
In the final part of this series we’ll look at the risk of an unvalidated redirect or forward. As this is the last risk in the Top 10, it’s also the lowest risk. Whilst by no means innocuous, the OWASP Risk Rating Methodology has determined that it takes last place in the order.
The practice of unvalidated redirects and forwards, also often referred to as an “open redirect”, appears fairly benign on the surface. However, it can readily be employed in conjunction with a combination of social engineering and other malicious activity such as a fraudulent website designed to elicit personal information or serve malware.
What an unvalidated redirect does is allows an attacker to exploit the trust a user has in a particular domain by using it as a stepping stone to another arbitrary, likely malicious site. Whilst this has the potential to do considerable damage, it’s also a contentious vulnerability which some organisations consciously choose to leave open. Let’s take a look at how it works, how to exploit it then how to protect against it.
Defining unvalidated redirects and forwards
This is actually an extremely simple risk to detect and exploits against it can occur in a number of different ways. In some ways, exploiting it is actually very similar to how you might approach a site which is vulnerable to the XSS flaws we looked at back in part 2 of this series.
Here’s how OWASP summarises it:
Web applications frequently redirect and forward users to other pages and websites, and use untrusted data to determine the destination pages. Without proper validation, attackers can redirect victims to phishing or malware sites, or use forwards to access unauthorized pages.
In fact the root of the problem is exactly what we were looking at back in the first two parts of the series: untrusted data. Let’s look at that definition from part 1 again:
Untrusted data comes from any source – either direct or indirect – where integrity is not verifiable and intent may be malicious. This includes manual user input such as form data, implicit user input such as request headers and constructed user input such as query string variables. Consider the application to be a black box and any data entering it to be untrusted.
OWASP defines the risk as follows:
| Threat Agents | Attack Vectors | Security Weakness | Technical Impacts | Business Impact | |
| Exploitability AVERAGE | Prevalence UNCOMMON | Detectability EASY | Impact MODERATE | ||
| Consider anyone who can trick your users into submitting a request to your website. Any website or other HTML feed that your users use could do this. | Attacker links to unvalidated redirect and tricks victims into clicking it. Victims are more likely to click on it, since the link is to a valid site. Attacker targets unsafe forward to bypass security checks. | Applications frequently redirect users to other pages, or use internal forwards in a similar manner. Sometimes the target page is specified in an unvalidated parameter, allowing attackers to choose the destination page. Detecting unchecked redirects is easy. Look for redirects where you can set the full URL. Unchecked forwards are harder, since they target internal pages. | Such redirects may attempt to install malware or trick victims into disclosing passwords or other sensitive information. Unsafe forwards may allow access control bypass. | Consider the business value of retaining your users’ trust. What if they get owned by malware? What if attackers can access internal only functions? | |
So we’re looking at a combination of untrusted data with trickery, or what we commonly know of as social engineering. The result of all this could be malware, data theft or other information disclosure depending on the objectives of the attacker. Let’s take a look at how all this takes place.
Anatomy of an unvalidated redirect attack
Let’s take a fairly typical requirement: You’re building a website which has links off to other sites outside of your control. Nothing unusual about that but you want to actually keep track of which links are being followed and log the click-through.
Here’s what the front page of the website looks like:
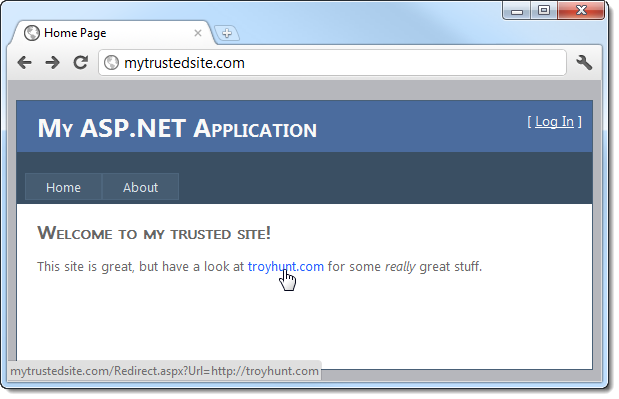
There are a couple of noteworthy thing to point out;
- The domain: let’s assume we recognise and trust the fictitious mytrustedsite.com (I’ve updated my hosts file to point to a local IIS website) and that seeing this host name in an address gives us confidence in the legitimacy of the site and its content.
- The target URL of the hyperlink: you can see down in the status bar that it links off to a page called Redirect.aspx with a query string parameter named URL and a value of http://troyhunt.com
What’s happening here is pretty self-explanatory, in fact that’s the whole reason why detectability is so easy. Obviously once we click the link we expect to see something like this:
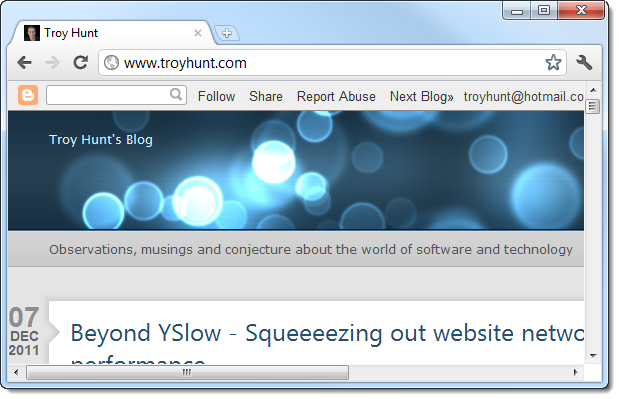
Now let’s imagine we’ve seen a link to this domain through a channel such as Twitter. It might appear something like this:
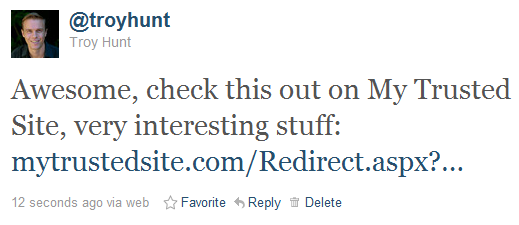
As best as a casual observer can tell, this is a perfectly legitimate link. It establishes confidence and credibility as the domain name is recognisable; there’s no reason to distrust it and for all intents and purposes, clicking on the link will load legitimate content on My Trusted Site. However:
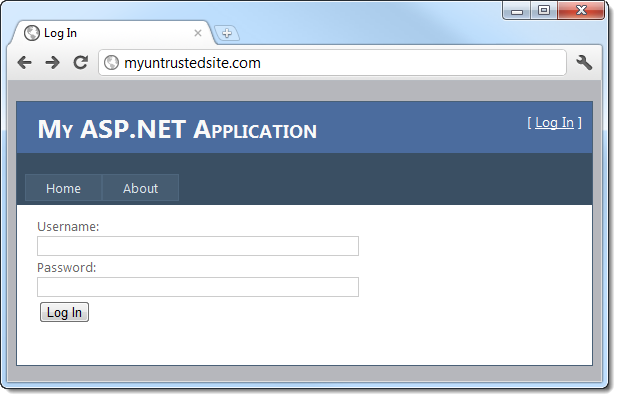
See the problem? It’s very subtle and indeed that’s where the heart of the attack lies: The address bar shows that even though we clicked on a URL which clearly had the host name of mytrustedsite.com, we’re now on myuntrustedsite.com. What’s more, there’s a logon form asking for credentials which you’d naturally expect would be handled properly under the circumstances. Clearly this won’t be the case in this instance.
Bingo. An unvalidated redirect has just allowed us to steal someone’s credentials.
What made this possible?
This is a simple attack and clearly it was made possible by a URL crafted like this:
http://mytrustedsite.com/Redirect.aspx?Url=http://myuntrustedsite.com
The code behind the page simply takes the URL parameter from the query string, performs some arbitrary logging then performs a redirect which sends an HTTP 302 response to the browser:
var url = Request.QueryString["Url"]; LogRedirect(url); Response.Redirect(url);
The attack was made more credible by the malicious site having a similar URL to the trusted one and the visual design being consistent (albeit both sample implementations). There is nothing that can be done about the similar URL or the consistent branding; all that’s left is controlling the behaviour in the code above.
Taking responsibility
Before getting into remediation, there’s an argument that the attack sequence above is not really the responsibility of the trusted site. After all, isn’t it the malicious site which is stealing credentials?
Firstly, the attack above is only one implementation of an unvalidated redirect. Once you can control where a legitimate URL can land an innocent user, a whole world of other options open up. For example, that could just as easily have been a link to a malicious executable. Someone clicks the link then gets prompted to execute a file. Again, they’re clicking a known, trusted URL so confidence in legitimacy is high. All the UAC in the world doesn’t change that fact.
The ability to execute this attack via your site is your responsibility because it’s your brand which cops the brunt of any fallout. “Hey, I loaded a link from mytrustedsite.com now my PC is infected.” It’s not a good look and you have a vested interest in this scenario not playing out on your site.
Whitelists are still important
Going back to that first part in the series again, I made a very emphatic statement that said “All input must be validated against a whitelist of acceptable value ranges”. This still holds true for unvalidated redirects and forwards and it’s the key to how we’re going to mitigate this risk.
Firstly, the code in the snippet earlier on performed no validation of the untrusted data (the query string), whatsoever. The first port of call should be to ensure that the URL parameter is indeed a valid URL:
var url = Request.QueryString["Url"]; if (!Uri.IsWellFormedUriString(url, UriKind.Absolute)) { // Gracefully exit with a warning message }
In fact this is the first part of our whitelist validation because we’re confirming that the untrusted data conforms to the expected pattern of a URL. More on that back in part 2.
But of course this won’t stop the attack from earlier, even though it greatly mitigates the risk of XSS. What we really need is a whitelist of allowable URLs which the untrusted data can be validated against. This would exist somewhere in persistent storage such as an XML file or a SQL database. In the latter case, whitelist validation using Entity Framework would look something like this:
var db = new MyTrustedSiteEntities(); if (!db.AllowableUrls.Where(u => u.Url == url).Any()) { // Gracefully exit with a warning message }
This is pretty self-explanatory; if the URL doesn’t exist in the database, the page won’t process. At best, all an attacker can do is manipulate the query string with other URLs already in the whitelist, but of course assuming those URLs are trustworthy, there’s no advantage to be gained.
But there’s also another approach we can take which provides a higher degree of obfuscation of the URL to be redirected to and rules out manipulation altogether. Back in part 4 I talked about insecure direct object references and showed the risk created by using internal identifiers in a publicly visible fashion. The answer was to use indirect reference maps which are simply a way of exposing a public identifier of no logical significance that resolved back to a private identifier internally within the app. For example, rather than placing a bank account number in a query string, a temporary and cryptographically random string could be used which then mapped back to the account internally thus stopping anyone from simply manipulating account numbers in the query string (i.e. incrementing them).
In the case of unvalidated redirects, we don’t need to have the URL in the query string, let’s try it like this:
http://mytrustedsite.com/Redirect.aspx?Id=AD420440-DB7E-4F16-8A61-72C9CEA5D58D
The entire code would then look something like this:
var id = Request.QueryString["Id"]; Guid idGuid; if (!Guid.TryParse(id, out idGuid)) { // Gracefully exit with a warning message } var db = new MyTrustedSiteEntities(); var allowableUrl = db.AllowableUrls.SingleOrDefault(u => u.Id == idGuid); if (allowableUrl == null) { // Gracefully exit with a warning message } LogRedirect(allowableUrl.Url); Response.Redirect(allowableUrl.Url);
So we’re still validating the data type (not that much would happen with an invalid GUID anyway!) and we’re still checking it against a whitelist, the only difference is that there’s a little more protection against manipulation and disclosure before actually resolving the ID to a URL.
Implementing referrer checking
In a case such as the example earlier on, the only time the redirect has any sort of legitimate purpose is when it’s used inside the site, that is another page on the same site links to it. The malicious purpose we looked at involved accessing the redirect page from outside the site, in this case following a link from Twitter.
A very simple mechanism we can implement on the redirect page is to check the referrer header the browser appends with each request. In case this sounds a bit foreign, here’s the header info the browser sends when we click that original link on the front page of the site, the legitimate one, that is:
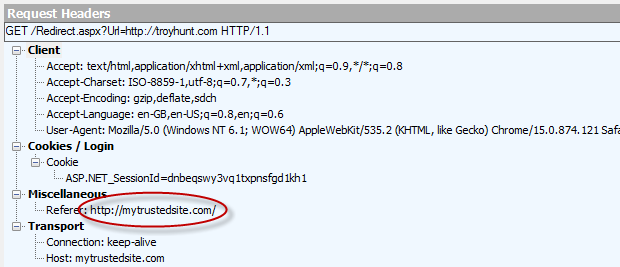
This was captured using Fiddler and you can see here that the site which referred this request was our trusted site. Now let’s look at that referrer from our malicious attack via Twitter:
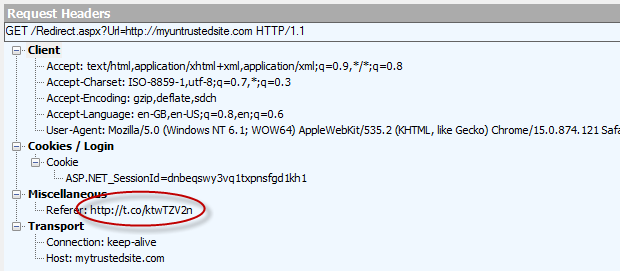
The referrer address is Twitter’s URL shortener on the t.co domain. Our trusted website receives this header and consequently, it can read it and act on it accordingly. Let’s try this:
var referrer = Request.UrlReferrer; var thisPage = Request.Url; if (referrer == null || referrer.Host != thisPage.Host) { // Gracefully exit with a warning message }
That’s a very simple fix that immediately rules out any further opportunity to exploit the unvalidated redirect risk. Of course it also means you can never deep link directly to the redirect page from an external resource but really, this isn’t something you’re normally going to want to do anyway.
Obfuscation of intent
Earlier on we looked at this URL:
http://mytrustedsite.com/Redirect.aspx?Url=http://myuntrustedsite.com
You only need to read the single query string parameter and the malicious intent pretty quickly becomes clear. Assuming, of course, you can see the full URL and it hasn’t been chopped off as in the Twitter example from earlier, shouldn’t it be quite easy for end users to identify that something isn’t right?
Let’s get a bit more creative:
This will execute in exactly the same fashion as the previous URL but the intent has been obfuscated by a combination of redundant query string parameters which draw attention away from the malicious one combined with URL encoding the redirect value which makes it completely illegible. The point is that you can’t expect even the most diligent users to spot a potential invalidated redirect attack embedded in a URL.
Just in case this sounds very theoretical, it’s precisely the attack which was mounted against eBay some time back. In fact this particular attack mirrored my example from earlier on in terms of using an obfuscated URL with the eBay domain to then redirect to an arbitrary site with eBay branding and asked for credentials (note the URL). Take this address:
Which redirected to this page:
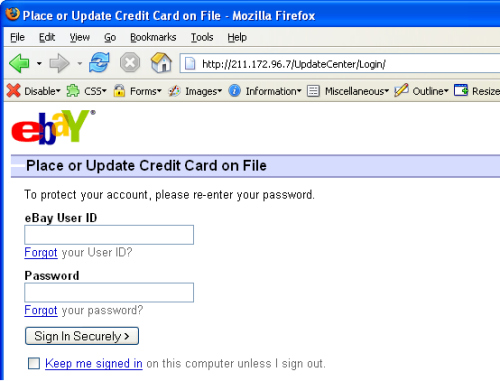
And there you have it: unvalidated redirect being exploited in the wild.
Unvalidated redirects contention
Despite the potential exploitation and impact of this risk being broadly known, it continues to occur in many sites which should know better. Google is one of these and a well-crafted URL such as this remains vulnerable:
http://www.google.com/local/add/changeLocale?currentLocation=http://troyhunt.com
But interestingly enough, Google knows about this and is happy to allow it. In fact they explicitly exclude URL redirection from their vulnerability rewards program. They see some advantages in openly allowing unvalidated redirects and clearly don’t perceive this as a risk worth worrying about:
Consequently, the reward panel will likely deem URL redirection reports as non-qualifying: while we prefer to keep their numbers in check, we hold that the usability and security benefits of a small number of well-implemented and carefully monitored URL redirectors tend to outweigh the perceived risks.
The actual use-case for Google allowing this practice isn’t clear; it’s possible there is a legitimate reason for allowing it. Google also runs a vast empire of services consumed in all sorts of fashions and whilst there may be niche uses for this practice, the same can rarely be said of most web applications.
Still, their defence of the practice also seems a little tenuous, especially when they claim a successful exploit depends on the fact that user’s “will be not be attentive enough to examine the contents of the address bar after the navigation takes place”. As we’ve already seen, similar URLs or those obfuscated with other query string parameters can easily fool even diligent users.
Unvalidated redirects tend to occur more frequently than you’d expect for such an easily mitigated risk. I found one on hp.com just last week, ironically whilst following a link to their WebInspect security tool:
I’m not sure whether HP take the same stance as Google or not, but clearly this one doesn’t seem to be worrying them (although the potential XSS risk of the “exit_text” parameter probably should).
Summary
Finishing the Top 10 with the lowest risk vulnerability that even Google doesn’t take seriously is almost a little anticlimactic. But clearly there is still potential to use this attack vector to trick users into disclosing information or executing files with the assumption that they’re performing this activity on a legitimate site.
Google’s position shouldn’t make you complacent. As with all the previous 9 risks I’ve written about, security continues to be about applying layers of defence to your application. Frequently, one layer alone presents a single point of failure which can be avoided by proactively implementing multiple defences, even though holistically they may seem redundant.
Ultimately, unvalidated redirects are easy to defend against. Chances are your app won’t even exhibit this behaviour to begin with, but if it does, whitelist validation and referrer checking are both very simple mechanisms to stop this risk dead in its tracks.
Resources
- Open redirectors: some sanity
- Common Weakness Enumeration: URL Redirection to Untrusted Site
- Anti-Fraud Open Redirect Detection Service
OWASP Top 10 for .NET developers series
|
1. Injection |