I have been, and still remain, a massive proponent of "the cloud". I built Have I Been Pwned (HIBP) as a cloud-first service that took advantage of modern cloud paradigms such as Azure Table Storage to massively drive down costs at crazy levels of performance I never could have achieved before. I wrote many blog posts about doing big things for small dollars and did talks all over the world about the great success I'd had with these approaches. One such talk was How I Pwned My Cloud Costs so it seems apt that today, I write about the exact opposite: how my cloud costs pwned me.
It all started with my monthly Azure bill for December which was way over what it would normally be. It only took a moment to find the problem:

That invoice came through on the 10th of Jan but due to everyone in my household other than me getting struck down with COVID (thankfully all asymptomatic to very mild), it was another 10 days before I looked at the bill. Ouch! It's much worse than that too, but we'll get to that.
Investigation time and the first thing I look at is Azure's cost analysis which breaks down a line item like the one above into all the individual services using it. HIBP is made up of many different components including a website, relationship database, serverless "Functions" and storage. Right away, one service floated right to the top:
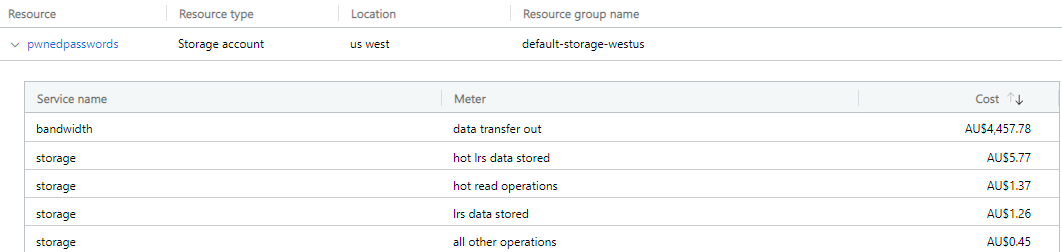
That first line item is 98% of my bandwidth costs across all services. Not just all HIBP services, but everything else I run in Azure from Hack Yourself First to Why No HTTPS. What we're talking about here is egress bandwidth for data being sent out of Microsoft's Azure infrastructure (priced at AU$0.1205 per GB) so normally things like traffic to websites. But this is a storage account - why? Let's start with when the usage started skyrocketing:
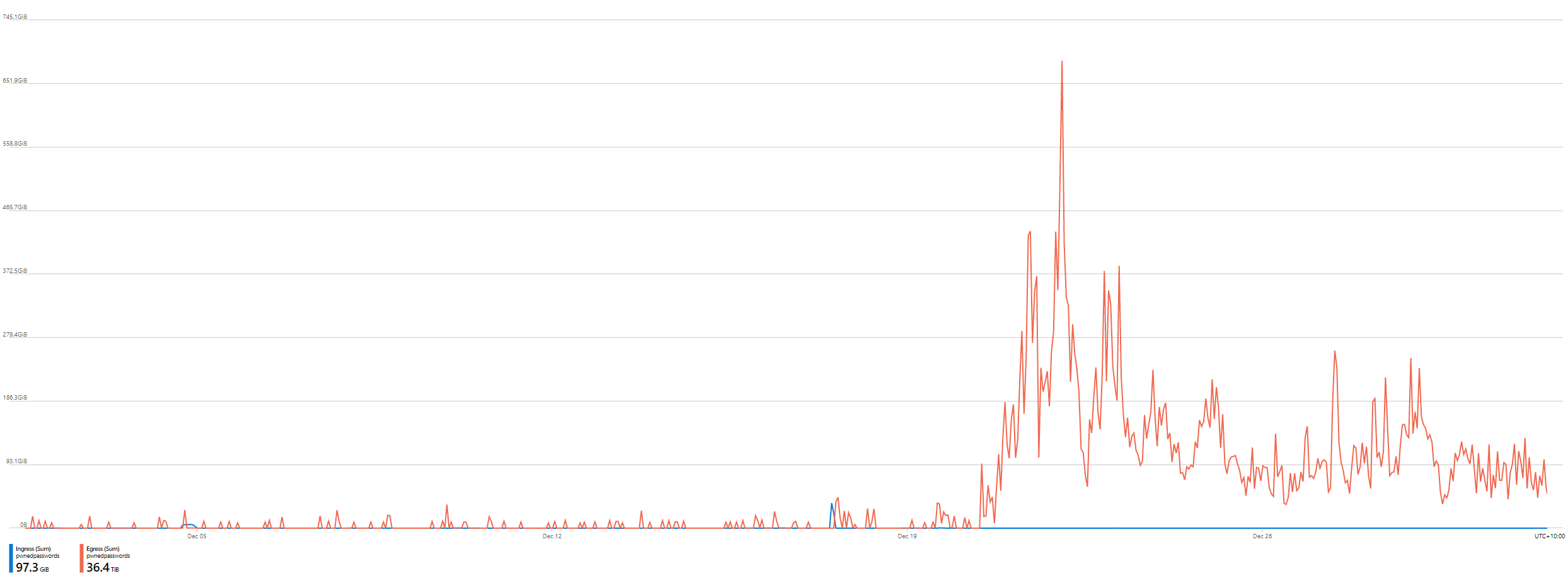
December 20. Immediately, I knew what this correlated to - the launch of the Pwned Passwords ingestion pipeline for the FBI along with hundreds of millions of new passwords provided by the NCA. Something changed then; was it the first production release of the open source codebase? Something else? I had to dig deeper, starting with a finer-grained look at the bandwidth usage. Here's 4 hours' worth:
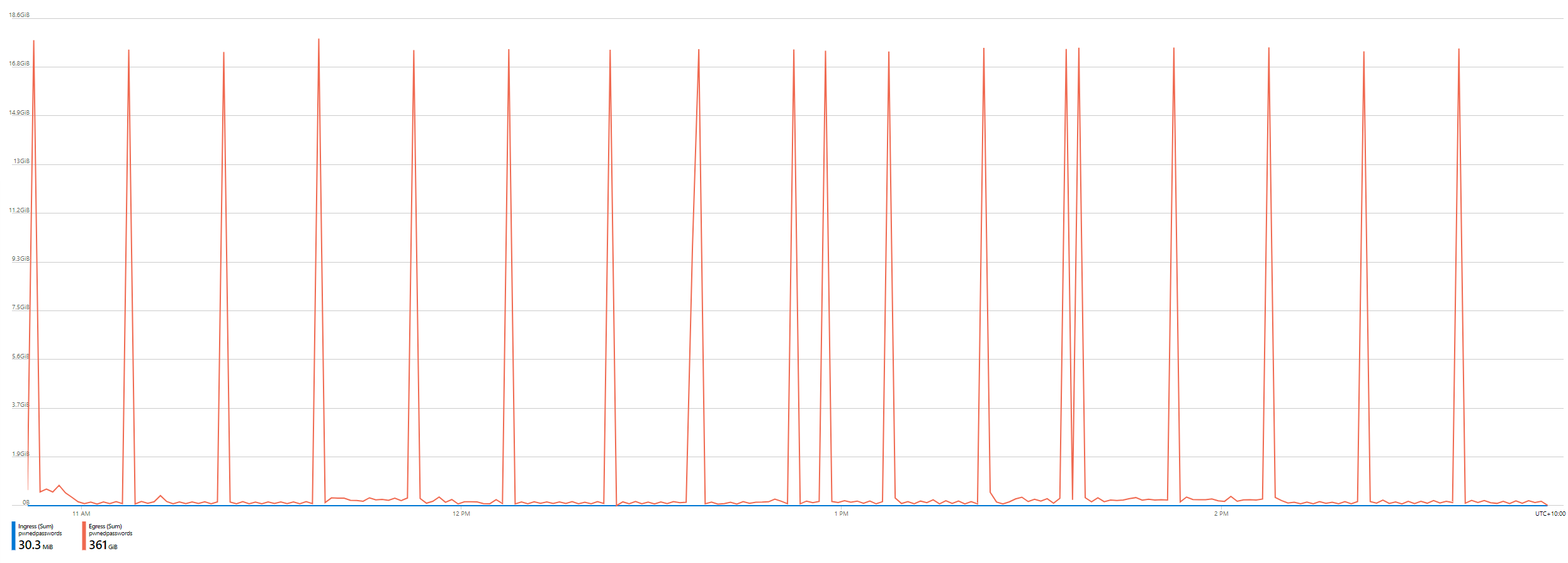
Consistently, each one of those spikes was 17.3GB. Not a completely linear distribution, but pretty regular spikes. By now, I was starting to get a pretty good idea of what was chewing up the bandwidth: the downloadable hashes in Pwned Passwords. But these would always cache at the Cloudflare edge node, that's why I could provide the service for free, and I'd done a bunch of work with the folks there to make sure the bandwidth from the origin service was negligible. Was that actually the problem? Let's go deeper again, right down to the individual request level by enabling diagnostics on the storage account:
{
"time":"2022-01-20T06:06:24.8409590Z",
"resourceId":"/subscriptions/[subscription id]/resourceGroups/default-storage-westus/providers/Microsoft.Storage/storageAccounts/pwnedpasswords/blobServices/default",
"category":"StorageRead",
"operationName":"GetBlob",
"operationVersion":"2009-09-19",
"schemaVersion":"1.0",
"statusCode":200,
"statusText":"Success",
"durationMs":690285,
"callerIpAddress":"172.68.132.54:13300",
"correlationId":"c0f0a4c6-601e-010f-80c2-0d2a1c000000",
"identity":{
"type":"Anonymous"
},
"location":"West US",
"properties":{
"accountName":"pwnedpasswords",
"userAgentHeader":"Mozilla/5.0 (Windows NT; Windows NT 10.0; de-DE) WindowsPowerShell/5.1.14393.4583",
"etag":"0x8D9C1082643C213",
"serviceType":"blob",
"objectKey":"/pwnedpasswords/passwords/pwned-passwords-sha1-ordered-by-count-v8.7z",
"lastModifiedTime":"12/17/2021 2:51:39 AM",
"serverLatencyMs":33424,
"requestHeaderSize":426,
"responseHeaderSize":308,
"responseBodySize":18555441195,
"tlsVersion":"TLS 1.2"
},
"uri":"https://downloads.pwnedpasswords.com/passwords/pwned-passwords-sha1-ordered-by-count-v8.7z",
"protocol":"HTTPS",
"resourceType":"Microsoft.Storage/storageAccounts/blobServices"
}
Well, there's the problem. These requests appeared regularly in the logs, each time burning a 17.3GB hole in my wallet. That IP address is Cloudflare's too so traffic was definitely routing through their infrastructure and therefore should have been cached. Let's see what the Cloudflare dashboard has to say about it:
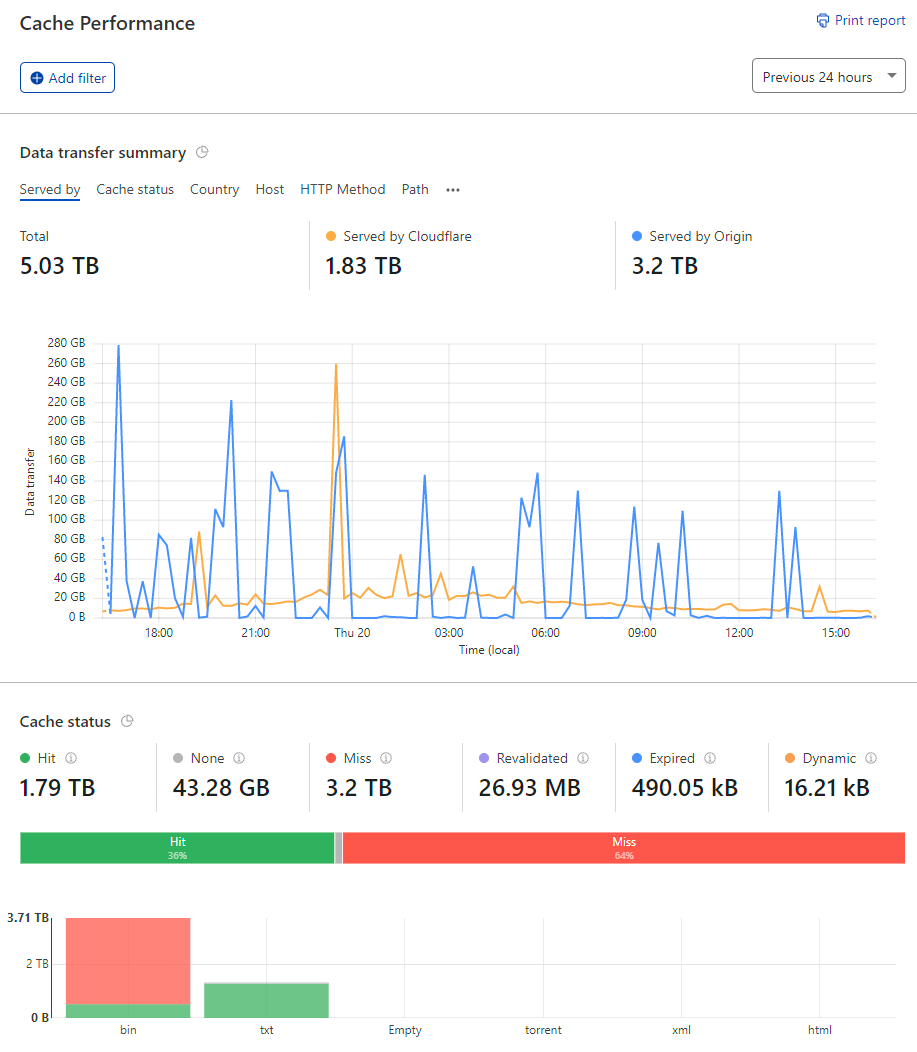
That's a lot of data served by the origin in only 24 hours, let's drill down even further:
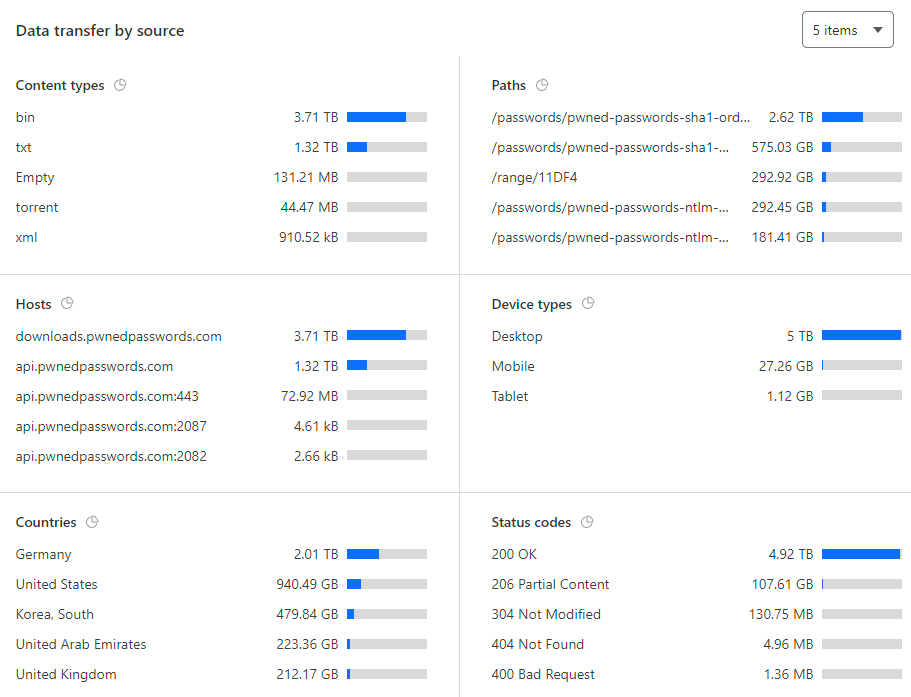
And there's those same zipped hashes again. Damn. At this stage, I had no idea why this was happening, I just knew it was hitting my wallet hard so I dropped in a firewall rule at Cloudflare:
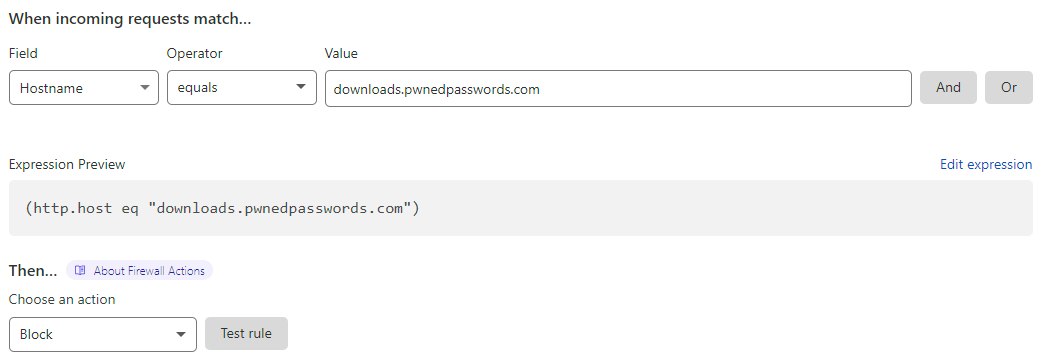
And immediately, the origin bandwidth hit dived:
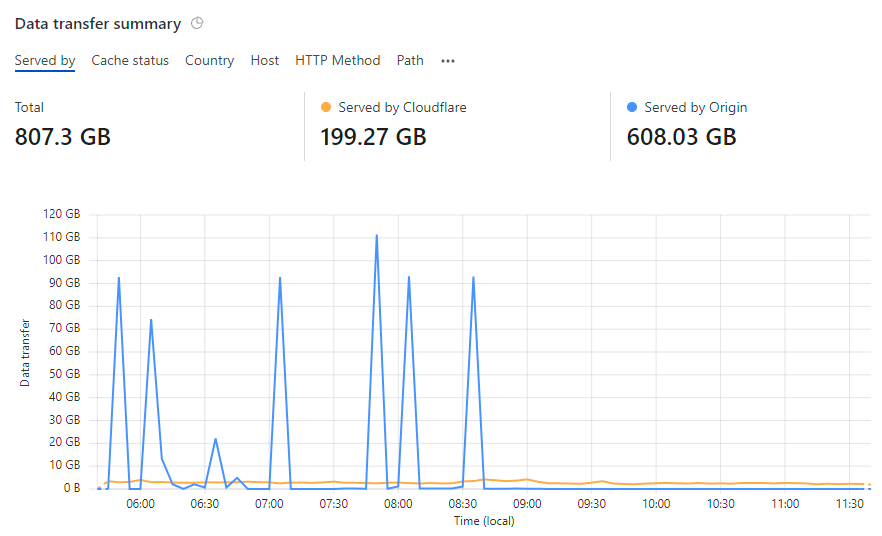
The symptom was clear - Cloudflare wasn't caching things it should have been - but the root cause was anything but clear. I started going back through all my settings, for example the page rule that defined caching policies on the "downloads" subdomain:
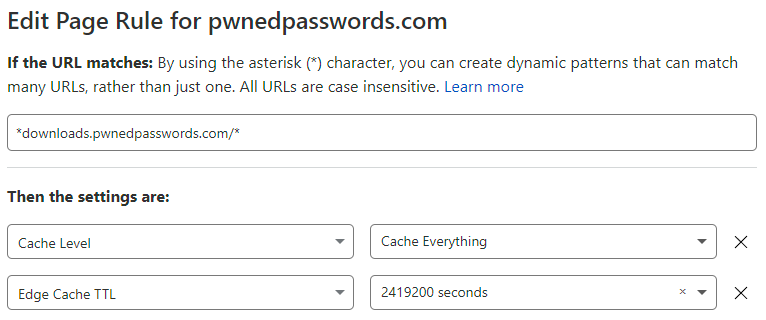
All good, nothing had changed, and it looked fine anyway. So, I looked at the properties of the file itself in Azure's blob storage:
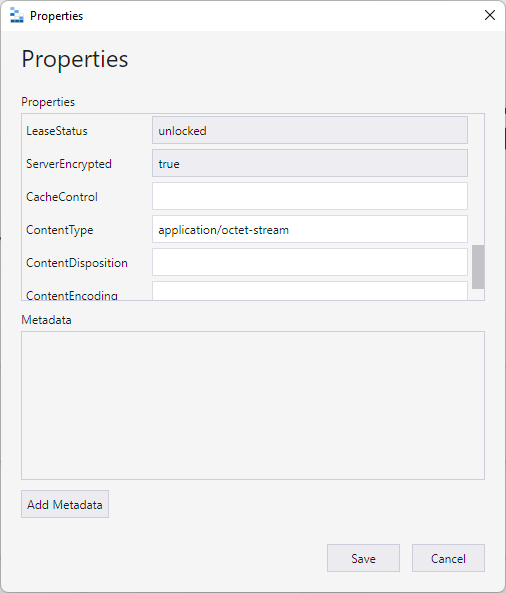
Huh, no "CacheControl" value. But there wasn't one on any of the previous zip files either and the Cloudflare page rule above should be overriding anything here by virtue of the edge cache TTL setting anyway. In desperation, I reached out to a friend at Cloudflare and shortly thereafter, the penny dropped:
So I had a quick look and I can certainly confirm that CF isn't caching those zip files.. Now I did find a setting on your plan that set the max cacheable file size to 15GB and it looks like your zipfile is 18GB big.. would it be possible that your file just grew to be beyond 15GB around that time?
Of course! I recalled a discussion years earlier where Cloudflare had upped the cacheable size, but I hadn't thought about it since. I jumped over to the Azure Storage Explorer and immediately saw the problem and why it had only just begun:
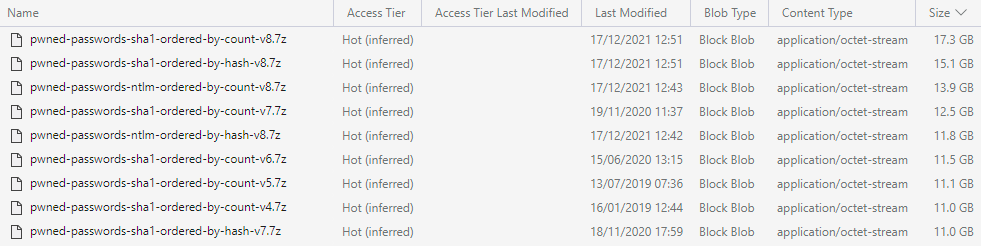
And there we have it - both SHA-1 archives are over 15GB. Dammit. Now knowing precisely what the root cause was, I tweaked the Cloudflare rules:
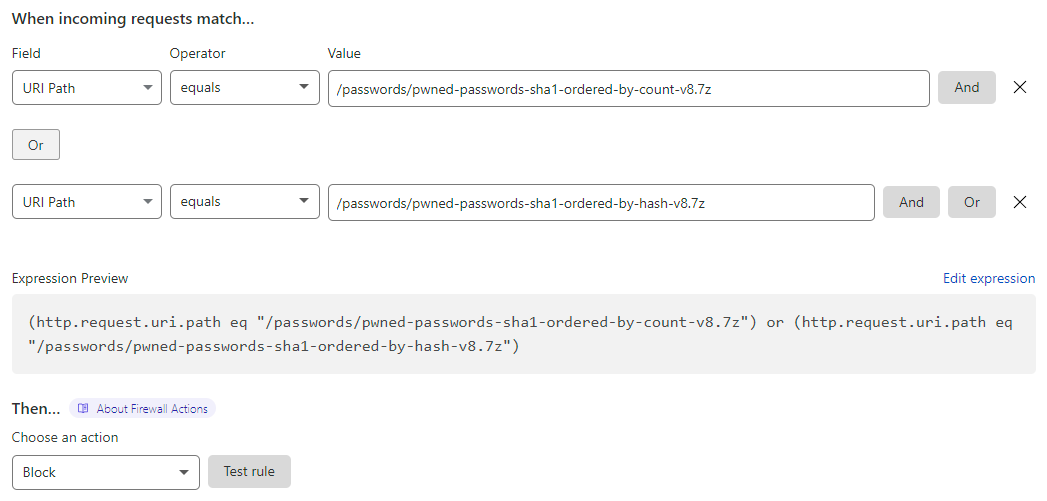
I removed the direct download links from the HIBP website and just left the torrents which had plenty of seeds so it was still easy to get the data. Since then, Cloudflare upped that 15GB limit and I've restored the links for folks that aren't in a position to pull down a torrent. Crisis over.
So, what was the total damage? Uh... not good:
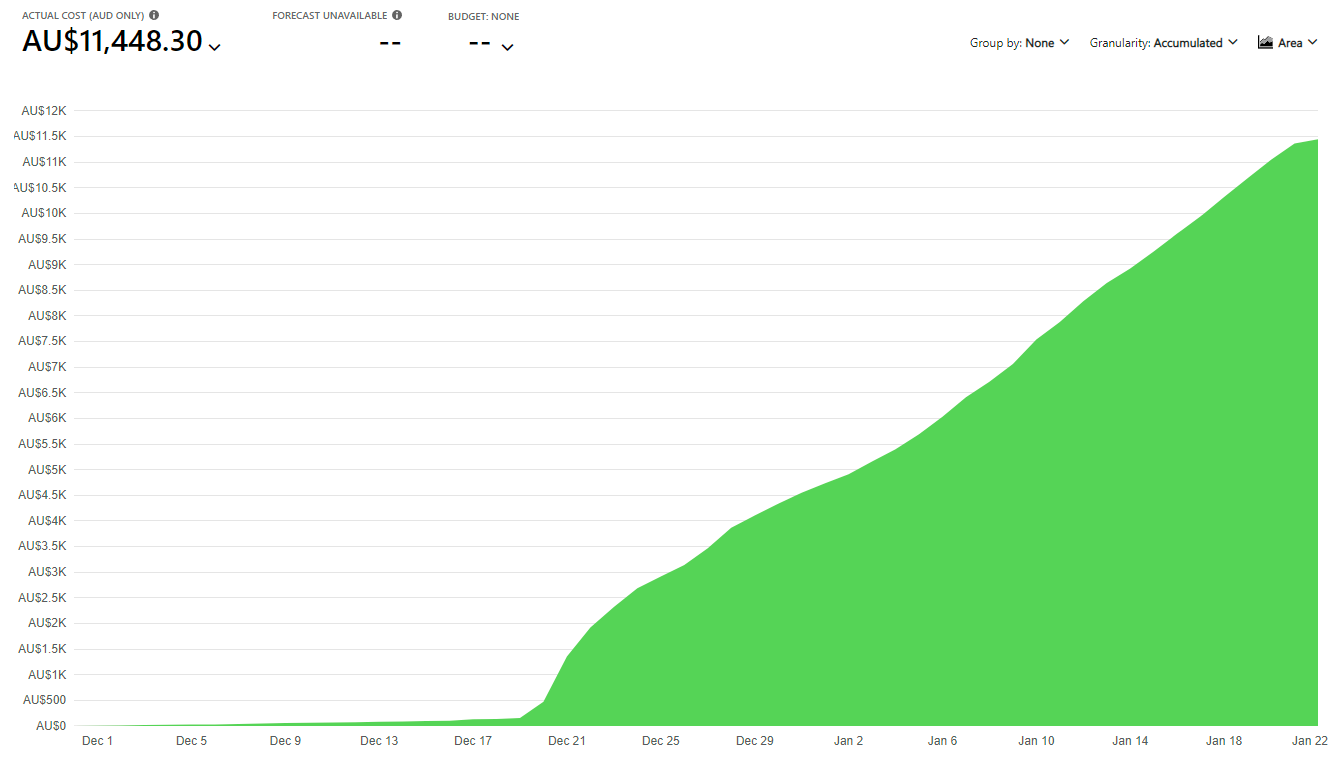
Over and above normal usage for that period, it cost me over AU$11k. Ouch! For folks in other parts of the world, that's about US$8k, GB£6k or EU€7k. This was about AU$350 a day for a month. It really hurt, and it shouldn't have happened. I should have picked up on it earlier and had safeguards in place to ensure it didn't happen. It's on me. However, just as I told earlier stories of how cost-effective the cloud can be, this one about how badly it can bite you deserved to be told. But rather than just telling a tale of woe, let's also talk about what I've now done to stop this from happening again:
Firstly, I always knew bandwidth on Azure was expensive and I should have been monitoring it better, particularly on the storage account serving the most data. If you look back at the first graph in this post before the traffic went nuts, egress bandwidth never exceeded 50GB in a day during normal usage which is AU$0.70 worth of outbound data. Let's set up an alert on the storage account for when that threshold is exceeded:
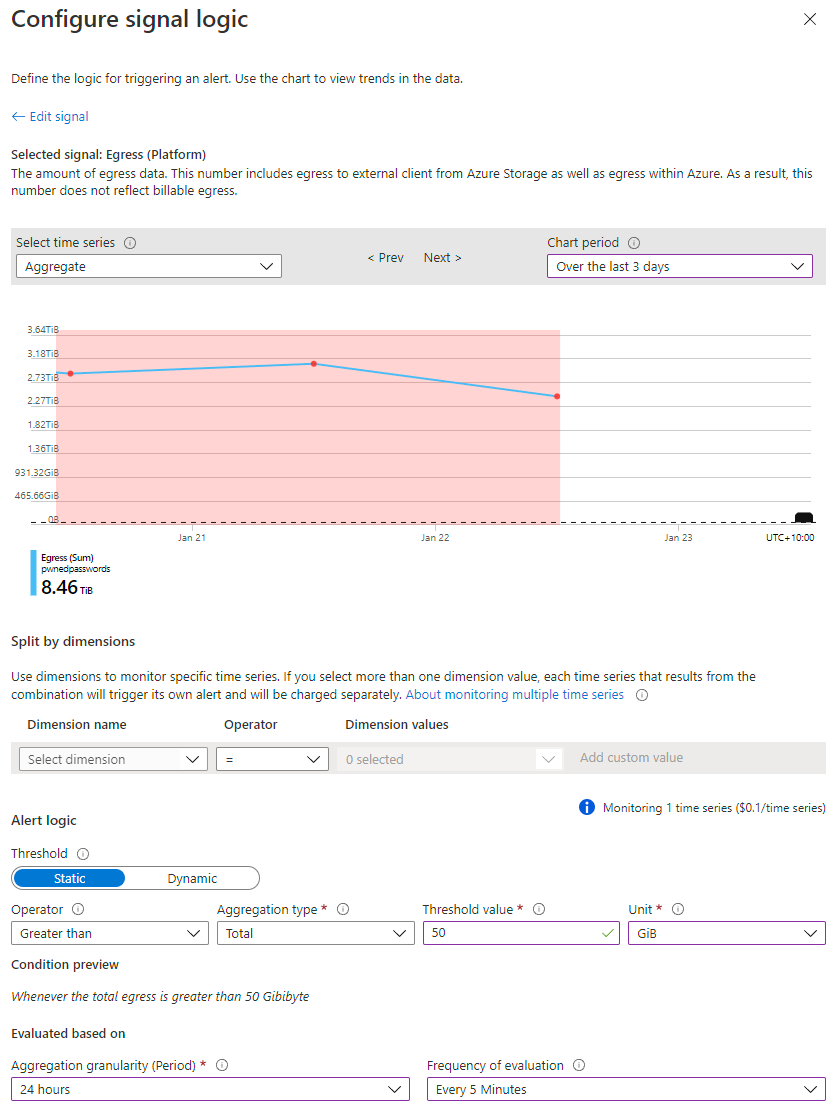
The graph at the top of that image shows a dashed black line right towards the bottom of the y-axis which is where my bandwidth should be (at the most), but we're still seeing the remnants of my mistake reflected to the left of the graph where bandwidth usage was nuts. After setting up the above, it was just a matter of defining an action to fire me off an email and that's it - job done. As soon as I configured the alert, it triggered, and I received an email:
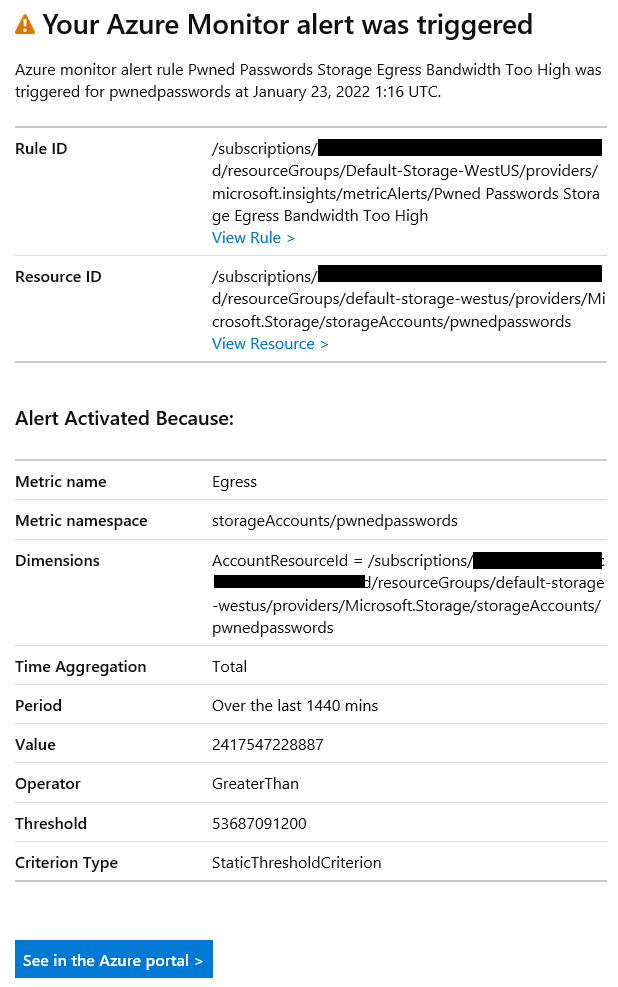
If I'd had this in place a month earlier, this whole shambles could have been avoided.
Secondly, there's cost alerts. I really should have had this in place much earlier as it helps guard against any resource in Azure suddenly driving up the cost. This involves an initial step of creating a budget for my subscription:
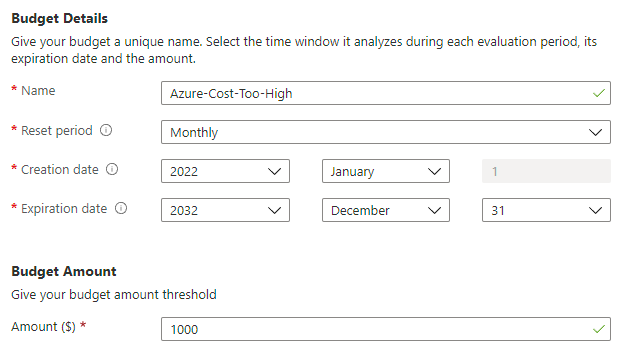
Next, it requires conditions and I decided to alert both when the forecasted cost hits the budget, or when the actual cost gets halfway to the budget:
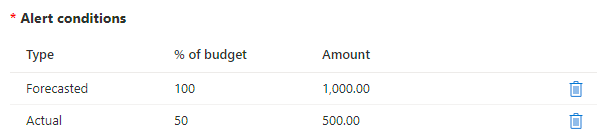
I figure that knowing when I get halfway there is a good thing, and I can always tweak this in the future. Cost is something that's easy to gradually creep up without you really noticing, for example, I knew even before this incident that I was paying way too much for log ingestion due to App Insights storing way too much data for services that are hit frequently, namely the HIBP API. I already needed to do better at monitoring this and I should have set up cost alerts - and acted on them - way earlier.
I guess I'm looking at this a bit like the last time I lost data due to a hard disk failure. I always knew there was a risk but until it actually happened, I didn't take the necessary steps to protect against that risk doing actual damage. But hey, it could have been so much worse; that number could have been 10x higher and I wouldn't have known any earlier.
Lastly, I still have the donations page up on HIBP so if you use the service and find it useful, your support is always appreciated. I, uh, have a bill I need to pay 😭