As time has gone by, one of the things I've enjoyed the most in running Have I Been Pwned (HIBP) is seeing how far I could make the dollars stretch. How big can it go whilst at the same time, running it on a shoestring? I keep finding new ways of optimising cost and the two most significant contributions to that since launching almost 5 years ago have come via serverless technology provided by 2 of my favourite tech companies: Cloudflare and Microsoft.
By way of (very brief) background, one of the features in HIBP is Pwned Passwords. This is a repository of 517M passwords from previous data breaches that organisations can refer to in order to stop people from using passwords which have previous been breached (the launch blog post talks about why that's important). When V2 of the service launched earlier this year, Cloudflare came up with a really neat anonymity model which meant you could query the API with a fragment of a hash of the password (just the first 5 chars) and get back enough info to establish whether the entire hash is in the database or not. It's called k-anonymity and it's awesome, so much so that it's also being used as the underlying model for Firefox and 1Password to query email addresses.
The mechanics of querying Pwned Passwords via k-anonymity essentially boils down to there being 16^5 (just over 1 million) different possible queries that can be run with each one returning an average of 493 records (because there's 517M in total). The challenge is how to make that super fast because many organisations are now in-lining Pwned Passwords checks into their registration, login and password change flows. I've written before about how I made this so fast so I won't go into detail again here (essentially it's a combination of Cloudflare cache, Azure Functions and Blob Storage as the underlying data structure), instead, I want to focus on the real cost of running the thing.
Let's start with the big picture: in the week leading up to writing this post, there were 32,408,715 queries sent to the API:
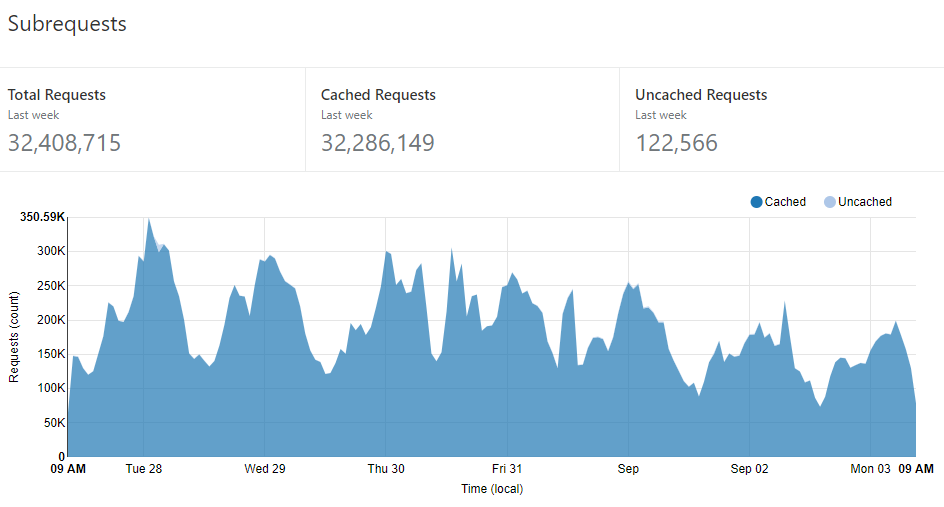
This stat is from Cloudflare and every request is routed through them so it's the most reliable number to refer to in terms of total traffic volume. (Incidentally, in case you previously saw me talking about a steady 8M-10M per day, it turns out that due to the way I'm using Cloudflare Workers there was double-counting. Cloudflare recently changed their reporting to consider this and the stats above are now correct.) The really important one, however, is the number of cached requests at 32,286,149. That's absolutely critical because it means that 99.62% of all requests were served directly from their infrastructure and never even hit Azure. That means two very awesome things, the first of which is that almost every single request is served from one of these purple dots:
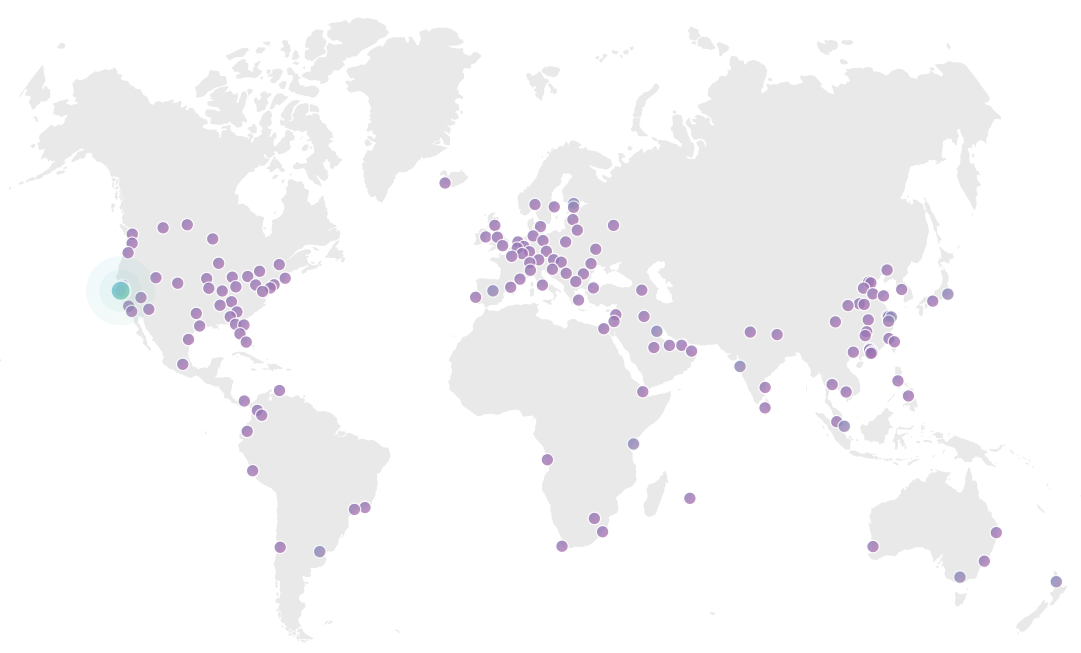
As of today, there's 152 Cloudflare edge nodes around the world and obviously, if you can return a request directly from the nearest one of those to the client rather than routing back to the origin website, that's going to help speed enormously. But that's just the beginning:
We're not anywhere close to done with @Cloudflare's network expansion. Here's our plan for turning up data centers in 250 cities and get within less than 10 milliseconds of 99% of the global population. pic.twitter.com/eZqgS9oJnJ
— Matthew Prince (@eastdakota) July 22, 2018
As their global network expands further, the value proposition improves. When almost every single request to the Pwned Passwords API is already returned from cache, what will that do to perf when 99% of clients are within 10ms of that data? Very, very good things. In fact, I was reminded of this just yesterday when Stefán Jökull Sigurðarson sent Junade Ali from Cloudflare (he came up with the k-anonymity model for Pwned Passwords and has been instrumental in optimising the caching) and I the following DM:
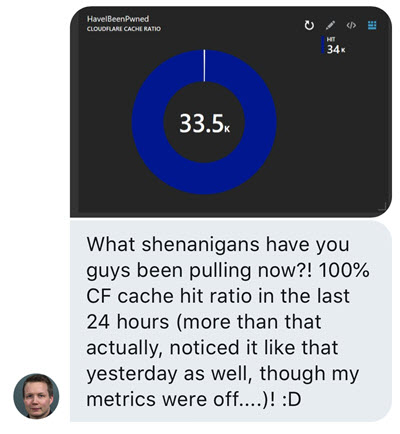
Stefán was the guy responsible for integrating Pwned Password into EVE Online, one of the use cases I wrote about in Pwned Passwords in Practice a few months ago. He's been really actively tracking the cache hit ratio seen at their end by watching for the "cf-cache-status" response header and recording hits versus misses. Unfortunately, this appears to be a round error on his part because I'm only getting 99.82% in my stats over the last 24 hours ?
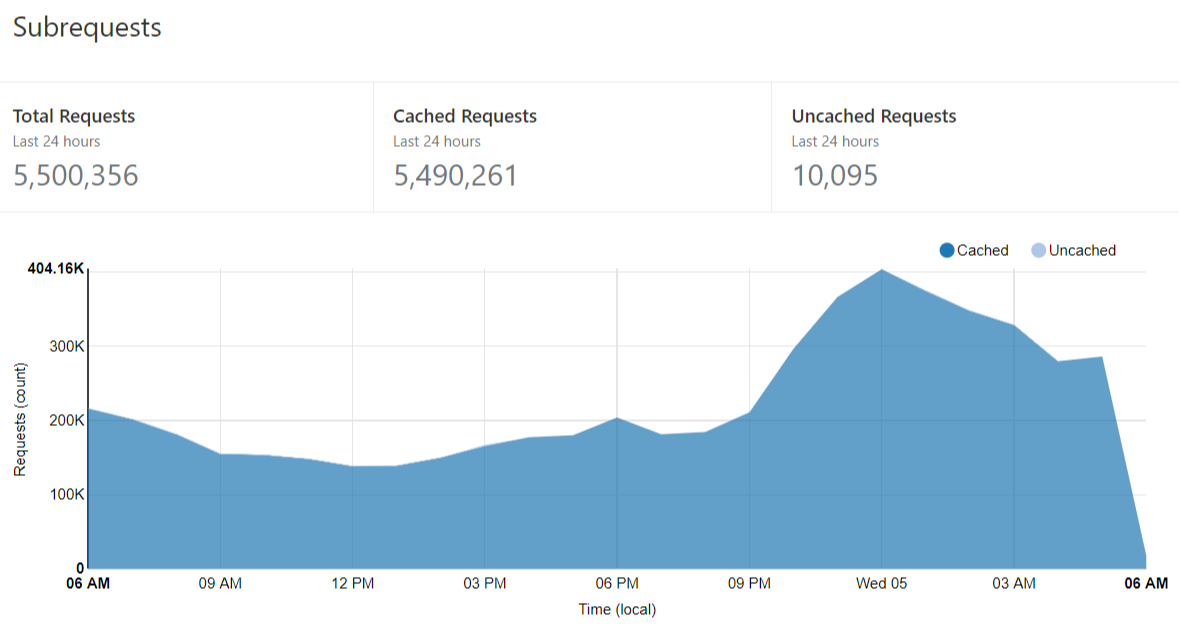
The point being that massively high cache hit ratios delight customers! This level of performance is what makes my service viable for them in the way they're using it today.
The second awesome thing is that the 99.62% cache hit ratio over that week led directly to a 99.62% reduction in requests to the origin website compared to not having Cloudflare in the picture. Or to put it another way, without Cloudflare I'd need to support 264 times more requests to support exactly the same traffic volumes. In turn, when you pay per execution of the API that then leads to a 99.62% reduction in cost. Now there are other costs which don't scale in this fashion (such as storage), but as you'll see later, that's a negligible number anyway.
One question that's come up a lot when I share stats on the Cloudflare model on how many requests are cached is "But what would Cloudflare cost if you had to pay for it yourself?" They've been great with providing resources for HIBP (both services and people expertise), but I've also wanted to ensure the other projects I run don't benefit from any support they've provided me that isn't available to everyone else (such as this blog which runs on the free tier). To that effect, Why No HTTPS runs on the free plan which is precisely what you can go and get your hands on right now and put your website behind in a few minutes Here's the cache hit ratio it's been achieving:
When I've written about really high cache-hit ratios on @haveibeenpwned courtesy of @Cloudflare, some people have suggested it's due to higher-level plans. Here's https://t.co/Y4GlsInvu2 running on the *free* plan: 99.0% cache hit ratio on requests and 99.5% on bandwidth. Free! pic.twitter.com/pP0wo7qKF3
— Troy Hunt (@troyhunt) July 31, 2018
Of course, this is very much down to the design of the app and both Pwned Passwords and Why No HTTPS benefit from really only serving static content. But the point is that there are massive levels of efficiency available completely for free and as you'll see later, even if the cache hit ratio was much lower, the cost would still be peanuts due to the efficiency of Azure Functions.
Next up is Cloudflare Workers and this brings us to the "serverless" part of the post. By running code "on the edge" at each of those 152 Cloudflare edge nodes, there's further efficiencies to be had. I'm just going to show you the code then talk about why it helps:
There are really 2 things happening here:
- Any OPTIONS requests are replied to directly from the edge. This means that not only do I not have to serve that traffic from the origin, but I don't even need to support that verb.
- The casing of the hash prefix is normalised, specifically by converting them all to uppercase. This ensures that no matter how someone searches the API, caching is maximised because hash prefix f89ea becomes equivalent to hash prefix F89EA.
Workers, however, aren't free:

But that cost is still only in the tens of dollars per month to support 141M requests. Plus, I'd still have a massively high cache hit ratio even without it, I'd just lose the efficiency gained from normalising the case.
Last thing on Cloudflare - it's not just the requests to the origin that they help dramatically reduce, it's the egress bandwidth from Azure as well:
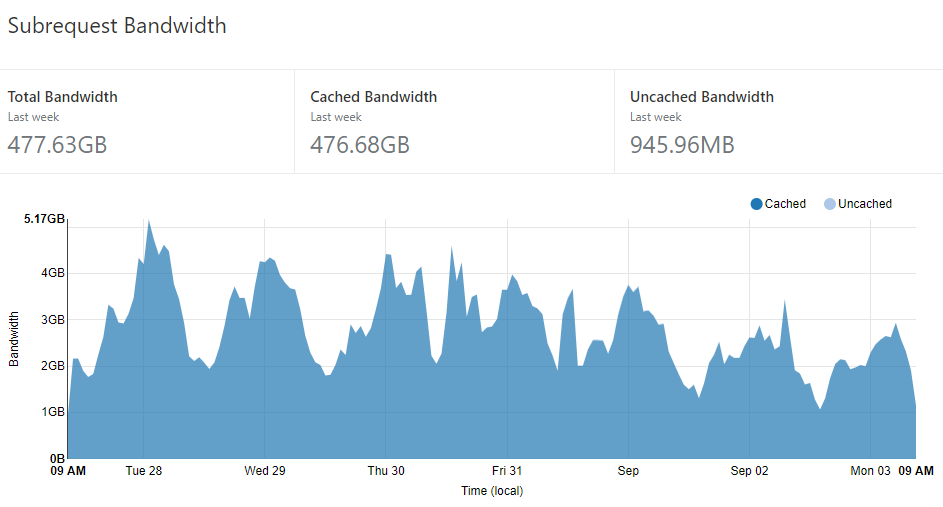
That's 476.68GB worth of data I haven't had to pay Microsoft for. Keeping in mind that you're looking at $0.087 per GB after the first 5 of them, that's approaching a couple of hundred bucks per month and this is with very small, very efficient compressed responses as well. Start serving content such as images and suddenly that number starts getting very big, very quickly. For many sites, even just using Cloudflare as a cache for bulky images could make a big whack of difference to bandwidth costs.
But let's move on because continuing the serverless theme, Azure Functions are a critical component of what makes Pwned Passwords operate so efficiently. I've been using Functions for the last couple of years and Functions, like Cloudflare Worker, are a pay-per-execution model. This is enormously important because you no longer need to ask whether you have enough infrastructure scale to support load, rather you simply open up a direct line to your wallet and let it run! Clearly, that's something you want to be a bit cautious about too (which is why responding to requests from Cloudflare's edge is so valuable), the point is that you get this beautifully linear scale of performance where it just absorbs whatever load you throw at it.
Looking at the function executions for the same period as the earlier Cloudflare graphs, here's what we see over that week:
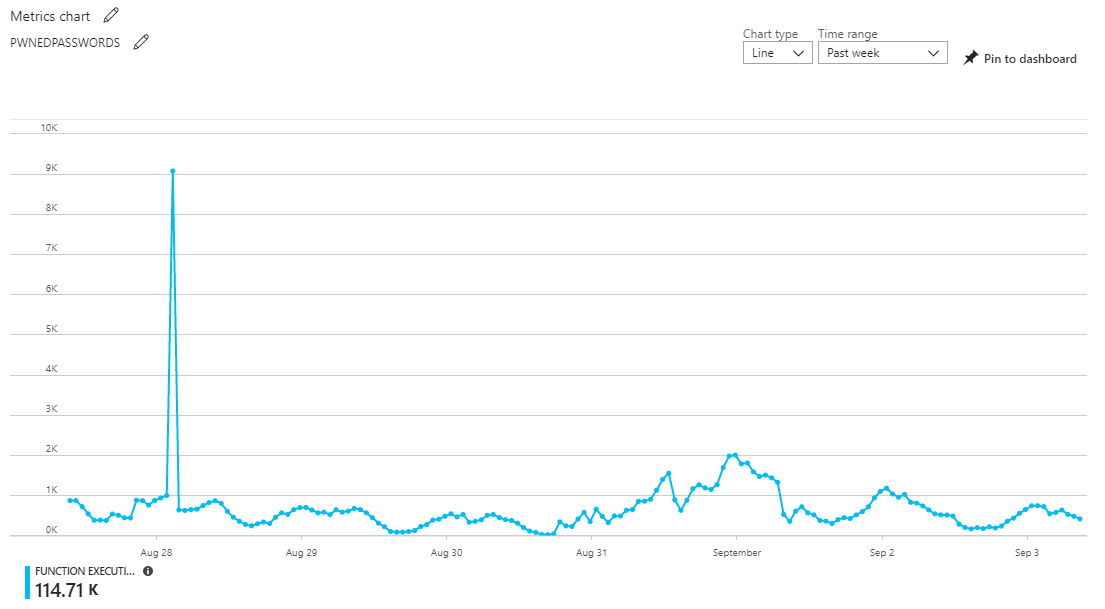
There's 114.71k executions of the function over the 7 days which roughly maps to the distribution of requests in the first Cloudflare graph. (Note: the number doesn't precisely line up with the uncached Cloudflare requests, these charts are often down-sampled or indicative rather than precise.) One interesting anomaly is the spike of traffic towards the beginning which doesn't correspond to a spike at the Cloudflare end. For whatever reason, the cache hit ratio obviously dropped during that short period of time and rather than serving 1k requests as it did over the preceding period, the traffic to the function exploded 9x. That one little spike is actually an awesome example of the Azure Function value proposition over the way I've stood up HIBP APIs in the past, namely as embedded endpoints in the web app. Let me explain:
When you have an Azure App Service website such as the one the HIBP website itself runs on, you have a logical machine. For example, I run that website on an S3 instance which is priced as follows:

If I use 10% of that capacity, I pay 51c an hour. If I use 100% of that capacity, I pay 51c per hour. If I get smashed by requests then the performance starts to degrade until another logical instance is added via auto-scale. Now, hypothetically, I'm using, say, 150% of one S3 instance. Then the traffic suddenly backs off and now I'm paying $1.02 an hour but I'm back to only needing 10% of a single S3 instance. In short, I'm always either paying too much or I don't have enough capacity and right about now, you start thinking "Hang on, wasn't the cloud meant to solve that problem? The one where the physical on-prem servers were always either over or under provisioned?" We made that problem much better with the cloud because we got agility of scale on-demand, but the premise of logical containers with boundaries means you're always either under-utilised and paying too much or maxing it out and suffering performance wise.
Azure Functions running in the consumption model fundamentally change pricing and execution by removing the logical boundaries and just charging you for precisely what you use. The pricing model relies on 2 factors:
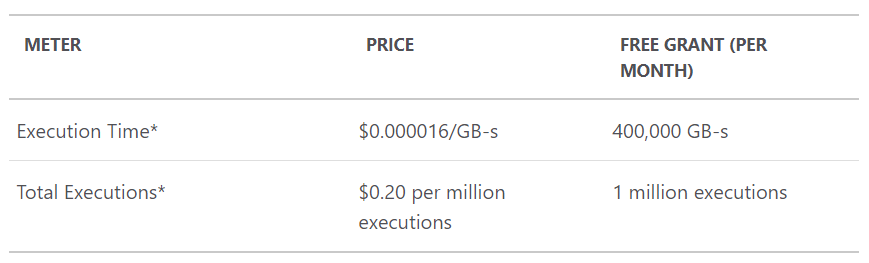
Total executions is the easy one and we know from my earlier graph that this was 114.71k. Execution time is the more interesting one because rather than being about how many times the function executes, it's about how hard the function works. And that's quite fair: a function that executes in 10ms and uses 100k of memory should be a lot cheaper than one that takes a second and consumes a meg of memory. The resource consumption figure is literally just those 2 attributes multiplied out:
Observed resource consumption is calculated by multiplying average memory size in gigabytes by the time in milliseconds it takes to execute the function.
Which all feels very fair because it means that the faster and more efficiently you can make code run, the less you pay. The function execution units for the time period we're dealing with look like this:
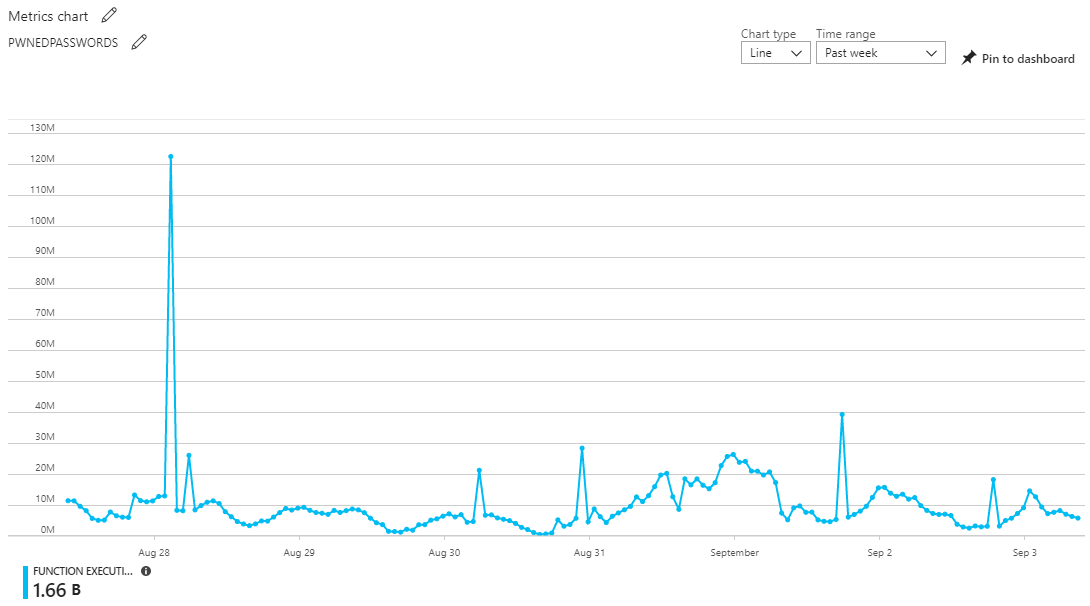
That chart is actually measured in MB-ms and later on you'll see me convert it to GB-s so we can use the pricing chart above. Note also that the pricing model includes a free grant each month: you get to consume 1 million executions and 400,000 GB-s before paying a cent and that'll factor into my pricing later on too.
So working down the stack of the architecture, we've covered Cloudflare, bandwidth and Azure Functions which means the only bit that's left is the storage itself. As I wrote in the blog post about making it fast, all the password hashes sit in blob storage. Each 5-character hexadecimal prefix has its own file so when I push a release, I'm literally just uploading 1.0x million files into a blob container. When the API is hit, it reaches into blob storage and picks up the individual file it needs then sends it out in the response. There are 2 factors that influence the cost of blob storage and I'm going to pull them out of the pricing page and share them here:
- It's $0.0208 per GB to keep the data "hot" in storage, that is to keep it in a construct that's suitable for frequent interactions with it
- It's $0.0044 per 10k read operations of hot storage; every single time the API is hit, there's a read operation as the file in blob storage needs to be retrieved
We can already work out the 2nd value because we know there were 114.71k requests during the week I've been profiling. As for the 1st value, the total size of the 16^5 files is 19.27GB (they're about 19KB each). Which now gives us everything required to share the complete calculations. Here's exactly what it costs me to run Pwned Passwords:
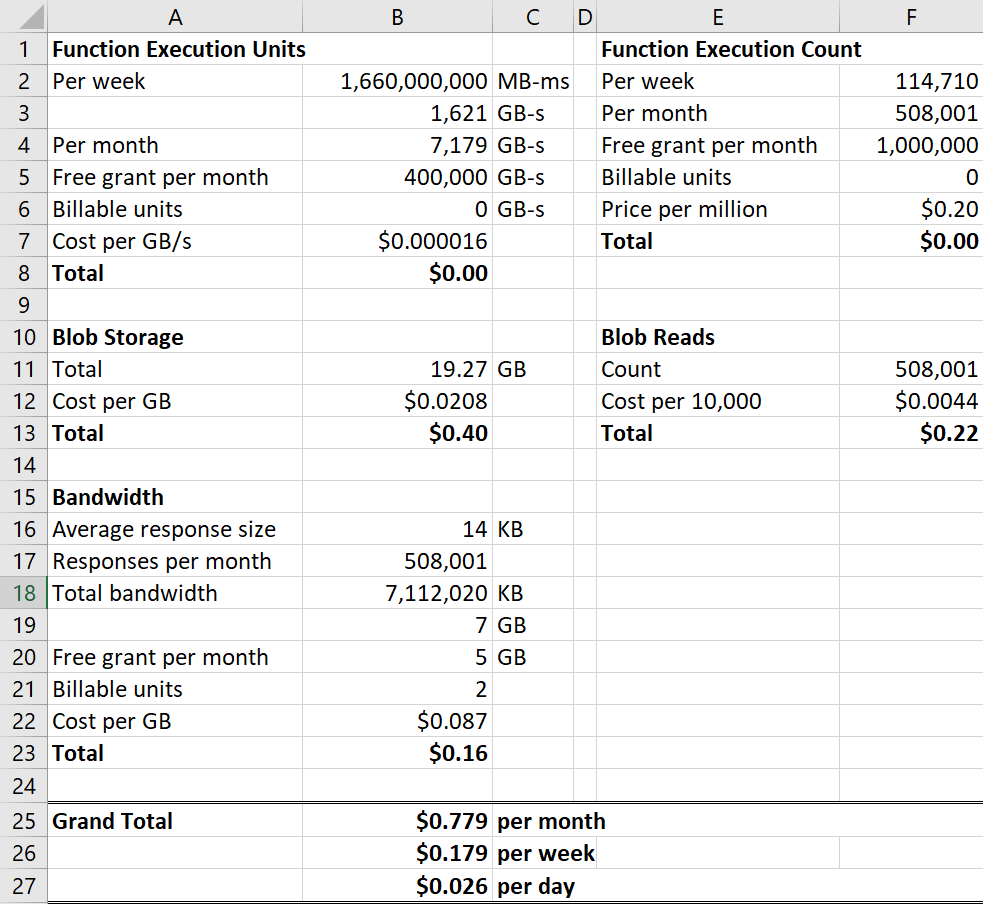
It's costing me 2.6c per day to support 141M monthly queries of 517M records.
Of that cost, 80% of it is going to blob storage but frankly, I think I can wear the total 62c each month for that! The function is totally free because I'm well within the free grants for execution units and counts each month and yes, everyone gets those. But just for kicks, let's imagine there was no Cloudflare - what would the cost be then? I mean what would it be if instead of there being 114.71k requests in that week there were 32,408,715 per the total number of requests that came into Cloudflare? Let's try that and I'll pro-rata out the execution units accordingly:
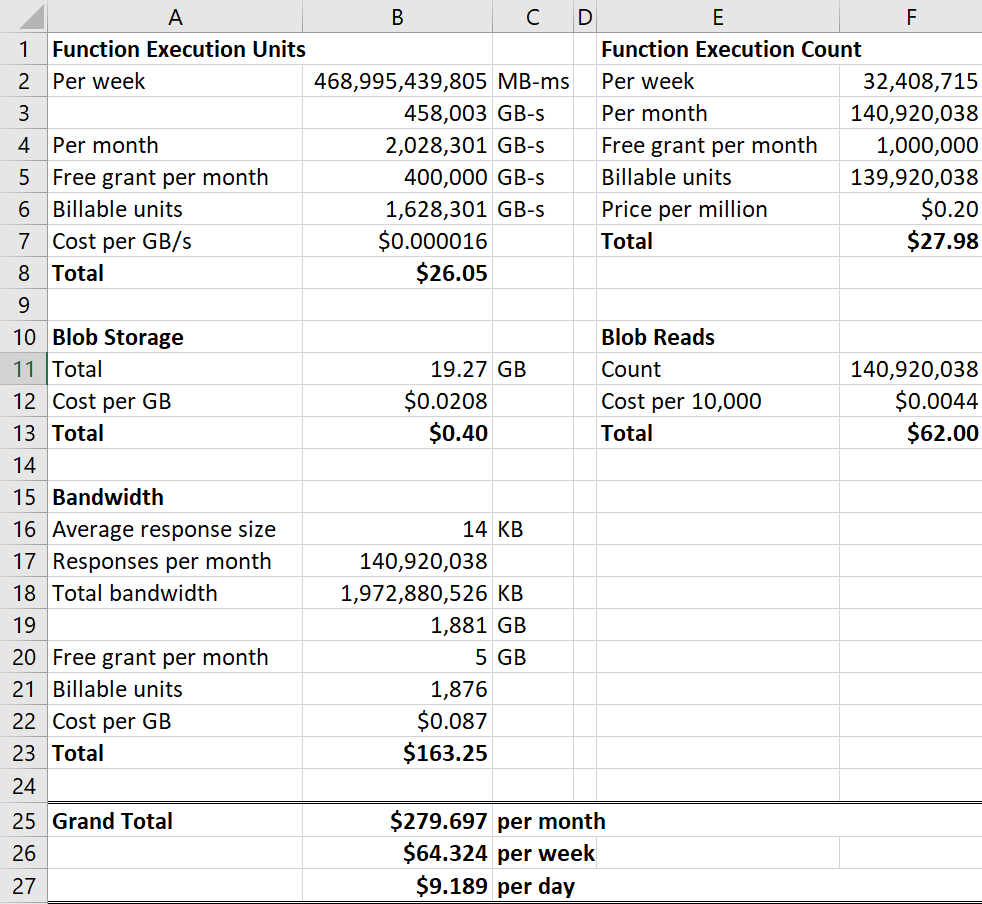
Frankly, I reckon 9 bucks a day is still a ringing endorsement of Azure Functions, especially when you consider the serverless architecture would happily scale to that level. But you wouldn't do this - you shouldn't do this - you'd use Cloudflare and even if it was the totally free tier and you didn't pay for the Worker, I bet the cost would still be down at under a dollar a day because as with Why No HTTPS, you'd still achieve a massive amount of caching for absolutely zero dollars.
So, in summary, the highlights here are:
- Choose the right storage construct to optimise query patterns, performance and cost. It may well be one you don't expect (as blob storage was for me).
- Run serverless on the origin to keep cost down and performance up. Getting away from the constraints of logical infrastructure boundaries means you can do amazing things.
- The fastest, most cost-effective way to serve requests is to respond immediately from the edge. Don't hit the origin server unless you absolutely have to!
That last point is really my number one takeaway from this exercise and I'll summarise it as follows:
The fastest, most cost-effective way of running code on Azure is to avoid hitting Azure!