The very first feature I added to Have I Been Pwned after I launched it back in December 2013 was the public API. My thinking at the time was that it would make the data more easily accessible to more people to go and do awesome things; build mobile clients, integrate into security tools and surface more information to more people to enable them to do positive and constructive things with the data. I highlighted 3 really important attributes at the time of launch:
There is no authentication.
There is no rate limiting.
There is no cost.
One of those changed nearly 3 years ago now - I had to add a rate limit. The other 2 are changing today and I want to clearly explain why.
Identifying Abusive API Usage
Let me start with a graph:
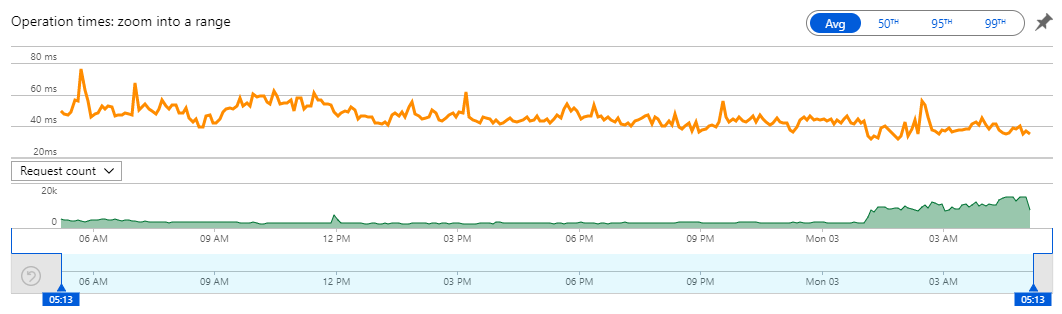
This is executions of the V2 API that enables you to search an individual email address. There's 1.06M requests in that 24 hour period with 491k of them in the last 4 hours. Even with the rate limit of 1 request every 1,500ms per IP address enforced, that graph shows a very clear influx of requests peaking at 14k per minute. How? Well let's pull the logs from Cloudflare and see:
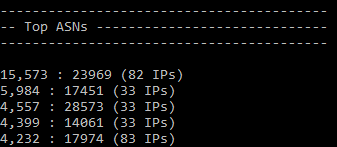
This is the output of a little log analyser I wrote that breaks requests down by ASN (and other metrics) over the past hour. There were 15,573 requests from AS23969 across 82 unique IP addresses. Have a look at where those IP addresses came from:
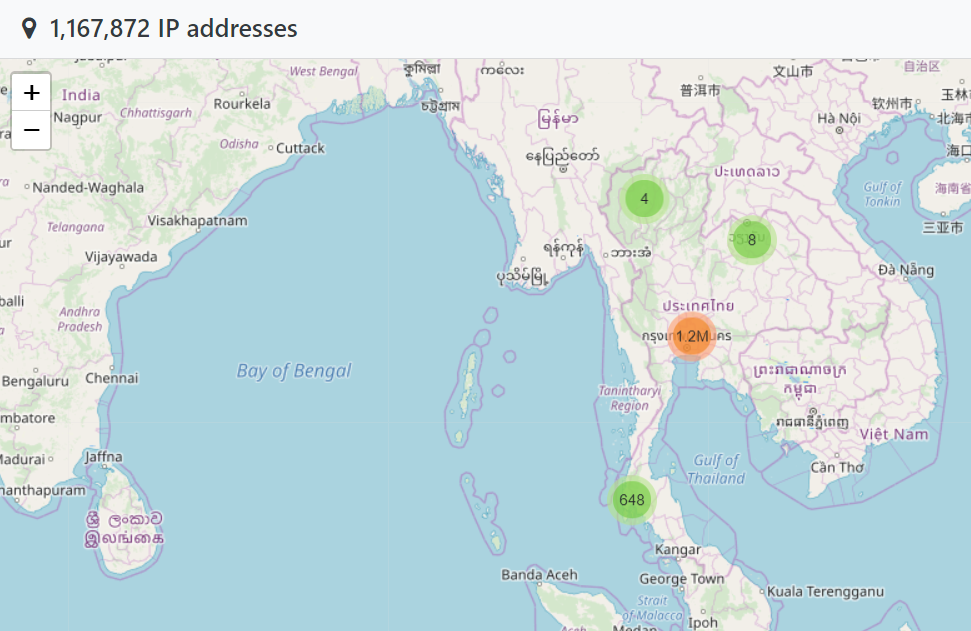
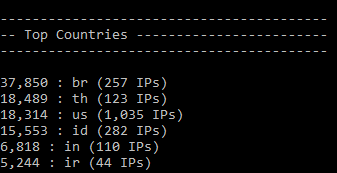
There is no conceivable way that this is legitimate, organic usage of the API from Thailand. The ASN is owned by TOT Public Company Limited, a local Thai telco that somehow, has ended up with a truckload of IP addresses hitting HIBP at just the right rate to not trigger the rate limit. The next top ASN is Biznet Networks in Indonesia. Then Claro in Brazil. After that there's Digital Ocean and then another Indonesian telco, Telkomnet. It makes for a geographical spread that's entirely inconsistent with legitimate usage of genuine consumers (no, HIBP isn't actually big in Iran!):
Late last year after seeing a similar pattern with a well-known hosting provider, I reached out to them to try and better understand what was going on. I provided a bunch of IP addresses which they promptly investigated and reported back to me on:
1- All those servers were compromised. They were either running standalone VPSs or cpanel installations.
2- Most of them were running WordPress or Drupal (I think only 2 were not running any of the two).
3- They all had a malicious cron.php running
This helped me understand the source of the problem, but it didn't get me any closer to actually blocking the abusive behaviour. For the sake of transparency, let me talk about how I tried to tackle this because that will help everyone understand why I've arrived at a very different model to what I started with.
Combating Abuse with Firewall Rules
Firewall rules on Cloudflare are amazingly awesome. It takes just a few seconds to have a rule like this in place:
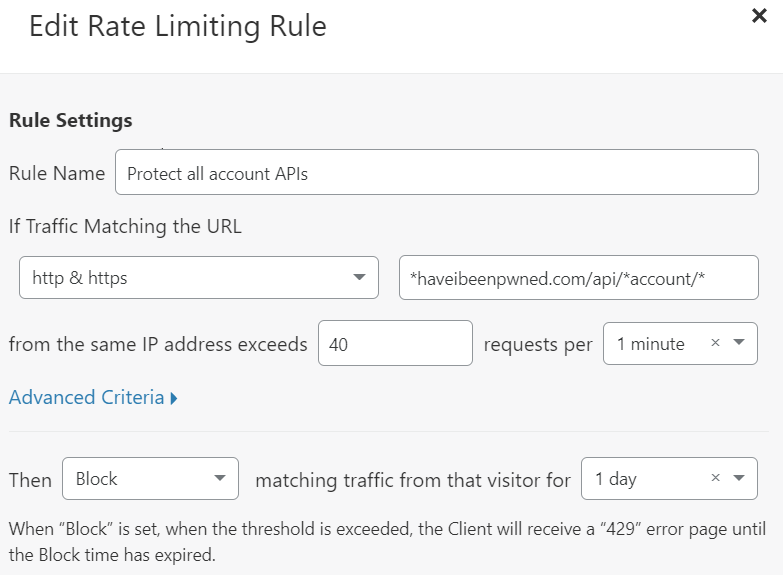
Make more than 40 requests in a minute and you're in the naughty corner for a day. Only thing is, that's IP-based and per the earlier section on abusive patterns, actors with large numbers of IP addresses can largely circumvent this approach. It's still a fantastic turn-key solution that seriously raises the bar for anyone wanting to get around it, but someone determined enough will find a way.
No problems, I'll just take abusive ASNs like the Thai one above and give them the boot. I scripted a lot of them based on patterns in the log files and create a firewall rule like this:
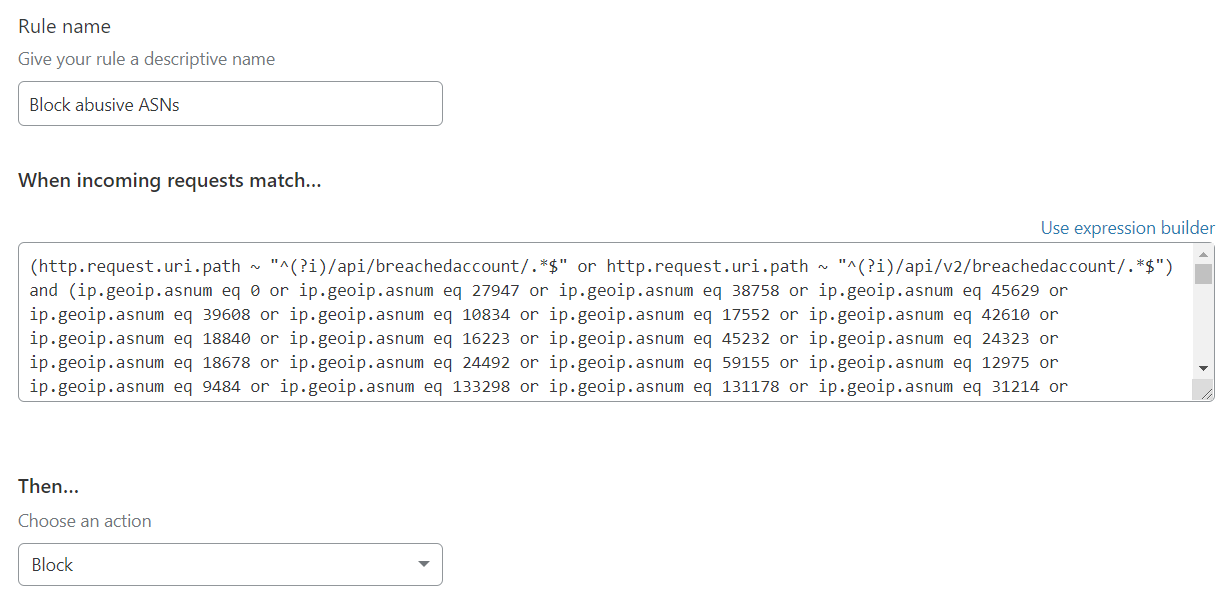
That works pretty quickly and is very effective, except for the fact that there's an awful lot of ASNs out there being abused. Plus, it has side-effects I'll come back to shortly too.
So how about looking at user agent strings instead? I mean could always just block the ones bad actors are using, except that was never going to work particularly well for obvious reasons (you can always define whatever one you like). That said, there were a heap of browser UAs which clearly were (almost) never legitimate for a client making API calls. So I blocked these as well:
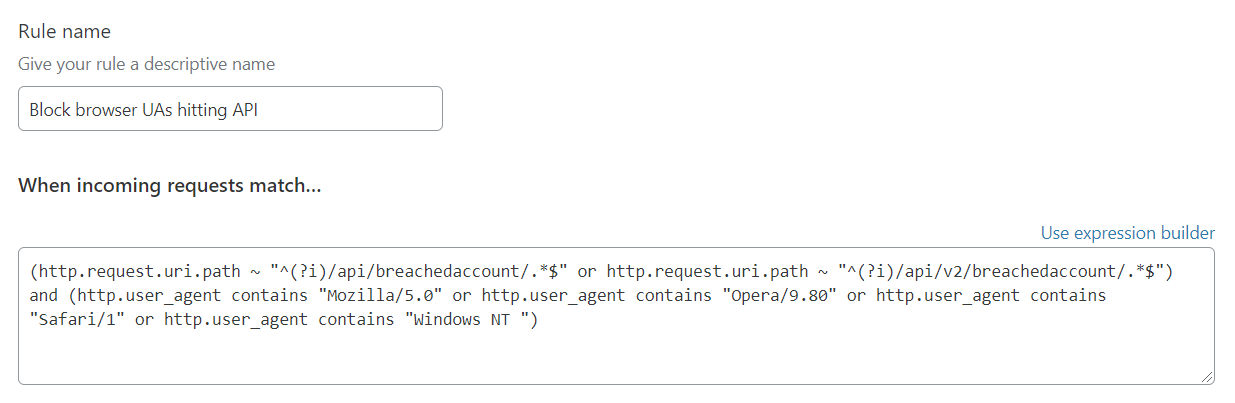
That shouldn't have come as a surprise to anyone as the API docs were actually quite clear about this:
The user agent should accurately describe the nature of the API consumer such that it can be clearly identified in the request. Not doing so may result in the request being blocked.
Problem is, people don't read docs and I ended up with a heap of default user agents (such as curl's) which were summarily blocked. And, of course, the user agent requirement was easily circumvented as I expected it would be and I simply started seeing randomised strings in the UA.
Another approach I toyed with (very transiently) was blocking entire countries from accessing the API. I was always really hesitant to do this, but when 90% of the API traffic was suddenly coming from a country in West Africa, for example, that was a pretty quick win.
I'm only writing about this here now because as the new model comes into place, all of this will be redundant. Plus, I wanted to shed some light on the API behaviour some people may have previously seen which they couldn't quite work out, and that brings me to the next section.
The Impact on Legitimate Usage
The attempts described above to block abuse of the API also blocked a lot of good requests. I feel bad about that because it made something I'd always intended to be easily accessible difficult for some people to use. I hope that by explaining the background here, people will understand why the approaches above were taken and indeed, why the changes I'm going to talk about soon were necessary.
I got way too many emails from people about API requests being blocked to respond to. Often this was due to simply not meeting the API requirements, for example providing a descriptive UA string. Other times it was because they were on the same network as abusive users. There were also those who simply smashed through the rate limit too quickly and got themselves banned for a day. Other times, there were genuine API users in that West African country who found themselves unable to use the service. I was constantly balancing the desire to make the API easily accessible whilst simultaneously trying to ensure it wasn't taken advantage of. In the end, the path forward was clear - the API would need to be authenticated.
The New Model: Authenticated Requests
I held back on this for a long time because adding auth to the API adds a barrier to entry. It also adds coding effort on my end as well as management overhead. However, by earlier this year it became clear that this was the only way forward: requests would have to be auth'd. Doing this solves a heap of problems in one fell swoop:
- The rate limit could be applied to an API key thus solving the problem of abusive actors with multiple IP addresses
- Abuse associated to an IP, ASN, user agent string or country no longer has to impact other requests matching the same pattern
- The rate limit can be just that - a limit rather than also dishing out punishment via the 24 hour block
Making an authenticated call is a piece of cake, you just add an hibp-api-key header as follows:
GET https://haveibeenpwned.com/api/v3/breachedaccount/test@example.com
hibp-api-key: [your key]However, this wasn't going to completely solve the problem, rather it moved the challenge to the way in which API keys were provisioned. It's no good putting controls around the key itself if a bad actor could just come along and register a heap of them. Anti-automation on the form where a key can be requested is one thing, stopping someone from manually registering, say, 20 of them with different email addresses and massively amplifying their request rate is quite another. I had to raise the bar just high enough to dissuade people from doing this, which brings me to the financial side of things.
There's a US$3.50 per Month Fee to Use the API
Clearly not everyone will be happy with this so let me spend a bit of time here explaining the rationale. This fee is first and foremost to stop abuse of the API. The actors I've seen taking advantage of it are highly unlikely to front up with a credit card and provide what amounts to personally identifiable data (i.e. make a credit card payment) in order to mass enumerate the API.
In choosing the $3.50 figure, I wanted to ensure it was a number that was inconsequential to a legitimate user of the service. That's about what a latte costs at my local coffee shop so spending a few bucks a month to search through billions of records seems like a pretty damn good deal, especially when that rate limit enables 57.6k requests per day.
One thing I want to be crystal clear about here is that the $3.50 fee is no way an attempt to monetise something I always wanted to provide for free. I hope the explanation above helps people understand that, and also the fact the API has run the last 5 and a half years without any auth whatsoever clearly demonstrates that financial gain has never been the intention. Plus, the service I'm using to implement auth and rate limits comes with a direct cost to me:
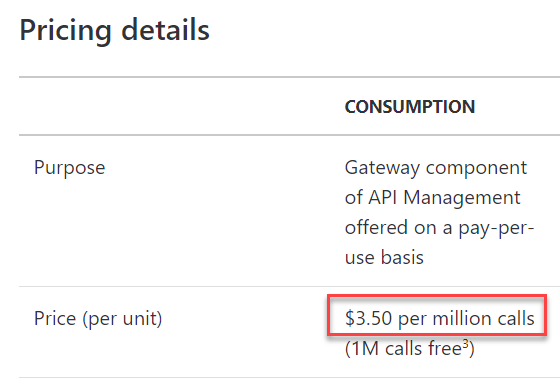
This is from the Azure API Management pricing page which is the service I'm using to provision keys and control rate limits (I'll write a more detailed post on this later on - it's kinda awesome). I chose the $3.50 figure because it represents someone making one million calls. Some people will make much less, some much more - that rate limit represents a possible 1.785 million calls per month. Plus, there's still the costs of function executions, storage queries and egress bandwidth to consider, not to mention the slice of the $3.50 that Stripe takes for processing the payment (all charges are routed through them). The point is that the $3.50 number is pretty much bang on the mark for the cost of providing the service.
What this change does it simultaneously gives me a much higher degree of confidence the API will be used in an ethical fashion whilst also ensuring that those who use it have a much more predictable experience without me dipping deeper and deeper into my own pocket.
The API is Revving to Version 3 (and Has Some Breaking Changes)
With this change, I'm revising the API up to version 3. All documentation on the API page now reflects that and also reflects a few breaking changes, the first of which is obviously the requirement for auth. When using V3, any unauthenticated requests will result in an HTTP 401.
The second breaking change relates to how the versioning is done. Back in 2014, I wrote about how your API versioning is wrong and headlined it with this graphic:

I outlined 3 different possible ways of expressing the desired version in API calls, each with their own technical and philosophical pros and cons:
- Via the URL
- Via a custom request header
- Via the accept header
After 4 and a bit years, by far and away the most popular method with an uptake of more than 90% is versioning via the URL. So that's all V3 supports. I don't care about the philosophical arguments to the contrary, I care about working software and in this case, the people have well and truly spoken. I don't want to have to maintain code and provide support for something people barely use when there's a perfectly viable alternative.
Next, I'm inverting the condition expressed in the "truncateResponse" query string. Previously, a call such as this would return all meta data for a breach:
GET https://haveibeenpwned.com/api/v2/breachedaccount/test@example.comYou'd end up with not just the name of the breach, but also how many records were in it, all the impacted data classes, a big long description and a whole bunch of other largely redundant information. I say "redundant" because if you're hitting the API over and over again, you're pulling but the same info for each account that appears in the same breach. Using the "truncateResponse" parameter reduced the response size by 98% but because it wasn't the default, it wasn't used that much. I want to drive the adoption of small responses because not only are they faster for the consumer, they also reduce my bandwidth bill which is one of the most expensive components of HIBP. You can still pull back all the data for each breach if you'd like, you just need to pass "truncateResponse=false" as true is now the default. (Just a note on that: you're far better off making a single call to get all breached sites in the system then referencing that collection by breach name after querying an individual email address.)
I'm also inverting the "includeUnverified" parameter. The original logic for this was that when I launched the concept of unverified breaches, I didn't want existing consumers of the API to suddenly start getting results for breaches which may not be real. However, with the passage of time I've come across a couple of issues with this and the first is that a heap of people consumed the API with the default params (which wouldn't include unverified breaches) and then contacted me asking "why does the API return different results to the front page of HIBP?" The other issue is that I simply haven't flagged very many breaches as unverified and I've also added other classes of breach which deviate from the classic model of loading a single incident clearly attributable to a single site such as the original Adobe breach. There are now spam lists, for example, as well as credential stuffing lists and returning all data by default is much more consistent with the ethos of considering all breached data to be in scope.
The other major thing related to breaking stuff is this:
Versions 1 and 2 of the API for searching breaches and pastes by email address will be disabled in 4 weeks from today on August 18.
I have to do this on an aggressive time frame. Whilst I don't, all the problems mentioned above with abuse of the API continues. When we hit that August due date, the APIs will begin returning HTTP 400 "Bad Request" and that will be the end of them.
One important distinction: this doesn't apply to the APIs that don't pull back information about an email address; the API listing all breaches in the system, for example, is not impacted by any of the changes outlined here. It can be requested with version 3 in the path, but also with previous versions of the API. Because it returns generic, non-personal data it doesn't need to be protected in the same fashion (plus it's really aggressively cached at Cloudflare). Same too for Pwned Passwords - there's absolutely zero impact on that service.
During the next 4 weeks I'll also be getting more aggressive with locking down firewall rules on the previous versions at the first sign of misuse until they're discontinued entirely. They're an easy fix if you're blocked with V2 - get an API key and roll over to V3. Now, about that key...
Protecting the API Key (and How My Problem Becomes Your Problem)
Now that API keys are a thing, let me touch briefly on some of the implications of this as it relates to those of you who've built apps on top of HIBP. And just for context, have a look at the API consumers page to get a sense of the breadth we're talking about; I'll draw some examples out of there.
For code bases such as Brad Dial's Pwny Corral, it's just a matter of adding the hibp-api-key header and a configuration for the key. Users of the script will need to go through the enrolment process to get their own key then they're good to go.
In a case like What's My IP Address' Data Breach Check, we're talking about a website with a search feature that hits their endpoint and then they call HIBP on the server side. The HIBP API key will sit privately on their end and the only thing they'll really need to do is stop people from hammering their service so it doesn't exceed the HIBP rate limit for that key. This is where it becomes their (your) problem rather than mine and that's particularly apparent in the next scenario...
Rich client apps designed for consumer usage such as Outer Corner's Secrets app will need to proxy API hits through their own service. You don't want to push the HIBP API key out with the installer plus you also need to be able to control the rate limit of all your customers so that it doesn't make the service unavailable for others (i.e. one user of Secrets smashes through the rate limit thus making the service unavailable for others).
One last thing on the rate limit: because it's no longer locking you out for a day if exceeded, making too many requests results in a very temporary lack of service (usually single digit seconds). If you're consuming the new auth'd API, handle HTTP 429 responses from HIBP gracefully and ask the user to try again momentarily. Now, with that said, let me give you the code to make it dead easy to both proxy those requests and control the rate at which your subscribers hit the service; here's how to do it with Cloudflare workers and rate limits:
Proxying With a Cloudflare Worker (and Setting Rate Limits)
The fastest way to get up and running with proxying requests to V3 of the HIBP API is with a Cloudflare Worker. This is "serverless code on the edge" or in other words, script that runs on Cloudflare's 180 edge nodes around the world such that when someone makes a request for a particular route, the script kicks in and executes. It's easiest just to have a read of the code below:
Stand up a domain on Cloudflare's free tier (if you're not on there already) then it's $5 per month to send 10M queries through your worker which is obviously way more than you can send to the HIBP API anyway. And while you're there, go and use the firewall rules to lock down a rate limit so your own API isn't hammered too much (keeping in mind some of the challenges I faced when doing this).
The point is that if you need to protect the API key and proxy requests, it's dead simple to do.
"But what if you just..."
I'll get a gazillion suggestions of how I could do this differently. Every single time I talk about the mechanics of how I've built something I always do! The model described in this blog post is the best balance of a whole bunch of different factors; the sustainability of the service, the desire to limit abuse, leveraging the areas my skills lie in, the limited availability of my time and so on and so forth. There are many other factors that also aren't obvious so as much as suggestions for improvements are very welcomed, please keep in mind that they may not work in the broader sense of what's required to run this project.
Caveats
There's a couple of these and they're largely due to me trying to make sure I get this feature out as early as possible and continue to run things on a shoestring cost wise. Firstly, there's no guarantee of support. We do the same thing with entry-level Report URI pricing and it's simply because it's enormously hard to do with the time constraints of a single person running this. That said, if anything is buggy or broken I definitely want to know about it. Secondly, there's no way to retrieve or rotate the API key. If you extend the one-off subscription you'll get the same key back or if you cancel an existing subscription and take a new one you'll also get the same key. I'll build out better functionality around this in the future.
Edit: You can now regenerate API keys by going to the API key page and clicking the "regenerate key" button. This will invalidate the old key and issue a new one.
I'm sure there'll be others that pop up and I'll expand on the items above if I've missed any here.
Summary
The changes I've outlined here strike a balance between making the API available for good purposes, making it harder to use for bad purposes, ensuring stability for all those in the former category and crucially, making it sustainable for me to operate. That last point in particular is critical for me both in terms of reducing abuse and reducing the overhead on me trying to achieve that objective and supporting those who ran into the previously mentioned blocks.
I expect there'll be many requests to change or evolve this model; other payment types, no payment at all for certain individuals or organisations, higher rate limits and so on and so forth. At this stage, my focus is on keeping the service sustainable as Project Svalbard marches forward and once that comes to fruition, I'll be in a much better position to revisit suggestions (also, there's a UserVoice for that). For now, I hope that this change leads to a much more sustainable service for everyone.
You can go and grab an API key right now from the API menu on the HIBP website:
Edit: Just to be crystal clear, this doesn't impact Pwned Passwords. Cloudflare picks up pretty much all the costs for running that so the service is still freely accessible.