements end users can feel.
Picture it like this:
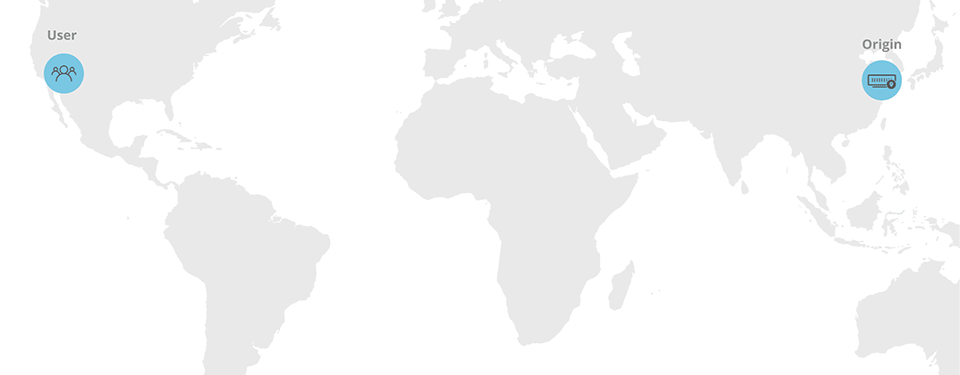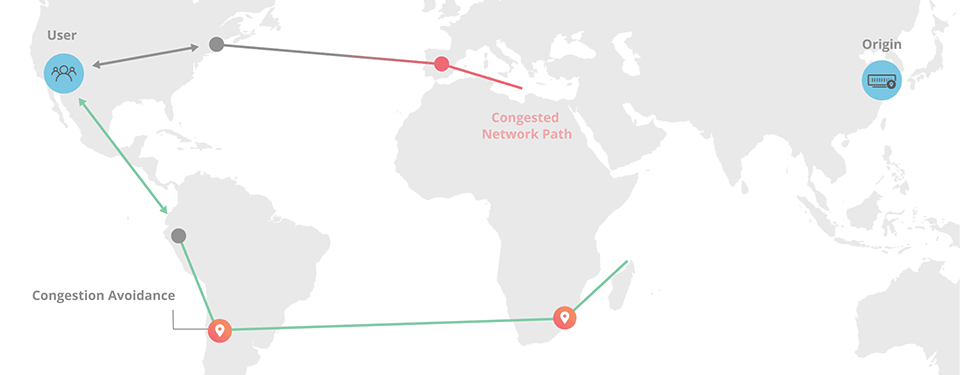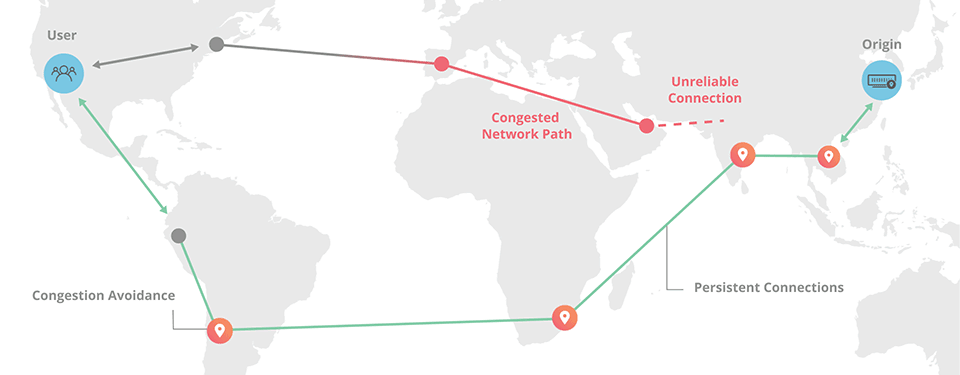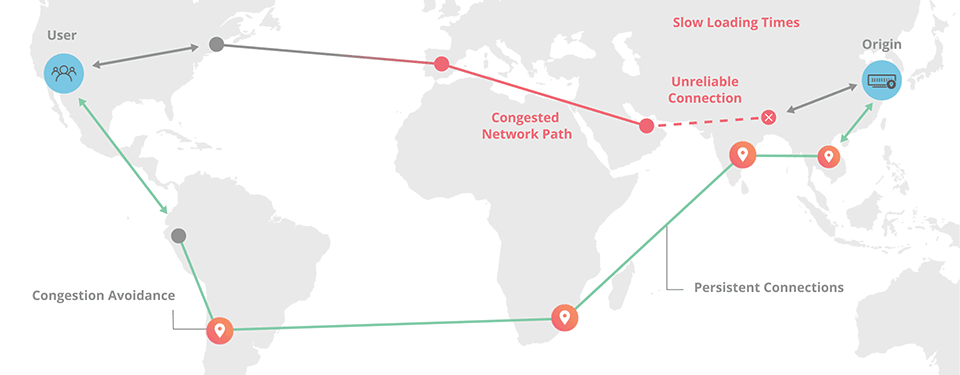
Cloudflare can do this because they "route more than 10% of all HTTP/HTTPS Internet traffic, providing Argo with real-time intelligence on the fastest network paths". Traffic routing in this fashion is only possible because they see such a significant portion of what's flying around the internet and can make intelligent decisions about how it should be routed. Let's look at what that actually looks like for Pwned Passwords:
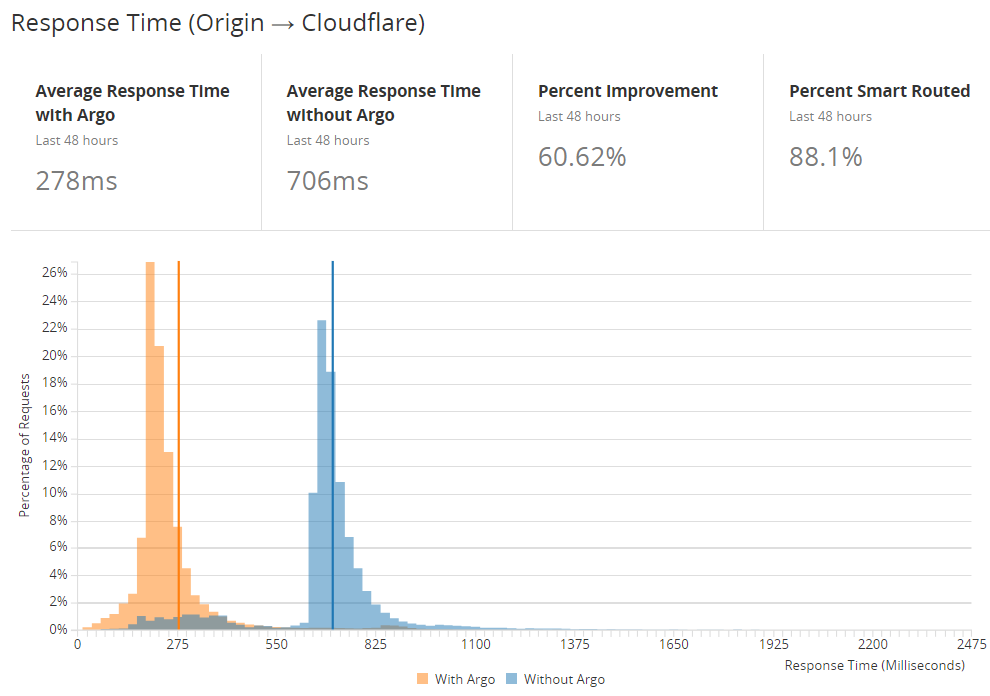
The first thing you see is that clearly, there's a massive improvement here; response times have been slashed by more than 60%. The next thing is you might start to wonder why even the 278ms figure is so high. What we're seeing here is Time To First Byte (TTFB) which is the delay between Cloudflare sending a request to the server and receiving the first byte in response. That figure therefore includes all the server processing time as well and whilst we know that's now only about 20% of the TTFB number, I've still got traffic traveling long distances. Remember, this is the time between one of those 122 Cloudflare edge nodes making a request and the Azure Function in Microsoft's West US data centre actually returning a response. Consider that in the context of the following map:
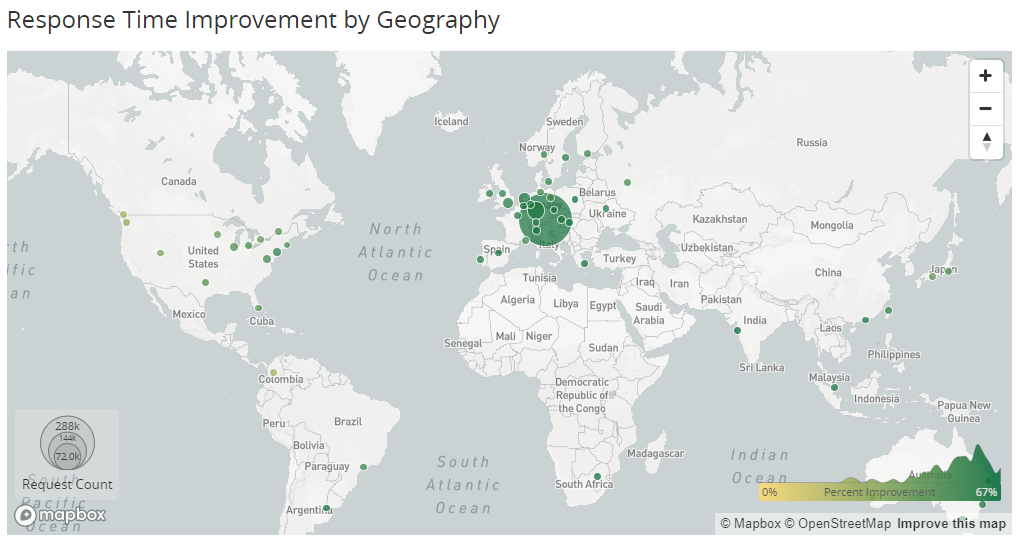
That biggest green dot is on Munich which is a 17,000km round trip away from Seattle. Longer distances, higher latency, greater volumes, more chance to improve things. Folks in Europe are picking up the biggest gains here whilst those on the west coast of the US are getting the smallest (but they're closer with lower latency in the first place).
Brotli
Here's another great performance boost that's dead easy to enable:
Brotli compression can work much more efficiently than gzip for certain content types. For example, Scott Helme found a 33% reduction for HTML when he wrote about it a couple of years back. So what does it look like for HIBP? Let's load the Pwned Passwords search page via Fiddler first with no "br" encoding then with brotli and we'll compare the results:
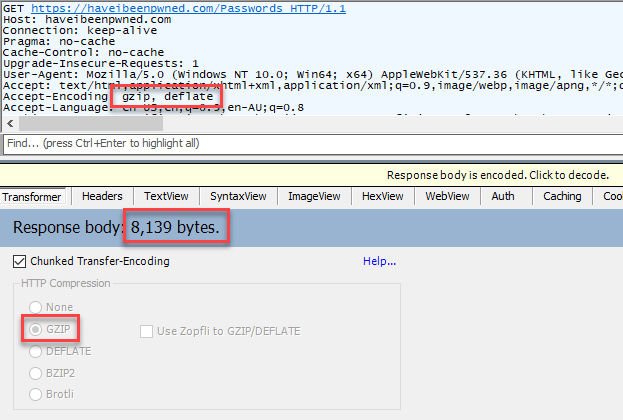
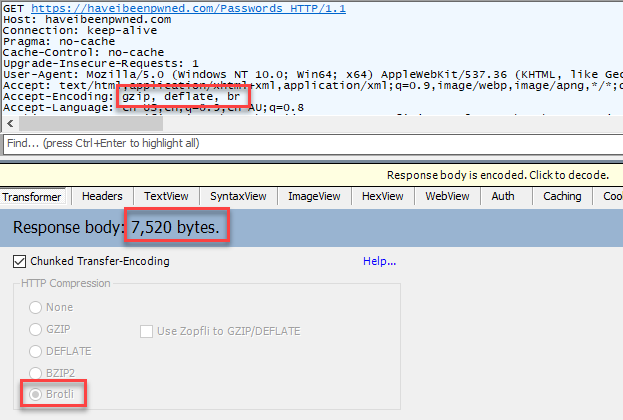
It's not quite at the level Scott found, but it's still 8% off the response size by doing nothing more than toggling a switch. However, you might have noticed that this is the search page on HIBP rather than the API request itself; as of today, Cloudflare isn't applying brotli to "text/plain" content types. However, I'm told that in the very, very near future that'll be turned on so I decided to stick it into this post anyway.
Oh - last thing: brotli is very well supported across modern browsers:
But what's not said in the image above is that brotli is HTTPS only (do read that post from Sam Saffron on brotli, it has a heap of good info). As if you needed another good reason to roll over to secure communications...
Future
I'm really happy with the basic philosophy of this whole thing: serve as much as possible from edge node cache, go as fast as possible across the network when the request needs to go to the origin then process that request as quickly as possible. On the one hand, that's all web performance 101 but on the other hand, it's not always that readily achievable, especially at both scale and price points.
There's certainly more opportunity for improvement though, for example by distributing the data and API endpoints in a more globally-accessible fashion. Putting another Azure Function in Europe with another copy of the data in Blob Storage wouldn't be hard or expensive. Cloudflare traffic manager could help geo-steer requests and folks in places like Europe could realise performance gains on requests that go all the way to the origin.
Another idea I'm toying with is to use the Cloudflare Workers John mentioned earlier to plug directly into Blob Storage. Content there can be accessed easily enough over HTTP (that's where you download the full 500M Pwned Password list from) and it could take out that Azure Function layer altogether. That's something I'll investigate further a little later on as it has to potential to bring cost down further whilst pumping up performance.
Ultimately though, it's all a work in progress and I'm enormously happy with the adoption and performance of the service so far. My intention is to keep working on that speed component so it's as efficient as possible for those who want to use it and hopefully, it actually makes a difference to the security posture of individuals and companies alike.