Two of my favourite developer things these days are Azure Functions and Cloudflare Workers. They're both "serverless" in that rather than running on your own slice of infrastructure, that concept is abstracted away and you get to focus on just code executions rather than the logical bounds of the server it runs on. So for example, when you have an Azure function and you deploy it under a consumption plan, you pay for per-second resource consumption (how much memory you use for how long) and the number of times it executes. If you have an efficient function that executes quickly it can be extremely cost effective as I recently demonstrated with the Pwned Passwords figures:
So here's the hard facts - I'm dipping into my pocket every week to the tune of... $7.40 for you guys to do 54M searches against a repository of half a billion passwords ? pic.twitter.com/WPez1SXYmD
— Troy Hunt (@troyhunt) June 27, 2018
Cells A1 through F8 tell the story: for more than 4 million queries of the 500 million password repositories, Azure Functions are costing me $3.35 per week. Admittedly, I'm taking advantage of the free grants that everyone using Functions gets each month (400,000GB/s and 1M executions) but even at 10 times those volumes, I'd still only be looking at $87 to run 40 million queries.
Then there's Cloudflare workers; "code on the edge". This is also serverless computing and it involves running your piece of software simultaneously on every single one of Cloudflare's 151 points of presence around the world:
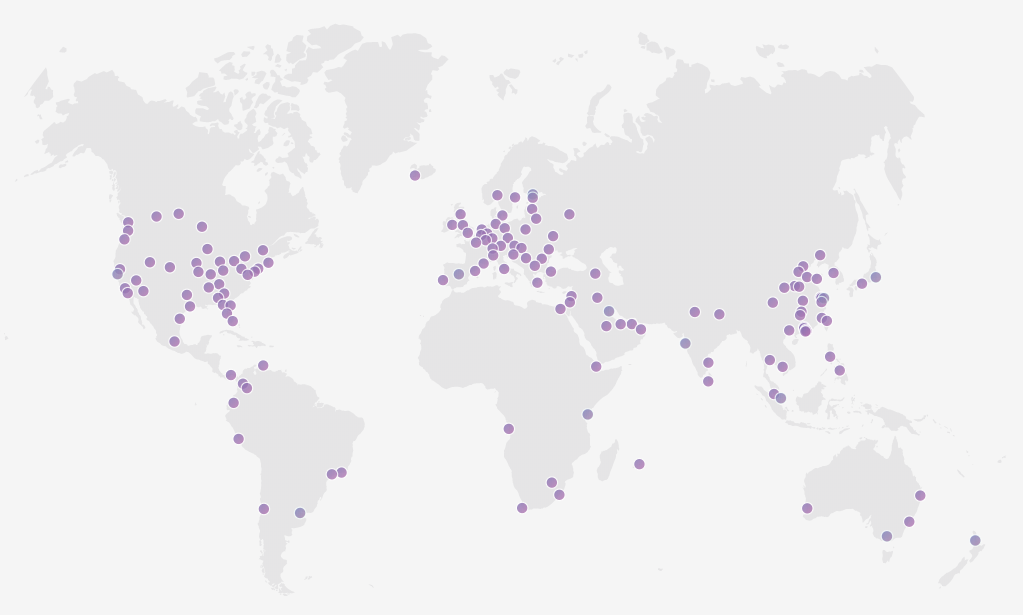
Cloudflare is a reverse proxy which means that traffic to your website routes through them, then to your website, then back through them before landing in your visitor's browser. This means they can do everything from cache responses to stop potentially malicious threats to apply firewall rules to block certain user agents or IP addresses. And, as of September last year, it also means being able to shape the flow of traffic before it even hits your site with Cloudflare Workers. I'll talk more about that later.
Let's start with the problem I'm solving here: I run Have I Been Pwned (HIBP) on an Azure App Service which is essentially a PaaS implementation of IIS. I run it on a single S3 instance which costs $0.40 an hour or just under a few hundred bucks a month. However, I also have auto-scale enabled so that when traffic ramps up it can spin up more instances, each of which also costs $0.40 an hour. This was a great way to get HIBP up and running cost effectively (I used to run it on an S2 instance which was half the price), whilst still allowing it to scale and support more load as it grew. Only problem is, this was getting expensive and causing me to occasionally lose traffic for reasons I wrote about in Brief Lessons on Handling Huge Traffic Spikes. In that case, HIBP was featured on British prime time TV and as the piece went to air, tens (possibly hundreds) of thousands of Brits simultaneous picked up their phones and visited HIBP. Which caused this to happen:
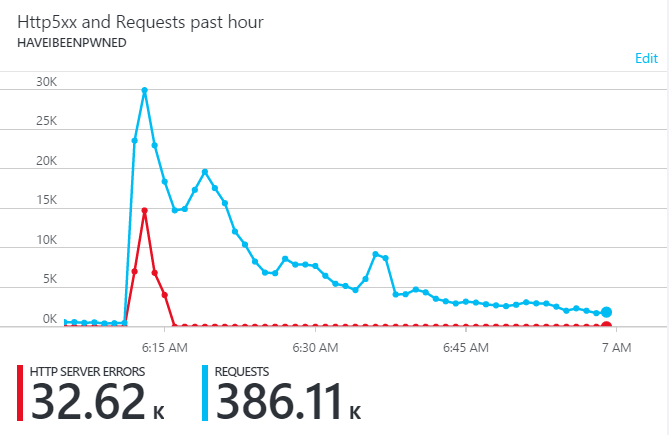
See how quickly that traffic ramps up? And how it caused a subsequent set of failed requests? That happened because the underlying app service did this:
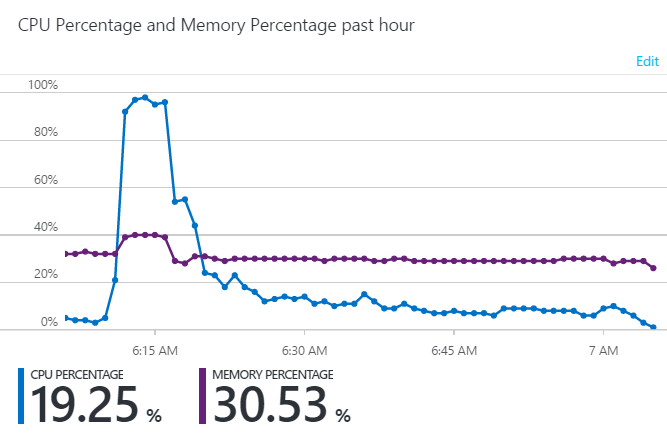
The CPU maxed out at 100% very quickly and the problem with that is the trigger for auto-scale needs to see a sustained level of traffic over a 5-minute period to add on another instance. That's great if there's traffic ramping up at a steady rate (such as people following links in a news story), but it simply can't keep up if demand increases at the rate it did in the graphs above. It's the same problem when someone suddenly starts hammering the API too, albeit to a lesser extent due to the rate limit but get multiple people hammering it simultaneously and it's the same sort of problem again.
The future is serverless because the logical infrastructure boundary causing the problems above goes away. Pages such as the HIBP homepage are already really aggressively cached by Cloudflare so if I could get calls to the API which everyone hits when they do a search to be routed through an Azure Function, the problem in the charts above goes away. As of a couple of weeks ago, the API in question was invoked via the following GET request:
https://haveibeenpwned.com/api/v2/unifiedsearch/test@example.comThat was hitting an ASP.NET Web API endpoint on the website running on that S3 instance so hammer that too hard and the whole site is going to suffer. Now, a quick caveat: this is not a publicly documented API. It's not intended for others to hit it and it's optimised specifically for the use case of the HIBP homepage. I make no guarantees about it not suddenly changing - which it since has - don't rely on this endpoint!
So let's talk about what's changed and indeed what's in the future: a few weeks back I announced that Firefox and 1Password were integrating HIBP searches into their products and the way I built that was with an authenticated Azure Function. I wanted to use that same service to add a new Function that will replace the old in-app one. In preparation for this, over the 4th of July holiday in the US I pushed some changes to the existing project running the Azure Function and... it broke. And I couldn't resurrect it. I later learned this was due to a combination of my changing an app setting in a breaking fashion and Azure not really making it clear that this was going to be a problem (and that's something Microsoft is rectifying), but in order to quickly stand up a working service that had live dependencies, I deployed an all new Azure Function service, configured it, pushed code and updated DNS. I lost traffic - not much - but I broke things and that made me rather sad ?
So I got to thinking - how can I turn that experience into something positive and illustrate how to use Functions and Workers in a really cool way that will help me run the service better and show other folks just how neat these features are? Which brings me to where we are now and I'm going to start with using Workers to help with some A/B testing of the new unified search endpoint. I want to see how it behaves on the live running site but I don't want my users to be the crash test dummies for it. What I really want is for only my own requests to be directed to this path:
https://[azure function name].azurewebsites.net/unifiedsearch/test@example.comI'm going to draw some inspiration from Cloudflare's post on A/B testing with Workers and create a cookie locally on my machine then use a Worker to direct requests to the address immediately above rather than the old HIBP API. Here's what the worker looks like:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
async function fetchAndApply(request) {
let isTestGroup = false
// Determine if this request is from someone in the test group
const cookie = request.headers.get('Cookie')
if (cookie && cookie.includes('Test-Group')) {
isTestGroup = true
}
// Grab the original URL and modify it if we're testing
let url = new URL(request.url)
if (isTestGroup) {
url = request.url.replace('https://haveibeenpwned.com/api/v2/unifiedsearch/', 'https://api.haveibeenpwned.com/unifiedsearch/')
}
const modifiedRequest = new Request(url, {
method: request.method,
headers: request.headers
})
// Send the request on
const response = await fetch(modifiedRequest)
if (isTestGroup) {
// Add a response header so we can see the request was part of the test group
const newHeaders = new Headers(response.headers)
newHeaders.append('Test-Group', true)
return new Response(response.body, {
status: response.status,
statusText: response.statusText,
headers: newHeaders
})
} else {
return response
}
}In other words, if a cookie called "Test-Group" is present then the request is going to be routed to the new API even though the path is to the old one. I've also added a "Test-Group" response header so I can easily identify when the request has been routed to the new endpoint. That gets saved as a new Worker called "test-new-unified-search", now I just need a route that will invoke that code on appropriate requests:
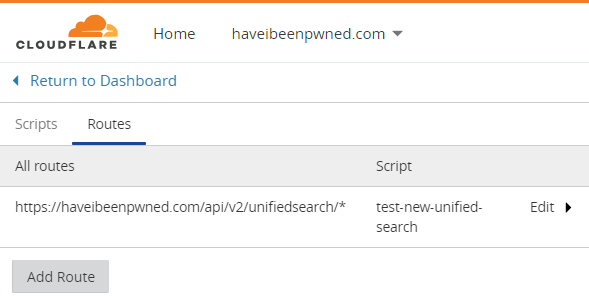
Add a cookie into the browser manually (it doesn't even need a value, it just has to exist):

And if I now run that up in the browser:
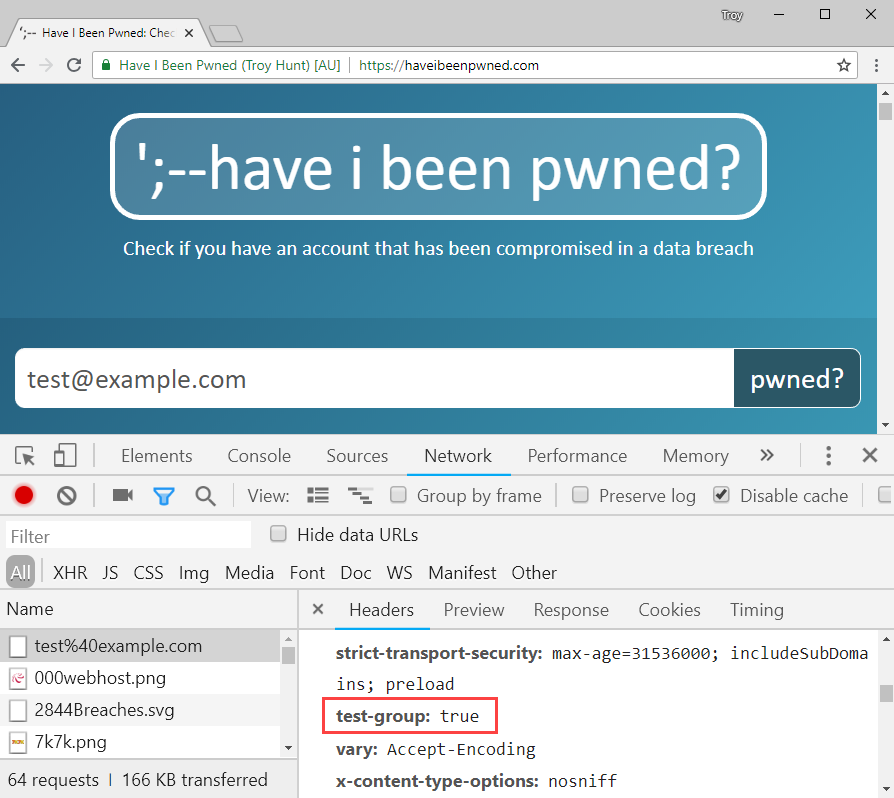
Success! And just to make sure it's only me hitting the new API, a quick check from an incognito browser session which won't have the cookie:
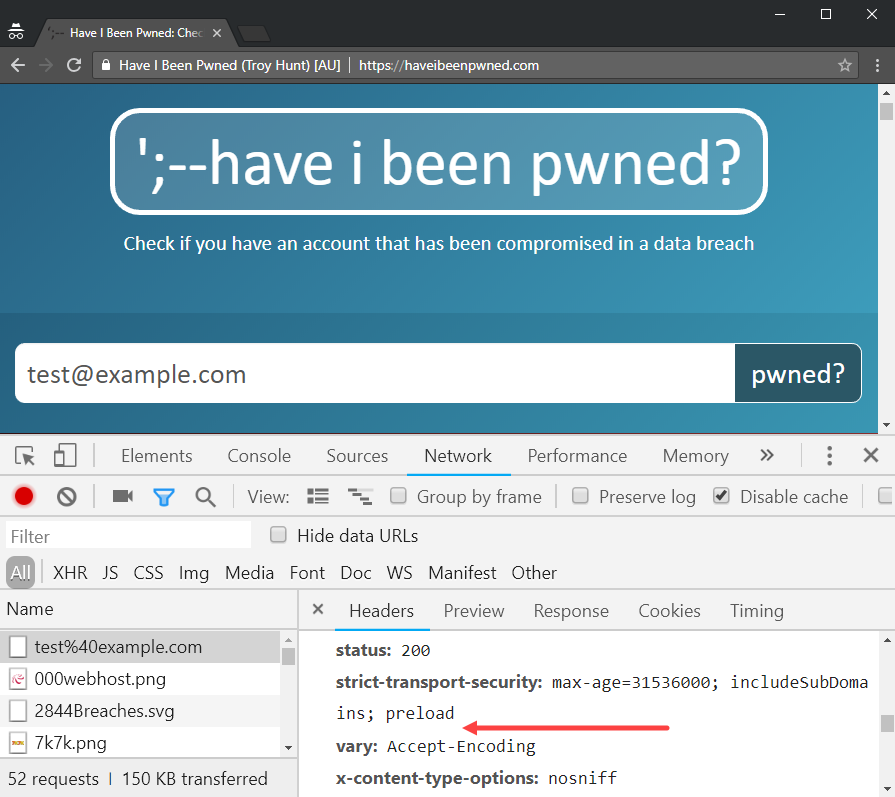
This is great because it enables me to use the site as normal but hit the new API and experience the behaviour first hand before rolling it out further. In building the new API, I actually modified the JSON response slightly from the original version (I removed some unnecessary properties) so being able to browse around with the console open and see any errors whilst running against a production data set is really neat. In my subsequent testing, I did identify a number of edge cases that needed work so I fixed those, pushed changes, tested again and got things to the point where I was completely happy with the behaviour (and performance) of the API. Now I need more guinea pigs!
I want to expand the scope of my test to use a sample of genuine requests coming to the old endpoint, that is normal everyday people doing searches. I only want to take a small sample of them though so I can watch the performance of the API and monitor any errors that might occur so I tweak the logic that decides if you're part of the test group as follows:
if(Math.random() < 0.2){
isTestGroup = true
}And that's it - 20% of requests will now be directed to the new API. If something bombs with it and they retry, there's a 4 out of 5 chance they'll hit the old one I know is super stable. I head off and start making requests via the live site until one returns the expected header:
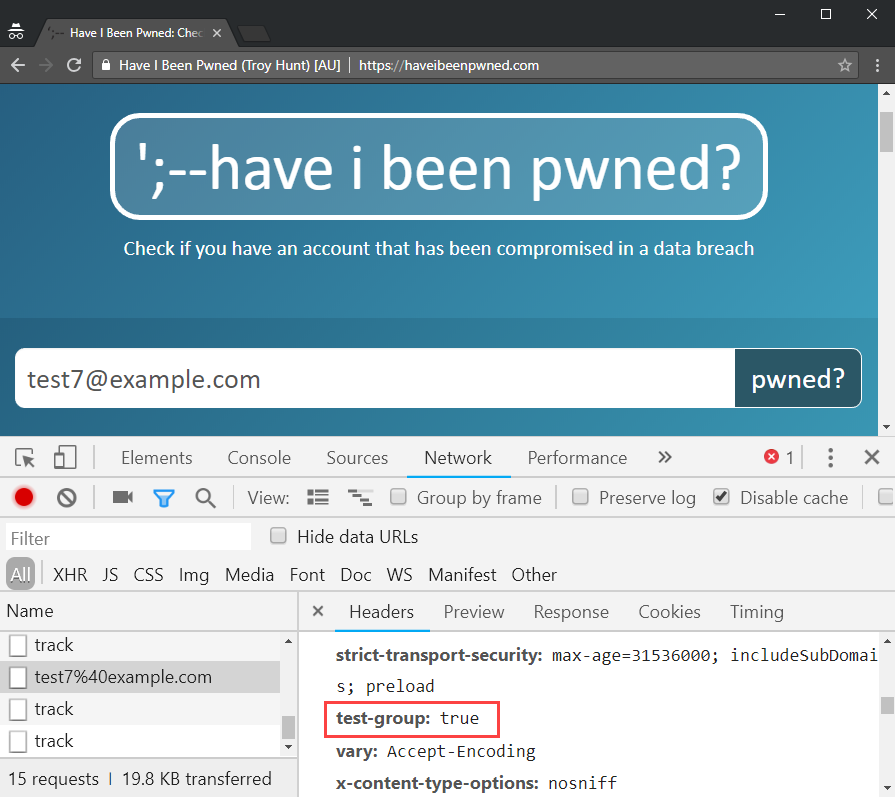
That took 7 goes and I kept incrementing the number of the email address to ensure I wasn't getting a cached result. Statistically, that's about the right number of goes and by hitting it incognito I was confident the cookie wasn't at play any more either. So, good result there, I can let that run for a while and go onto other things.
Speaking of which, let's move onto those deployment slots. About the easiest way you can deploy an Azure Function is via GitHub on commit. This ensures you're always deploying from source control, your deployment history is easily accessible and you can quickly roll back to a recent deployment:
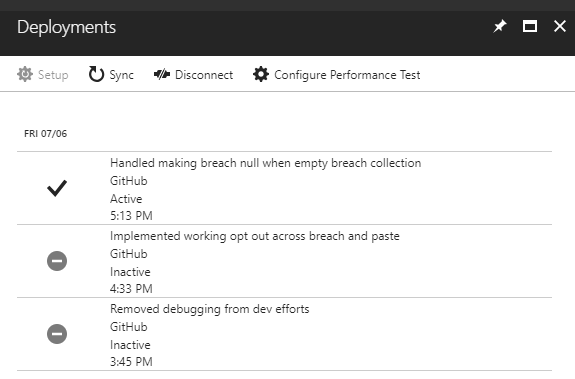
That's the good news, now let's tackle the bad news and I'm going to illustrate this by way of example. Following is a screen cap of Fiddler replaying requests sequentially, that is it issues a request, waits for a response then issues the same one again over and over. See if you can spot where the deployment happens (and incidentally, I disabled the Cloudflare worker above before doing this so that nobody would actually see an error):

The problem is that deployment is not a seamless process. New code is being pushed, old code is being replaced, some requests get dropped. You don't want that at the best of times, let alone when we're moving headlong into this new serverless world which is meant to be so high performance and reliable. This is where Azure deployment slots come in so let's see them in action. That link gives you the rundown on how to create one (it's about a 20 second job, I called mine "stage"), after which I removed the GitHub deployment from the primary slot and set up automatic deployment to the stage slot. Now, after pushing to GitHub and letting it deploy to the new slot, it's just a matter of swapping them:
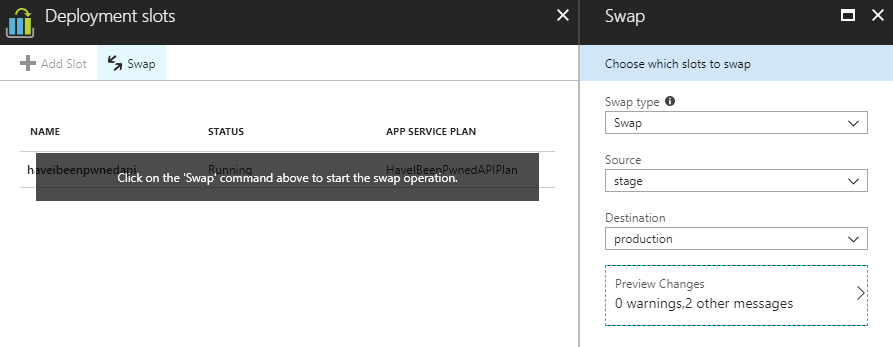
The 2 messages in the image above were simply due to some settings staying with the slot and others moving. Do get these right per the Microsoft article above, it'll ensure production traffic is hitting production storage accounts and other services you want handled separately between that environment and the staging one. Let's now swap and just before doing so, I'll fire up Fiddler to issue a heap of requests again:
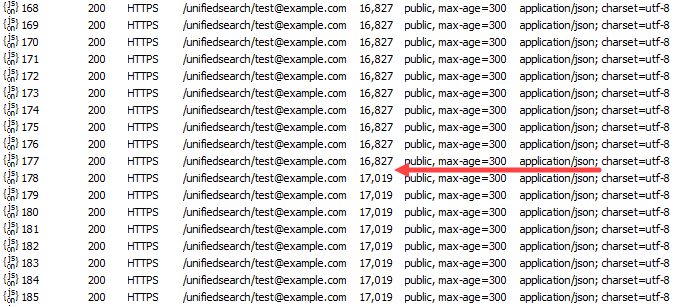
See where the swap happened? I made the new deployment return slightly more data so you could see when it happens and unlike the earlier image, there's zero dropped requests. That stage slot can be hit at any time too so when you tie it all together, the workflow for a release looks like this:
- Push new code to GitHub
- Let it deploy to the stage slot
- Run any tests you need to against there
- Swap stage with production
So not only do you get zero downtime, you also get to test the whole thing first before seeing it go live. I've got a whole suite of little integration tests I can run over HTTP just to make sure everything in the target environment is behaving precisely as I expect it to.
Onto the next piece and per the title, it's going to involve DNS rollover. The Azure Function I set up above is new, it's actually replacing the old one which had the aforementioned dramas. As such, I need to roll DNS to go from pointing to one Function app to another one. Managing DNS can be painful at the best of times if you're not super cautious, and it's extra tricky in Azure due to the way the domain validation happens. When you add a hostname to a service, Azure wants to validate that the DNS records already have a CNAME pointing to the resource you're trying to bind it to. This means you have to update DNS to point to somewhere that hasn't yet had that name bound before you can bind the name, get it? (Incidentally, you're also not meant to use A records when binding a domain to a consumption-based Function, I assume so that Microsoft can shuffle the service across different IPs at their will.) Now, if you do it quickly enough then hopefully by the time DNS propagates to people hitting the resource you'll have it bound to the new one, but you also can't bind it until Azure has seen DNS change which means other people might too! And just to make it even harder, you can't add the domain to the new Azure resource before removing it from the old one. (If anyone is reading this and thinks I've got it wrong, please comment!)
This is where Cloudflare Workers can help again because regardless of where DNS is bound to, so long as the request is routing through them then I can point it to whatever underlying resource I want. In fact, because Workers are so easy to configure and redirect traffic with, I can begin sending people to the new Function app without even touching DNS as follows:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
async function fetchAndApply(request) {
// Grab the original URL and modify it
let url = request.url.replace('https://api.haveibeenpwned.com/', 'https://[azure function name].azurewebsites.net/')
const modifiedRequest = new Request(url, {
method: request.method,
headers: request.headers
})
// Send the request on
const response = await fetch(modifiedRequest)
// Add a header indicating the request was redirected
const newHeaders = new Headers(response.headers)
newHeaders.append('Redirected-Url', true)
return new Response(response.body, {
status: response.status,
statusText: response.statusText,
headers: newHeaders
})
}And just as a quick test:
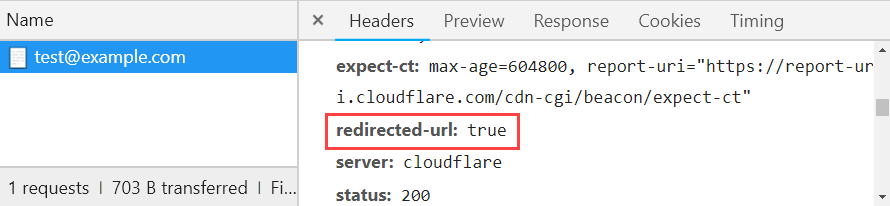
Success! All traffic is now going through to the new service so I can relax a little with the DNS rollover. There are still edge cases, namely that you need to stop routing through Cloudflare in order for Azure to see the CNAME resolving to their own service and that then creates an issue if you're using a Cloudflare origin cert which browsers won't validate. Fortunately, I find that Azure usually sees any changes on Cloudflare's DNS within seconds so it's a very small window.
Another little side note on the API rollover from the old unified search to the new: during the testing process I identified a bug that was causing some searches to be case sensitive. Rather than rush to fix a bug in the live service, I simply updated the Cloudflare worker to redirect all traffic back to the original service. This gave me time to fix the issue, push the change to stage, test it there, swap the slot to production (which still wasn't getting any unified search traffic), test it again then eventually update the worker to being redirecting unified search traffic back again. It meant things ended up looking like this:
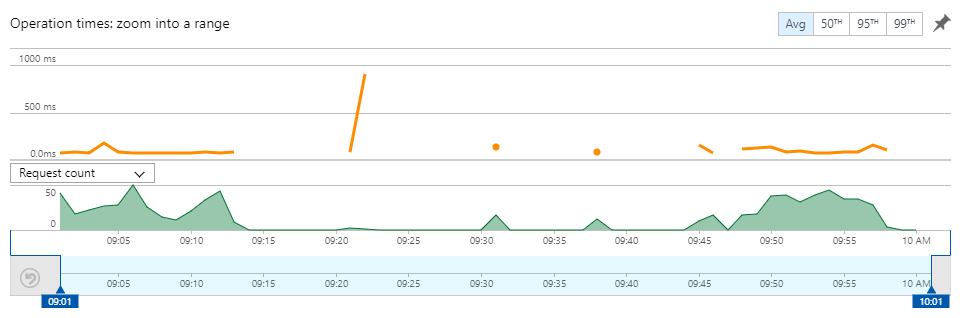
You can see the traffic rapidly go to zero, a few of my test requests over a half hour period then the traffic return to normal after that. The point of all this is that Workers make it dead simple to instantaneously reroute traffic whilst you're bug fixing or rolling over services or doing anything else where you want to make fast, easy changes to the traffic flow.
So how does that unified search look now? Rock solid!
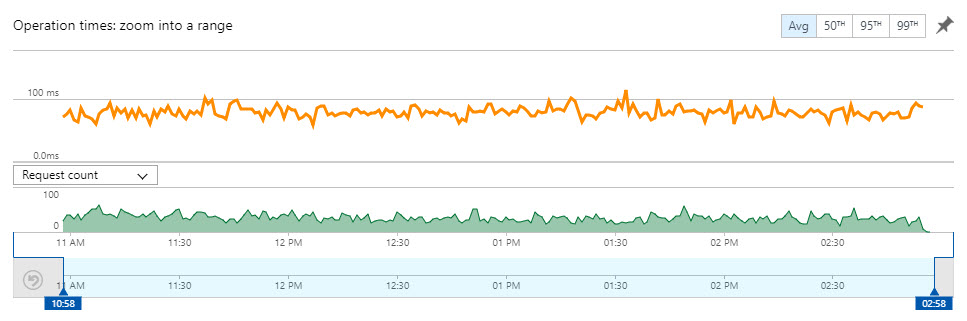
Over the last couple of weeks, I gradually upped the amount of traffic going to the new service by tweaking the Worker. Eventually, it got to 100% after which I then modified the HIBP site itself to ensure people hit the new URL on api.haveibeenpwned.com directly. The final step was to decommission the old Web API version that ran in the HIBP website but before doing that, I scrapped the old Worker that gradually redirected traffic and replaced it with this one:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
async function fetchAndApply(request) {
return new Response(null, { status: 404 })
}That's then applied to the old API route of https://haveibeenpwned.com/api/v2/unifiedsearch/* which means that every request for a service that no longer exists is returned quickly from the edge without me having to process it on the origin. It's a little thing, but it's also a really neat approach and just one more way of unburdening the website itself.
And just for good measure, because I want to make sure that API isn't abused I dropped in a Cloudflare rate limit too:
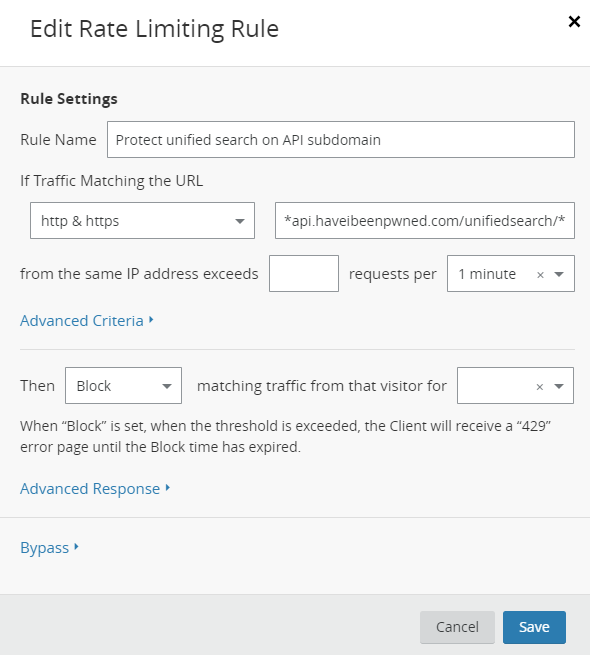
The blank "requests per minute" and duration for which traffic is blocked are settings I keep tweaking. Being an undocumented API I won't talk about precisely what values I'm playing with here, suffice to say I'm always looking for that balance which lets the good stuff in and keeps the bad stuff out. The main thing is that by using this feature "at the edge", just like how I'm responding with the 404 above I can keep requests off the origin website and deal with misuse upstream. That's especially important when we're talking about potential brute force style attacks that send huge volumes of traffic because as I've said before, the last thing you want to be doing is trying to use your web server infrastructure to fend off attacks whilst also serving legitimate traffic.
I love the way these two services work in unison: Azure Functions to ensure you can scale immediately without being bound by logical infrastructure, deployment slots that make it easy to test and rollover new releases with zero downtime, then of course Cloudflare Workers to give you heaps of control over traffic flow for testing and rollover purposes and all protected using their rate limit service. The next task on my list is to move the documented APIs over to Azure Functions which in days gone by would have been a breaking change due to the different host name, but of course now I can just use a Cloudflare Worker to point requests to a totally different location without anyone even knowing something has changed. Once I do that, not only will the sudden traffic spikes on the HIBP website disappear (the homepage is really aggressively cached and there's nowhere else on the site that gets big traffic volumes), but I'll also be able to scale down the Azure App Service that runs it to an S2 instance which is half the price. Because those Functions are so cheap to execute, I expect it'll save hundreds of dollars off the Azure costs each month which is really significant for a project like this.
Let me close with one final note: a lot of effort goes into making everything look easy in a blog post like this. This is what I find myself doing these days - taking things that can be complex and presenting them in ways which are readily consumable. But truth be told, I break more than my fair share of stuff in preparing material such as this and there's often a heap of trial and error involved to ultimately distil everything down to what you'd read here. I just wanted to add that in case anyone feels a bit disillusioned wondering why things aren't as easy as they seem! Hopefully they are if you replicate this process, but there was a lot of HTTP 5XX along the way trying to make this simple ?