Pretty much every day, I get a reminder from someone about how little people know about their exposure in data breaches. Often, it's after someone has searched Have I Been Pwned (HIBP) and found themselves pwned somewhere or other. Frequently, it's some long-forgotten site they haven't even thought about in years and also frequently, the first people know of these incidents is via HIBP:
large @ticketfly data breach. thanks @troyhunt for the excellent @haveibeenpwned service that notifies users of #privacy disasters like this :) https://t.co/xgklY59sOU pic.twitter.com/jlqnKXteDG
— Yale Privacy Lab (@YalePrivacyLab) June 4, 2018
Well, that's annoying: @TicketFly data breach attacker publicly posted my info (along w 26MM others). I at least know about it, thx to @haveibeenpwned
— Tim Plas (@TJPlas) June 3, 2018
@ticketfly a heads up would have been nice. Thankfully @troyhunt built an amazing tool ( @haveibeenpwned )for issues like this. Only used you guys once for tickets to a @TravisGreeneTV concert. ???♂️? pic.twitter.com/tcs282i5lA
— Tope Akinwande (@takinwande) June 3, 2018
In cases like Ticketfly, loading the data into HIBP meant notifying 105k of my subscribers. That's out of a subscriber base that just recently ticked over the 2M million mark:
Wow, just realised @haveibeenpwned passed the 2 million *verified* subscribers mark whilst I've been travelling. That's amazing, never expected to see that! pic.twitter.com/uTfoZud7wk
— Troy Hunt (@troyhunt) June 20, 2018
2 million is more than I ever expected, if I'm honest, but it's also only a tiny, tiny drop in the ocean. Of the 5.1 billion records that are in HIBP today, there's 3.1B unique email addresses. I'm reaching 0.06% of them via the notification service and not a whole lot more in terms of people coming to the site and doing an ad hoc search (usually 100k - 200k people a day). Don't get me wrong - I'm enormously happy and personally fulfilled by having been able to do even this - but clearly, I'm barely scratching the surface. However, that scope is about to expand dramatically via 2 new partnerships which I'm announcing today, starting with Firefox:
Mozilla and Firefox Monitor
Last November, there was much press about Mozilla integrating HIBP into Firefox. I was a bit surprised at the time as it was nothing more than their Breach Alerts feature which simply highlighted if the site being visited had previously been in a data breach (it draws this from the freely accessible breach API on HIBP). But the press picked up on some signals which indicated that in the long term, we had bigger plans than that and the whole thing got a heap of very positive attention. I ended up fielding a heap of media calls just on that one little feature - people loved the idea of HIBP in Firefox, even in a very simple form. As it turns out, we had much bigger plans and that's what I'm sharing here today.
Over the coming weeks, Mozilla will begin trialling integration between HIBP and Firefox to make breach data searchable via a new tool called "Firefox Monitor".
Here's what it looks like:
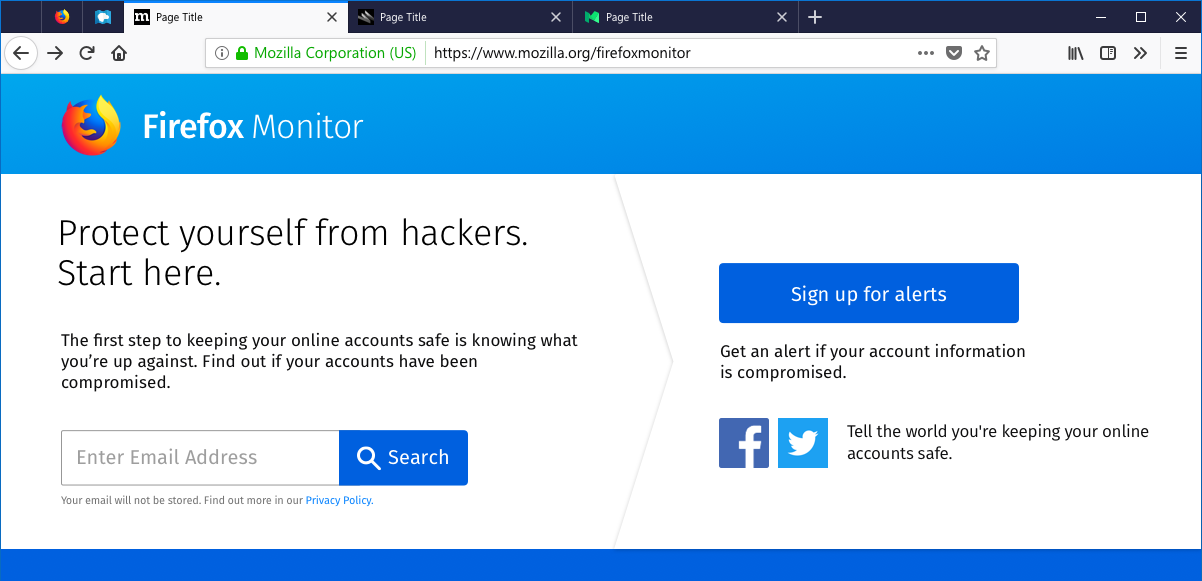
This is major because Firefox has an install base of hundreds of millions of people which significantly expands the audience that can be reached once this feature rolls out to the mainstream. You can read Mozilla's announcement of the new feature and how they plan to conduct the testing and rollout.
I'm really happy to see Firefox integrating with HIBP in this fashion, not just to get it in front of as many people as possible, but because I have a great deal of respect for their contributions to the technology community. In particular, Mozilla was instrumental in the birth of Let's Encrypt, the free and open certificate authority that's massively increased the adoption of HTTPS on the web. Arguably, the work done by Mozilla's Josh Aas and Eric Rescorla (still the Mozilla CTO today) has been one of the greatest contributions to online privacy and security we've seen and Mozilla remains a platinum sponsor to this day. They've also been instrumental in helping define the model which HIBP uses to feed them data without Mozilla disclosing the email addresses being searched for. I'm going to talk more about the mechanics of that model in a moment but first, let me talk about 1Password:
1Password
My relationship with 1Password stretches all the way back to 2011 when I came to the realisation that the only secure password is the one you can't remember. Over the last 7 years, I've continued to buy their product and use it every single day across all my devices and my entire family's devices. In February, only the day after I launched Pwned Passwords V2, 1Password turned around and built it into their product so that users of the password manager could see if their password had been previously exposed in a breach. That effort was a large factor in my choosing 1Password to partner with HIBP back in March and since that time, they've built Pwned Passwords into the desktop apps for Mac and Windows and provided the ability to check all your passwords in one single go. But today, we're announcing something much bigger:
As of now, you can search HIBP from directly within 1Password via the Watchtower feature in the web version of the product.
This helps Watchtower become "mission control" for accounts and introduces the "Breach Report" feature:
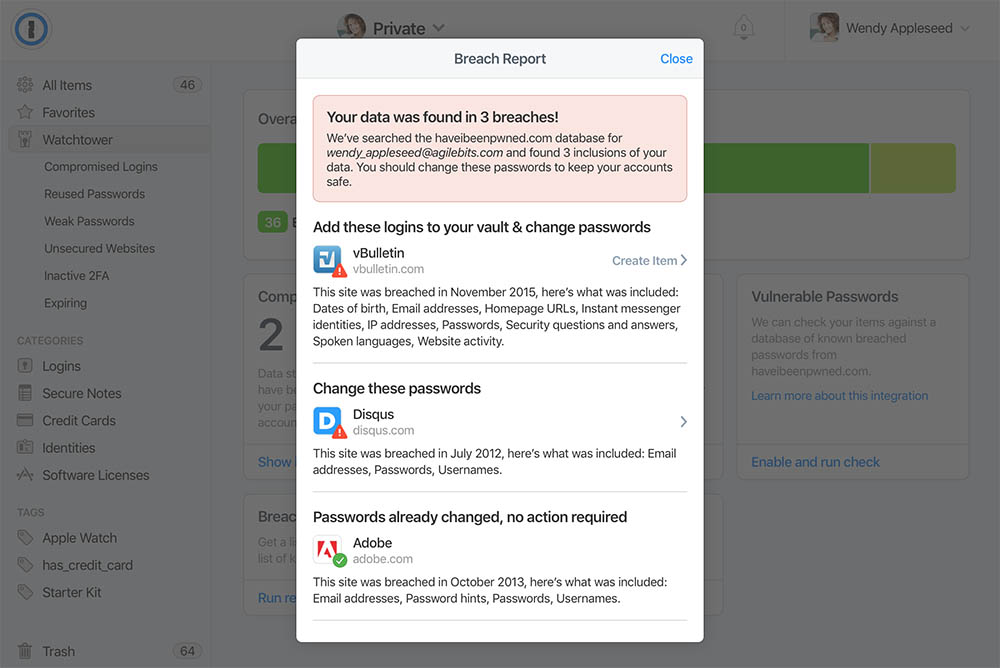
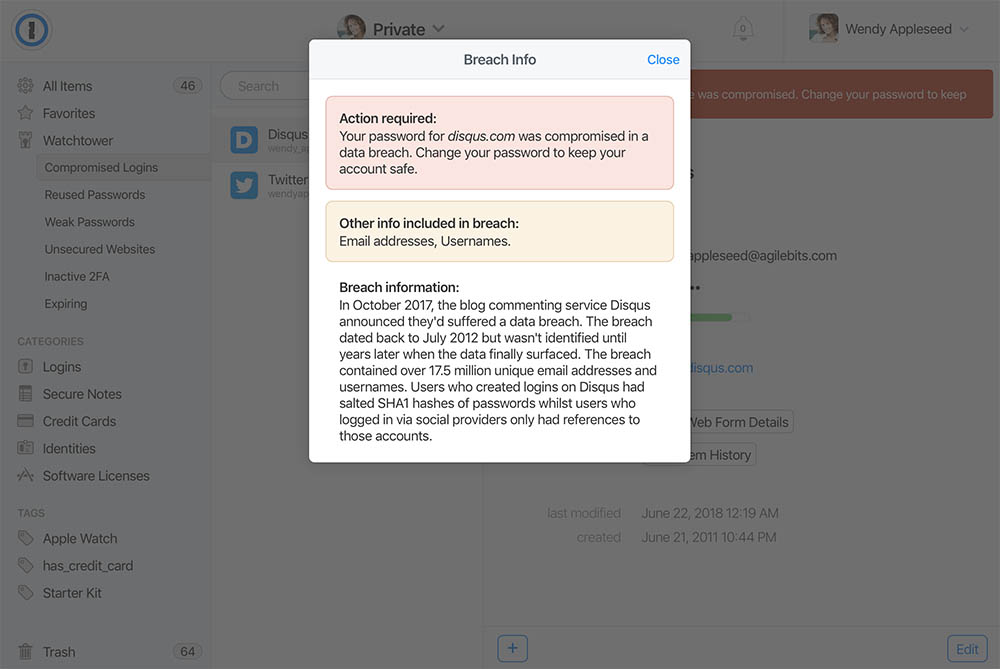
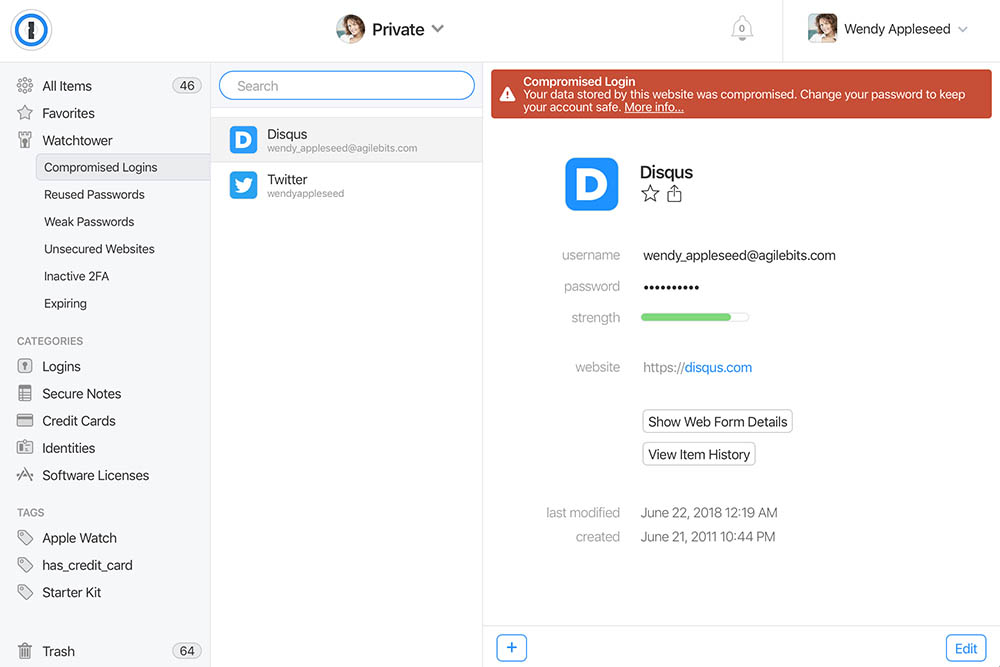
As with Pwned Passwords, by pushing this out in the web-based version of the product they can get it to customers quickly then over time, bake it right into the desktop versions as well. There's also a bunch of other ways 1Password can use the data to streamline how users protect their accounts and that's something we're actively discussing. I expect we'll see the existing functionality enhanced in the not too distant future.
If you're a 1Password user you can use this feature right now, just head on over to the 1Password login page. And if you're not already putting all your passwords in 1Password, go and grab a free trial and give it a go. You can also find a more detailed write-up on 1Password's implementation in the very aptly titled blog post: we shall fight on the breaches (why didn't I ever think of that?!)
Enabling Anonymous Searches with k-Anonymity
I want to talk about protecting the identities of Firefox and 1Password users because more than ever - and regardless of where you are in the world - we're becoming increasingly conscious of our online privacy. We're also becoming increasingly connected and sharing unprecedented volumes of data which, let's face it, isn't exactly analogous with privacy and anonymity! But we can have both and I want to illustrate that by talking about the Pwned Passwords model for a moment.
When this feature launched, Cloudflare (hat-tip again to Junade Ali there) did some great work on a "k-anonymity" model which works like this: when searching HIBP for a password, the client SHA-1 hashes it then takes the first 5 characters and sends this to the API. In response, a collection of hashes is returned that match that prefix (477 on average). By looking at the hash prefix sent to the service, I have no idea what the password is. It could be any one of those 477 or it could be something totally different, I don't know. Of course, I could always speculate based on the prevalence of each password but it would never be anything more than that - speculation. (Just to add to that, I've never got any idea of the username attached to the password either so even if I take an educated guess at it, there's nothing I can actually do with it.)
The email address being searched for by Firefox and 1Password works in the same fashion, albeit it with slightly different numbers due to the significantly larger data set at play. When I processed the source HIBP data in preparation for this feature, out of the 5B records in the system at the time there were 3.1B unique email addresses. (In other words, each address has been in an average of 1.6 data breaches.) I took each one of those 3.1B addresses, hashed it and stored it in a new data construct I'll talk about later. That gave me a repository to search against, now let's cover the mechanics of that search:
For the purposes of anonymity, I needed to decide on how many characters of the SHA-1 hash to allow searching by such that a sufficiently large number was returned to have no reasonable way of knowing which address was searched for, but also for the system to respond quickly. For Pwned Passwords, that number was 5 characters resulting in 16^5 possible search ranges which, across a data set of 500M records, meant the aforementioned 477 results per range. However, if I'd used 5 chars with the 3.1B email addresses, each range would contain an average of almost 3K results which is starting to get pretty sizeable.
Ultimately, I settled on 6 characters which means 16^6 possible ranges with an average of 185 results per range. Now, on the one hand you might say "that's less than Pwned Passwords therefore provides less protection", but it's a bit more nuanced than that. Firstly, because this number will grow significantly over time; more data breaches means more new email addresses means larger results in the range search. More importantly though, email addresses are far less predictable than passwords; as I mentioned earlier, if I was to spy on searches for Pwned Passwords (and I don't, but this is the threat k-anonymity is protecting us from), the prevalence of passwords in the system beginning with that hash can indicate the likelihood of what was searched by. But when we're talking about email addresses, there's no such indicator, certainly the number of breaches each has been exposed in divulges nothing in terms of which one is likely being searched for.
Here's what a search for an email address ultimately looks like:
Address: test@example.com
SHA-1 hash: 567159D622FFBB50B11B0EFD307BE358624A26EE
6 char prefix: 567159
API endpoint: https://[host]/[path]/567159Which results in a response containing the following:

In this case, the searched address is the last one because the hash suffix matches with the SHA-1 hash of test@example.com. The associated websites next to that hash are the ones that the email address appeared in and can be matched back to the full breach details via the public breach list API.
Unlike the way 1Password implements Pwned Passwords by calling the API directly from the client, this model is only consumable by an authenticated request from Firefox's or 1Password's infrastructure. What this means is that consumers only ever call their API then they call HIBP's API. Both these organisations implement all the same controls that HIBP does on the existing public email search API, namely the rate limit, not returning sensitive breaches to non-verified addresses and employing a range of other abuse-protection mechanisms. Why not call the API directly from each client? Let's talk about that next:
The Viability of Using This API Publicly
There's one fundamentally important (and perhaps quite obvious) reason why I don't expect to make this service available publicly: it could massively accelerate enumeration activities. Back in 2016, I implemented a rate limit on the public API to greatly reduce the potential to abuse the service. This meant the ability to check records was limited to 1 request every 1,500ms. If I was to offer the k-anonymity service publicly, that jumps massively to 185 every 1,500ms (and it will grow as the data does) because that's how many results are returned. In fairness, you'd only get back hashed suffixes of email addresses but if someone had a massive list of them they wanted to work through (and that's one of the key patterns the rate limit is designed to curtail), they could hash the lot then grab those first 6 chars of each and get back a bunch of results in one go. Granted, they almost certainly wouldn't have the source email addresses of all 185 returned suffixes, but it still provides a vector to greatly accelerate search rates.
A (somewhat) middle ground, however, would be to allow searching the repository of hashed addresses by complete hash. Rather than the current model which needs a full email address, now that I have a mirrored data set containing only hashes I could always roll the search over to query that repository instead. I could also adapt the web front end to hash an entered email address client-side then only send that to the server. I actually closed a User Voice idea along these lines (and you can read about why in that idea), but now that I have that collection of hashes already in storage, it'd be trivial to stand up an endpoint to query it even if there's not always a lot of privacy upside. The main reason I can't do that immediately is that the email addresses for the paste service are not hashed and the existing search model on the website needs to search both sources.
And just on that, let me refer quickly back to my post on The Ethics of Running a Data Breach Search Service. This explains in detail why the service allows addresses to be searched in the way it presently does and provides both technical and logical reasons. Do read that if you're curious, it was very carefully thought-out and explains the detailed thinking behind it.
Scaling Searches with Azure and Cloudflare
As with the k-anonymity model itself, I've leaned heavily on the Pwned Passwords experience in designing how this model works. Azure Functions provide the API layer (they're serverless and scale beautifully) and Cloudflare does the reverse-proxying and caching. Unfortunately, I can't cache anywhere near as aggressively as with Pwned Passwords because instead of 16^5 different ranges (and therefore unique request patterns), it's 16^6. Also, I have a one-month cache expiration on Pwned Passwords because they rarely change but at present, only a 15-minute cache expiration on the email address search. I didn't want someone searching for a breach I'd just loaded, finding it in HIBP then not finding it in Firefox or 1Password.
One major difference between Pwned Passwords and this feature here is the underlying storage construct. For the passwords, I ended up putting them all in blob storage so there's one file per hash range. That was faster than the original Table Storage construct I used and because the files rarely ever change (I'll probably only update the passwords a couple of times a year), they could remain relatively static files. For emails in breaches, however, I don't have that luxury; breaches are continually loaded into the system and I needed a queryable construct that allowed for fast inserts and reads which means that like the existing HIBP email address storage, the hash ranges for this service are also in Azure Table Storage. It's an entirely separate table to the one that's been there from day one and just holds email addresses so obviously that's also impacted the data load process which now needs to do twice as much record handling.
What this means is that the entire record for test@example.com looks like this:
Partition key: 567159
Row key: D622FFBB50B11B0EFD307BE358624A26EE
Websites: [delimited array of pwned site names]Partitioning in this fashion means that when a search is done, it's easy to return every single suffix for the hash prefix which is used as the partition key. Some quick performance testing last week resulted in the following:
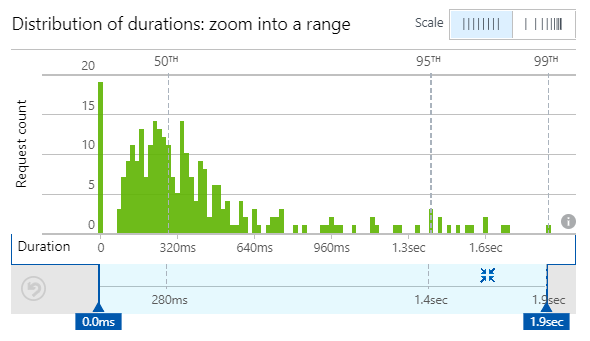
That's fine as a starting point and median load time of 280ms means that even with network latency and processing on Firefox's and 1Password's end should mean results are turned around in well under a second. Functions also seem to accelerate in execution time as infrastructure warms up so I expect we'll only see improvements in this area. I'll share some perf info once the volumes really ramp up.
Finally, like the existing search services and regardless of the fact requests only ever contain 6 characters of a hash, no searches are ever explicitly logged. They'll pass through very short-term transient logs and that's it - all I'll have is very broad-brush stats on things like the number of calls and the duration of executions. So, in summary, everything will be fast, efficient and above all, anonymous.
The Notification Service
Let me talk briefly about one last thing that's on the horizon - notifications. The service above is a point-in-time representation of breach state which is great, but clearly, it's a state that will continue to evolve over time. There needs to be a construct to notify Firefox and 1Password of deltas to the data set as new breaches are loaded so that in the future, they have the ability to offer subscriptions in the same way as the HIBP notification service. Re-querying all the data every time a breach is loaded would be massively inefficient so that's not going to happen, we need to be smarter than that.
A few years back I wrote about a callback model and an equivalent paradigm will be used here. What this boils down to is the ability to subscribe a hash prefix for notifications so in that test@example.com scenario, "567159" would be subscribed then a callback sent to Firefox or 1Password when an address that hashes down to that prefix is loaded. The callback will contain the name of the breach that's just been loaded and all the hash suffixes for that prefix that were found in it.
I'm building that feature out next and in time I expect we'll see that flow through to Firefox and 1Password. It's a neat way of ensuring that anonymity is still protected and that subscribers of those services stay abreast of security incidents that impact them.
Summary
As HIBP grows, I keep coming back to this question:
How can HIBP do good things for people in the wake of bad events?
I'm really happy this initiative furthers that objective and does it in a way that puts privacy first. The leverage these two organisations have to drive positive outcomes in the wake of data breaches is massive and I'm enormously excited to see the impact they both make in partnership with HIBP.