
If your app uses a web server, a framework, an app platform, a database, a network or contains any code, you’re at risk of security misconfiguration. So that would be all of us then.
The truth is, software is complex business. It’s not so much that the practice of writing code is tricky (in fact I’d argue it’s never been easier), but that software applications have so many potential points of vulnerability. Much of this is abstracted away from the software developer either by virtue of it being the domain of other technology groups such as server admins or because it’s natively handled in frameworks, but there’s still a lot of configuration placed squarely in the hands of the developer.
This is where security configuration (or misconfiguration, as it may be), comes into play. How configurable settings within the app are handled – not code, just configurations – can have a fundamental impact on the security of the app. Fortunately, it’s not hard to lock things down pretty tightly, you just need to know where to look.
Defining security misconfiguration
This is a big one in terms of the number of touch points a typical app has. To date, the vulnerabilities looked at in the OWASP Top 10 for .NET developers series have almost entirely focussed on secure practices for writing code or at the very least, aspects of application design the developer is responsible for.
Consider the breadth of security misconfiguration as defined by OWASP:
Good security requires having a secure configuration defined and deployed for the application, frameworks, application server, web server, database server, and platform. All these settings should be defined, implemented, and maintained as many are not shipped with secure defaults. This includes keeping all software up to date, including all code libraries used by the application.
This is a massive one in terms of both the environments it spans and where the accountability for application security lies. In all likelihood, your environment has different roles responsible for operating systems, web servers, databases and of course, software development.
Let’s look at how OWASP sees the vulnerability and potential fallout:
| Threat Agents | Attack Vectors | Security Weakness | Technical Impacts | Business Impact | |
| Exploitability EASY | Prevalence COMMON | Detectability EASY | Impact MODERATE | ||
| Consider anonymous external attackers as well as users with their own accounts that may attempt to compromise the system. Also consider insiders wanting to disguise their actions. | Attacker accesses default accounts, unused pages, unpatched flaws, unprotected files and directories, etc. to gain unauthorized access to or knowledge of the system. | Security misconfiguration can happen at any level of an application stack, including the platform, web server, application server, framework, and custom code. Developers and network administrators need to work together to ensure that the entire stack is configured properly. Automated scanners are useful for detecting missing patches, misconfigurations, use of default accounts, unnecessary services, etc. | Such flaws frequently give attackers unauthorized access to some system data or functionality. Occasionally, such flaws result in a complete system compromise. | The system could be completely compromised without you knowing it. All your data could be stolen or modified slowly over time. Recovery costs could be expensive. | |
Again, there’s a wide range of app touch points here. Given that this series is for .NET developers, I’m going to pointedly focus on the aspects of this vulnerability that are directly within our control. This by no means suggests activities like keeping operating system patches current is not essential, it is, but it’s (hopefully) a job that’s fulfilled by the folks whose job it is to keep the OS layer ticking along in a healthy fashion.
Keep your frameworks up to date
Application frameworks can be a real bonus when it comes to building functionality quickly without “reinventing the wheel”. Take DotNetNuke as an example; here’s a mature, very broadly used framework for building content managed websites and it’s not SharePoint, which is very good indeed!
The thing with widely used frameworks though, is that once a vulnerability is discovered, you now have a broadly prevalent security problem. Continuing with the DNN example, we saw this last year when an XSS flaw was discovered within the search feature. When the underlying framework beneath a website is easily discoverable (which it is with DNN), and the flaw is widely known (which it quickly became), we have a real problem on our hands.
The relationship to security misconfiguration is that in order to have a “secure” configuration, you need to stay abreast of changes in the frameworks you’re dependent on. The DNN situation wasn’t great but a fix came along and those applications which had a process defined around keeping frameworks current were quickly immunised.
Of course the concept of vulnerabilities in frameworks and the need to keep them current extends beyond just the third party product; indeed it can affect the very core of the .NET framework. It was only a couple of months ago that the now infamous padding oracle vulnerability in ASP.NET was disclosed and developers everywhere rushed to defend their sites.
Actually the Microsoft example is a good one because it required software developers, not server admins, to implement code level evasive action whilst a patch was prepared. In fact there was initial code level guidance followed by further code level guidance and eventually followed by a patch after which all prior defensive work needed to be rolled back.
The point with both the DNN and the Microsoft issues is that there needs to be a process to keep frameworks current. In a perfect world this would be well formalised, reliable, auditable monitoring of framework releases and speedy response when risk was discovered. Of course for many people, their environments will be significantly more casual but the objective is the same; keep the frameworks current!
One neat way to keep libraries current within a project is to add them as a library package reference using NuGet. It’s still very early days for the package management system previously known as NuPack but there’s promise in its ability to address this particular vulnerability, albeit not the primary purpose it sets out to serve.
To get started, just jump into the Extension Manager in Visual Studio 2010 and add it from the online gallery:
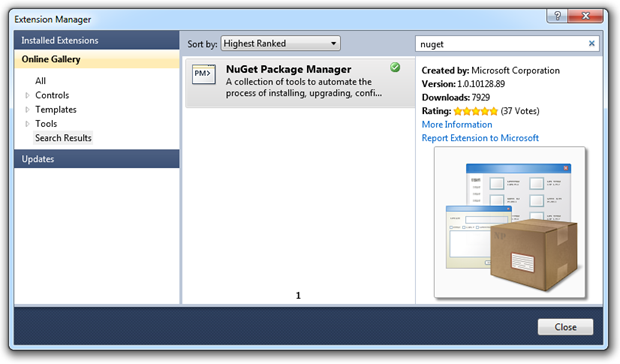
Which gives you a new context menu in the project properties:
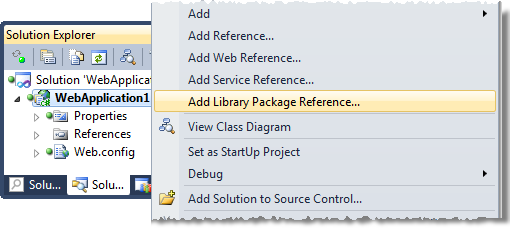
That then allows you to find your favourite packages / libraries / frameworks:
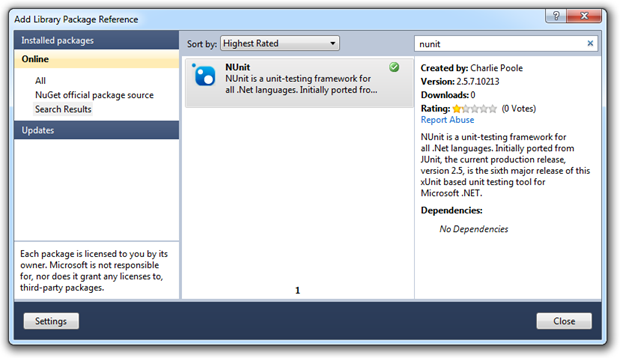
Resulting in a project which now has all the usual NUnit bits (referenced to the assemblies stored in the “packages” folder at the root of the app), as well as a sample test and a packages.config file:
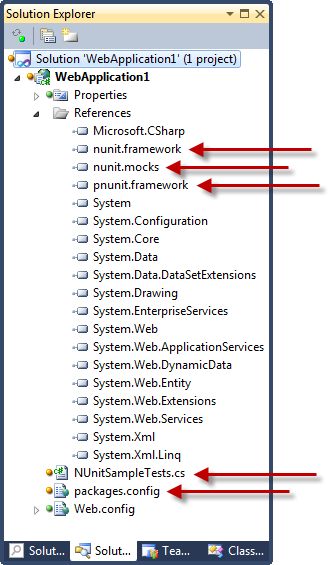
Anyway, the real point of all this in the context of security misconfiguration is that at any time we can jump back into the library package reference dialog and easily check for updates:
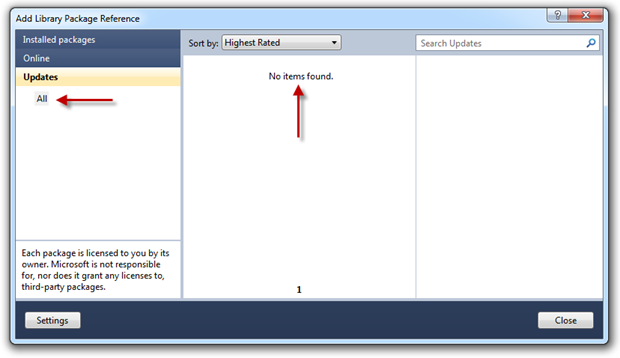
From a framework currency perspective, this is not only a whole lot easier to take updates when they’re available but also to discover them in the first place. Positive step forward for this vulnerability IMHO.
Customise your error messages
In order to successfully exploit an application, someone needs to start building a picture of how the thing is put together. The more pieces of information they gain, the clearer the picture of the application structure is and the more empowered they become to start actually doing some damage.
This brings us to the yellow screen of death, a sample of which I’ve prepared below:
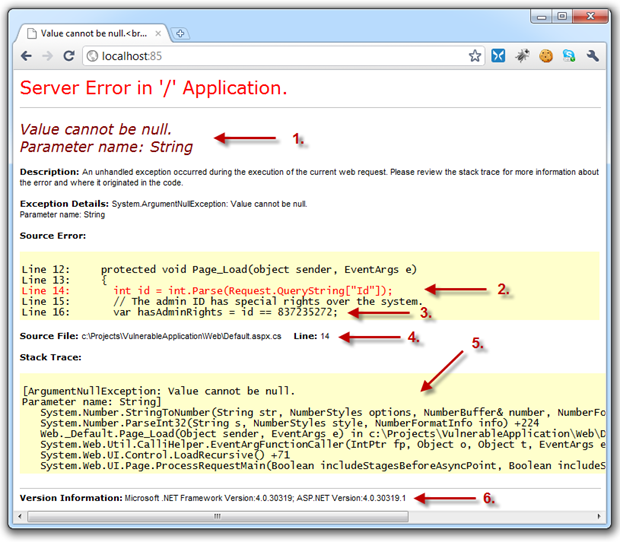
I’m sure you’ve all seen this before but let’s just pause for a bit and consider the internal implementation information being leaked to the outside world:
- The expected behaviour of a query string (something we normally don’t want a user manipulating)
- The internal implementation of how a piece of untrusted data is handled (possible disclosure of weaknesses in the design)
- Some very sensitive code structure details (deliberately very destructive so you get the idea)
- The physical location of the file on the developers machine (further application structure disclosure)
- Entire stack trace of the error (disclosure of internal events and methods)
- Version of the .NET framework the app is executing on (discloses how the app may handle certain conditions)
The mitigation is simple and pretty broadly known; it’s just a matter of turning custom errors on in the system.web element of the Web.config:
<customErrors mode="On" />
But is this enough? Here’s what the end user sees:
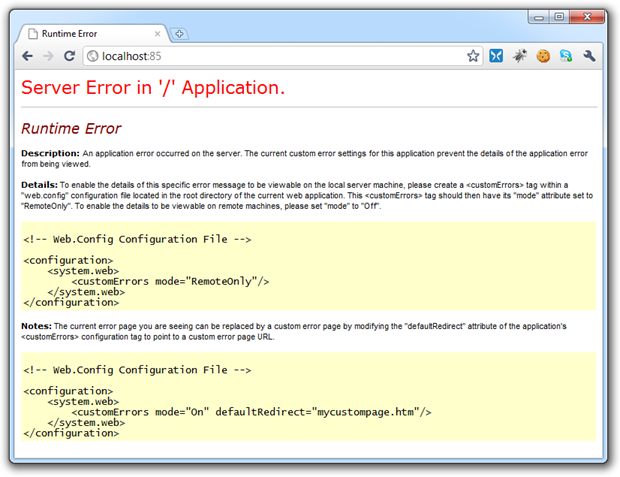
But here’s what they don’t see:
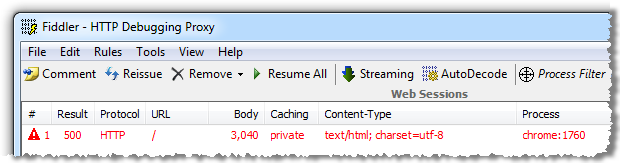
What the server is telling us in the response headers is that an internal server error – an HTTP 500 – has occurred. This in itself is a degree of internal information leakage as it’s disclosing that the request has failed at a code level. This might seem insignificant, but it can be considered low-hanging fruit in that any automated scanning of websites will quickly identify applications throwing internal errors are possibly ripe for a bit more exploration.
Let’s define a default redirect and we’ll also set the redirect mode to ResponseRewrite so the URL doesn’t change (quite useful for the folks that keep hitting refresh on the error page URL when the redirect mode is ResponseRedirect):
<customErrors mode="On" redirectMode="ResponseRewrite" defaultRedirect="~/Error.aspx" />
Now let’s take a look at the response headers:
A dedicated custom error page is a little thing, but it means those internal server errors are entirely obfuscated both in terms of the response to the user and the response headers. Of course from a usability perspective, it’s also a very good thing.
I suspect one of the reasons so many people stand up websites with Yellow Screens of Death still active has to do with configuration management. They may well be aware of this being an undesirable end state but it’s simply “slipped through the cracks”. One really easy way of mitigating against this insecure configuration is to set the mode to “RemoteOnly” so that error stack traces still bubble up to the page on the local host but never on a remote machine such as a server:
<customErrors mode="RemoteOnly" redirectMode="ResponseRewrite" defaultRedirect="~/Error.aspx" />
But what about when you really want to see those stack traces from a remote environment, such as a test server? A bit of configuration management is the way to go and config transforms are the perfect way to do this. Just set the configuration file for the target environment to turn custom errors off:
<customErrors xdt:Transform="SetAttributes(mode)" mode="Off" />
That’s fine for a test environment which doesn’t face the public, but you never want to be exposing stack traces to the masses so how do you get this information for debugging purposes? There’s always the server event logs but of course you’re going to need access to these which often isn’t available, particularly in a managed hosting environment.
Another way to tackle this issue is to use ASP.NET health monitoring and deliver error messages with stack traces directly to a support mailbox. Of course keep in mind this is a plain text medium and ideally you don’t want to be sending potentially sensitive data via unencrypted email but it’s certainly a step forward from exposing a Yellow Screen of Death.
All of these practices are pretty easy to implement but they’re also pretty easy to neglect. If you want to be really confident your stack traces are not going to bubble up to the user, just set the machine.config of the server to retail mode inside the system.web element:
<deployment retail="true" />
Guaranteed not to expose those nasty stack traces!
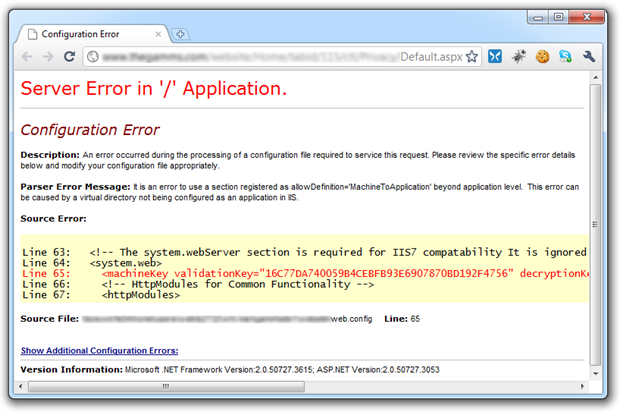
One last thing while I’m here; as I was searching for material to go into another part of this post, I came across the site below which perfectly illustrates just how much potential risk you run by allowing the Yellow Screen of Death to make an appearance in your app. If the full extent of what’s being disclosed below isn’t immediately obvious, have a bit of a read about what the machineKey element is used for. Ouch!
Get those traces under control
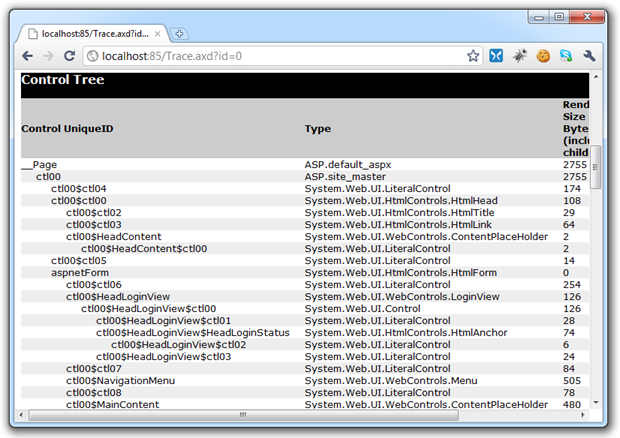
ASP.NET tracing can be great for surfacing diagnostic information about a request, but it’s one of the last things you want exposed to the world. There are two key areas of potential internal implementation leakage exposed by having tracing enabled, starting with information automatically exposed in the trace of any request such as the structure of the ASPX page as disclosed by the control tree:
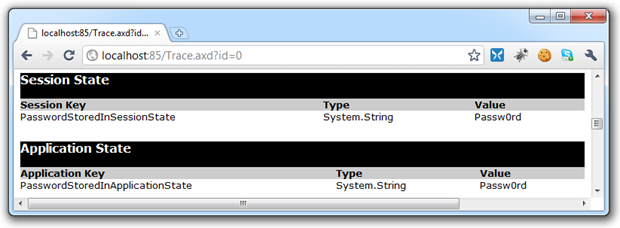
Potentially sensitive data stored in session and application states:
Server variables including internal paths:
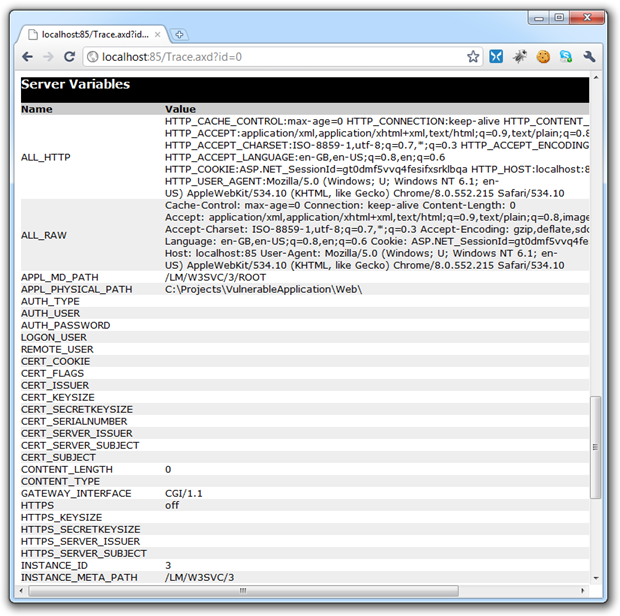
The .NET framework versions:
Secondly, we’ve got information explicitly traced out via the Trace.(Warn|Write) statements, for example:
var adminPassword = ConfigurationManager.AppSettings["AdminPassword"]; Trace.Warn("The admin password is: " + adminPassword);
Which of course yields this back in the Trace.axd:
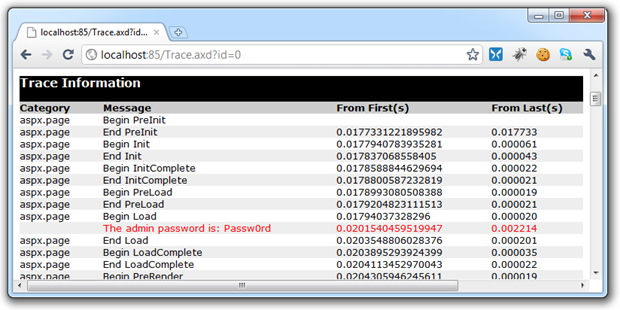
Granted, some of these examples are intentionally vulnerable but they illustrate the point. Just as with the previous custom errors example, the mitigation really is very straight forward. The easiest thing to do is to simply set tracing to local only in the system.web element of the Web.config:
<trace enabled="true" localOnly="true" />
As with the custom errors example, you can always keep it turned off in live environments but on in a testing environment by applying the appropriate config transforms. In this case, local only can remain as false in the Web.config but the trace element can be removed altogether in the configuration used for deploying to production:
<trace xdt:Transform="Remove" />
Finally, good old retail mode applies the same heavy handed approach to tracing as it does to the Yellow Screen of Death so enabling that on the production environment will provide that safety net if a bad configuration does accidentally slip through.
Disable debugging
Another Web.config setting you really don’t want slipping through to customer facing environments is compilation debugging. Scott Gu examines this setting in more detail in his excellent post titled Don’t run production ASP.NET Applications with debug=”true” enabled where he talks about four key reasons why you don’t want this happening:
- The compilation of ASP.NET pages takes longer (since some batch optimizations are disabled)
- Code can execute slower (since some additional debug paths are enabled)
- Much more memory is used within the application at runtime
- Scripts and images downloaded from the WebResources.axd handler are not cached
Hang on; does any of this really have anything to do with security misconfiguration? Sure, you don’t want your production app suffering the sort of issues Scott outlined above but strictly speaking, this isn’t a direct security risk per se.
So why is it here? Well, I can see a couple of angles where it could form part of a successful exploit. For example, use of the “DEBUG” conditional compilation constant in order to only execute particular statements whilst we’re in debug mode. Take the following code block:
#if DEBUG Page.EnableEventValidation = false; #endif
Obviously in this scenario you’re going to drop the page event validation whilst in debug mode. The point is not so much about event validation, it’s that there may be code written which is never expected to run in the production environment and doing so could present a security risk. Of course it could also present a functionality risk; there could well be statements within the “#if” block which could perform actions you never want happening in a production environment.
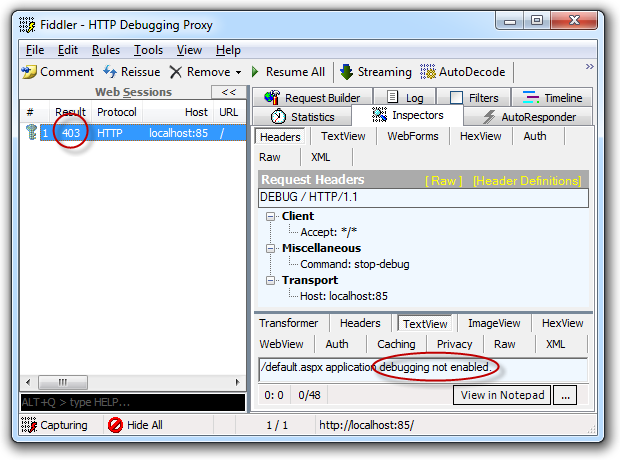
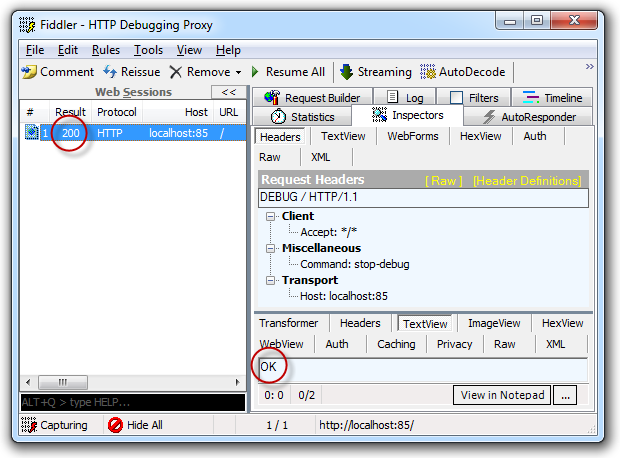
The other thing is that when debug mode is enabled, it’s remotely detectable. All it takes is to jump over to Fiddler or any other tool that can construct a custom HTTP request like so:
DEBUG / HTTP/1.1
Host: localhost:85
Accept: */*
Command: stop-debug
And the debugging state is readily disclosed:
Or (depending on your rights):
But what can you do if you know debugging is enabled? I’m going to speculate here, but knowing that debugging is on and knowing that when in debug mode the app is going to consume a lot more server resources starts to say “possible service continuity attack” to me.
I tried to get some more angles on this from Stack Overflow and from the IT Security Stack Exchange site without getting much more than continued speculation. Whilst there doesn’t seem to be a clear, known vulnerability – even just a disclosure vulnerability – it’s obviously not a state you want to leave your production apps in. Just don’t do it, ok?!
Last thing on debug mode; the earlier point about setting the machine in retail mode also disables debugging. One little server setting and custom errors, tracing and debugging are all sorted. Nice.
Request validation is your safety net – don’t turn it off!
One neat thing about a platform as well rounded and mature as the .NET framework is that we have a lot of rich functionality baked right in. For example, we have a native defence against cross-site scripting (XSS), in the form of request validation.
I wrote about this earlier in the year in my post about Request Validation, DotNetNuke and design utopia with the bottom line being that turning it off wasn’t a real sensible thing to do, despite a philosophical school of thought along the lines of “you should always be validating untrusted data against a whitelist anyway”. I likened it to turning off the traction control in a vehicle; there are cases where you want to do but you better be damn sure you know what you’re doing first.
Getting back to XSS, request validation ensures that when a potentially malicious string is sent to the server via means such as form data or query string, the safety net is deployed (traction control on – throttle cut), and the string is caught before it’s actually processed by the app.
Take the following example; let’s enter a classic XSS exploit string in a text box then submit the page to test if script tags can be processed.
It looks like this: <script>alert('XSS');</script>
And here’s what request validation does with it:
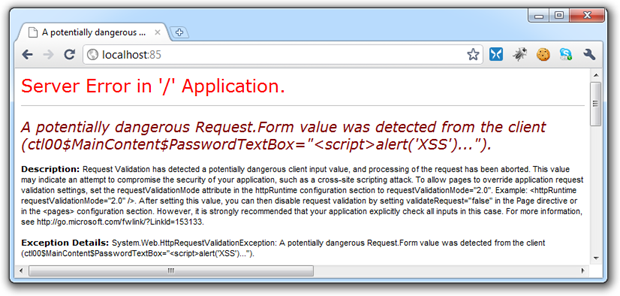
I’ve kept custom errors off for the sake of showing the underlying server response and as you can see, it’s none too happy with the string I entered. Most importantly, the web app hasn’t proceeded with processing the request and potentially surfacing the untrusted data as a successful XSS exploit. The thing is though, there are folks who aren’t real happy with ASP.NET poking its nose into the request pipeline so they turn it off in the system.web element of the Web.config:
<httpRuntime requestValidationMode="2.0" /> <pages validateRequest="false" />
Sidenote: changes to request validation in .NET4 means it needs to run in .NET2 request validation mode in order to turn it off altogether.
If there’s really a need to pass strings to the app which violate request validation rules, just turn it off on the required page(s):
<%@ Page ValidateRequest="false" %>
However, if you’re going to go down this path, you want to watch how you handle untrusted data very, very carefully. Of course you should be following practices like validation against a whitelist and using proper output encoding anyway, you’re just extra vulnerable to XSS exploits once you don’t have the request validation safety net there. There’s more info on protecting yourself from XSS in OWASP Top 10 for .NET developers part 2: Cross-Site Scripting (XSS).
Encrypt sensitive configuration data
I suspect this is probably equally broadly known yet broadly done anyway; don’t put unencrypted connection strings or other sensitive data in your Web.config! There are just too many places where the Web.config is exposed including in source control, during deployment (how many people use FTP without transport layer security?), in backups or via a server admin just to name a few. Then of course there’s the risk of disclosure if the server or the app is compromised, for example by exploiting the padding oracle vulnerability we saw a few months back.
Let’s take a typical connection string in the Web.config:
<connectionStrings> <add name="MyConnectionString" connectionString="Data Source=MyServer;Initial Catalog=MyDatabase;User ID=MyUsername;Password=MyPassword"/> </connectionStrings>
Depending on how the database server is segmented in the network and what rights the account in the connection string has, this data could well be sufficient for any public user with half an idea about how to connect to a database to do some serious damage. The thing is though, encrypting these is super easy.
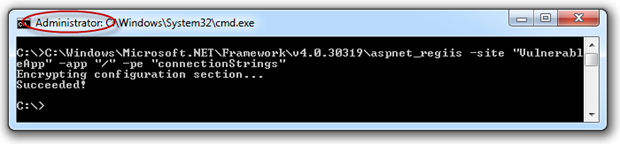
At its most basic, encryption of connection strings – or other elements in the Web.config, for that matter – is quite simple. The MSDN Walkthrough: Encrypting Configuration Information Using Protected Configuration is a good place to start if this is new to you. For now, let’s just use the aspnet_regiis command with a few parameters:
C:\Windows\Microsoft.NET\Framework\v4.0.30319\aspnet_regiis -site "VulnerableApp" -app "/" -pe "connectionStrings"
What we’re doing here is specifying that we want to encrypt the configuration in the “VulnerableApp” IIS site, at the root level (no virtual directory beneath here) and that it’s the “connectionStrings” element that we want encrypted. We’ll run this in a command window on the machine as administrator. If you don’t run it as an admin you’ll likely find it can’t open the website.
Here’s what happens:
You can also do this programmatically via code if you wish. If we now go back to the connection string in the Web.config, here’s what we find:
<connectionStrings configProtectionProvider="RsaProtectedConfigurationProvider"> <EncryptedData Type="http://www.w3.org/2001/04/xmlenc#Element" xmlns="http://www.w3.org/2001/04/xmlenc#"> <EncryptionMethod Algorithm= "http://www.w3.org/2001/04/xmlenc#tripledes-cbc" /> <KeyInfo xmlns="http://www.w3.org/2000/09/xmldsig#"> <EncryptedKey xmlns="http://www.w3.org/2001/04/xmlenc#"> <EncryptionMethod Algorithm= "http://www.w3.org/2001/04/xmlenc#rsa-1_5" /> <KeyInfo xmlns="http://www.w3.org/2000/09/xmldsig#"> <KeyName>Rsa Key</KeyName> </KeyInfo> <CipherData> <CipherValue> Ousa3THPcqKLohZikydj+xMAlEJO3vFbMDN3o6HR0J6u28wgBYh3S2WtiF7LeU/r U2RZiX0p3qW0ke6BEOx/RSCpoEc8rry0Ytbcz7nS7ZpqqE8wKbCKLq7kJdcD2OTK qSTeV3dgZN1U0EF+s0l2wIOicrpP8rn4/6AHmqH2TcE= </CipherValue> </CipherData> </EncryptedKey> </KeyInfo> <CipherData><
CipherValue>
eoIzXNpp0/LB/IGU2+Rcy0LFV3MLQuM/cNEIMY7Eja0A5aub0AFxKaXHUx04gj37nf7E
ykP31dErhpeS4rCK5u8O2VMElyw10T1hTeR9INjXd9cWzbSrTH5w/QN5E8lq+sEVkqT9
RBHfq5AAyUp7STWv4d2z7T8fOopylK5C5tBeeBBdMNH2m400aIvVqBSlTY8tKbmhl+am
jiOPav3YeGw7jBIXQrfeiOq4ngjiJXpMtKJcZQ/KKSi/0C6lwj1s6WLZsEomoys=
</CipherValue>
</CipherData>
</EncryptedData>
</connectionStrings>
Very simple stuff. Of course keep in mind that the encryption needs to happen on the same machine as the decryption. Remember this when you’re publishing your app or configuring config transforms. Obviously you also want to apply this logic to any other sensitive sections of the Web.config such as any credentials you may store in the app settings.
Apply the principle of least privilege to your database accounts
All too often, apps have rights far exceeding what they actually need to get the job done. I can see why – it’s easy! Just granting data reader and data writer privileges to a single account or granting it execute rights on all stored procedures in a database makes it really simple to build and manage.
The problem, of course, is that if the account is compromised either by disclosure of the credentials or successful exploit via SQL injection, you’ve opened the door to the entire app. Never mind that someone was attacking a publicly facing component of the app and that the admin was secured behind robust authentication in the web layer, if the one account with broad access rights is used across all components of the app you’ve pretty much opened the floodgates.
Back in OWASP Top 10 for .NET developers part 1: Injection I talked about applying the principal of least privilege:
In information security, computer science, and other fields, the principle of least privilege, also known as the principle of minimal privilege or just least privilege, requires that in a particular abstraction layer of a computing environment, every module (such as a process, a user or a program on the basis of the layer we are considering) must be able to access only such information and resources that are necessary to its legitimate purpose.
From a security misconfiguration perspective, access rights which look like this are really not the way you want your app set up:
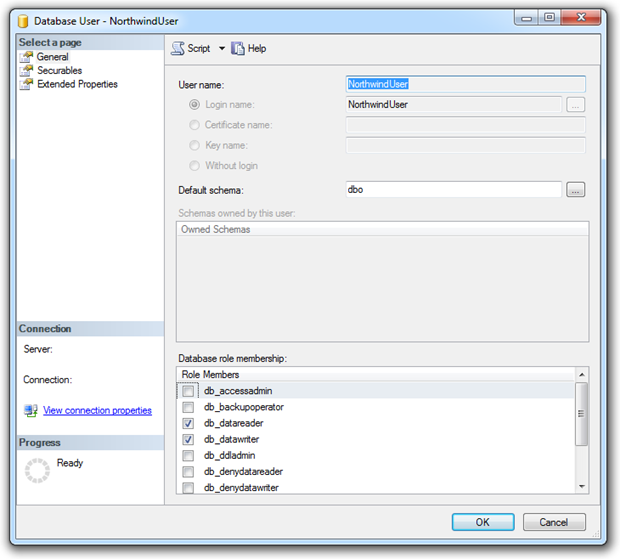
A single account used by public users with permissions to read any table and write to any table. Of course most of the time the web layer is going to control what this account is accessing. Most of the time.
If we put the “least privilege” hat on, the access rights start to look more like this:
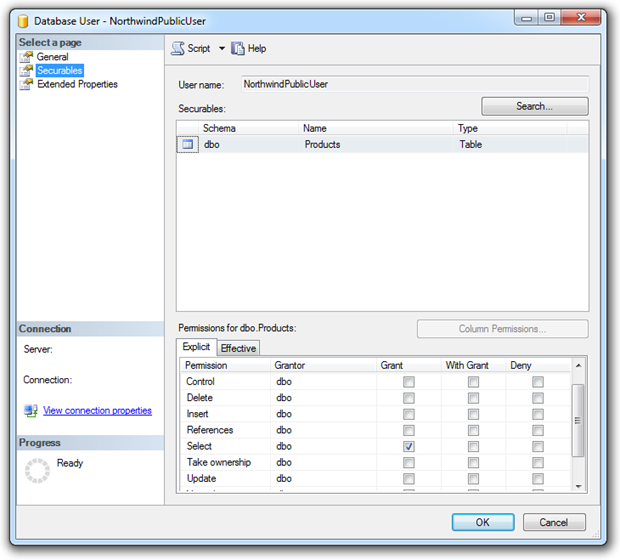
This time the rights are against the “NorthwindPublicUser” account (the implication being there may be other accounts such as “NorthwindAdminUser”), and select permissions have explicitly been granted on the “Products” table. Under this configuration, an entirely compromised SQL account can’t do any damage beyond just reading out some product data.
For example, if the app contained a SQL injection flaw which could otherwise be leveraged to read the “Customers” table, applying the principal of least privilege puts a stop to that pretty quickly:
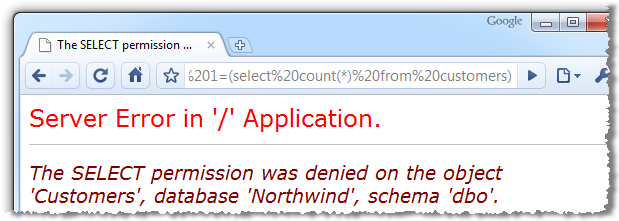
Of course this is not an excuse to start relaxing on the SQL injection front, principals such as input validation and parameterised SQL as still essential; the limited access rights just give you that one extra layer of protection.
Summary
This is one of those vulnerabilities which makes it a bit hard to point at one thing and say “There – that’s exactly what security misconfiguration is”. We’ve discussed configurations which range from the currency of frameworks to the settings in the Web.config to the access rights of database accounts. It’s a reminder that building “secure” applications means employing a whole range of techniques across various layers of the application.
Of course we’ve also only looked at mitigation strategies directly within the control of the .NET developer. As I acknowledged earlier on, the vulnerability spans other layers such as the OS and IIS as well. Again, they tend to be the domain of other dedicated groups within an organisation (or taken care of by your hosting provider), so accountability normally lies elsewhere.
What I really like about this vulnerability (as much as a vulnerability can be liked!), is that the mitigation is very simple. Other than perhaps the principal of least privilege on the database account, these configuration settings can be applied in next to no time. New app, old app, it’s easy to do and a real quick win for security. Very good news for the developer indeed!
Resources
- Deployment Element (ASP.NET Settings Schema)
- Request Validation - Preventing Script Attacks
- Walkthrough: Encrypting Configuration Information Using Protected Configuration