Four and a half years ago now, I rolled out version 2 of HIBP's Pwned Passwords that implemented a really cool k-anonymity model courtesy of the brains at Cloudflare. Later in 2018, I did the same thing with the email address search feature used by Mozilla, 1Password and a handful of other paying subscribers. It works beautifully; it's ridiculously fast, efficient and above all, anonymous. Yet from time to time, I get messages along the lines of this:
Why are you using SHA-1? It's insecure and deprecated.
Or alternatively:
Our [insert title of person who fills out paperwork but has no technical understanding here] says that k-anonymity involves sending you PII.
Both these positions make no sense whatsoever when you peel back the covers and understand what's happening underneath, but I get how on face value these conclusions can be drawn. So, let's settle it here in a more complete fashion than what I can do via short tweets or brief emails.
SHA-1 is Just Fine for k-Anonymity
Let's begin with the actual problem SHA-1 presents. Actually, the multiple problems, the first of which is that it's just way too fast for storing user passwords in an online system. More than a decade ago now, I wrote about how Our Password Hashing Has no Clothes and in that post, showed the massive rate at which consumer-grade hardware can calculate these hashes and consequently "crack" the password. Since that time, Moore's Law has done its thing many times over making the proposition of SHA-1 (or SHA-256 or SHA-512) even worse than before. For a modern day reference of how you should be storing passwords, check out OWASP's Password Storage Cheat Sheet.
The other problem relates to how SHA-1 is used for integrity checks. Hashing algorithms provide an efficient means of comparing two files and establishing if their contents is the same due to the deterministic nature of the algorithm (the same input always produces the same output). If a trustworthy source says "the hash of the file is 3713..42" (shown in abbreviated form) then any file with that same hash is assumed to be the same as the one described by the trustworthy source. We use hashes all over the place for precisely this purpose; for example, if I wanted to download Windows 11 Business Editions from my MSDN subscription, I can refer to the hash Microsoft provides on the download page:

After download, I can then use a utility such as PowerShell's Get-FileHash to verify that the file I downloaded is indeed the same one listed above. (There's another rabbit hole we can go down about how you trust the hash above, but I'll leave that for another post.)
We also use hashes when implementing subresource integrity (SRI) on websites to ensure external dependencies haven't been modified. Every time this very blog loads Font Awesome from Cloudflare's CDN, for example, it's verified against the hash in the integrity attribute of the script tag (view source for yourself).
And finally (although not exhaustively - there are many other places we use hashing algorithms in tech), we use hashing algorithms on digital certificate signatures. To pick another example from this blog, the certificate issued by Cloudflare uses SHA-256 as the signature hash algorithm:
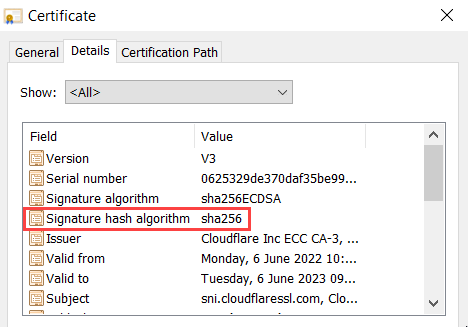
But ponder this: if a hashing algorithm always produces a fixed length output (in the case of SHA-1, it's 40 hexadecimal characters), then there are a finite number of hashes in the world. In that SHA-1 example, the finite number is 16^40 as there are 16 possible values (0-9 and a-f) and 40 positions for them. But how many different input strings are there in the world? Infinite! So, there must be multiple input strings that produce the same output, and this is what we refer to as a "hash collision". It's possible for this to occur naturally, although it's exceedingly unlikely simply due to the massive number of possibilities 16^40 presents. However, what if you could manufacture a hash collision? I mean what if you could take an existing hash for an existing document and say "I'm going to create my own document that's different but when passed through SHA-1, produces the same hash!"?
Half a decade ago now, Google researchers demonstrated precisely this with their SHAttered attack. Their simple infographic tells the story:

And this is the heart of the integrity problem with SHA-1: it's simply past its used by date as an algorithm we can be confident in. That's why the signature hash algorithm of the TLS cert on this blog uses SHA-256 instead, among other examples of where we've eschewed the weaker algorithm in favour of stronger variants.
So, now that you understand the problem with SHA-1, let's look at how it's used in HIBP and why it isn't a problem there. There are actually 2 reasons, and I'll start with a sample of passwords used in Pwned Passwords:
P@ssw0rd
abc123
635,someone@example.com,+61430978216,37 example street
money
qwertyThat middle line isn't a password, it's a parsing problem. Not necessarily my parsing problem, it just turns out that you can't always trust hackers to dump breached data in a clean format 🤷♂️ So, instead of providing passwords to people in plain text format, I provide them as SHA-1 hashes:
21BD12DC183F740EE76F27B78EB39C8AD972A757
6367C48DD193D56EA7B0BAAD25B19455E529F5EE
A4DDCDA001E137C72FF8259F36BC67C5F9E083AA
C95259DE1FD719814DAEF8F1DC4BD64F9D885FF0
B1B3773A05C0ED0176787A4F1574FF0075F7521E4 of those hashes are easily cracked (Google is great at that, just try searching for the first one) and that's just fine; nobody is put at risk by learning that some unidentified party used a common password. The 1 hash that won't yield any search results (until Google indexes this blog post...) is the middle one. The fact that SHA-1 is fast to calculate and has proven hash collision attacks against its integrity doesn't diminish the purpose it serves in protecting badly parsed data.
The second reason is best explained by walking through the process of how the API is queried. Let's take an example of someone signing up to a website with the following password:
P@ssw0rdThis will pass many password complexity criteria (uppercase, lowercase, number, non-alphanumeric character, 8 chars long) but is clearly terrible. Because they're signing up to a responsible website that checks Pwned Passwords on registration, that website now creates a SHA-1 hash of the provided password:
21BD12DC183F740EE76F27B78EB39C8AD972A757Let's pause here for a sec: whether it's a hash of a password or a hash of an email address, what we're looking at is a pseudonymous representation of the original data. There's no anonymity of substance achieved here because in the specific case above, you can simply Google the hash and in the case of an email address, you can determine with near certainty (hash collisions aside), if a given plain text email address is the one used to generate the hash.
This, however, is a different story:
21BD1This is the first 5 characters only of the hash and it's passed to the Pwned Passwords API as follows:
https://api.pwnedpasswords.com/range/21BD1You can easily run this yourself and see the result but to summarise, the API then responds with 788 lines, including the following 5:
2D6980B9098804E7A83DC5831BFBAF3927F:1
2D8D1B3FAACCA6A3C6A91617B2FA32E2F57:1
2DC183F740EE76F27B78EB39C8AD972A757:83129
2DE4C0087846D223DBBCCF071614590F300:3
2DEA2B1D02714099E4B7A874B4364D518F6:1What we're looking at here is the hash suffix of every hash that begins with 21BD1 followed by the number of times that password has been seen. Turns out that "P@ssw0rd" ain't a great choice as it's the one in the middle that's been seen over 83k times. The consumer of the Pwned Passwords service knows it's this one because when combined with the prefix, it's a perfect match to the full hash of the password. I'll touch more on the mathematical properties of this in a moment, for now I want to explain the second reason why SHA-1 is used:
SHA-1 makes it very easy to segment the entire corpus of hashes into roughly equal equivalent sized chunks that can be queried by prefix. As I already touched on, there are 16^5 different possible hash prefixes which is specifically 1,048,576 or "roughly a million". Not every hash prefix has 788 associated suffixes, some have more and others less but if we take that as an average, that explains how the approximately 850M passwords in the service are divided down into a million smaller collections.
Why the first 5 characters? Because if it was the first 4 then each response would be 16 times larger and it would start hurting response times. If it was the first 6 then each response would be 16 times smaller and it would start hurting anonymity. 5 characters was the sweet spot between the two.
Why not SHA-256? Instead of 40 characters each hash would be 64 characters and whilst I could have achieved the same anonymity properties by still just using the first 5 characters of the hash, each suffix in the response would be an additional 24 characters and multiplying that 788 times over adds multiple kb to each response, even when compressed on the transport layer. It's also a slower hashing algorithm; still totally unsuitable for storing user passwords in an online system, but it can have a hit on the consuming service if doing huge amounts of calculations. And for what? Integrity doesn't matter because there's no value in modifying the source password to forge a colliding hash. You'd further increase the anonymity by 16^24 more possibilities, but then why not use SHA-512 which is 128 characters therefore another 16^64 possibilities than even SHA-256? Because, as you'll read in the next section, even SHA-1 provides way more practical anonymity than you'll ever need anyway.
In summary, think of the choice of SHA-1 simply being to obfuscate poorly parsed input data to protect inadvertently included info, and as a means of dividing the collection of data down into nice easily segmentable and queryable collections. If your position is "SHA-1 is broken", then you simply don't understand its purpose here.
PII and the Protection Provided by k-Anonymity
Let's turn the discussion more to the privacy aspects of the email address search I mentioned earlier on. The principles are identical to the password search but for one difference in the technical implementation: queries are done on the first 6 characters of a SHA-1 hash, not the first 5. The reason is simple: there are a lot more email addresses in the system than passwords, about 5 billion in total. Querying via the first 6 characters of a SHA-1 hash means there are 16 times more possibilities than with the password search, therefore 16^6 or just over 16M. Let's take this email address:
test@example.comWhich hashes down to this value with SHA-1:
567159D622FFBB50B11B0EFD307BE358624A26EEAnd similar to the password search, it's only the prefix that is sent to HIBP when performing a query:
567159So, putting the privacy hat on, what's the risk when a service sends this data to HIBP? Mathematically, with the next 34 characters unknown, there are 16^34 different possible hashes that this prefix could belong to. Just to really labour the point, given a 6 character SHA-1 hash prefix you could take a 1 in 87,112,285,931,760,200,000,000,000,000,000,000,000,000 guess as to what the full hash prefix is. And then due to the infinite number of potential input strings, multiply that number out to... well... infinity. That's the total number of possible email addresses it could represent. By any definition of the term, those first 6 characters tell you absolutely nothing useful about what email address is being searched for.
But we're left with a more semantic, possibly philosophical question: is "567159" personally identifiable information? In practice, no, for all intents and purposes it's impossible to tell who this belongs to without the remaining 34 characters and even then, you still need to be able to crack that hash which is most likely only going to happen if you have a dictionary of email address to work through in which the given one appears. But it's derived from pseudonymous PII, and this is where the occasional [insert title of person who fills out paperwork but has no technical understanding here] loses their mind.
To explain this in more colloquial terms, it's like saying that the "t" at the beginning of the email address I used above is personally identifying. Really? My own email address begins with a "t", so it must be mine! It's a nonsense argument.
I'll wrap up with a definition and I like NIST's the best, not just because it's clear and concise but because they're a great authoritative source on this sort of thing (it was actually their guidance on prohibiting passwords from previous breach corpuses that led me to create Pwned Passwords in the first place):
Any representation of information that permits the identity of an individual to whom the information applies to be reasonably inferred by either direct or indirect means.
Phone numbers are PII. Physical addresses are PII. IP addresses are PII. The first 6 characters of a SHA-1 hash of someone's email address is not PII.
Summary
None of the misunderstandings I've explained above have dented the adoption of these services. Pwned Passwords is now doing in excess of 2 billion queries a month and has an ongoing feed of new passwords directly from the FBI. The k-anonymity search for email addresses sees over 100M queries a month and is baked into everything from browsers to password managers to identity theft services. The success of these services isn't due to any technical genius on my part (hat-tip again to Cloudflare), but rather to their simple yet effective implementations that (almost) everyone can easily understand 😊